Orchestratorというツールを最近知り、MHAやmysqlfailoverのような自動フェールオーバーができるということで試してみました。
Orchestratorとは
MySQL、及びMariaDBやPerconaServer等のMySQL互換のDBのレプリケーション構成(Replication topology)を管理するツールで、レプリケーション構成の分析・ビジュアライズ、スレーブの付け替え、自動フェールオーバーなどの機能があります。Perconaのエコシステム(PMM)にもexperimentalながら採用されたり、GitHubのバックエンドでも活躍しているそうです。
中〜大規模、あるいは複雑なレプリケーション構成のクラスタを管理しやすくするためのツール、といった感じです。以下のような機能・特徴があります。
- GTID, 非GTID(binlog file:pos)いずれのレプリケーションにも対応
- GUIやCLIでレプリケーションの構成変更が行える(Refactoring)
- マスターの自動フェールオーバー(Recovery)
- レプリケーショントポロジーをクロールすることで、管理対象の登録が簡単に行える(Discovery)
- GUI, CLI, HTTP APIが用意されている
他にも様々な機能があります。
GUIデモ
GUIデモがこちらで公開されているので、なんとなく雰囲気がつかめます。
デザインもいい感じ!
Orchestratorによる高可用化(Recovery)
OrchestratorのRecovery機能は、MHAやmysqlfailoverのように、マスターがダウンした時に自動的にスレーブをマスターに昇格させる機能です。昇格させる際には log-slave-updatesの状態など、マスター昇格できるものかどうかを判定し、可能なものの中から最新のものを選択します。
Semi-Syncレプリケーションにも対応しているので、データロスのリスクを抑えて短時間でのフェールオーバーが可能です。
MHAやmysqlfailoverと比較した特徴を挙げてみます。
- GTID, 非GTIDで動作する
- 特別なAgentは不要(orchestrator-agentというものもオプショナルであるが、Recoveryには不要)
- フェールオーバー発生後、再度セットアップする必要がない
- 複数のクラスタを監視できる
- 冗長化できる(複数動作させても正常に動作する)
- 状態をMySQLに保存するため、Orchestrator用のMySQLインスタンスが必要になる
また、誤検知による暴発のリスクをなるべく抑えるため、単純にマスターだけを監視するのではなくレプリケーショントポロジー全体の状態から判断してダウンを検知する仕組みが実装されています。
たとえばデータセンターをまたいでレプリケーションしているようなケースで、Orchestratorからマスターへのネットワークに障害が発生し、スレーブには正常につながる場合、スレーブのレプリケーションに異常がないかなどの情報もダウンの判断条件とすることで、誤検知を防ぐことができます。
他にも一度フェールオーバーが発生したら一定時間はフェールオーバーをさせない設定や、フェールオーバー後にmasterが復帰した時の挙動(再度リマスターするかどうか)の設定も用意されています。
Orchestrator自体の冗長化については公式ドキュメントを参考にすると、Orchestrator用のDBをマルチマスター(Galera/XtraDB,グループレプリケーション等)にして、HaProxy経由でOrchestratorからアクセスすれば良いとのことです。
フェールオーバーを試す
Orchestratorを使っての高可用化を試してみます。
Orchestratorはレプリケーションの再構築までしか行わないので、アプリケーションからのルーティング対策はフェールオーバーのイベントをフックして自分たちで行う必要があります。今回はマスターのVIPの付け替えまでやることにします。
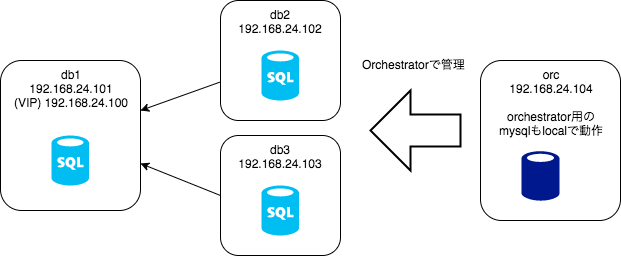
以下のように1マスター2スレーブのシンプルな構成で試します。
今回はVagrantでCentOSのVMを用意して試しました。db1〜db3に管理対象のMySQLを立て、orcでOrchestratorを動かします。
1. Orchestratorのインストール
orcサーバーにOrchestratorをインストールします。
1-1. Orchestrator用のMySQLを用意する
Orchestratorは自身が管理するデータをMySQLに保存します。orcにもMySQLをインストールしてOrchestratorのためのユーザーとテーブルを用意します。
mysql> CREATE DATABASE IF NOT EXISTS orchestrator;
mysql> GRANT ALL PRIVILEGES ON `orchestrator`.* TO 'orc_server'@'%' IDENTIFIED BY 'orc_server_pass';
1-2. Orchestratorをインストール
GitHubのReleasesページからダウンロードしてインストールします。rpmが用意されているのでそれを利用しました。
sudo yum install https://github.com/github/orchestrator/releases/download/v2.1.2/orchestrator-2.1.2-1.x86_64.rpm
1-3. 設定ファイル
/etc/orchestrator.conf.jsonに以下のような内容で設定ファイルを作成します。
{
"ListenAddress": ":3000",
"AuthenticationMethod": "",
"MySQLTopologyUser": "orc_client",
"MySQLTopologyPassword": "orch_client_pass",
"MySQLOrchestratorHost": "127.0.0.1",
"MySQLOrchestratorPort": 3306,
"MySQLOrchestratorDatabase": "orchestrator",
"MySQLOrchestratorUser": "orc_server",
"MySQLOrchestratorPassword": "orc_server_pass",
"RecoveryPollSeconds": 10,
"RecoverMasterClusterFilters": [
".*"
],
"PostMasterFailoverProcesses": [
"sudo -u orchestrator /usr/local/orchestrator/failover.sh {failureType} {failureClusterAlias} {failedHost} {successorHost} >> /tmp/orc_failover.log"
],
"ApplyMySQLPromotionAfterMasterFailover": true
}
-
AuthenticationMethodはWebGUIの認証方法。Basic認証などが利用できますが今回は認証なしにしておきます -
MySQLTopologyUserとMySQLTopologyPasswordは管理対象のMySQL(db1〜db3)にアクセスするためのログイン情報 -
MySQLOrchestratorXXXXは先ほどセットアップしたOrchestrator自身が利用するMySQLの情報 -
RecoveryPollSecondsはダウン判定の間隔です -
RecoverMasterClusterFiltersはフェールオーバーの監視対象にするクラスタ名のフィルタリング条件を正規表現で指定します。すべてを対象という条件にします(今回は1クラスタしかありませんが)。 -
PostMasterFailoverProcessesはフェールオーバー後に行うアクションを指定します。(複数指定可能)。後ほど説明するフェールオーバースクリプトを実行します。 -
ApplyMySQLPromotionAfterMasterFailoverをtrueにすると、フェールオーバー後に旧マスターが復帰してしまった時、read_onlyにしてレプリケーショントポロジーから除外します。
Recovery Hooks
設定ファイルでは、PostMasterFailoverProcesses以外にも、フェールオーバーが実行される際の各プロセスにイベントをフックすることができます。
-
OnFailureDetectionProcesses: ダウン検知直後に呼ばれます。フェールオーバーを実行するかどうか決定する前。 -
PreFailoverProcesses: フェールオーバーを実行することが決まった直後に呼ばれます。ここで実行されるスクリプトでnon-zeroが変える場合、フェールオーバーは中断されます。これ以降のフックでフェールオーバーを止めることはできません。 -
PostIntermediateMasterFailoverProcesses: 中間マスター(スレーブでもありスレーブを持つマスターでもあるノード)のフェールオーバー実施後に呼ばれます。 -
PostMasterFailoverProcesses: マスターのフェールオーバー実施後に呼ばれます。 -
PostFailoverProcesses: (ノードの種類に関わらず)フェールオーバー実施後に呼ばれます。 -
PostUnsuccessfulFailoverProcesses: フェールオーバーが失敗した時に呼ばれます。
イベントフックのスクリプトには様々なパラメータが渡せます。
{failureType}, {failureDescription}, {failedHost}, {failedPort}, {failureCluster},
{failureClusterAlias}, {failureClusterDomain}, {countReplicas}または{countSlaves}, {isDowntimed}, {autoMasterRecovery}, {autoIntermediateMasterRecovery}, {orchestratorHost},
{lostReplicas}または{lostSlaves}, {replicaHosts} aka {slaveHosts}, {isSuccessful}
1-4. 起動
sudo /etc/init.d/orchestrator start
systemd用の設定もこちらに用意したのでお好みでどうぞ。
起動の確認
http://192.168.24.104:3000/をブラウザで開くと、GUIが表示されます。まだ何もクラスタを登録していないためNo clusters foundと表示されています。
2. 管理対象のMySQLクラスタを用意
db1〜db3にMySQLをインストールします。
2-1. MySQLの設定
最初はdb1をマスターにしますが、db2,db3もフェールオーバーによりマスターに昇格可能なように、log-slave-updatesを設定しておきます。今回は設定が簡単なのでGTIDで試しました。
[mysqld]
log-bin
log-slave-updates
server-id=1 # インスタンスごとに変える
gtid-mode=ON
enforce-gtid-consistency
:
2-2. レプリケーションを開始する
レプリケーションユーザーを追加し、レプリケーションを開始します。
mysql> GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%' IDENTIFIED BY 'repl';
mysql> CHANGE MASTER TO
MASTER_HOST='db1',
MASTER_PORT=3306,
MASTER_USER='repl',
MASTER_PASSWORD='repl',
MASTER_AUTO_POSITION=1;
mysql> START SLAVE;
2-3. Orchestratorのためのセットアップ
Orchestratorがクラスタを監視できるようにユーザーを作成します。ユーザー名とパスワードはOrchestratorの設定ファイルと合わせます。
mysql> GRANT SUPER, PROCESS, REPLICATION SLAVE, RELOAD ON *.* TO 'orc_client'@'%' IDENTIFIED BY 'orch_client_pass';
mysql> GRANT SELECT ON mysql.slave_master_info TO 'orc_client'@'%';
2-4. VIPの設定
マスターを示すVIPを、db1に設定します。アプリケーションからはこのアドレスでマスターに接続する想定です。
sudo -n ip address add 192.168.24.100/24 dev enp0s8
3. Orchestratorにクラスタを登録する
GUIからDisoveryメニューを選択肢登録します。db1だけ指定すれば、残りのノードは自動で見つけ出して登録してくれます。
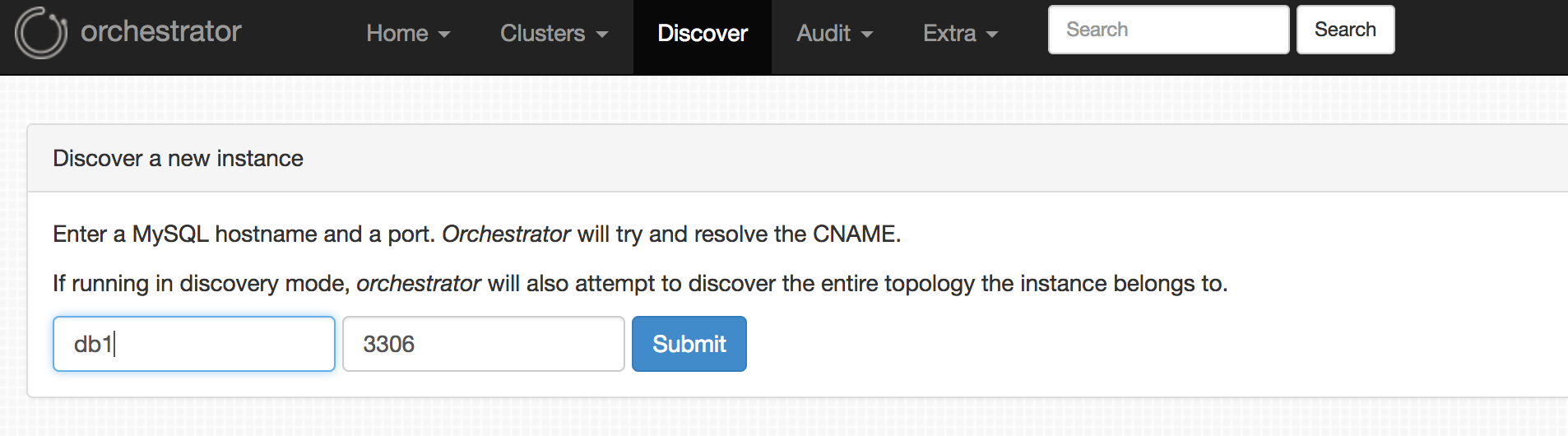
WebAPIでも登録できます。WebAPIやCLIは、AnsibleやChef等からも利用できるので嬉しいですね。
curl http://orc:3000/api/discover/db1/3306
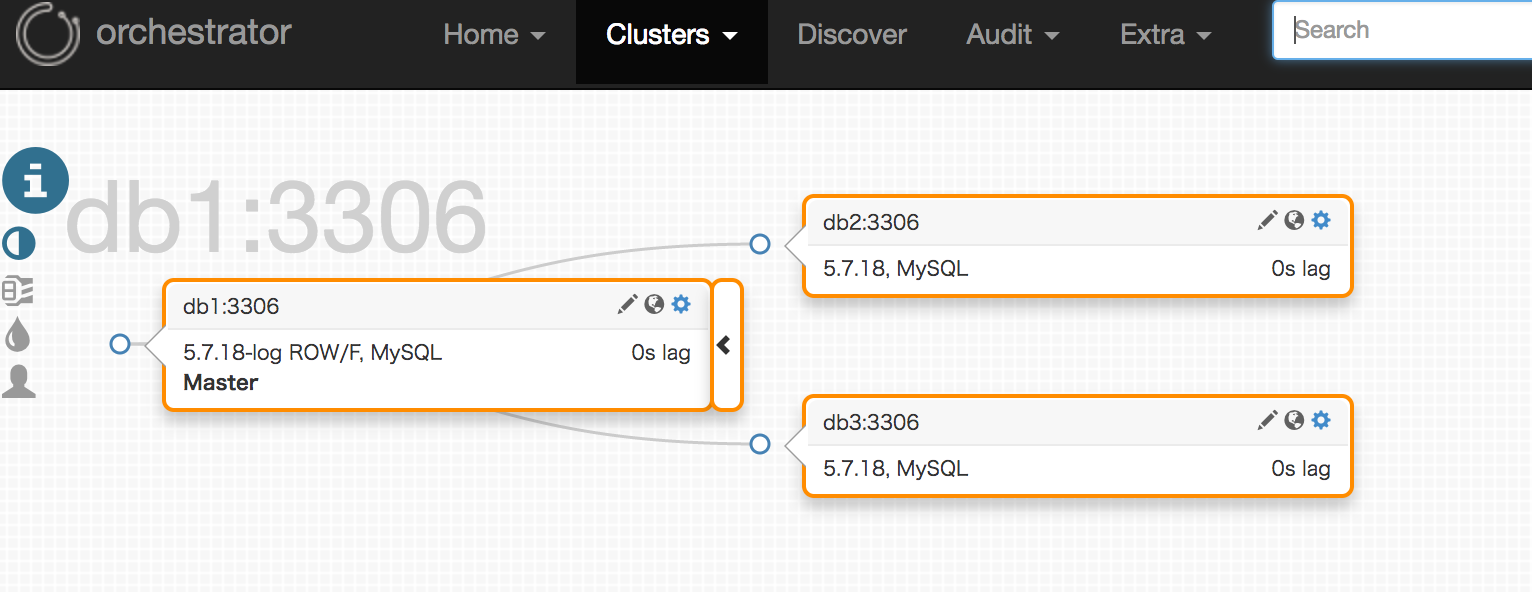
Clusters -> Dashboard を開くと登録できたことがわかります。![]() アイコンを押すと様々な状態を確認できます。
アイコンを押すと様々な状態を確認できます。
4. フェールオーバーの準備
Orchestratorがやってくれるのはレプリケーション構成の変更までです。マスターのVIPの付け替えは自分で行う必要があります。このステップはそのための準備を行います。
VIP付け替え以外の方法(ロードバランサー,サービスディスカバリやDNSなど)でももちろん可能ですので、その場合はそれぞれのやり方に従いセットアップし、次のステップに進んでください。
4-1. orchesratorユーザーを作成する
VIPの付け替えはsshして行うため、あらかじめorcからdb1〜db3に鍵認証でsshできるユーザーを作成しておきます。ユーザー名はorchestratorとしました。
またsudoが必要になるので、requirettyを不要とするsudoer設定も行なっておきます。
sudo vi /etc/sudoers.d/orchestrator
Defaults !requiretty
orchestrator ALL=(ALL) NOPASSWD: /usr/sbin/arping,/sbin/ip
4-2. フェールオーバースクリプトを用意する
設定ファイルでフェールオーバー時のアクションを指定することができるので、そこでVIP付け替えスクリプトを叩きます。
"PostMasterFailoverProcesses": [
"sudo -u orchestrator /usr/local/orchestrator/failover.sh {failureType} {failureClusterAlias} {failedHost} {successorHost} >> /tmp/orc_failover.log"
],
(注) 今回はOrchestratorをrootで動かしているのでsudo -u orchestrator としています。root権限でなくても動作できるので、initスクリプトを修正するなどして動作ユーザーを変えるのが本当はよいかと思います。systemd用の設定ファイルを参考までに。
スクリプトは以下のようなものを用意しました。複数のクラスタを監視している場合は、 {failureClusterAlias} でクラスタを判定してVIPを選択するといったことができそうです。
#!/bin/bash
original_master=$3
new_master=$4
ssh_user=orchestrator
vip_eth=enp0s8
vip=192.168.24.100
vip_mask=24
echo "Down VIP on $original_master"
ssh -o ConnectTimeout=5 -o StrictHostKeyChecking=no $ssh_user@$original_master "sudo -n /sbin/ip address delete $vip/$vip_mask dev $vip_eth"
echo "Up VIP on $new_master"
ssh -oStrictHostKeyChecking=no $ssh_user@$new_master "sudo -n /sbin/ip address add $vip/$vip_mask dev $vip_eth"
echo "Refresh arp"
ssh -oStrictHostKeyChecking=no $ssh_user@$new_master "sudo /sbin/arping -q -c 3 -A $vip -I $vip_eth"
5. マスターをダウンさせてみる
テスト用のテーブルを用意してクエリを投げ続けておきます。
mysql> CREATE DATABSE test;
mysql> CREATE TABLE test.tbl(id INT(11) NOT NULL AUTO_INCREMENT PRIMARY KEY);
mysql> GRANT ALL PRIVILEGES ON `test`.* TO 'test'@'%' IDENTIFIED BY 'test';
mysql -h 192.168.24.100 -utest -ptest -e 'INSERT INTO test.tbl VALUES ();'
マスターを殺します。
sudo systemctl stop mysqld
即座にクエリが失敗し続けますが、しばらくするとフェールオーバーが動作し正常に戻ります。
Orchestratorのログもにわかに騒がしくなります。
2017-05-18 01:04:31 ERROR dial tcp 192.168.24.101:3306: getsockopt: connection refused
2017-05-18 01:04:31 ERROR ReadTopologyInstance(db1:3306): dial tcp 192.168.24.101:3306: getsockopt: connection refused
2017-05-18 01:04:31 INFO topology_recovery: will handle DeadMaster event on db1:3306
2017-05-18 01:04:31 INFO topology_recovery: running 0 PreFailoverProcesses hooks
2017-05-18 01:04:31 INFO topology_recovery: done running PreFailoverProcesses hooks
2017-05-18 01:04:31 INFO topology_recovery: RecoverDeadMaster: will recover db1:3306
2017-05-18 01:04:31 INFO topology_recovery: RecoverDeadMaster: masterRecoveryType=MasterRecoveryGTID
2017-05-18 01:04:31 INFO topology_recovery: RecoverDeadMaster: regrouping replicas via GTID
2017-05-18 01:04:32 INFO Stopped slave nicely on db3:3306, Self:db3-bin.000006:20731, Exec:db1-bin.000013:2898
2017-05-18 01:04:32 INFO Stopped slave nicely on db2:3306, Self:db2-bin.000005:8678, Exec:db1-bin.000013:2898
2017-05-18 01:04:32 INFO Stopped slave on db3:3306, Self:db3-bin.000006:20731, Exec:db1-bin.000013:2898
2017-05-18 01:04:32 INFO Stopped slave on db2:3306, Self:db2-bin.000005:8678, Exec:db1-bin.000013:2898
2017-05-18 01:04:32 INFO Will move 1 replicas below db3:3306 via GTID
2017-05-18 01:04:32 INFO Will move db2:3306 below db3:3306 via GTID
2017-05-18 01:04:32 INFO Stopped slave on db2:3306, Self:db2-bin.000005:8678, Exec:db1-bin.000013:2898
2017-05-18 01:04:32 INFO ChangeMasterTo: Changed master on db2:3306 to: db3:3306, db3-bin.000006:20731. GTID: true
2017-05-18 01:04:32 INFO Started slave on db2:3306
2017-05-18 01:04:32 INFO Started slave on db3:3306
2017-05-18 01:04:33 INFO topology_recovery: RecoverDeadMaster: 0 postponed functions
2017-05-18 01:04:33 INFO topology_recovery: promoted replica: db3:3306
2017-05-18 01:04:33 INFO topology_recovery: checking if should replace promoted replica with a better candidate
2017-05-18 01:04:33 INFO topology_recovery: RecoverDeadMaster: successfully promoted db3:3306
2017-05-18 01:04:33 INFO topology_recovery: - RecoverDeadMaster: will apply MySQL changes to promoted master
2017-05-18 01:04:33 INFO Will reset replica on db3:3306
2017-05-18 01:04:33 INFO Stopped slave on db3:3306, Self:db3-bin.000006:20731, Exec:db1-bin.000013:2898
2017-05-18 01:04:33 INFO Reset slave db3:3306
2017-05-18 01:04:33 INFO instance db3:3306 read_only: false
2017-05-18 01:04:33 INFO topology_recovery: running 1 PostMasterFailoverProcesses hooks
2017-05-18 01:04:33 INFO topology_recovery: running PostMasterFailoverProcesses hook #0
2017-05-18 01:04:33 INFO CommandRun(sudo -u orchestrator /usr/local/orchestrator/failover.sh DeadMaster db1:3306 db1 db3 >> /tmp/orc_failover.log,[])
2017-05-18 01:04:33 INFO CommandRun/running: bash /tmp/orchestrator-process-cmd-379082042
2017-05-18 01:04:36 INFO CommandRun successful. exit status 0
2017-05-18 01:04:36 INFO Executed PostMasterFailoverProcesses command: sudo -u orchestrator /usr/local/orchestrator/failover.sh DeadMaster db1:3306 db1 db3 >> /tmp/orc_failover.log
GUIで確認するとdb3がマスターになり、db2のレプリケーション先がdb3に変わっていることが確認できます。
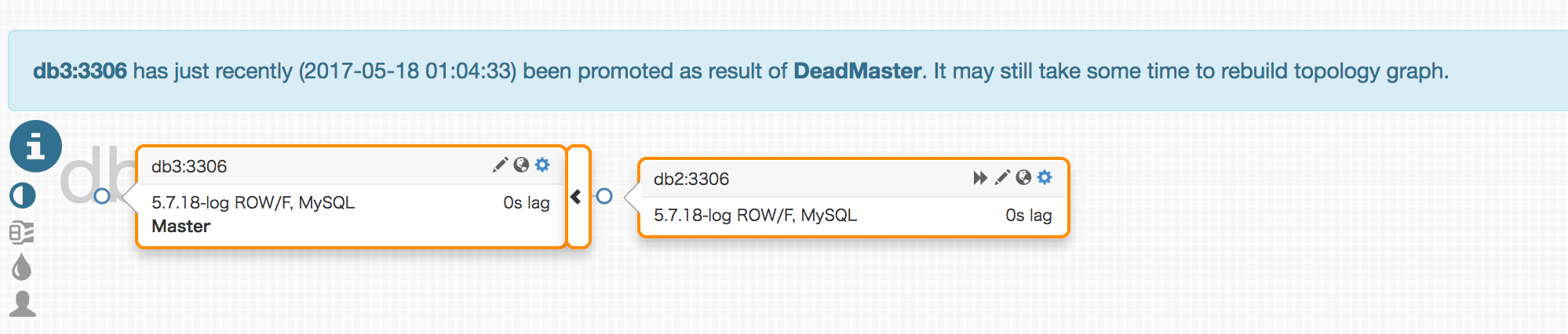
実際にMySQL Serverに入って確かめてみます。
mysql> show slave status \G;
Empty set (0.01 sec)
mysql> show slave status \G;
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: db3
Master_User: repl
Master_Port: 3306
:
無事フェールオーバーが成功しました!
なお、このクラスタはこの後1時間はdb3がダウンしてもフェールオーバーは実行されません(暴発防止機能)。この時間はRecoveryPeriodBlockSecondsの設定によって決まります(デフォルトが3600)。
所感
MHAと比べるとOrchestrator用のMySQLが必要ということで若干大掛かりな気もしますが、エージェントが不要だったり、再セットアップがいらないなど優位な面もあります。中〜大規模なクラスタ向けではあるようですが、小規模なクラスタでも、フェールオーバーの機能を使うためだけに導入するのはよさそうと感じました。