はじめに
日本語の文章内の単語をemojiに変換するえもじほんやくき(emoji-translate-jp)を作ってみました。考え方と参考にした記事、ライブラリなどをシェアしたいと思います! ![]()
emoji-translate-jpとは
こちらです。
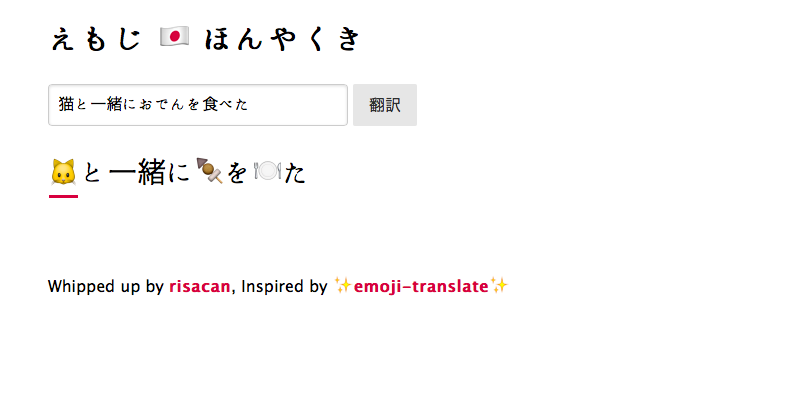
https://risacan.github.io/emoji-translate-jp/app/index.html
Herokuの立ち上げで翻訳に時間がかかる場合があります。 ![]() でも淹れながら気長に変換をお待ち下さい。
でも淹れながら気長に変換をお待ち下さい。
emoji-translateの実装
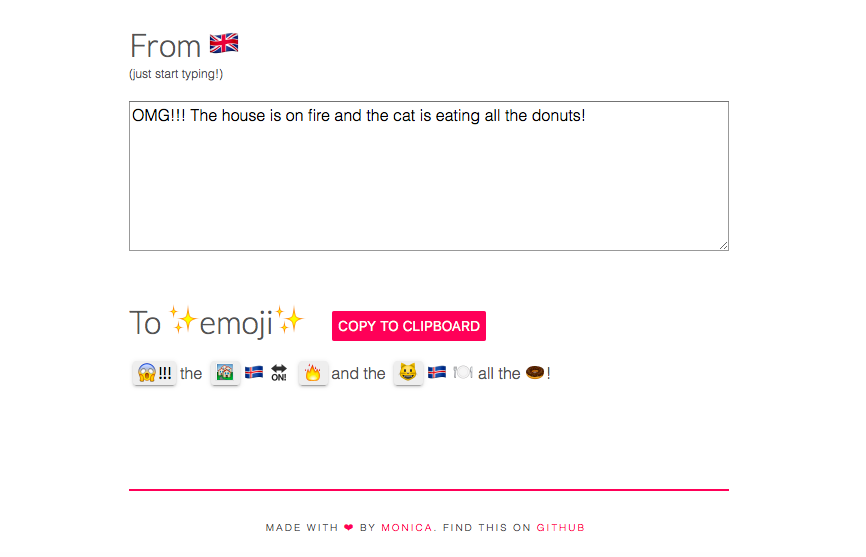
emoji-translate- jp は、英文の単語をemojiに変換してくれるemoji-translateを非常に参考にしています。そのため、最初にemoji-translateの紹介をします。
emoji-translateはemojilibというemojiのキーワードを集めたライブラリを利用して作られています。
emojilibは1つの大きなJSONファイルです。emoji codeと、複数のキーワード、emojiそのもの、emojiのカテゴリー名で構成されています。
"grinning": {
"keywords": ["face", "smile", "happy", "joy", ":D"],
"char": "😀",
"category": "people"
},
"grimacing": {
"keywords": ["face", "grimace", "teeth"],
"char": "😬",
"category": "people"
},
"grin": {
"keywords": ["face", "happy", "smile", "joy"],
"char": "😁",
"category": "people"
},
"joy": {
"keywords": ["face", "cry", "tears", "weep", "happy", "haha"],
"char": "😂",
"category": "people"
},
"smiley": {
"keywords": ["face", "happy", "joy", "haha", ":D"],
"char": "😃",
"category": "people"
},
"smile": {
"keywords": ["face", "happy", "joy", "funny", "haha", "laugh", "like", ":D"],
"char": "😄",
"category": "people"
},
"sweat_smile": {
"keywords": ["face", "hot", "happy", "laugh"],
"char": "😅",
"category": "people"
},
(省略)
emoji-translateでは、まず英語の文章をスペースで区切り1単語にしたあと、その1単語をemojilibと照らし合わせます。そして、対応するemojiがあった場合は該当のemoji(たとえば"😁"、"🐶"、"🍎")を表示し、対応するemojiがなければもとの単語を表示させています(たとえば、"the", "all", "is")。
emoji-translate-jpをどう作るか
emoji-translateのコードを読んで、日本語版としてemoji-translate-jpを実装するにはどうすればいいか考えました。emoji-translate-jpも、emoji-translateと同じように、
- 文章を単語に分割
- 1つ1つの単語をemojiに変換
- もとの文章中の単語をemojiに置き換え
この3点を実現すればいいはずです。
文章を単語に分割
まず、文章を単語に分割することを考えました。英語だとスペースを使って区切れば ![]() ですが、日本語はそうは行きません。そこで、日本語形態素解析エンジンのkuromojiを使い、文章を言葉に分割することにしました。
ですが、日本語はそうは行きません。そこで、日本語形態素解析エンジンのkuromojiを使い、文章を言葉に分割することにしました。
kuromoji.js/README.md at master · takuyaa/kuromoji.js
README.mdを参考に以下のコードを実行してみると・・・
var kuromoji = require("kuromoji");
kuromoji.builder({ dicPath: "./node_modules/kuromoji/dict" }).build(function (err, tokenizer) {
// tokenizer is ready
var path = tokenizer.tokenize("大変!家が燃えてて猫がドーナツ全部食べた。");
console.log(path);
});
[ { word_id: 305410,
word_type: 'KNOWN',
word_position: 1,
surface_form: '大変',
pos: '名詞',
pos_detail_1: '形容動詞語幹',
pos_detail_2: '*',
pos_detail_3: '*',
conjugated_type: '*',
conjugated_form: '*',
basic_form: '大変',
reading: 'タイヘン',
pronunciation: 'タイヘン' },
{ word_id: 91640,
word_type: 'KNOWN',
word_position: 3,
surface_form: '!',
pos: '記号',
pos_detail_1: '一般',
pos_detail_2: '*',
pos_detail_3: '*',
conjugated_type: '*',
conjugated_form: '*',
basic_form: '!',
reading: '!',
pronunciation: '!' },
{ word_id: 2326630,
word_type: 'KNOWN',
word_position: 4,
surface_form: '家',
pos: '名詞',
pos_detail_1: '一般',
pos_detail_2: '*',
pos_detail_3: '*',
conjugated_type: '*',
conjugated_form: '*',
basic_form: '家',
reading: 'イエ',
pronunciation: 'イエ' },
{ word_id: 92920,
word_type: 'KNOWN',
word_position: 5,
surface_form: 'が',
pos: '助詞',
pos_detail_1: '格助詞',
pos_detail_2: '一般',
pos_detail_3: '*',
conjugated_type: '*',
conjugated_form: '*',
basic_form: 'が',
reading: 'ガ',
pronunciation: 'ガ' },
{ word_id: 229980,
word_type: 'KNOWN',
word_position: 6,
surface_form: '燃え',
pos: '動詞',
pos_detail_1: '自立',
pos_detail_2: '*',
pos_detail_3: '*',
conjugated_type: '一段',
conjugated_form: '連用形',
basic_form: '燃える',
reading: 'モエ',
pronunciation: 'モエ' },
{ word_id: 1114670,
word_type: 'KNOWN',
word_position: 8,
surface_form: 'て',
pos: '動詞',
pos_detail_1: '非自立',
pos_detail_2: '*',
pos_detail_3: '*',
conjugated_type: '一段',
conjugated_form: '連用形',
basic_form: 'てる',
reading: 'テ',
pronunciation: 'テ' },
{ word_id: 92780,
word_type: 'KNOWN',
word_position: 9,
surface_form: 'て',
pos: '助詞',
pos_detail_1: '接続助詞',
pos_detail_2: '*',
pos_detail_3: '*',
conjugated_type: '*',
conjugated_form: '*',
basic_form: 'て',
reading: 'テ',
pronunciation: 'テ' },
{ word_id: 1172110,
word_type: 'KNOWN',
word_position: 10,
surface_form: '猫',
pos: '名詞',
pos_detail_1: '一般',
pos_detail_2: '*',
pos_detail_3: '*',
conjugated_type: '*',
conjugated_form: '*',
basic_form: '猫',
reading: 'ネコ',
pronunciation: 'ネコ' },
{ word_id: 92920,
word_type: 'KNOWN',
word_position: 11,
surface_form: 'が',
pos: '助詞',
pos_detail_1: '格助詞',
pos_detail_2: '一般',
pos_detail_3: '*',
conjugated_type: '*',
conjugated_form: '*',
basic_form: 'が',
reading: 'ガ',
pronunciation: 'ガ' },
{ word_id: 2181020,
word_type: 'KNOWN',
word_position: 12,
surface_form: 'ドーナツ',
pos: '名詞',
pos_detail_1: '一般',
pos_detail_2: '*',
pos_detail_3: '*',
conjugated_type: '*',
conjugated_form: '*',
basic_form: 'ドーナツ',
reading: 'ドーナツ',
pronunciation: 'ドーナツ' },
{ word_id: 34920,
word_type: 'KNOWN',
word_position: 16,
surface_form: '全部',
pos: '名詞',
pos_detail_1: '副詞可能',
pos_detail_2: '*',
pos_detail_3: '*',
conjugated_type: '*',
conjugated_form: '*',
basic_form: '全部',
reading: 'ゼンブ',
pronunciation: 'ゼンブ' },
{ word_id: 3037610,
word_type: 'KNOWN',
word_position: 18,
surface_form: '食べ',
pos: '動詞',
pos_detail_1: '自立',
pos_detail_2: '*',
pos_detail_3: '*',
conjugated_type: '一段',
conjugated_form: '連用形',
basic_form: '食べる',
reading: 'タベ',
pronunciation: 'タベ' },
{ word_id: 23430,
word_type: 'KNOWN',
word_position: 20,
surface_form: 'た',
pos: '助動詞',
pos_detail_1: '*',
pos_detail_2: '*',
pos_detail_3: '*',
conjugated_type: '特殊・タ',
conjugated_form: '基本形',
basic_form: 'た',
reading: 'タ',
pronunciation: 'タ' },
{ word_id: 90940,
word_type: 'KNOWN',
word_position: 21,
surface_form: '。',
pos: '記号',
pos_detail_1: '句点',
pos_detail_2: '*',
pos_detail_3: '*',
conjugated_type: '*',
conjugated_form: '*',
basic_form: '。',
reading: '。',
pronunciation: '。' } ]
surface_from の欄に注目してみるといい感じに単語にわかれています。
"大変!家が燃えてて猫がドーナツ全部食べた。" という文章を、
"大変/!/家/が/燃え/て/て/猫/が/ドーナツ/全部/食べ/た/。" というような単語に区切ることができました。 ![]()
1つ1つの単語をemojiに変換
次に、分割した1つ1つの単語をemojiに変換していく方法を考えます。2つの方法を思いつきました。
- emojilibを日本語化する
- 単語を英訳してemojilibで検索する
1をプロジェクト化するのも面白そうですが、ライブラリを育てるにはかなり時間がかかりそうなので、2を選択しました。
単語を英語に翻訳
無料のMicrosoft translate API を使って、単語を翻訳します。
Microsoft Translator APIを使ってみる – nanoway
こちらの記事を参考に、単語を1つずつ翻訳して、もとの日本語の単語の区切りとついになるような配列を作りました。しかし日本語単語の配列を一番最初から順番に翻訳APIで叩いても、帰ってくる順番がバラバラで思ったような配列になりませんでした。そこで、もとの配列のインデックスと変換後の英単語のインデックスを合わせることで配列を作成して解決しました ![]()
["大変", "!", "家", "が", "燃え", "て", "て", "猫", "が", "ドーナツ", "全部", "食べ", "た", "。"]
["hard", "!", "home", "but", "burning", "as", "as", "cat", "but", "donut", "all of it", "eat", "i", “。"]
emojilibのkeywordを反映させる
次に、英単語がemojilibのキーワードにあるかチェックします。emojiが複数該当する場合があるので配列で返すようにしました。
例えば、"home"は該当するemojiが複数あるので
[ '👪', '👨👩👧', '👨👩👧👦', '👨👩👦👦', '👨👩👧👧', '👩👩👦', '👩👩👧', '👩👩👧👦', '👩👩👦👦', '👩👩👧👧', '👨👨👦', '👨👨👧', '👨👨👧👦', '👨👨👦👦', '👨👨👧👧', '🏠', '🏡' ] という配列を返すようにします。
反対に、該当するemojiがなければ ""が返されます。
文章中の単語をemojiに置き換え
最後に、画面に表示する文章を構成します。
emojiの配列と日本語単語の配列を比べて、該当emojiがない部分には日本語単語が入るようにします。
[大変,!,[👪,👨👩👧,👨👩👧👦,...,👨👨👦👦,👨👨👧👧,🏠,🏡],が,燃え,て,て,[🐱,🐯,🐾],が,[🍩],全部,[🍽],た,。]
画面に表示する
あとは、配列の要素をつなげて表示するだけです。
各要素にhtmlのタグを付けます。複数選択肢のあるemojiはプルダウンで選択できるようにしました。
["<span>大変</span>", "<span>!</span>", "<select>", "<option>👪</option>", "<option>👨👩👧</option>", "<option>👨👩👧👦</option>", ..., "<option>👨👨👦👦</option>", "<option>👨👨👧👧</option>", "<option>🏠</option>", "<option>🏡</option>", "</select>", "<span>が</span>", "<span>燃え</span>", "<span>て</span>", "<span>て</span>", "<select>", "<option>🐱</option>", "<option>🐯</option>", "<option>🐾</option>", "</select>", "<span>が</span>", "<span>🍩</span>", "<span>全部</span>", "<span>🍽</span>", "<span>た</span>", "<span>。</span>"]
これまでの作業で、入力された日本語の文章はこんなふうに変化してきました。
"大変!家が燃えてて猫がドーナツ全部食べた。"
👇
["大変", "!", "家", "が", "燃え", "て", "て", "猫", "が", "ドーナツ", "全部", "食べ", "た", "。"]
👇
["hard", "!", "home", "but", "burning", "as", "as", "cat", "but", "donut", "all of it", "eat", "i", “。"]
👇
[“”,””,[👪,👨👩👧,👨👩👧👦,...,👨👨👦👦,👨👨👧👧,🏠,🏡],””,””,””,””,[🐱,🐯,🐾],”",[🍩],"",[🍽],"",""]
👇
[大変,!,[👪,👨👩👧,👨👩👧👦,...,👨👨👦👦,👨👨👧👧,🏠,🏡],が,燃え,て,て,[🐱,🐯,🐾],が,[🍩],全部,[🍽],た,。]
👇
["<span>大変</span>", "<span>!</span>",
"<select>", "<option>👪</option>", "<option>👨👩👧</option>", "<option>👨👩👧👦</option>", ..., "<option>👨👨👦👦</option>", "<option>👨👨👧👧</option>", "<option>🏠</option>", "<option>🏡</option>", "</select>", "<span>が</span>", "<span>燃え</span>", "<span>て</span>", "<span>て</span>", "<select>", "<option>🐱</option>", "<option>🐯</option>", "<option>🐾</option>", "</select>", "<span>が</span>", "<span>🍩</span>", "<span>全部</span>", "<span>🍽</span>", "<span>た</span>", "<span>。</span>"]
完成です ![]()

あとまわし
とにかく思い描いたものを作りたい!という一心でつくったので、後回しにしたポイントがかなりあります。
速くしたい
ためしてくださったらわかると思うのですが、激遅です。レスポンス激遅だと、誰も触ってくれないと思うので、もっと速くemojiを表示できるように、emoji化の処理をサーバー側に移したり、結果をキャッシュできるようなコードに直したいです。
リファクタリングしたい
殆どjsで書いたのですが、書き方を理解しないまま書き写したりしていたので、ぐちゃぐちゃで、自分でもどこになんの処理があるのかわかりません。せめて、自分でも処理の流れが終えるようなコードに書き直したいです。
精度を上げたい
emojilibのリストから英単語に該当するキーワードを抽出する部分も、単語のフィルタリングを変えればもっと多くのemojiがヒットするようになりそうです。例えば、kuromojiで動詞と判定されたら、動詞の原形を翻訳させることで、よりemojilibに登録されているキーワードにヒットするようになるかもしれません。
おわりに
emoji-translate-jpの実装時の考え方をシェアしてみました。クオリティはともかく、emojiという大好きなものを使って1つ形になるものが作れたことが素直に嬉しいです! ![]() emoji最高! Happy emoji
emoji最高! Happy emoji ![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()