この記事はElasticsearch Advent Calendar 2015の22日目のエントリです。
最近、インデクシングのパフォーマンスを測定する機会があったので、高スループットを追求するための考慮事項や測定結果をまとめました。特に記述のない場合、Elasticsearchのバージョンは1.7.3を前提にしています。またクライアントはTransport/NodeクライアントではなくHTTP/REST経由でElasticsearchにデータを送信することを想定しています。
インデックス定義・設計時
マッピングを定義して暗黙的なマッピングを避け、不要なフィールドを作らないようにする
Elasticsearchはスキーマレスをうたっており、マッピングの定義をしなくても自動で作成される。しかし実運用上はマッピングの作成は必要不可欠。自動で作成されるフィールドのタイプは最初にElasticsearchが受け取ったデータで決まり、その後変更できない。(フィールドの追加や一部属性は変更可能)明示的に作成していないフィールドのタイプ不整合などによって生じるエラーを避けるため、dynamic=strictなどを指定してフィールドの自動生成を禁止するのが推奨される。
Elasticsearchはデフォルトの設定が注意深く選ばれており、そのままで使えてしまう事も多いが、マニュアルでマッピング定義をすることで、各フィールドに対して下記のような詳細な設定を行う事ができる。
必要でなければ_allの使用をやめる
全フィールドのデータをまとめて検索可能にする_allというメタフィールドがあり、デフォルトで使用可能になっている。index=noでないフィールドのデータはこのフィールドにコピーされ検索可能になる。必要ない場合、include_in_all, enabledなどの属性で除外するフィールドを指定したり、完全に使わない設定にしてディスク容量を節約できる。ちなみにquery_stringクエリやsimple_stringクエリはフィールド指定がない場合にこのフィールドをデフォルトの検索フィールドとして使用する。
必要でなければ_sourceの使用をやめる
_sourceは送信されたドキュメントのオリジナルのJSONデータを格納するメタフィールド。デフォルトで使用可能になっており、ハイライトやUpdate API、再インデックスなどの用途に使える。これらの用途に必要でなければ、disabledすることでディスク容量を削減することが可能。ただし_allよりは幾分使われる局面が多いように思われる。
下表は筆者の環境で実験的に_allと_sourceをdisableした場合のインデックスのサイズを測定したもの(HTMLファイル300万件17GB、レプリカ無し、フィールドはidとコンテンツ用のフィールドのみ)。_allや_sourceが全体のサイズにどれくらい影響を与えているかが分かる。
| _all | _source | インデックスサイズ | 削減率 |
|---|---|---|---|
| enabled | enabled | 24.5GB | 0% |
| disabled | enabled | 18.5GB | 24% |
| enabled | disabled | 19.1GB | 22% |
| disabled | disabled | 13.3GB | 46% |
storeやindex属性を設定してインデックスサイズを削減する
データベースと異なり、Elasticsearchではストアされていないフィールドの値は取り出すことができない(_sourceメタフィールドがenabledであればそちらから取り出すことはできる)。検索のみに使用し、値を取得する必要がないフィールドはstore=falseとすることでディスク容量を節約できる。また、stringタイプのフィールドはデフォルトでanalyzedであり、トークナイズされたデータを使って検索可能になるが、ソート/アグリゲーションなどの用途で使用する場合はindex=not_analyzedと設定し、トークナイズしないようにする。検索にもソート・アグリゲーションにも使用しないフィールドはindex=noと設定することでデータ容量を削減できる。
下表は筆者の環境でこれらの設定を行い、インデックスサイズを測定したもの。(HTMLファイル300万件17GB、レプリカ無し、フィールドはidとコンテンツ用のフィールドのみ。Luceneの制限で32KBを超えるデータをnot analyzedフィールドに格納することができないので、index=not_analyzedはignore_above=10922と一緒に指定している。参照:ignore_above)ストアされているフィールドやトークナイズされたインデックスがどの程度の容量を占めるのかが分かる。
| index | store | インデックスサイズ | 削減率 |
|---|---|---|---|
| analyzed | true | 24.4GB | 0% |
| analyzed | false | 19.4GB | 20% |
| not_analyzed | true | 21.8GB | 11% |
| no | true | 12.8GB | 48% |
マッピングタイプを使いすぎないようにする
Elasticsearchでは1つのインデックスの中に複数の異なるスキーマ定義を持つことができる。このスキーマ定義をマッピングタイプという。単に「タイプ」と呼ばれる事もある。フィールドのデータタイプとは別の概念。インデックスはデータベースに、マッピングタイプはその中のテーブルに例えられる事が多いが、同じ名前のフィールドはマッピングタイプが異なっていても定義が共有されたりして、データベースのテーブルほど互いに独立していない中途半端なものになっている。(2.0より前のバージョンではタイプごとにフィールド定義が異なっていても多少使えたりしたが、2.0以降は厳密に禁止されるようになった. 参照:Conflicting field mappings)
タイプが異なっていてもデータは同じLuceneインデックスの中に混ざって入ってしまうため、タイプ間で互いに影響する事が避けられない。例えば、大量のデータを含むタイプAと少量のデータを含むタイプBが同じインデックスに存在した場合、Luceneはインデックスに含まれるターム数に応じてメモリを確保するので、タイプBしか検索しない場合でも、タイプAとタイプB両方の検索に必要なメモリを確保しようとして、余分なメモリ要求が発生することになる。
Elasticsearchの開発者もタイプとテーブルとのアナロジーは間違った発想だったと述べている。https://www.elastic.co/blog/index-vs-type
This was a mistake: the way data is stored is so different that any comparisons can hardly make sense, and this ultimately led to an overuse of types in cases where they were more harmful than helpful.
データ投入前
インデクシング中のレプリカの数について検討する
インデクシングのパフォーマンスにおいてレプリカの存在は大きなコストである。プライマリシャードで実行したインデクシングをそれぞれのレプリカに対してもリプレイし、その完了を待たなければいけない。実際、インデックスリクエストは下記のように処理される。
- クライアントはURLを指定してリクエストを送るノードを決める(このノードをそのリクエストのコーディネーターと呼ぶ)
- idの値からどのプライマリシャードにドキュメントを書き込むべきか判断し、そのプライマリシャードの存在するノードにリクエストが転送される
- プライマリシャードで書き込みが完了した後、レプリカシャードの存在するノードに同じリクエストが転送される
- 全レプリカシャードで書き込みが完了したら、コーディネーターは呼び出し側にレスポンスを返す
このように、全レプリカに書込みが完了するまで呼び出し側は待たされることになるので、レプリカの数が多いほど待ち時間が長くなる傾向にある。また、なんらかの理由で特定のレプリカに書き込みが失敗し、シャード間の整合性が崩れた場合、ノードの再始動時にチェックが行われ、必要なセグメントが別シャードからコピーされ復旧される。インデクシング時にこれが起こればスループットに対して大きな影響がある。
Elasticsearchではプライマリシャードの数は変更できないが、レプリカシャードの数は自由に変更できる。可能であれば最初はレプリカ数を0にしてインデクシングを行い、インデックス終了後にレプリカを増やすようにする。
プライマリシャードの個数について検討する
前述のようにプライマリシャードの数はインデックス作成時に一定に決まってしまうので、将来のデータ増加を見越して多めにプライマリシャードの個数を設定するよう推奨される事が多い(参照)。こうすることで、将来データが増加したときにノードを追加し、プライマリシャードをそちらにリバランスさせることでスケールさせることができる。
もし将来的にノードを追加する予定がない場合はプライマリシャードをノード数と同数程度にするのがよい。1ノードあたりのシャード数が増えるとディスクにデータを分けて書くことになりディスクI/Oの負荷が増加する。
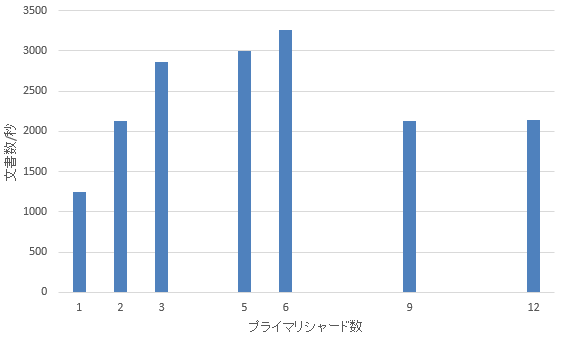
下表は3ノードのクラスターに対してプライマリシャードの個数を変化させてスループットを計測した結果(レプリカなし)。いずれもシャードのアロケーションは操作せず、Elasticsearchにオートバランスさせている。3シャードまではスループットが直線的に改善しているが、それ以降はほぼ頭打ちでオーバーヘッドによって悪化する様子が見られる。
refresh intervalを長めにしてセグメントマージの量を削減する
refresh_intervalは定期的に実行されるリフレッシュの間隔の設定で、このタイミングでLuceneのインメモリバッファの内容がファイルキャッシュに移されてセグメントとなり、検索可能になる。セグメントはサーチの効率化のためにバックグラウンドでマージされて大きなセグメントになる。
refresh_intervalが短いと、投入したデータはすぐに検索可能になるが、その分、小さなセグメントが多数生成されて必要なマージも増えるというトレードオフの関係にある。refresh_intervalのデフォルト値は1秒で、Near Realtimeサーチを実現するためにややマージの負荷を上げる方向に振ってあると考えられる。データをインデクシングしてる間にNear Realtimeサーチが必要でなければ、refresh_intervalを長く設定することで、マージにDisk I/Oが消費されるのを避けることができる。
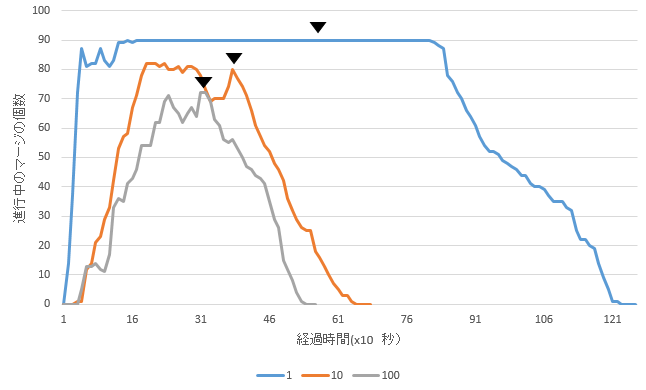
下記は100万文書(合計5.6GB)を異なる長さのrefresh_intervalで実行した場合のマージの個数を示したもの。三角形のマークはバルクリクエスト処理が完了したタイミングを表している。refresh intervalが短いものほど大量のマージが残り、リクエスト処理完了後もしばらく続く様子が分かる。
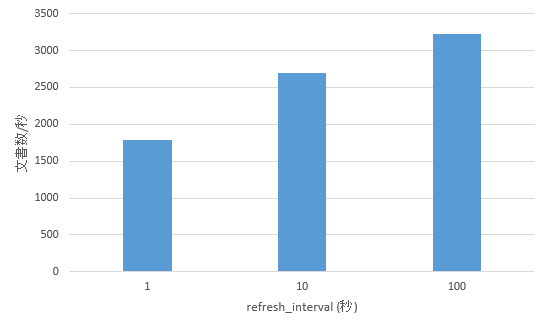
それぞれのrefresh_interval設定でのスループットを表したものが下記である。ある程度長くなると改善する割合は低くなるので、環境やデータに応じて適切な長さを事前にテストして見つけるとよい。
バージョン1.xではスロットリングをdisableすることを検討する
上述のようにElasticsearchはバックグラウンドでLuceneのセグメントをマージし、効率よいサーチのための大きいセグメントを生成する。マージの速度に対してインデクシングのスピードが速いと、小さいセグメントが大量に発生することになるので、Elasticsearchはスロットリングという仕組みでインデックスの速度を調整する。インデクシングのスループットを最大化したければindices.store.throttle.type=noneという設定によってこれを実行しないようにできる。
参照:Store Level Throttling
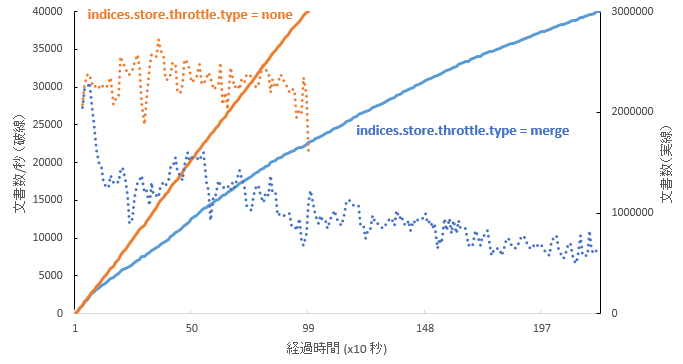
下記グラフはデフォルトの設定とスロットリングをdisableした場合について文書数の増加とスループットを示したグラフである。デフォルトの設定では文書数の増加が直線ではなく、スロットリングによって処理速度が制限されているのが分かる。
ただし2.0からはこの設定はなくなり、自動でスロットリング量が調整されるようになった(Merge and merge throttling settings)
データ送信時
データ送信前にクラスタの状態を確認する
Elasticsearchへデータを送る前にCluster Health APIでクラスターの状態を確認するようにする。シャードのリカバリなどが起こっている過負荷な状態のところへ追加でデータを挿入すると状況を悪化させることになるため。Cluster Health APIを使うと、ステータスがGreenやYellowになるまでブロックして待つ事ができる。
ステータスがRedの場合はプライマリシャードのうち利用可能でないものがあり、そのシャードに対する書き込みとなるインデクシング要求はエラーになる。Yellowの場合はレプリカシャードが完全にそろっていない可能性があり、サーチは実行可能だが、インデクシングはドキュメントが一部のレプリカにしか入らない可能性がある。文書が入らなかったレプリカは復帰後に他シャードからデータをコピーされて復旧される。
また、デフォルトの設定ではprimaryとreplicaをあわせて、quorum(過半数)のシャードが利用可能でない場合にはインデクシングが事前検査に失敗してエラーになる。この設定はwrite_consistencyで変更可能でquorumの他にallまたはoneが設定可能だが、このチェックは書き込み前に実行されるものなので、oneに変更したとしてもパフォーマンスが向上するわけではない。インデクシングが成功するためには全レプリカに書き込みが完了することが必要である。
常にBulk APIを使い、バルクサイズを十分大きくする
Bulk APIはcreate/index, delete, updateのアクションを一括してまとめてElasticsearchへ送信する仕組み。インデックスのデータを効率よく送信するために常にBulk APIを使うようにする。複数アクションをまとめて送信することで手順を減らすことができ、ソケットを開くことによるfile descriptorの消費も防げる。
バルクリクエストはコーディネータによって複数のリクエストに分解され、それぞれがプライマリシャードの存在するノードへ転送される。受け取ったノードでバルクキューにつめられ、順次更新が行われる。コーディネーターはこの更新が終わるまで呼び出し側に制御を戻さない。送信側はNodes Stats APIでバルクキューに溜まったリクエストの個数を監視し、キューがあふれないように(デフォルトのサイズは50)注意しながらデータを送信するようにする。スループットを最大化するには、キューにリクエストが残っているのを常時確認することで、十分なデータがノードに送られていると判断できる。
GET /_nodes/stats
...
"bulk": {
"threads": 4,
"queue": 12, // 現在処理待ちのキューに溜まっているリクエスト数
"active": 4,
"rejected": 350, // これまでにリジェクトされたリクエスト数
"largest": 4,
"completed": 202387
},
...
ここで「リクエスト数」はクライアントから送られたバルクを各シャード用のリクエストに分解したものの個数をさす。そのためクライアント側から送ったのは1バルクリクエストでも上記のメトリックが複数回カウントアップされることがある。
一回のバルクリクエストで送るデータの数量はクライアント側で自由に決められるが、量が小さいとオーバーヘッドが多く効率が悪い。サイズが大きすぎるとElasticsearchがHTTPのレイヤーに持つ制限値http.max_content_length(デフォルトでは100MB)にヒットしてエラーになる。この範囲内でバルクサイズを適切に大きくするようにする。http.max_content_lengthを変更し最大2Gまでにする事も可能だが、Elasticsearchの消費メモリが増加しOutOfMemoryの危険性が増すので必要でなければ避けるほうがよい。
筆者の環境でバルクサイズを変えてスループットを測定したのが下記のグラフ。この環境では1MBでは小さすぎ、10MB程度あれば十分だと考えられる。
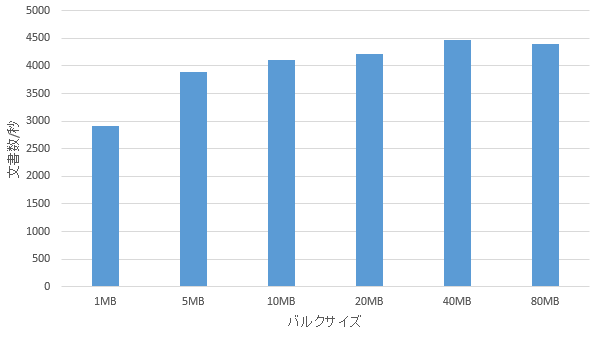
エラーを避ける、エラーハンドリングを正確に行う
バルクリクエストのレスポンスには、バルクに含まれる各アクションの実行結果が戻される。ここで観察される典型的なエラーは、過負荷でバルクキュー(デフォルトサイズは50)があふれ、EsRejectedExecutionException例外が起きるもの。ここであふれたドキュメントは捨てられるので運用時はこのエラーを拾ってインデクシングをリトライするようなロジックをクライアントアプリ側で実装する必要がある。もちろん効率よくインデクシングを行うためには上述のとおりバルクキューを注意深く観察しこのような状況を避ける必要がある。
Elasticsearchのような分散環境でエラーを検出するためには時間がかかることがある。たとえばあるノードが落ちてプライマリシャードが失われている状態のときインデクシングを実行してしまうと、そのノードに通信に行ってタイムアウトが発生してエラーとなった上で戻ってくる。タイムアウトが発生するまで何もしないで待つことになるので、スループットには大きな影響がある。
複数のセッションからデータを送信してスループットを向上させる
インデックス中にはディスク入出力やネットワーク応答待ちなどでブロックされるタイミングが必ず発生する。これを回避するためには複数クライアントやスレッドからデータを送信するのも有効。ただしこの場合Elasticsearch側に過負荷をかけないように注意する必要がある。Elasticsearchへの書き込みアクセスは同期的で全レプリカに書き込みが終了してから制御が戻されるので、単一のクライアントからの実行では過負荷になる可能性は低い。(これを一部非同期にする設定replication=asyncも可能だったが、2.0で廃止されている。)
下記は筆者の環境でスレッド数を変えてインデクシングした時の時間と処理完了した文書数の関係をグラフにしたもの。四角形内の数字はスレッド数を表す。スレッド数を増やすとスループットが向上するが、32スレッドと64スレッドで実行した場合は過負荷になりキューがあふれてrejectされ、送信した全データはインデクシングできていない。
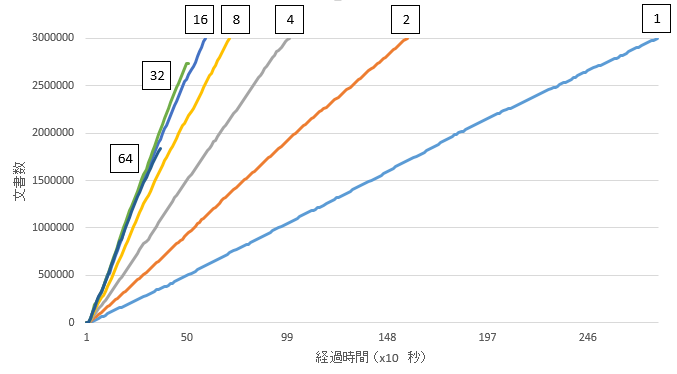
| スレッド数 | 64 | 32 | 16 | 8 | 4 | 2 | 1 |
|---|---|---|---|---|---|---|---|
| 文書数/秒 | 4963 | 5365 | 5085 | 4225 | 3000 | 1899 | 1071 |
その他、スループット向上に効果がなかったこと
- ドキュメントをインデックスに追加するアクションには、indexとcreateの2種類がある。違いは、indexはすでに同じidを持つドキュメントが存在しても上書き更新するが、createはエラーになるという点。チェックをしている分createの方が遅いかと思われたが、実際に検証したところでは差はみられなかった。Elasticsearchはドキュメントにバージョンを付加して管理しているのでindexの場合も既存のドキュメントのバージョン確認が必要であり、ロジックとしてcreateとあまり変わらないのかも知れない。
- また、クラスタを構成する各ノードに平均的にデータを送信することでコーディネーターのタスクが分散され、スループットが向上するかと思われたが、検証の結果ほとんど違いは見られなかった。筆者の環境ではデータ量が少なくコーディネーターのノードに対する負荷が十分でないため分散の効果が現れなかったのかもしれない。
- バルクキューを観察していると特定のノードに負荷が集中し、別ノードは遊んでいるように見えるというケースが頻繁にあった。何が原因で偏りが起きるのか、設定次第で全ノードに平均的に負荷をかけられるようにできるのか分かっていない。
参考文献
https://www.elastic.co/blog/performance-considerations-elasticsearch-indexing
https://www.elastic.co/guide/en/elasticsearch/guide/current/indexing-performance.html
https://www.loggly.com/blog/nine-tips-configuring-elasticsearch-for-high-performance/