みなさん DBPedia をご存知でしょうか.DBPedia とは,Wikipedia から構造化データ (RDF) として情報を抽出するものです.DBPedia では Linked Data として情報が体系化されているので,Wikipedia 内の必要な情報を,非常に簡単に抽出することができます.
「◯◯ の情報を Wikipedia からスクレイピングして取ってきて…」みたいな話をよく耳にし,そんなのスクレイピングしなくても DBPedia 使えば一瞬なのに… と感じることが最近多々あるので,DBPedia の普及もかねて簡単にまとめてみることにしました.DBPedia なんて初めて聞いたという方は,ぜひチェックしてみて下さい.
Linked Data の基本
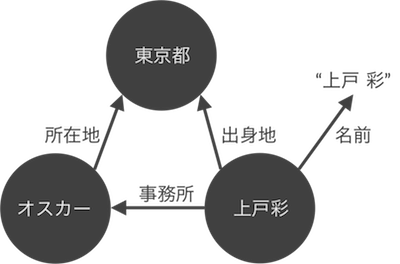
Linked Data では,エンティティ,プロパティ,リテラル の 3 つを使って情報を表現します.エンティティは上図の ● の部分で,リソースごとに一意の URI を割り当てます.DBPedia の場合は Wikipedia の各ページに対応します.また,プロパティは → の部分であり,リテラルは "上戸 彩" のように文字列や数値を直接記述したものです.
エンティティの属するクラスや,各クラスのプロパティの種類などは,オントロジー と呼ばれるもので定義されます.DBPedia のオントロジーは こちら で定義されており,これに基づいて対応する情報を抽出 (マッピング) することで,Linked Data を構築しています.DBPedia では,infobox (Wikipedia の右に表示されている box) や本文中の情報をマッピングします.
また,リソースは RDF を利用して記述します.RDF では,<Subject (主語)> <Predicate (述語)> <Object (目的語)> のトリプルで Linked Data を記述します.自治体などが公開している LOD (Linked Open Data) が近年注目を浴びていますが,その多くは RDF で記述されています.上図のものを RDF で記述すると,以下のようになります.
<http://ja.dbpedia.org/resource/上戸彩> <http://ja.dbpedia.org/property/出生地> <http://ja.dbpedia.org/resource/東京都> .
<http://ja.dbpedia.org/resource/上戸彩> <http://ja.dbpedia.org/property/事務所> <http://ja.dbpedia.org/resource/オスカー> .
<http://ja.dbpedia.org/resource/上戸彩> <http://ja.dbpedia.org/property/name> "上戸 彩"@ja .
<http://ja.dbpedia.org/resource/オスカー> <http://dbpedia.org/ontology/locationCity> <http://ja.dbpedia.org/resource/東京都> .
実際は prefix を用いて URI の記述を省略したり,RDF の簡略表記である N-Triples や Turtle で記述したりすることが多いです.
そして,RDF から情報を抽出するには,SPARQL という SQL ライクな検索言語を用います.例えば,上記の RDF データから Subject が上戸彩エンティティであるもの全てを取得したい場合,以下のように記述します.
select * where { <http://ja.dbpedia.org/resource/上戸彩> ?p ?o . }
以下の様な結果となります.簡単ですね.
また,Linked Data なので当然 1 ホップ先,2 ホップ先… とたどることができて,例えば「上戸彩が所属している事務所の所在地が知りたい」といった場合も以下のように簡単に取得できます.クエリの詳しい説明は省略しますが,直感的に分かると思います.
select ?locationCity where {
<http://ja.dbpedia.org/resource/上戸彩> <http://ja.dbpedia.org/property/事務所> ?office .
?office <http://dbpedia.org/ontology/locationCity> ?locationCity .
}
以上,Linked Data の基本をざっと説明しました.RDF や SPARQL について詳しく知りたい方は W3C 公式ドキュメントをご参照下さい.
DBPedia からの情報抽出
いよいよ本題です.日本語版の Wikipedia を対象とした DBPedia Japanese のページには SPARQL エンドポイントが用意されており,誰でも利用することができます.
DBPedia Japanese Sparql Endpoint: http://ja.dbpedia.org/sparql
Query Text に SPARQL クエリを記述し,Results Format で出力フォーマットを指定 (HTML 以外はファイル出力となります),Run Query で実行できます.
以下,2 つのユースケースを設定してそれぞれの抽出をおこないます.
1. 全上場企業の概要を取得したい
これをスクレイピングでやろうとすると,上場企業一覧を取得して,それに対応する各ページから概要と思われる部分を抽出して… といった,かなり面倒な作業になります.しかし,Wikipedia には Category:東証一部上場企業 というページがあることを利用し,以下のようなクエリを投げることで,一発で全上場企業とその概要を取得することができます.
select distinct ?name ?abstract where {
?company <http://dbpedia.org/ontology/wikiPageWikiLink> <http://ja.dbpedia.org/resource/Category:東証一部上場企業> .
?company rdfs:label ?name .
?company <http://dbpedia.org/ontology/abstract> ?abstract .
}
以下のような結果が返ってくるはずです.プロパティを変更することで,概要だけでなく,必要に応じて自分の欲しい情報を取ってこれます.
| name | abstract |
|---|---|
| "本田技研工業"@ja | "本田技研工業株式会社(ほんだぎけんこうぎょう、英称:Honda Motor Co., Ltd.)は、東京都港区に本社(発祥の地は静岡県浜松市)を置く大手輸送機器及び機械工業メーカーである。"@ja |
| "東日本旅客鉄道"@ja | "東日本旅客鉄道株式会社(ひがしにほんりょかくてつどう、英: East Japan Railway Company)は、1987年4月1日に、日本国有鉄道(国鉄)から鉄道事業を引き継いだ旅客鉄道会社の一つ。東北地方全域(青森県の一部を除く)、関東地方全域(神奈川県の一部を除く)、新潟県の大部分、山梨県・長野県のそれぞれ約半分、静岡県の一部地域を営業区域とし、JRグループの中で最も企業規模が大きい。本社は東京都渋谷区。東証一部上場。通称はJR東日本(ジェイアールひがしにほん)。英語略称はJR East。コーポレートカラーは緑色。取締役会長は清野智、取締役副会長は小縣方樹、代表取締役社長は冨田哲郎。社歌は「明け行く空に」。"@ja |
| "オリンパス"@ja | "オリンパス株式会社 (Olympus Corporation) は、日本の光学機器・電子機器メーカーである。本社は、東京都新宿区西新宿。"@ja |
| … | … |
2. 日本の都道府県,市町村リストを取得したい
これも DBPedia を使えば一発です.以下のクエリを投げると,全ての都道府県と市町村がペアとなって返ってきます.
select distinct ?prefectureName ?cityName where {
?prefecture <http://dbpedia.org/ontology/wikiPageWikiLink> <http://ja.dbpedia.org/resource/Category:日本の都道府県> .
?prefecture a <http://schema.org/AdministrativeArea> .
?city <http://dbpedia.org/ontology/location> ?prefecture .
?prefecture rdfs:label ?prefectureName .
?city a <http://dbpedia.org/ontology/City> .
?city rdfs:label ?cityName .
}
<http://dbpedia.org/ontology/wikiPageWikiLink> に <http://ja.dbpedia.org/resource/Category:日本の都道府県> を持つ Subject (?prefecture) を見つけ,さらに <http://dbpedia.org/ontology/location> にその ?prefecture を持つ Subject (?city) を見つけています.
このように,スクレイピングといった面倒な作業をすることなく,簡単な SPARQL クエリを書くだけで Wikipedia から情報を抽出できました.初めて知った方は,今後どんどん利用していって下さい.