2017/01/31に発生したGitLabのインシデントについて、2017/02/01にGitLab.com Database Incidentというブログ記事が投稿されました。
こちらの記事の英検3級的ゆるふわ和訳です。プルリク待ち。
公開から色々追記しているようで、時折時系列がおかしいところがあります。
時刻は全てUTCです。
GitLab.com Database Incident
昨日、データベースに深刻な事故が発生した。
GitLab.comのデータ(issue、マージリクエスト、ユーザ、コメント、スニペット他)が6時間分失われたよ。
GitとWikiのリポジトリ、自己ホスティングサービスのインスタンスは影響を受けないよ。
データを失うことは容認できることではないので、近いうちに何故このような事態が発生したのか、再発させないための対策リストを発表するよ。
Update 6:14pm UTC: GitLab.com is back online
この記事を書いてる時点では、6時間前のバックアップからデータベースを復元しようとしてるよ。
すなわち、午後5:20から11:25までのデータ(project、issue、マージリクエスト、ユーザ、コメント、スニペット他)は、GitLab.comが復旧した際には失われるよ。
Git data (repositories and wikis) and self-hosted instances of GitLab are not affected.
要約についてはここから下に記載するよ。
死刑宣告書も読めるよ。
First Incident
2017/01/31午後6時、あるスパマーがスニペットを使ってデータベースに大量アクセスし、そのせいでデータベースが不安定になってることを発見したよ。
我々はトラブルシューティングを行い、問題の内容と対策方法を調査したよ。
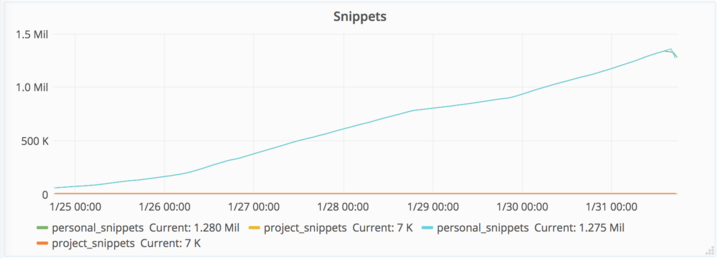
2017/01/31午後9時、スパムのアクセスはさらにエスカレートし、データベース書き込みにロックアップが発生し、それがダウンタイムを引き起こしたよ。
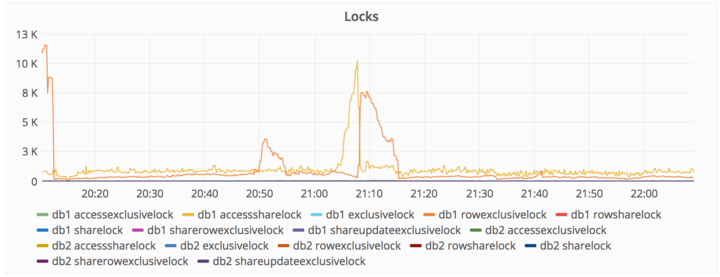
Actions taken
・スパマーのIPアドレスをブロックした。
・47000のIPアドレスを使って同一IDでアクセスしてきていたCDNを排除した。
・スニペットを作成して、スパムユーザを削除した。
Second Incident
2017/01/31午後10時、DBのレプリケーションが遅すぎたせいで止まったよ。
大量のデータが登録されたから、セカンダリデータベースでリアルタイム処理しきれなかったせいだよ。
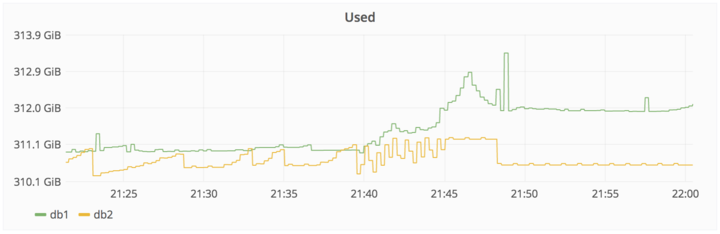
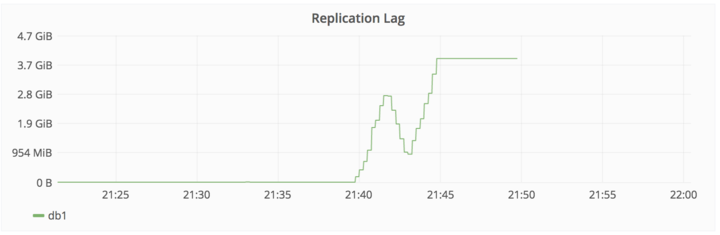
Actions taken
・db2を修正しようと思ったけど、この時点ですでに4GBの遅れが出ていた。
・db2.clusterでレプリケーションがエラーになったから、再度クリーンなレプリケーションをしようと/var/opt/gitlab/postgresql/dataを削除した。
・db2.clusterはmax_wal_sendersが少ないとdb1に接続拒否された。max_wal_sendersはスレーブサーバからの同時接続数上限を表す。
・チームメンバー1はdb1でmax_wal_sendersを32に設定してPostgreSQLを再起動した。
・PostgreSQLは、セマフォの使用数が多すぎるとして再起動を拒否した。
・チームメンバー1はmax_connectionsを2000から8000にしてPostgreSQLを再起動した。
・db2.clusterは接続エラーこそ出さなくなったが、レプリケーションは相変わらず動かない。何も言わずにハングアップする。
・不満が募り始める。チームメンバー1は、23時に帰る予定だったが、この問題が発生したせいでそれどころではなくなったと発言した。
Third Incident
017/01/31午後11時、チームメンバー1は、pg_basebackupが失敗するのは、db2にデータディレクトリが存在するせいではないかと思いついたよ(すでに空だったけど)。
そこでデータディレクトリを削除しようと決意したよ。
彼はそのコマンドを実行した数秒後に、db2.cluster.gitlab.comではなくdb1.cluster.gitlab.comでそれを実行したことに気がついたよ。
017/01/31午後11:27分、チームメンバー1は削除コマンドを中断した。
だが、それはあまりにも遅かった。
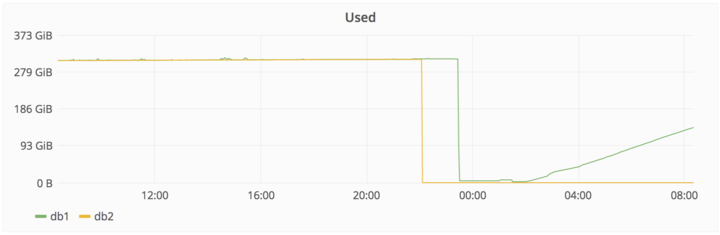
300GBのデータのうち、わずか4.5GBしか残っていなかった。
我々はGitLab.comを停止しなければならず、Twitterでこの情報を共有した。
We are performing emergency database maintenance, https://t.co/r11UmmDLDE will be taken offline
— GitLab.com Status (@gitlabstatus) 2017年1月31日
Problems Encountered
・LVMのスナップショットは、デフォルトでは24時間に一回実行される。
チームメンバー1は、データベースのロードバランシング作業を行っていたため、たまたま6時間前に手動でバックアップしてた。
・デフォルトのバックアップは24時間に一回動いてるように見えたが、チームメンバー1は、バックアップが何処にあるかわからなかった。
チームメンバー2が確認したところ、数バイトのファイルしか生成されておらず、まともに動いてるようには見えなかった。
・チームメンバー3の調査結果。
pg_dumpがPostgreSQL9.6ではなく9.2で動作してるせいでバックアップに失敗しているようだ。
サーバ側のPostgreSQLは9.6で動作しているが、pg_dumpはそれを使わず自前の9.2でバックアップを実行しようとしている。
その結果バージョン違いによりpg_dumpは何もエラーを出さずに失敗し、SQLダンプは生成されていなかった。
またFog gemが古いバックアップを削除していた。
・Azureのスナップショットは、NFSサーバはバックアップしてたけどDBサーバは対象外だった。
・同期プロセスは、データをステージングに同期させた後に削除する仕様。24時間以内に取り出さないと、過去のデータは失われる。
・レプリケーションの手順は問題が多く、エラーが発生しやすく、出鱈目なシェルスクリプトに依存していて、まともに文書化されていなかった。
・S3へのバックアップはうまくいってなかった。中身は空っぽだった。
・つまり、存在している5系統のバックアップ/レプリケーションは全て、現在、もしくは最初に設定して以来動作していなかった。
最終的に6時間前のバックアップを復元することにした。
・pg_basebackupは、マスタDBがレプリケーションを開始するまでは何も反応せずに待機するが、これには最大10分ほどかかる可能性がある。
このことを知らなければ、コマンドがフリーズしていると考えてもおかしくないだろう。
straceを使っても、特に有用な情報は得られなかった。
Recovery
現在、ステージングのバックアップデータを使って、復旧作業を進めているよ。
We accidentally deleted production data and might have to restore from backup. Google Doc with live notes https://t.co/EVRbHzYlk8
— GitLab.com Status (@gitlabstatus) 2017年2月1日
・2017/02/01 00:36 db1.staging.gitlab.comをバックアップした。
・2017/02/01 00:55 db1.staging.gitlab.comをdb1.cluster.gitlab.comにマウントした。
・ステージングの/var/opt/gitlab/postgresql/data/から本番の/var/opt/gitlab/postgresql/data/にコピーした。
・2017/02/01 01:05 nfs-share01を/var/opt/gitlab/db-meltdownの一時記録場所に設定した。
・残った本番データ、pg_xlogを含む20170131-db-meltodwn-backup.tar.gzをコピーした。
以下はデータの削除と、その後のコピーの様子。
Twitterや他の場所で#hugopsで受けた素晴らしい助言について感謝します。
メモ
自動バックアップは信用できないとかいって定期的に手動バックアップしてる顧客がいるのだが、あの運用が正しかったということが証明されたな(棒)
syncはバックアップ自体は取れている(その後消える)ように読めたのだが、何か読み違いがあるだろうか。
再発させないための対策を書くと書いてあるが、まだ無いようだった。
webhooksとかomnibusとか、どういう意味なのかよくわからなかった。
synchronisation processはsync sync syncのことだろうか?
参考
http://www.publickey1.jp/blog/17/gitlabcom56.html
全体的な概要。
http://tmegos.hatenablog.jp/entry/gitlab_backup_fail
pg_dumpが動かない実体験。