Scalaの開発環境をセットアップするためのツール、Typesafe Activator。これを使ってチュートリアル通りに進めていけば、簡単にローカル環境でApache Sparkを試せるらしい。
... 簡単に、と思って始めてみたら、特にWindowsでいろいろハマったので、メモがてら、試したStepを書き残してみます。
環境
- Windows 8.1 64bit 日本語 (Proでは無いです)
- Ubuntu 14.04 LTS 32bit 日本語Remix
両者とも「JDK8」インストール済。環境変数PATHも通して、javac -versionするとこんな感じ。
> javac -version
javac 1.8.0_25
Typesafe Activatorのセットアップ
Typesafe Activatorのダウンロード
「Download」ボタンから。2015/02/22時点ではtypesafe-activator-1.2.12.zipでした。
Zipを解凍
cdしやすいところにフォルダーを掘って解凍。私の場合は、
- Windowsでは、C:\scala\activator
- Ubuntuでは、/home/myuser/activator
Activator uiの起動
Command Prompt、もしくはTerminalを立ち上げて、
> cd C:\scala\activator
> .\activator.bat ui
> cd /home/myuser/activator
> chmod +x activator
> .\activator ui
しばらく放置しておくとブラウザが起動。localhost上でwebアプリが立ち上がります。
Spark-Workshop テンプレートを試してみる
Spark-workshop テンプレートの選択
Filter Templateで「spark」としてみると、何個かヒットするので、その中から「spark-workshop」と書かれているものを選んで、「Create」。
Your application is readyと出たら、「Compiler/log view」へ。
基本的に自動でコンパイルと依存の解決が始まるはずですが、何もlog viewに出てなかったら「start compile」を押す
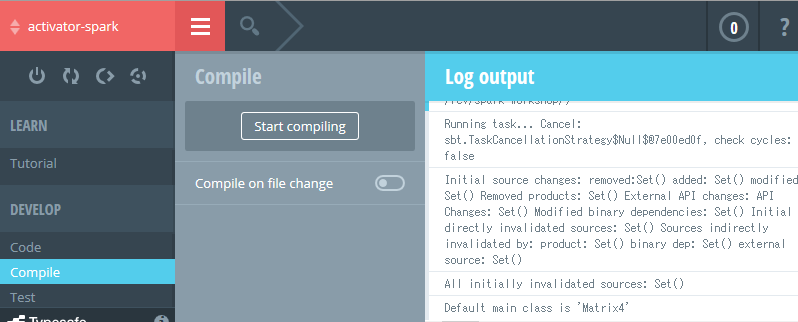
Spark1.2.0の時点では、Scala2.10.xのみ対応 [2.11.xはダメ] なので、その辺の依存を解決したりしてるようですね。
途中で「com.typesafe.sbtrc.NeedToRebootException: Need to reboot SBT (this is expected)」と出ますが、expectedと言っているので、それは気にしなくても良し。
「Will watch 51 source files.」と出て、Javaの挙動が落ち着いたら完了。Winならタスクマネージャー、Ubuntuならtopコマンドでマシンの状況をモニタしておくと良いでしょう。
Testを流してみる
Testメニューに入って、Runボタンを押す
Testの途中経過は、何故かCompileページのlogに出てくるので、Test Run始めたらそちらに移動しましょう。
この時点で、私のUbuntuの方では、Test 9件が全てPassしました。
Windowsにはwinutils.exeが必要
WindowsでTest Runすると、エラーがいっぱい出てくるかと思います。Null Pointerがどうのこうのとか一杯エラー出て埋もれちゃうんですが、Root Causeは、最初のtest failのメッセージにあるwinutils.exeが無いという件。
NGrams6Spec:
NGrams6
15/02/17 00:16:19 ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
at org.apache.hadoop.util.Shell.getQualifiedBinPath(Shell.java:278)
at org.apache.hadoop.util.Shell.getWinUtilsPath(Shell.java:300)
winutils.exeは上のエラーからも想像つくかとは思いますが、HadoopのもろもろをWin上で動かす時に必要なwrapper的なモノ。で、Hadoopのbinには含まれていないので、ソースからビルドして作る必要がある。と。
自力でビルドするのはとても面倒な感じだったので、以下自炊されておられるサイトから頂きました。
hadoop 2.4.1用winutils.exeとhadoop.dllのダウンロード - DD開発ROOM
システム環境変数%HADOOP_HOME%を作って、
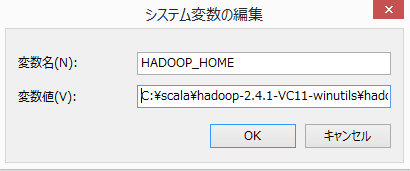
その下にbinフォルダを作って、winutils.exeを置きます。
環境変数を認識させるにはActivatorの再起動が必要っぽいので、ブラウザとcommand promptを閉じて、dir %HADOOP_HOME%\binで確認。
> dir %HADOOP_HOME%\bin
2014/07/15 14:48 124,416 hadoop.dll
2014/07/15 14:38 110,080 winutils.exe
spark-workshop プロジェクトフォルダの中にあるactivator.batをダブルクリックすると、またブラウザでUIが立ち上がるので、そこでもう一度Testを流してみましょう。
それでもWindowsではTest Fail
「Crawl5aSpec」というTestがFailしている
Crawl5aSpec:
Crawl5a
15/02/16 23:27:49 WARN TaskSetManager: Stage 200 contains a task of very large size (390 KB). The maximum recommended task size is 100 KB.
- simulates a web crawler *** FAILED ***
java.nio.charset.MalformedInputException: Input length = 1
どうも、spark-workshop\data\enron-spam-ham\spam100の中にある「0002.2001-05-25.SA_and_HP.spam.txt」というファイル、エンコードがLatin1で著作権記号(c)が書かれている。これがうまく読み込めないのが問題っぽい。
コントロールパネル -> 地域 -> 管理で、システムロケールを英語に変えると、Passになるのを確認しました。
もしくは、ファイルの読み込みのところをエンコード指定で読むように書き換えれば多分動くんだろうなーというところですが、本題ではないので、まあ放置でいいかなと。
Runしてみる
Run Viewに行って、wordcount2を選んで流してみてください。
実行中の挙動は、Testのときと同じく「Compile View」に出ます。
正常終了すると「spark-workshop\data\kjvdat.txt」が変換されて、「spark-workshop\output\kjv-wc2」に、「_SUCCESS」と「part-00000」という結果ファイルが出てくると思います。
余談ですが、サンプル入力の「kjv」とは、King James Versionの聖書ってことらしいです。
欽定訳聖書 - Wikipedia
CommandPropmt or TerminalからのRun
RunするのにActivator UIを起動するのは面倒、ということで、CLIからのRunを試してみます。
> cd [your spark-workshop directory]
> activator.bat run
> cd [your spark-workshop directory]
> ./activator run
以下のようなTargetのリストが出て選べとなると思うので、Runしたいものの番号を入力すると流れます(Hadoop.xxとなってるTargetはlocal環境では動きませんが)
| No | Name |
|---|---|
| 1 | hadoop.HSparkSQL9 |
| 2 | hadoop.HMatrix4 |
| 3 | hadoop.HWordCount3 |
| 4 | Crawl5a |
| 5 | SparkStreaming8Main |
| 6 | hadoop.HNGrams6 |
| 7 | NGrams6 |
| 8 | InvertedIndex5bSortByWordAndCounts |
| 9 | SparkStreaming8 |
| 10 | hadoop.HJoins7 |
| 11 | hadoop.HSparkStreaming8 |
| 12 | Matrix4 |
| 13 | WordCount2SortByWord |
| 14 | WordCount2SortByCount |
| 15 | WordCount2GroupBy |
| 16 | InvertedIndex5b |
| 17 | Matrix4StdDev |
| 18 | SparkSQL9 |
| 19 | hadoop.HInvertedIndex5b |
| 20 | SparkStreaming8SQL |
| 21 | hadoop.HCrawl5aHDFS |
| 22 | com.typesafe.sparkworkshop.util.streaming.DataSocketServer |
| 23 | Joins7 |
| 24 | com.typesafe.sparkworkshop.util.streaming.DataDirectoryServer |
| 25 | WordCount3SortByWordLength |
| 26 | Crawl5aHDFS |
| 27 | SparkStreaming8MainSocket |
| 28 | Joins7Ordered |
| 29 | WordCount2 |
| 30 | WordCount3 |
詳細はSpark Workshopに書いてある通りなのですが、長いので雑に要約すると
| Type | Description |
|---|---|
| WordCount2, WordCount3 | 文章中の単語の出現数をカウント。2と3の違いは、3の方では「Kryo Serialization」という圧縮効率のいいライブラリを使ってるので、メモリとネットワーク帯域をセーブできるということらしいです。 |
| Matrix4 | 行列に対する処理のサンプル。デフォルトでは5x10の行列を作って(1)、行ごとに合計と平均を出しているようです。 |
| Crawl5a, InvertedIndex5b | クローラーが引っ張ってきたデータを、転置インデックスにするという、全文検索エンジン向けのシナリオ。 |
| NGram6 | Ngramによるパターンマッチ。ここでは「% love % %」という条件で、「4単語のつながりで2番目がlove」となるものを探してるようです。 |
| Joins7, Joins7Ordered | 2つのデータのJoin。「kjvdat.txt」と「abbrevs-to-names.tsv」の1カラム目をKeyとしてJoinして、略されている聖書の名前をフルネームに変換をしています(e.g. Gen -> Genesis)。 |
| SparkStreaming8 | バッチ処理では当然流した時点の集計しかできないわけですが、SparkにはStreamを受け取ってリアルタイムな処理をする機能があるので、サーバ立ててincrementalなword countができるよ、というシナリオ。 |
| SparkSQL9 | 今までのExerciseでは直接Text FileをRDDに読み込んでアレコレしてましたが、ここでは読み込んだTextに対して、Spark SQLの機能を使ってフィルタ(WHERE文)したりGroup By -> Countしたりしてます。単純な集計なら自力でreduceByKeyとかするより楽っぽい? |
WordCount2とかNgram6とかの末尾についてる数字の意味は、単純に、Exerciseの番号、ということみたいですね。順序通りやるもよし、興味あるものだけ流すもよし。
1番目のExercise「Intro1.scala」がリストに出てきませんが、これはspark shellを起動してinteractiveに流すということのようなので、このバッチ実行には含まれていません。「SparkSQLParquet10」「HiveSQL11」も同じくですね。
Testを流すならactivator testで流れます。
Scala IDEに、Spark-Workshop プロジェクトをインポートする
…… Eclipse (Scala IDE)にインポートしてそっからdebug出来ると素敵、と思ってボチボチ試したのですが、どうも、そう上手くいかなかったので以下略。Debug AsでJava Applicationとしてしか認識されなくて起動できない & Versionが合わないエラーがいっぱい出て挫折。
現在はAtomエディタにlanguage-scalaとautocomplete-plusを入れて、実行はCLIからやってます。
breakpoint貼ってデバッグ出来ないのが痛いですが、まあ、Activator & Scala IDEのアップデートがあったら、もう一度試してみますかね。
...
参考までにですが、Eclipse形式にspark-workshopプロジェクトを変換するに当たって、
Not a valid command: eclipse (similar: listen, help, alias) Not a valid project ID: eclipse Expected ':' (if selecting a configuration) Not a valid key: eclipse (similar: deliver, licenses, clean) eclipse ^
と出た場合、spark-workshop\projectのplugins.sbtとactivator-sbt-eclipse-shim.sbtの中にあるaddSbtPlugin("com.typesafe.sbteclipse" % "sbteclipse-plugin" % "2.5.0")のversion指定に相違があることがあるみたいなので、どちらかに合わせる必要があるみたいです。
-
Rなら
matrix(0:49, nrow=5, ncol=10, byrow=Tかな。 ↩