この投稿はクローラー/スクレイピング Advent Calendar 2014の12月25日用です。
199X年。核戦争によって荒廃した時代に、ジャギという男がいた。
「おいお前、普段使っているシェルの名前を言ってみろぉ」
弟ケンシロウに成りすまし、そう言っては、“Bourne Shell”と答えない平民達を虐殺するという悪行を繰り返していた。弟の名に頼り、銃に頼り、人質に頼り、含み針に頼り、そしてガソリンという切り札に頼ったその男は、己の肉体のみで闘う弟によって、無様な最期を遂げた。
さて題名にもあるとおり、この記事は「POSIX原理主義」、つまりUNIX系OS最小インストール時に使えるコマンドだけでスクレイピングします。立派な言語やライブラリーがあったらスゴいスクレイピングができて当たり前。それだと道具がスゴいだけで、「自分はノーアイデアです」と言っているようなものです。
しかしながらスクレイピングというのは、道具一発で片が付くことは稀で、対象データの構造を的確に捉えつつ、いかにウマく道具を活用するかが問われる分野です。
ならば、UNIX系OSの標準ではない道具には一切頼らない、まさに究極のスクレイピングを披露しようじゃありませんか。
お題:ここのAdventCalendarをスクレイピング
さーて、究極と豪語するからには何かデモせねば。何を料理しようかなーと思って選んだのは、この「クローラー/スクレイピング Advent Calendar 2014」のカレンダーです。11/30~1/3まで書き込まれたテーブルがありますね。
こいつをあとあと弄りやすいようにスクレイピングしてみましょ、というわけです。
0)材料
まずは次のものを用意します。
- クローラー/スクレイピング Advent Calendar 2014のHTMLソース…1ファイル
Webブラウザーからソースをコピペしてくるなどして用意します。
それにしても、
<!DOCTYPE html><html xmlns:og="http://ogp.me/ns#"><head><meta charset="UTF-8" /><title>クローラー/スクレイピング Advent Calendar 2014 - Qiita</title><meta charset="UTF-8" /><meta content="width=device-width,height=device-height,initial-scale=1" name="viewport" /><meta content="クローラー/スクレイピングに関する話題ならなんでも誰でも OK な Advent Calendar です。
:
これはスクレイピングのやりがいがありそうな、ごちゃごちゃソースですね。
- UNIX系OS…1ホスト
POSIX、つまりUNIX系とされるOSなら何でもいいです。
- XMLパーサー"parsrx.sh"…1ファイル
POSIXの範囲で書いたシェルスクリプト製のXMLパーサーです。上記のリンクからダウンロードあるいはコピペし、実行ビットを立てておいてください。(このパーサーに関する詳細は→jq、xmllintコマンドさようなら。俺はパイプが好きだからを参照)
1)XMLパーサーに掛ける
POSIXの範囲で使える各種UNIXコマンドで調理するには、まずHTMLデータを行列指向に直さないと始まりません。というわけで、まずはXMLパーサー"parsrx.sh"に掛けましょう。
./parsrx.sh crawler2014.html
すると、「DOM階層」(XPath形式)と「そこの値」という2列から構成されるテキストに置換されます。
/html/@xmlns:og http://ogp.me/ns#
/html/head/meta/@charset UTF-8
/html/head/meta
/html/head/title クローラー/スクレイピング Advent Calendar 2014 - Qiita
/html/head/meta/@charset UTF-8
/html/head/meta
/html/head/meta/@content width=device-width,height=device-height,initial-scale=1
/html/head/meta/@name viewport
/html/head/meta
/html/head/meta/@content クローラー/スクレイピングに関する話題ならなんでも誰でも OK な Advent Calendar です。\nWebからどうやって情報を集めるか、いろいろな方法を共有しましょう。\n\n例:\n\n言語別のクローラー/スクレイピング方法\nノンプログラムで使えるサービス\nやっぱりExcel最高!!\n情報収集に関する注意点(著作権法、岡崎図書館事件)\n
:
/html/body/div/div/div/table/tbody/tr/td/p/a richmikan@github
/html/body/div/div/div/table/tbody/tr/td/p
/html/body/div/div/div/table/tbody/tr/td/p/@class adventCalendar_calendar_entry
/html/body/div/div/div/table/tbody/tr/td/p POSIX原理主義に基づく究極のスクレイピング
:
そしてなるほど、目的のテーブルは/html/body/div/div/div/table/tbodyという階層にあることがわかりますね。
2)目的の表の部分だけに絞り込む
他のDOM部分は要らないのでgrepで除去します。併せて階層のパスが深いので/html/body/div/div/div/table/tbodyの部分は削ってしまいましょう。それからついでに、余計な が混入していますのでそれもとってしまいましょう。
./parsrx.sh crawler2014.html |
grep ^/html/body/div/div/div/table/tbody/tr |
sed 's:/html/body/div/div/div/table/tbody::' | # 深くてウザいので浅く
sed 's/ //g' # がウザいのでトル
/tr/td/@class adventCalendar_calendar_day
/tr/td/p/@class adventCalendar_calendar_date
/tr/td/p 30
/tr/td
/tr/td/@class adventCalendar_calendar_day
/tr/td/p/@class adventCalendar_calendar_date
/tr/td/p 1
/tr/td/div/@class adventCalendar_calendar_join
/tr/td/div/button/@class btn btn-success btn-block js-adventCalendar_button-join
/tr/td/div/button/@data-day 1
:
/tr/td/p/a/i
/tr/td/p/a クローラーをデーモンとして動かす ― Scrapyd
/tr/td/p
:
おっと、データをよーく見まわすと値に半角スペースを含むものがありますね。
~動かす ― Scrapyd
このままだとUNIXでは扱いづらいですね。
3)値としての" "は"_"に置換
UNIXコマンドはデフォルトでは文字列の中に半角スペースがあると面倒なので、とりあえずアンダースコアに変換しておきましょうか。(元の文字と被るのがどうしても嫌というなら、何らかのコントロールコードに変換しておくという技もあるんですけど、まぁここではやりません)
sedで半角スペースのグローバル置換をやった後、先頭のもの(値ではなく列区切りとしての半角スペース)だけ戻してやります。
./parsrx.sh crawler2014.html |
(途中省略) |
sed 's/ /_/g; s/_/ /'
こうするとスペースが階層区切りの部分だけになり、AWK等で簡単に扱えるようになります。
/tr/td/@class adventCalendar_calendar_day
/tr/td/p/@class adventCalendar_calendar_date
/tr/td/p 30
/tr/td
/tr/td/@class adventCalendar_calendar_day
/tr/td/p/@class adventCalendar_calendar_date
/tr/td/p 1
/tr/td/div/@class adventCalendar_calendar_join
/tr/td/div/button/@class btn_btn-success_btn-block_js-adventCalendar_button-join
/tr/td/div/button/@data-day 1
:
/tr/td/p/a/i
/tr/td/p/a クローラーをデーモンとして動かす_―_Scrapyd
/tr/td/p
:
4)階層区切りの"/"を">"に変更
この後の作業でDOM階層文字列部分を正規表現に掛け、値の意味を判定するのですが、"/"だと厄介です。ですから">"という文字に置き換えてしまいましょう。
./parsrx.sh crawler2014.html |
(途中省略) |
awk '{gsub(/\//,">",$1);print;}' # 第1列の"/"だけ全置換する
>tr>td>@class adventCalendar_calendar_day
>tr>td>p>@class adventCalendar_calendar_date
>tr>td>p 30
>tr>td
>tr>td>@class adventCalendar_calendar_day
>tr>td>p>@class adventCalendar_calendar_date
>tr>td>p 1
>tr>td>div>@class adventCalendar_calendar_join
>tr>td>div>button>@class btn_btn-success_btn-block_js-adventCalendar_button-join
>tr>td>div>button>@data-day 1
:
>tr>td>p>a Ruby+Mechanizeで対話型のスクレイピング
>tr>td>p
>tr>td
>tr
>tr>td>@class adventCalendar_calendar_day
>tr>td>p>@class adventCalendar_calendar_date
>tr>td>p 7
:
ところどころに階層だけで値のない行がありますが、これはテーブルの列や行の替わり目です。
5)セル上の行列番号を付加
元のテーブル上で、それが何行目の何列目だったのか印をつけましょう。それには、階層文字列が"td"や"tr"で終わっていて、値を持たない行を見ればいいですね。
./parsrx.sh crawler2014.html |
(途中省略) |
awk 'BEGIN {r=1;c=1; } #
$1==">tr" {r++;c=1; } #
$1==">tr>td"{c++; } #
"at_last" {print r,c,$0;}'
コードにある"at_last"というのは、「各行の処理の最後にここを実行する」ということをコメントするために、私が勝手につけただけなので気になる人は書かなくて構いませんよ。
このコードを通したものがこちらです。このようにして、行頭に行列番号がつくことで各行4列(一部3列)になります。
1 1 >tr>td>@class adventCalendar_calendar_day
1 1 >tr>td>p>@class adventCalendar_calendar_date
1 1 >tr>td>p 30
1 2 >tr>td
1 2 >tr>td>@class adventCalendar_calendar_day
1 2 >tr>td>p>@class adventCalendar_calendar_date
1 2 >tr>td>p 1
1 2 >tr>td>div>@class adventCalendar_calendar_join
1 2 >tr>td>div>button>@class btn_btn-success_btn-block_js-adventCalendar_button-join
1 2 >tr>td>div>button>@data-day 1
:
元の階層文字列を解析すれば、こうやってセルの位置も把握できるんです。行列番号をふっておけば、例えば後になって「3行4列目の中身が見たい」と思ったらgrep '^3 4 'と書けばいいので便利ですよね。
6)値を持たない行はトル
行列番号を付けたら、階層文字列だけで値を持たない行はもう用済みで、後のスクレイピングでは邪魔になるので消してしまいましょう。
./parsrx.sh crawler2014.html |
(途中省略) |
awk 'NF==4'
7)値のうち、単純文字列とリンクに印を付けて抽出
元のカレンダーを眺めると、各セルの中の文字列はその出現順に意味があることが想像つきますね。日にちと著者名(とそのリンク)、記事名(とそのリンク)が欲しいわけですが、とりあえず各セルの中での出現順によって判定できそうです。
ですからここでは、各セル内で文字列とリンク(hrefプロパティー)の登場順に印を付けていくことにしましょう。
./parsrx.sh crawler2014.html |
(途中省略) |
awk '$1!=r0||$2!=c0 { #
str_n=1; #
lnk_n=1; } #
$3==">tr>td>p>a>@href" { #
$3="lnk" lnk_n; #
print; #
lnk_n++; } #
$3^>tr>td>p([a-z>]*)?$/{ #
$3="str" str_n; #
print; #
str_n++; } #
"at_last" { #
r0=$1; #
c0=$2; }'
上記のコードを通したものが次のテキストです。セルの中で実際に表示される文字列には"str n "という印を、リンク(hrefプロパティー)文字列には"lnk n "という印を、階層パスと置き換えるかたちでつけてあります。
1 1 str1 30
1 2 str1 1
1 3 str1 2
1 3 lnk1 /dkfj
1 3 str2 dkfj
1 3 lnk2 http://blog.takuros.net/entry/2014/12/02/234959
1 3 str3 スクレイピングのお仕事について
1 4 str1 3
1 4 lnk1 /nezuq
1 4 str2 nezuq
:
なんだか、規則性が見えてきましたね。
8)日にち,著者名,著者URL,記事名,記事URLを横一列化
上記のテキストを見ると
| 印 | 意味 |
|---|---|
| str1 | 日にち |
| str2 | 著者名 |
| lnk1 | 著者リンク |
| str3 | 記事名 |
| lnk2 | 記事リンク |
となっていることがわかります。ですからこれを横一列に並べ、1つのセルが1行になるようにしましょう。
行列番号が同じ間、値を読み込み、行列番号が替わったところで横一列に書き出せばよいですね。また、セルによっては存在しない項目もありますので、デフォルト文字列として"-"を設定しておくことにしましょう。
./parsrx.sh crawler2014.html |
(途中省略) |
awk '$1!=r0||$2!=c0 { #
print r0,c0,day,aut,aln,ttl,tln; #
day="-"; aut="-"; aln="-"; ttl="-"; tln="-";} #
$3=="lnk1"{aln=$4; } #
$3=="lnk2"{tln=$4; } #
$3=="str1"{day=$4; } #
$3=="str2"{aut=$4; } #
$3=="str3"{ttl=$4; } #
"at_last"{r0=$1; c0=$2; } #
END {print r0,c0,day,aut,aln,ttl,tln; }'
横一列が長くなってしまって見にくいかもしれませんが、これでOKです。
1 1 30 - - - -
1 2 1 - - - -
1 3 2 dkfj /dkfj スクレイピングのお仕事について http://blog.takuros.net/entry/2014/12/02/234959
1 4 3 nezuq /nezuq Webスクレイピングの法律周りの話をしよう! /nezuq/items/3cc9772118ad112c18dc
1 5 4 shogookamoto /shogookamoto 普及して欲しくないアンチスクレイピングサービス http://happyou-info.hatenablog.com/entry/2014/12/04/005504
1 6 5 dkfj /dkfj Ruby+Nokogiriでスクレイピング http://blog.takuros.net/entry/2014/12/05/061034
1 7 6 dkfj /dkfj Ruby+Mechanizeで対話型のスクレイピング http://blog.takuros.net/entry/2014/12/06/235232
2 1 7 orangain /orangain Pythonでクローリング・スクレイピングに使えるライブラリいろいろ http://orangain.hatenablog.com/entry/scraping-in-python
2 2 8 dkfj /dkfj クローラー/スクレイピングのWebサービス 「Kimono」のユースケース http://blog.takuros.net/entry/2014/12/08/100216
2 3 9 sue445 /sue445 ccc_privacy_bot_を支える技術 http://sue445.hatenablog.com/entry/2014/12/09/000000
AWKを使えば、「2行1列目の記事名」とか「14日を担当している著者名とそのリンク」なんていう指定も簡単です。
awk '$1==2 && $2==1 {print $6}'
awk '$3==14 {print $4,$5}'
9)CSVにする
ここまでで終わりでもいいのですが、Excelに持っていきたいなんてことがあるかもしれないですね。ということで、さらにCSV化(RFC 4180)してみましょう。
行列番号がついていますから、それを見ながら適宜カンマと改行を挿み、値をダブルクォーテーションで囲んで出力します。
さらに、Excelに持っていくには、文字コードと改行コードを各々Shift_JIS、CR+LFに合わせておく必要がありますので、変換も掛けておきます。
./parsrx.sh crawler2014.html |
(途中省略) |
sed 's/"/""/g' |
awk '$1!=r0{printf("\n"); } #
$2>1 {printf("," ); } #
"at_last" { #
printf("\"%s\n%s\n%s\n%s\n%s\"",$3,$4,$5,$6,$7); #
r0=$1; #
c0=$2; }' |
awk 'NR>5' |
iconv -f UTF8 -t SJIS |
sed "s/\$/$(printf '\r')/" > crawler2014.csv
こうしてできたファイルをExcelで開いたものがこちらです。
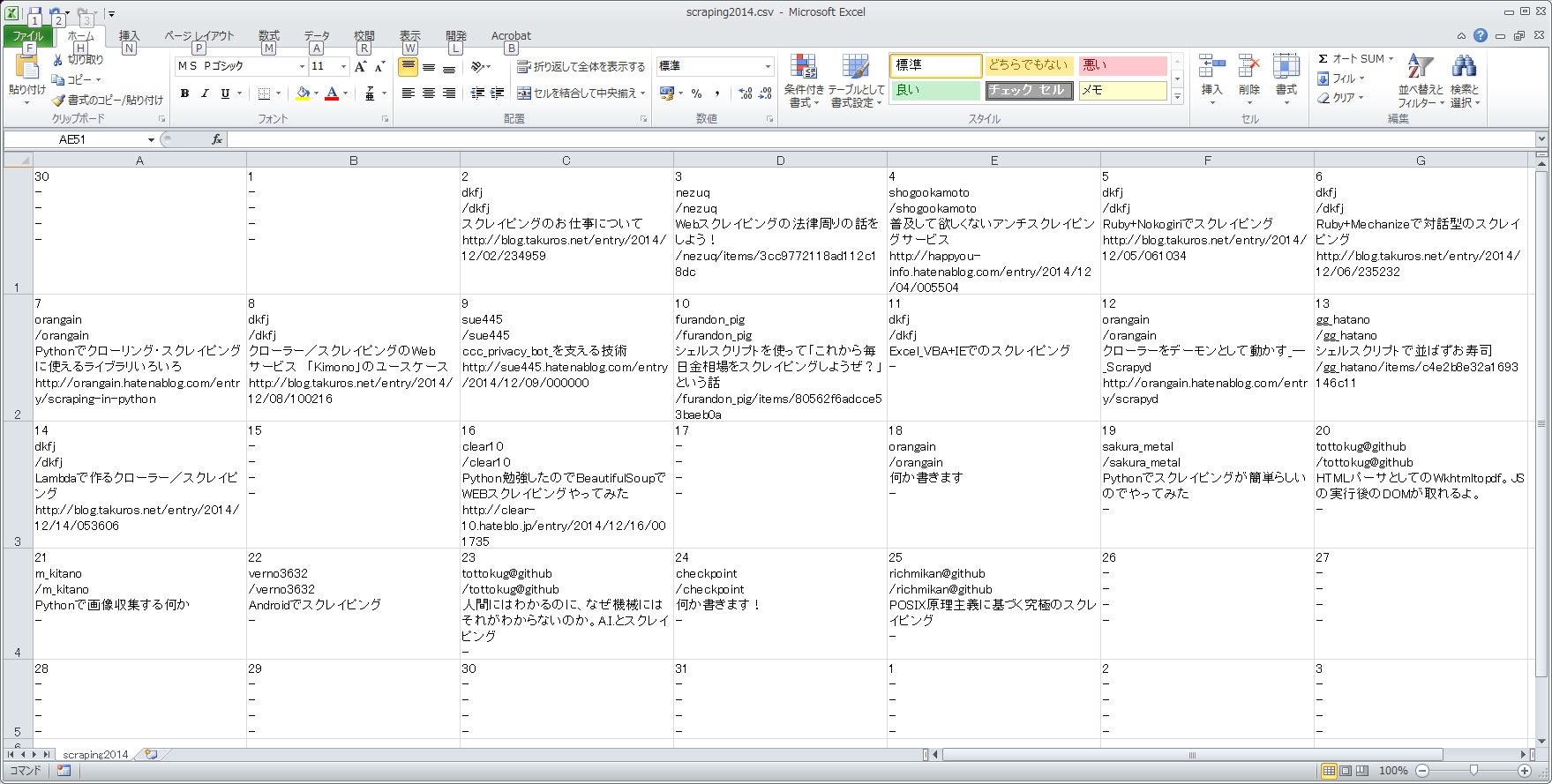
できあがり
ここまでのコードをまとめると、こうなります。
# === 1)HTMLパース ====================================== #
./parsrx.sh crawler2014.html |
# 1:値のパス 2:値文字列 #
# #
# === 2)表の部分だけに絞り込む ========================== #
grep ^/html/body/div/div/div/table/tbody/tr |
sed 's:/html/body/div/div/div/table/tbody::' | # 深くてウザいので浅く
sed 's/ //g' | # がウザいのでトル
# #
# === 3)値としての" "は"_"に置換 ======================== #
sed 's/ /_/g; s/_/ /' |
# #
# === 4)階層の"/"がウザいので">"に変更 ================== #
awk '{gsub(/\//,">",$1);print;}' |
# #
# === 5)セル上の行列番号を付加 ========================== #
awk 'BEGIN {r=1;c=1; } #
$1==">tr" {r++;c=1; } #
$1==">tr>td"{c++; } #
"at_last" {print r,c,$0;}' |
# 1:行番号 2:列番号 3:値のパス 4:値文字列(あれば) #
# #
# === 6)値を持たない行はトル ============================ #
awk 'NF==4' |
# 1:行番号 2:列番号 3:値のパス 4:値文字列 #
# #
# === 7)値のうち,単純文字列とリンクに印を付けて抽出 ===== #
awk '$1!=r0||$2!=c0 { #
str_n=1; #
lnk_n=1; } #
$3==">tr>td>p>a>@href" { #
$3="lnk" lnk_n; #
print; #
lnk_n++; } #
$3^>tr>td>p([a-z>]*)?$/{ #
$3="str" str_n; #
print; #
str_n++; } #
"at_last" { #
r0=$1; #
c0=$2; }' |
# 1:行番号 2:列番号 3:値の種別と出現番号 4:値文字列 #
# #
# === 8)日にち,著者名(URL),記事名(URL)を横一列化 ======== #
awk '$1!=r0||$2!=c0 { #
print r0,c0,day,aut,aln,ttl,tln; #
day="-"; aut="-"; aln="-"; ttl="-"; tln="-";} #
$3=="lnk1"{aln=$4; } #
$3=="lnk2"{tln=$4; } #
$3=="str1"{day=$4; } #
$3=="str2"{aut=$4; } #
$3=="str3"{ttl=$4; } #
"at_last"{r0=$1; c0=$2; } #
END {print r0,c0,day,aut,aln,ttl,tln; }' |
# 1:行番号 2:列番号 3:日にち 4:著者 5:著者URL 6:記事名 7:記事URL
# #
# === 9)CSVにする ======================================= #
sed 's/"/""/g' |
awk '$1!=r0{printf("\n"); } #
$2>1 {printf("," ); } #
"at_last" { #
printf("\"%s\n%s\n%s\n%s\n%s\"",$3,$4,$5,$6,$7); #
r0=$1; #
c0=$2; }' |
awk 'NR>5' |
iconv -f UTF8 -t SJIS |
sed "s/\$/$(printf '\r')/" > crawler2014.csv
1コマンドをプログラムの1ステップにするのがUNIXの美学
このプログラムを見てどうですか?パイプ"|"で15個ものコマンドを繋げていますが、UNIXコマンドをそんな使い方した事ない人から見ると、変態に思えるかもしれませんね。さらに言うと、冒頭で呼んでるXMLパーサー"parsrx.sh"の中では同様にしてコマンドを26個繋げていて、もっと変態に映るかもしれません。
しかし、UNIXとは本来こういうやり方によって物事を解決していく「ツール」なのです。他のプログラムで言うところの、1ステップが1コマンドに対応しているようなものです。AWKを使って1コマンドが巨大になっている箇所がいくつかありますが、もしウマいコマンドがあるならこれらもより単純なコマンドに分解するのが理想です。
するとどうなるかというと、プログラムが上から下へ素直に読めるようになります。パイプで繋がれたコマンドを流れるデータの流れは一方向なので当然そうなります。これによってメンテナンス性が飛躍的に向上するのです。
読みやすいですし、間にteeコマンドを挿めば、途中を流れるデータを覗き見ることもできてデバッグもやりやすいです。しかも各コマンドは、独立したプロセスで動くので勝手にマルチプロセス化もされ、マシンのコアが増えれば増えるほど高速化されます。ビ、ビッグデータも怖くないんだからねっ。
究極とはこういうことさ
どーですか、POSIXの実力は?「Unix系OSを最小限インストールした状態で使えるコマンドだけ」という誰しもが認めざるを得ない最小限の道具で、しかも高い効果を得る。これを究極と言わずして何という!
究極のスクレイピングツールは何でしょうか?
と、人に問われたら、返すべき答えは、
UNIX
です。ジョークでもなんでもありません。
極力POSIXで闘う本、コミケで頒布します
最後に宣伝。こんなふうにして(極力)POSIXのみで闘う薄い本を、コミケで頒布します。気になる人は、**12/30 西2ホール い-33aにて「Shell Script ライトクックブック2014」**を見てくださいませ。