概要
JavaScriptでDOMを作ってるサイトをPythonを使ってスクレイピングしたので、手順をメモ。
大雑把には、ScrapyとSeleniumを組み合わせてやった。
Scrapy
Scrapyは、クローラーを実装するためのフレームワーク。
クローラーをSpiderのサブクラス、スクレイピングした情報をItemのサブクラス、スクレイピングした情報に対する処理をPipelineのサブクラス、という風にフレームワークが決めたインターフェースを満たすクラスとしてクローラーを実装する。
scrapyというコマンドが提供されてて、このコマンドを使って、作ったクローラーの一覧を見たり、クローラーを起動したりできる。
Selenium
Seleniumは、ブラウザをプログラムから制御するためのツール(でいいのかな?)。Pythonも含めたいろんな言語で使える。
よくWebサイト/アプリの自動テスト文脈でよく出てくる。
これを使えば、JavaScript実行して、動的に生成されたDOMも含めたHTMLのソースをスクレイピングできる。
元はJavaScript経由でブラウザを制御してたみたいだけど、今はブラウザに直接メッセージを送ってブラウザを制御してくれる。
ぼくの環境(OSX)で試したら、Safari、Chromeだと拡張機能みたいなのをインストールしないと使えなかった。
Firefoxだとそのまま使える。
PhantomJSを入れれば、ウィンドウ無しでスクレイピングもできるので、サーバー上で使っても大丈夫。
なんでScrapyを使うのか
Scrapyを使わなくても、Seleniumだけでもスクレイピングはできるんだけど、
- 並行処理で複数ページをスクレイピングしてくれる(マルチスレッド?プロセス?)、
- 何ページクロールしたかとか、エラーは何回起こったかとか、ログをいい感じにまとめてくれる、
- クロール対象ページの重複を回避してくれる、
- クロールの間隔とか、いろんな設定オプションを提供してくれる、
- CSS、XPathを組み合わせて、DOMから情報を抜ける(組み合わせが結構便利!)、
- クロール結果を、JSONとかXMLで吐き出せる、
- いい感じのプログラム設計でクローラーを書ける(下手に自分で設計するより良いと思う)、
など、思いつくScrapyを使うメリットはこんな感じ。
最初は、フレームワークの勉強が面倒くさくて、SeleniumとPyQueryだけでクローラーを実装してたけど、ログとかエラー処理とか書いてたら、車輪の再発明感が強くなってきてやめました。
実装前にScrapyのドキュメントを、最初からSettingsのページまでと、Architecture overview、Downloader Middlewareあたりを読みました。
ScrapyとSeleniumを組み合わせて使う
元ネタはこのstack overflow。
Scrapyのアーキテクチャーはこんな感じ(Scrapyのドキュメントより)。
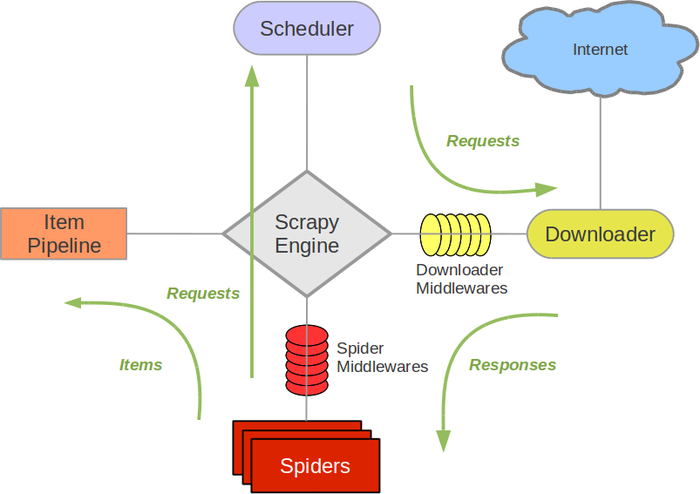
Downloader Middlewaresを、カスタマイズして、ScrapyのSpiderがSeleniumを使ってスクレイピングするように調整する。
Donwloader Middlewareの実装
Downloader Middlewareは、process_requestを実装した普通のクラスとして実装する。
# -*- coding: utf-8 -*-
import os.path
from urlparse import urlparse
import arrow
from scrapy.http import HtmlResponse
from selenium.webdriver import Firefox
driver = Firefox()
class SeleniumMiddleware(object):
def process_request(self, request, spider):
driver.get(request.url)
return HtmlResponse(driver.current_url,
body = driver.page_source,
encoding = 'utf-8',
request = request)
def close_driver():
driver.close()
このDownload Middlewareを登録すると、Spiderが、ページをスクレイピングする前に、process_requestを呼び出してくれる。
詳しくは、こちら。
HtmlResponseのインスタンスを返してるんで、それ以降のDownload Middlewareは呼び出されない。
優先順位の設定によっては、デフォルトのDonwload Middleware(robots.txtを解析処理など)は呼び出されないので注意。
上では、Firefoxを使ってるけど、PhantomJSを使いたい時は、driver変数のとこを書き換える。
Download Middlewareの登録
使いたいSpiderクラスに、SeleniumMiddlewareを登録する。
# -*- coding: utf-8 -*-
import scrapy
from ..selenium_middleware import close_driver
class SomeSpider(scrapy.Spider):
name = "some_spider"
allowed_domains = ["somedomain"]
start_urls = (
'http://somedomain/',
)
custom_settings = {
"DOWNLOADER_MIDDLEWARES": {
"some_crawler.selenium_middleware.SeleniumMiddleware": 0,
},
"DOWNLOAD_DELAY": 0.5,
}
def parse(self, response):
# クローラーの処理
def closed(self, reason):
close_driver()
custom_settingsのDOWNLOADER_MIDDLEWARESのとこが設定。
スクレイピングに使ったFirefoxのウィンドウを消すために、closeメソッドの処理を書いてる。