#オーディオ・音声分析への道7 FFT 自己相関関数 ピッチ検出
前回までで、
- Xcodeにてオーディオデータの入出力を行う Libsndfile , vDSPによる各種演算方法
- vDSPによるFFT、iFFT法
- FFT結果の強度(magnitude)と位相(phase)への変換
- 簡単なフィルタリング
を行いました。今回は、vDSPを使用して自己相関関数(Autocorrelation)を求め、そこからオーディオデータのピッチが検出できるようにしたいと思います。
##自己相関関数 Autocorrelation
自己相関関数は、以下の数式によって示されるように、
信号がそれ自身を時間シフトした信号とどれだけ良く整合するかを測る尺度であり、時間シフトの大きさの関数として表される。wikipedia参照
autocorrelation_t(\tau) = \sum_{j=t}^{t+W-\tau-1}x_j\cdot x_{j+\tau}
で定義でき、ここからautocorrelationの値を-1~1に標準化(Normalize)する為には、
n_t(\tau) = autocorrelation_t(\tau)/autocorrealation_0(\tau)
と、0番目のautocorrelationで全体を割る事で得られます。ただし,
autocorrelation[0] > 0
です。
これは、autocorrelationで得られた信号のうち、0番目が最も大きい値をとるためでです。
##ウィーナー=ヒンチン(Wiener-Khinchin)の定理
上の方法で自己相関関数を計算する為にはコンピュータに大きな負荷がかかります。
そこで、ウィーナー=ヒンチン(Wiener-Khinchin)の定理を使用し、FFTを使用する事で全く同じ結果が得られます。
手順としては以下の用に行います。
- FFTフレームサイズと同じ長さの信号を得る
- 窓がけを行う。
- FFT
- 得られた信号の絶対値をとる sqrt(realreal + imgimg)
- iFFT
窓がけを行わないと、雑音が多く信号に混じり、ピッチ検出が綺麗にいかない場合があります。
##プログラム
今回はクラリネットのcrescendoを録音した音を使用します。純音に近い音から、音量が大きくなるにつれて、歪んだ音に変化します。
プログラムは、入力信号を input として窓がけを以下
vDSP_vmul(input, 1, window, 1, keinput, 1, fftsize);
そしてFFT
vDSP_ctoz( ( COMPLEX * ) input, 2, &splitComplex, 1, ffthalfsize );
// FFT FORWARD
vDSP_fft_zrip(fftsetup, &splitComplex, 1, log2n,FFT_FORWARD);
パワースペクトラルを得ます。(sqrt(real * real + img * img))
vDSP_zvabs(&splitComplex, 1, Autocorrelation, 1, ffthalfsize);
こうして得られたパワースペクトラルをplotしてみると、
20フレーム辺りはまだ純音に近い感じです。

しかし、160フレームあたりでは、かなり音が歪んでスペクトラルもそれを表しています。また、基音よりも第二倍音あたりの方が大きな強度を持っています。

ちなみに、濃い緑の縦線は100フレーム毎、薄い緑の縦線は25フレーム毎に描写されています。
この信号を、 SplitComplex型 の real 部分のみに代入し、 img 部分を0でパディングします。
for(i=0;i<ffthalfsize;i++){
splitComplex->realp[i] = Autocorrelation[i];
splitComplex->imagp[i] = 0;
}
そしてiFFTを行い、結果を ** Autocorrelation** に格納します。 ** Autocorrelation** のサイズは fftsize です。
vDSP_fft_zrip(fftsetup, splitComplex, 1, log2n,FFT_INVERSE);
vDSP_ztoc(splitComplex, 1, (COMPLEX *) Autocorrelation, 2, ffthalfsize);
この信号がAutocorrelationになります。
これを標準化し-1~1の値にします。
for(i=0;i<ffthalfsize;i++){
if(autocorrelation[0]){
NSDF[i] = autocorrelation[i]/autocorrelation[0];
}else NSDF[i] = 0;
}
fftsize分の信号が得られましたが、実際に使用するのはその半分です。
FFTサイズの半分の領域を、20フレーム、160フレームそれぞれプロットします。
Autocorrelation 20th frame

Autocorrelation 160th frame

黒い横線は、0を表しています。
##ピッチ検出
ピッチの検出は以下の手順で行います。
- Autocorrelationの信号を時間軸上(横軸上)にデータを調べ、0クロス点から正に値が動いた地点から、0クロス点から再び負の値に動いた地点を取得。つまり、下画像の最初の赤い丸から、最後の赤い丸までの間を取得
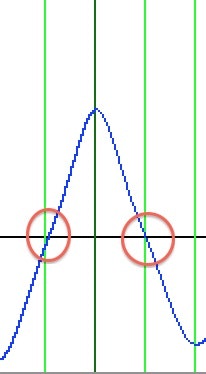
- 1で得られたデータ領域から、最も大きな強度を持つbin、ピークbinを一つ検出する。
- これをフレーム一杯繰り返し、いくつかのピークを取得(ピークリストを作成)
例えば20th frameのAutocorrelationでは、9個くらいのピークが検出できると思います
4.ピークリストから、最も大きい値を持つピークを抜き出し、その値の80%~100%の間で閾値(threshold)を設定する。
5.ピークリストの中で、閾値を見たし、且つ最初に検出されたピークを取得する。
6.ピークのbinの逆数をとる。
具体的には、
f(Hz) = Samplingrate / bin
となる。
FFTのサイズにもよりますが、出てきた値は荒いと思うので、隣り合ういくつかのbinの重心を取る等して、値を補完するとより良い結果が得られます。
参考 : http://www.cs.otago.ac.nz/tartini/papers/A_Smarter_Way_to_Find_Pitch.pdf
##まとめ
自己相関関数を得る事で、音のピッチが得られました。ただこれは、単音やノイズの少ない音に対して威力を発揮する物で、和音やノイズの多い音に対しては誤動作をする可能性があります。定常的なノイズを軽減する手法の一つに、スペクトラルの時間軸上の差分をとって計算するものがあります。
今回はピッチを取得しましたが、スペクトラル情報からは他にも、
- 音の明るさ
- 音のノイズっぽさ
- 音の偏差
- 音の大きさ
- スペクトラルの広がり方
などなど、色々な尺度を得る事ができます。
これから、ケプストラム等を使って、音声を母音や子音に分ける分析などもやっていきたいと思います。