この記事は、システムエンジニア Advent Calendar 2016 - Qiita の23日目の記事です。
昨日は @yy_yank さんの 気負わず普通にテストしよう でした。
明日は @koduki さんです。
はじめに
複数ユーザが触るアプリケーションを作る場合、同時にデータが更新された場合の制御は避けては通れません。
この制御はスレッドセーフとか同時更新とか色々な観点で考えないといけないのですが、いまいちそのあたり自分自身の中できれいに整理できていませんでした。
なので、この機会に同時に更新される場合の排他制御について、自分なりに整理してみました。
まえおき
- 説明に使用する言語は Java です。
- 説明のためにシーケンス図っぽいものを使っていますが、 UML の厳密な定義には従っていません。図が描きやすいからシーケンス図を利用している、ってだけなので厳密な記法ルールに従っているかどうかは気にせずに雰囲気で見てください。
- あくまで私の経験・知識を整理したものなので、ベストプラクティスというわけではありません。「私のところはこうしてる」とか「これは××な理由で危険なので○○のほうが良い」とかあれば教えていただけると幸いです。
「同時に更新される」のケースを分類する
| リクエストの回数 | |||
|---|---|---|---|
| 単一 | 複数 | ||
| 対象データを更新する プロセスの数 |
単一 | 1 | 3 |
| 複数 | 2 | 4 | |
一口に「同時に更新される」と言っても、そのケースは複数あると思います。
今回、改めて「同時に更新される」のはどんなケースがあり得るかについて考えた結果、上のように分類できるのかなぁという結論に至りました(完全に我流です。もしかして、こういうのは既にある?)。
それぞれの言葉について説明します。
軸1:対象データを更新するプロセスの数
データを更新するプログラムの数です。プロセスは、 OS のプロセスのイメージです。
たとえば Java プログラムなら、起動している JVM プロセスの数です。
プロセス数が単一とは、 Tomcat や GlassFish などのミドルウェアのプロセスを1つだけ起動して、その上でアプリケーションを動かしているようなケースです。
一方プロセス数が複数とは、複数のサーバープロセスを起動してクラスタリングさせているようなケースです。
バッチや他の Web アプリなどからアクセスされる場合もあるかもしれませんが、ここではひとまず説明を単純にするためクラスタ環境というケースで進めます。
軸2:リクエストの回数
一連の更新処理で実行されるリクエストの回数です。
単一というのは、一回のリクエストでデータの参照→更新が完結しているケースです。
一方複数というのは、まず参照のリクエストがあって、そのあとで更新のリクエストが来るようなケースです。
この2つの軸を掛け算して分類すると、それぞれ次のようになります。
分類1:プロセス・リクエストが単一
単独のプロセスで動かしている Web アプリケーションに、複数のユーザーから同時に更新リクエストが飛んできたようなケースです。
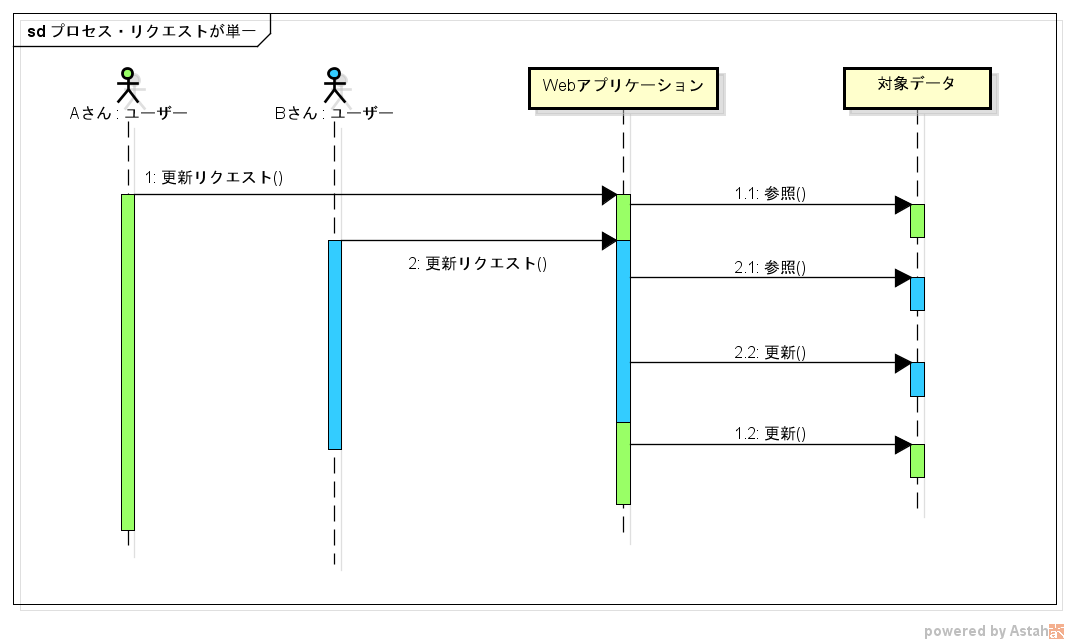
このケースの場合、特に対象データがインスタンスフィールドの値とかだと、スレッドセーフとかの話が中心になります。
分類2:プロセスが複数・リクエストが単一
クラスタリングしている Web アプリケーションに対して、複数のユーザーから同時に更新リクエストが飛んできたようなケースです。
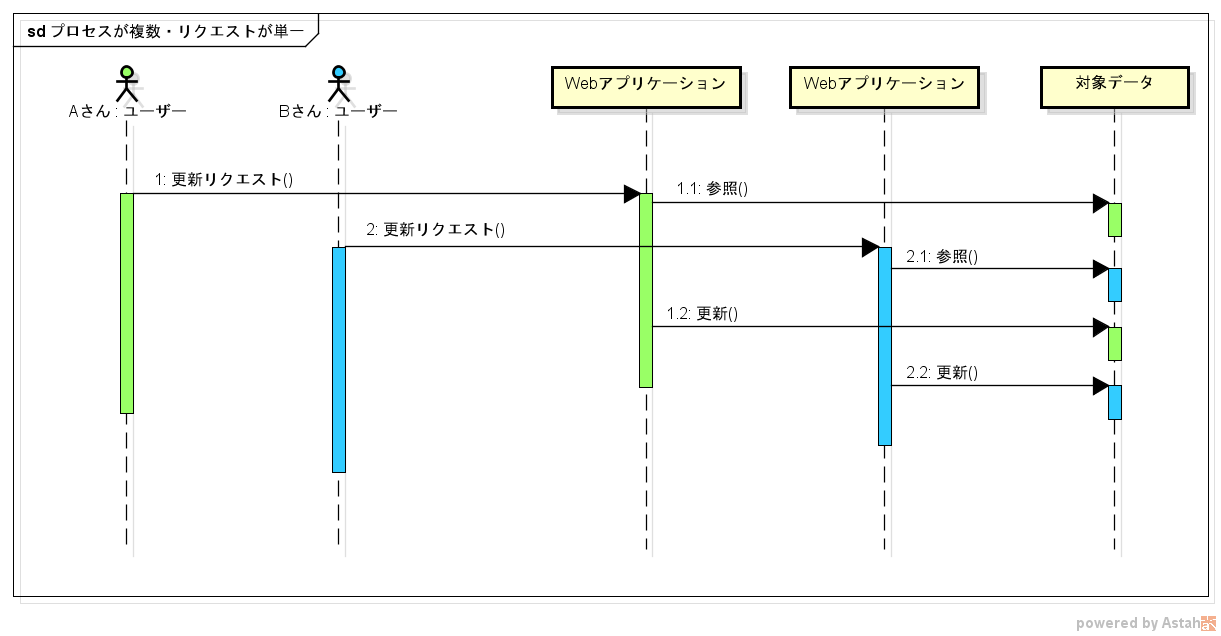
この場合は分類1の対応に加えて、複数のプロセスを跨って実行できる排他制御が必要になります。
※対象データが個々のプロセスの中に閉じていたら、クラスタ構成でも分類1になります。
分類3:プロセスが単一・リクエストが複数
単独のプロセスで動かしている Web アプリケーションに、複数のユーザーが同じ時間帯にデータを更新するようなケースです。
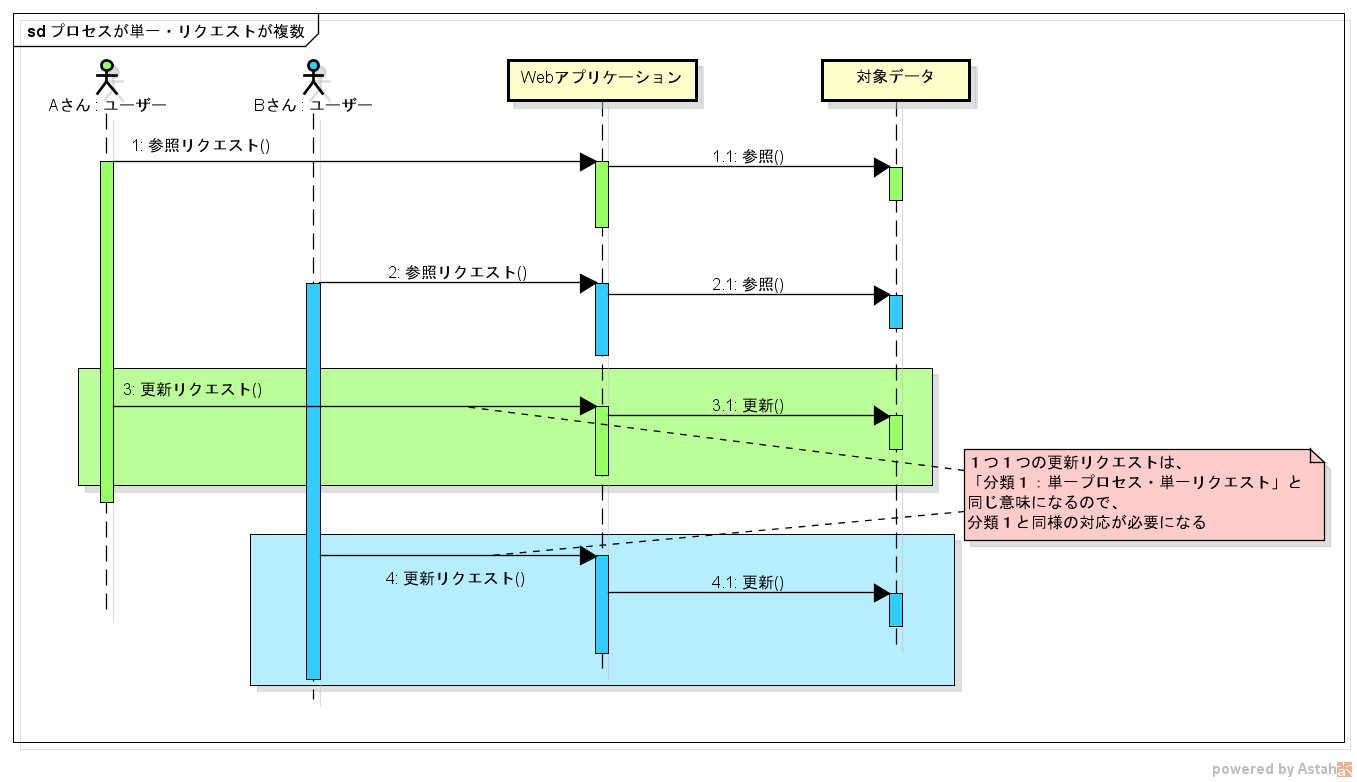
リクエストが複数回にまたがる場合は、よく楽観的排他制御とか呼ばれている制御が関係してきます。
また、個々の更新リクエストは分類1と同じ条件になるので、そちらの対策も取る必要があります(これを忘れやすい気がする)。
分類4:プロセス・リクエストが複数
分類3の Web アプリケーションがクラスタリングされたようなケースです。
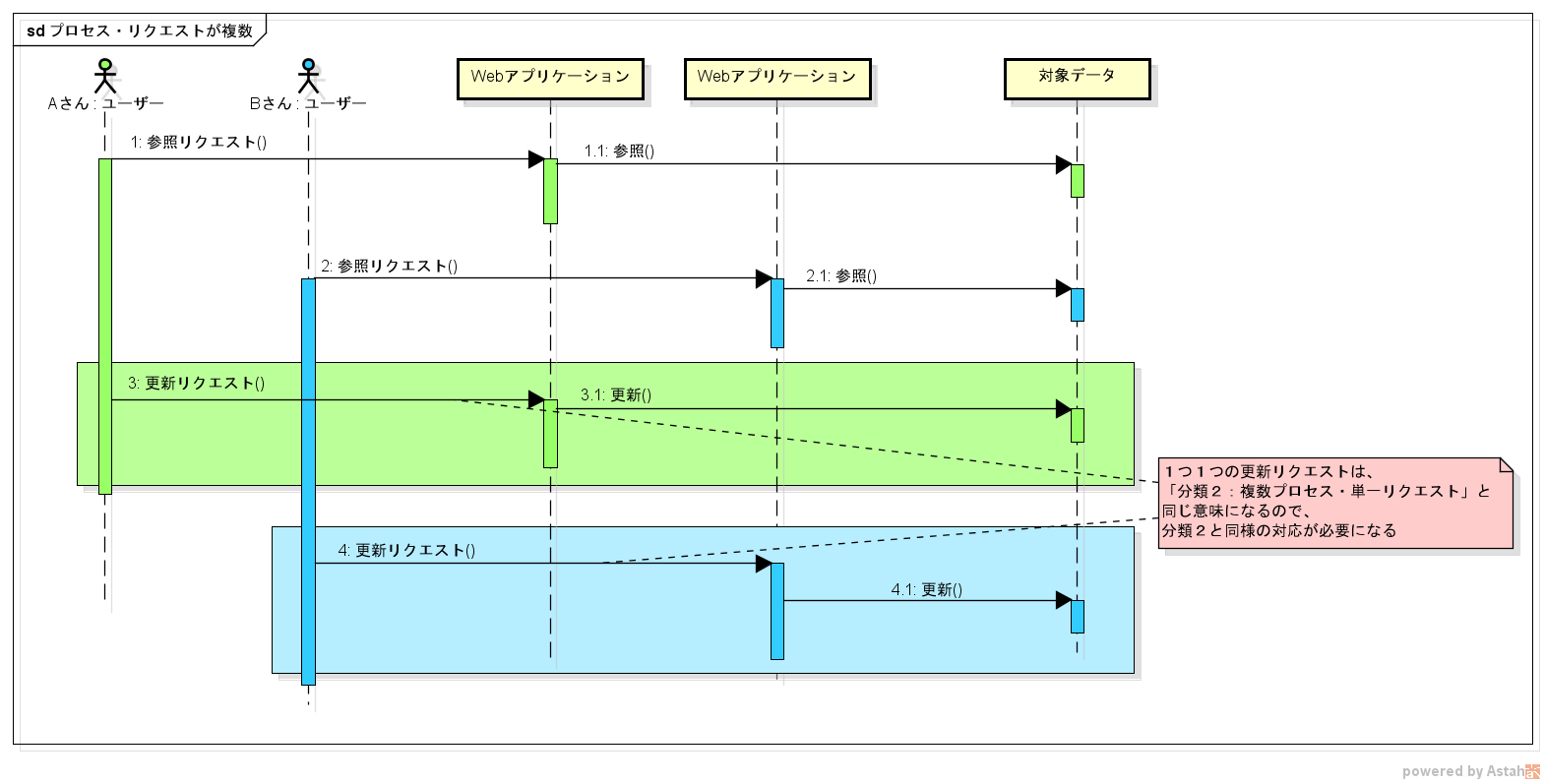
たぶん、通常はこのケースになることが多いのではないかと思います。
今まで、自分はこの分類の境界が曖昧でした。
例えば、「あれ、今は楽観的排他制御の実装(分類3・4)をしているのにスレッドセーフとかの話(分類1)が出てくる?」という感じです。
今回上のように分類することで、この辺のモヤモヤは個人的にややスッキリしました。
次は、それぞれの分類についてもっと詳細な話と、具体的な対応方法について整理していきます。
単一プロセス×単一リクエスト
このケースは最も単純となるケースで、要はマルチスレッドでプログラムを作成するときの基本的な問題が関わってきます。
なので、このケースでの対応方法は他の分類2・3・4でも同様に必要になります。
ここでは説明をシンプルにするために、サンプル実装を Web アプリではなくスタンドアロンな Java プログラムで記述しています。
しかし、結局は Web アプリもマルチスレッドで動いているので同じ話になります。
マルチスレッド下だとそのままでは使えないクラス
Java はマルチスレッドでの処理が可能です。しかし、標準 API の中にはマルチスレッド下でそのまま使うことができないクラスが存在します。
有名なのは SimpleDateFormat とか HashMap などのコレクションクラス でしょうか。
例えば SimpleDateFormat の実装を見てみると、次のようになっています(JDK8)。
public abstract class DateFormat extends Format {
...
protected Calendar calendar;
...
public class SimpleDateFormat extends DateFormat {
...
private StringBuffer format(Date date, StringBuffer toAppendTo,
FieldDelegate delegate) {
// Convert input date to time field list
calendar.setTime(date);
...
}
...
format(Date, StringBuffer, FieldDelegate) メソッドは、 format(Date) メソッドを呼び出すと最終的に実行されるメソッドです。
その先頭で、親クラスである DateFormat が持つインスタンス変数 calendar の値を setTime() で書き換えています。
format() メソッドは、この後 calendar にセットされた時刻の情報をもとに日付文字列を生成して return します。
ということは、複数のスレッドが同時に format(Date) メソッドを使うと危険な感じがしますね。
試しに次のようなコードを作成して動かしてみます。
package sample;
import java.text.SimpleDateFormat;
import java.util.Calendar;
public class Main {
private static SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
public static void main(String[] args) {
new Thread(() ->
printDate(2015, 10, 11)
).start();
new Thread(() ->
printDate(2016, 12, 31)
).start();
}
private static void printDate(int year, int month, int day) {
Calendar cal = Calendar.getInstance();
cal.set(Calendar.YEAR, year);
cal.set(Calendar.MONTH, month - 1);
cal.set(Calendar.DAY_OF_MONTH,day);
String expected = "Date(" + year + "/" + month + "/" + day + ")";
String actual = sdf.format(cal.getTime());
System.out.println(expected + " = " + actual);
}
}
スレッドを2つ作成し、単一の SimpleDateFormat インスタンスを使って日付の文字列を出力させています。
これを実行すると、次のようになります。
※1回目
Date(2015/10/11) = 2016-12-31
Date(2016/12/31) = 2016-12-31
※2回目
Date(2015/10/11) = 2015-10-31
Date(2016/12/31) = 2016-12-31
※3回目
Date(2015/10/11) = 2015-10-11
Date(2016/12/31) = 2015-10-11
完全に間違った値を出力していますし、毎回異なる結果になってしまいました(実行する環境によってはこれとは異なる動きになるかもしれません)。
この問題は、 calendar という単一のインスタンスフィールドを複数のスレッドが参照したり変更しているために起こっています。
図にすると下のような感じです。
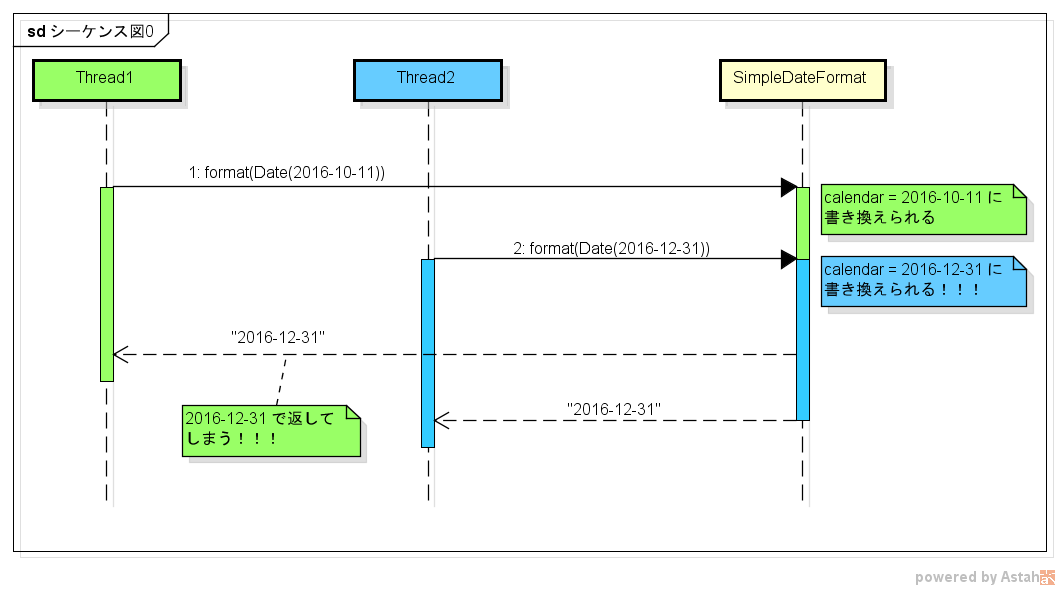
まず、 Thread1 が format() を実行して calendar の値を書き換えます。しかし、直後に Thread2 が format() を実行するため、再び calendar の値が書き換わります。その結果、 Thread1 が呼び出した format() は、 Thread2 が format() を呼び出したときに渡した日付の情報で文字列を生成してしまうわけです。
このようにマルチスレッド下で使用すると正しい動作をしない可能性のあるものは、スレッドセーフではないと表現します。
逆に、マルチスレッド下で使っても正しく動作するものはスレッドセーフであると表現します。
どのクラスがスレッドセーフで、どのクラスがスレッドセーフでないかは、普通 Javadoc に記載されています。
(標準 API なら私の知る限りでは必ず記載がありますが、 OSS のライブラリなどはモノによっては何も書いていない場合もあります)
スレッドセーフでないクラスとして先ほど使用した SimpleDateFormat の Javadoc には、次のように記載されています。
日付フォーマットは同期化されません。スレッドごとに別のフォーマット・インスタンスを作成することをお薦めします。複数のスレッドがフォーマットに並行してアクセスする場合は、外部的に同期化する必要があります。
また、スレッドセーフなクラスの例としてPattern クラスの Javadoc には次のように記載されています。
このクラスのインスタンスは不変であるため、複数のスレッドで並行して使用できます。
どうやって防ぐ?
私が知る限り、次の3つの対応方法があります。
-
synchronizedで処理を排他制御する1 - スレッドセーフではないクラスのインスタンスはスレッドごとに生成する
- スレッドセーフなクラスを使用する
synchronized で処理を排他制御する
排他制御とは、複数のスレッドが同じ処理を実行しようとしたときに、単一のスレッドだけが処理を実行できるように制御することを言います。
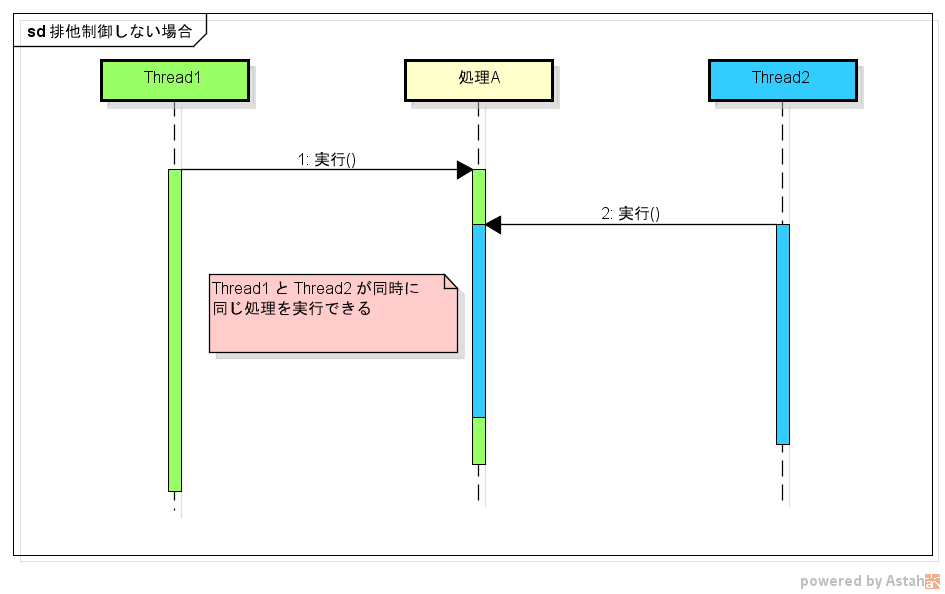
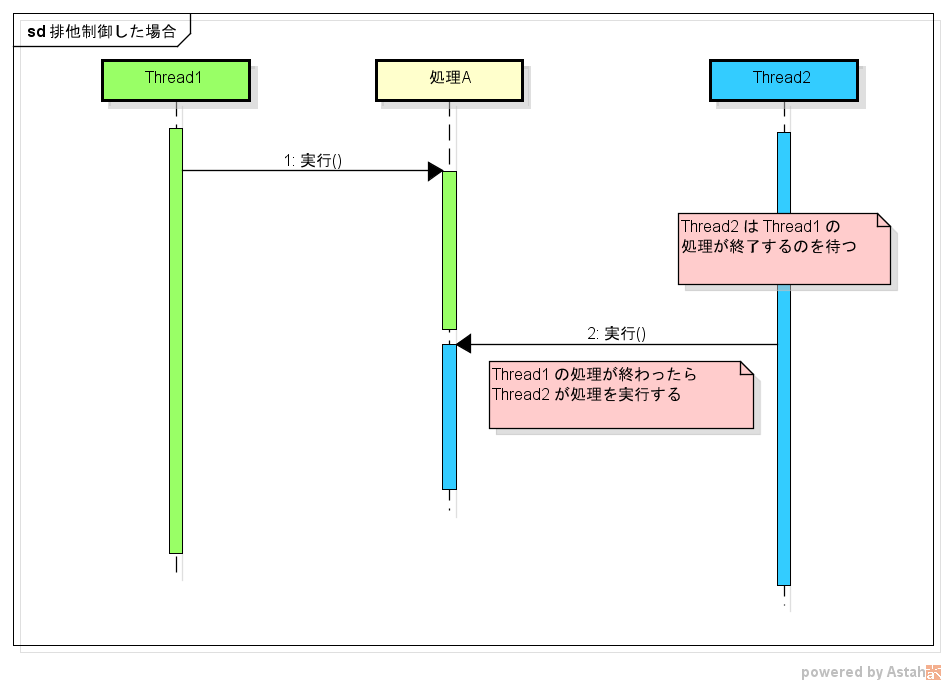
排他制御をしない場合は、1つの処理を複数のスレッドが同時に実行できます。
排他制御をすると、1つのスレッドが処理をしている間、他のスレッドは待機するようになります。
Java では synchronized を使うことで排他制御を実現することができます。
package sample;
import java.text.SimpleDateFormat;
import java.util.Calendar;
public class Main {
private static SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
public static void main(String[] args) {
new Thread(() ->
printDate(2015, 10, 11)
).start();
new Thread(() ->
printDate(2016, 12, 31)
).start();
}
// ★メソッドの宣言に synchronized を追加した
synchronized private static void printDate(int year, int month, int day) {
Calendar cal = Calendar.getInstance();
cal.set(Calendar.YEAR, year);
cal.set(Calendar.MONTH, month - 1);
cal.set(Calendar.DAY_OF_MONTH,day);
String expected = "Date(" + year + "/" + month + "/" + day + ")";
String actual = sdf.format(cal.getTime());
System.out.println(expected + " = " + actual);
}
}
先述の実装にあった printDate() メソッドの頭に synchronized を付けました。これで、このメソッドは排他制御されるようになります。
これを実行すると、次のようになります。
※1回目
Date(2015/10/11) = 2015-10-11
Date(2016/12/31) = 2016-12-31
※2回目
Date(2015/10/11) = 2015-10-11
Date(2016/12/31) = 2016-12-31
※2回目
Date(2015/10/11) = 2015-10-11
Date(2016/12/31) = 2016-12-31
うまくいっているっぽいです。
ただ、 synchronized を使った排他制御は他のスレッドの実行を停止させてしまうので、パフォーマンスを低下させる可能性があります。スレッドの待機時間が長くなると、マルチスレッドにしたことによるメリットが弱まってしまいます。
なるべく他のスレッドの処理を停止させないようにするためには、本当に排他制御が必要なところだけを synchronized で括ってあげるのがいいです。
今回の場合、問題があるのは SimpleDateFormat の format() を呼んでいるところだけです。なので、次のようにすることもできます。
package sample;
import java.text.SimpleDateFormat;
import java.util.Calendar;
public class Main {
private static SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
public static void main(String[] args) {
new Thread(() ->
printDate(2015, 10, 11)
).start();
new Thread(() ->
printDate(2016, 12, 31)
).start();
}
private static void printDate(int year, int month, int day) {
Calendar cal = Calendar.getInstance();
cal.set(Calendar.YEAR, year);
cal.set(Calendar.MONTH, month - 1);
cal.set(Calendar.DAY_OF_MONTH,day);
String expected = "Date(" + year + "/" + month + "/" + day + ")";
String actual;
// ★SimpleDateFormat のインスタンスを指定して format() だけを排他制御
synchronized (sdf) {
actual = sdf.format(cal.getTime());
}
System.out.println(expected + " = " + actual);
}
}
synchronized はメソッドの修飾子として以外にも、上のようにブロックとして使用することもできます。
その場合は synchronized (ロックオブジェクト) {処理} というふうに書きます。
ロックオブジェクトは、 synchronized ブロック内の処理を実行できるスレッドを制御するためのオブジェクトです。すでに synchronized ブロックを実行しているスレッドと同じオブジェクトを持つスレッドが来た場合は、処理が待機させられます。
よくわからないという方は、スレッドを人に、ロックオブジェクトを旗に置き換えて次のようにイメージすると分かりやすいかもしれません。
旗(ロックオブジェクト)を持っている人(スレッド)だけが作業を行うことができます。
人は何人かで旗を取り合って、最初に旗を手に入れた人だけが作業を行います。その間、旗を取れなかった他の人は待機させられます。最初に旗を取った人が作業を終えると、旗をもとの場所に戻します。すると、それまで待機していた他の人が一斉に旗の取り合いを再開します。そして、次に旗を手に入れた人が作業を開始します。旗が取れなかった人は、また待機させられるわけです。
スレッドセーフではないクラスのインスタンスはスレッドごとに生成するようにする
そもそもの問題は、スレッドセーフでないクラスのインスタンスを複数のスレッドで共有していることです。
なので、スレッドごとにインスタンスを生成すれば、この問題は発生しなくなります。
package sample;
import java.text.SimpleDateFormat;
import java.util.Calendar;
public class Main {
public static void main(String[] args) {
new Thread(() ->
printDate(2015, 10, 11)
).start();
new Thread(() ->
printDate(2016, 12, 31)
).start();
}
private static void printDate(int year, int month, int day) {
Calendar cal = Calendar.getInstance();
cal.set(Calendar.YEAR, year);
cal.set(Calendar.MONTH, month - 1);
cal.set(Calendar.DAY_OF_MONTH,day);
String expected = "Date(" + year + "/" + month + "/" + day + ")";
// ★メソッドの中で SimpleDateFormat を new する
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
String actual = sdf.format(cal.getTime());
System.out.println(expected + " = " + actual);
}
}
SimpleDateFormat の new を printDate() メソッド内で行うようにしました。
こうすると、 SimpleDateFormat は printDate() を実行しているスレッドごとに new されるようになります。その結果、最初の実装にあったような問題は起こらなくなります。
図にすると次のような感じです。
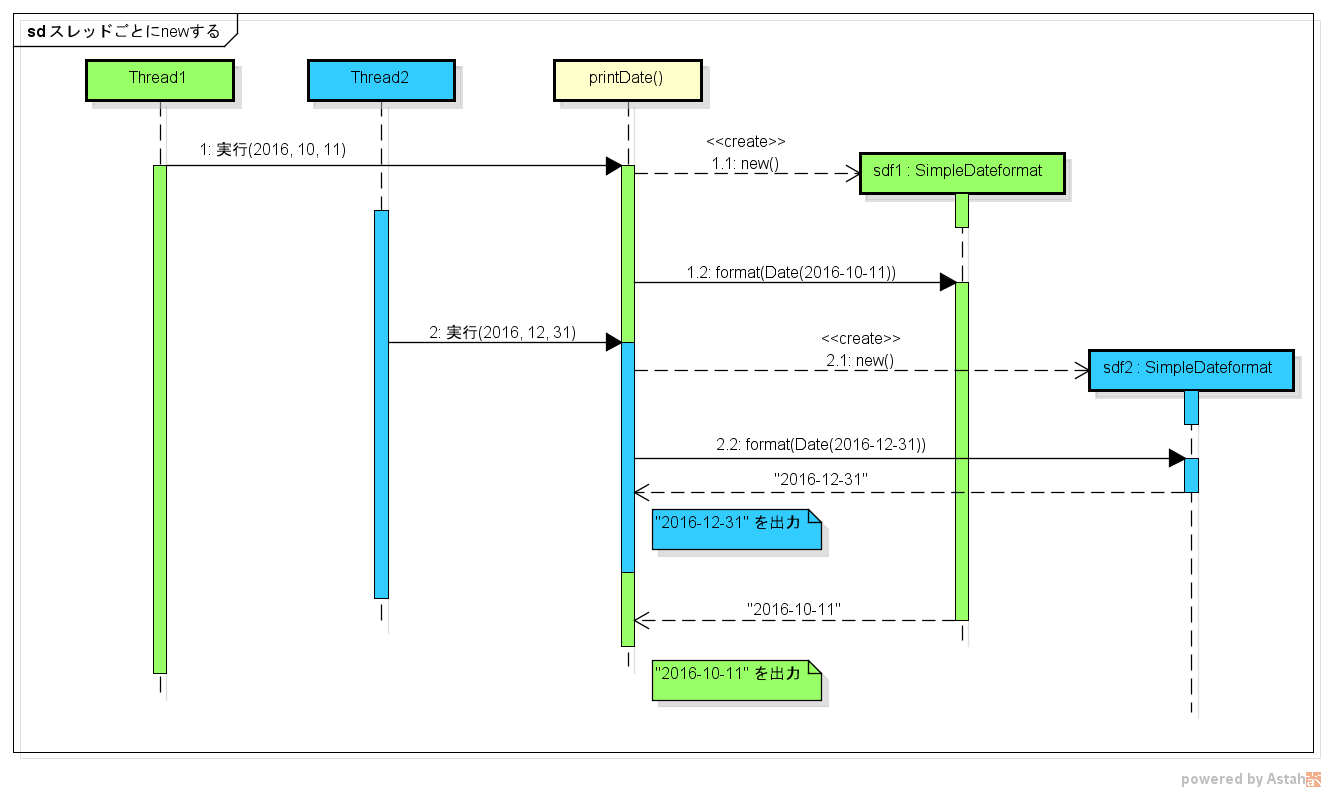
これなら、 synchronized と比べてスレッドの待機も起こらなくなります。
では synchronized は使わずに常にインスタンスを生成すればいいのかというと、そういうわけでもありません。
もしもコンストラクタの処理が非常に遅い場合は、インスタンスを複数作るほうが syonchronized で排他制御するよりも遅くなるかもしれません。
まぁ、多くのクラスのコンストラクタはそんなに遅い処理になることはないので、インスタンスを毎回作るほうがシンプルになって楽な場合が多いと思います。
厳密にどちらのほうが速いかを知りたい場合は、クラスごとに測定する必要があるでしょう。
ちなみに、最初「ローカル変数にしたらスレッドセーフになる」と書こうと思ったのですが、よく考えると次のような実装にするとローカル変数でもダメなことに気付いたのでやめときました(もしかして、こういうのはローカル変数って言わなかったりする?)。
package sample;
import java.text.SimpleDateFormat;
import java.util.Calendar;
public class Main {
public static void main(String[] args) {
// ★変数自体はローカルで宣言しているけど
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
new Thread(() ->
// ★結局複数のスレッドで参照している
printDate(sdf, 2015, 10, 11)
).start();
new Thread(() ->
// ★結局複数のスレッドで参照している
printDate(sdf, 2016, 12, 31)
).start();
}
private static void printDate(SimpleDateFormat sdf, int year, int month, int day) {
Calendar cal = Calendar.getInstance();
cal.set(Calendar.YEAR, year);
cal.set(Calendar.MONTH, month - 1);
cal.set(Calendar.DAY_OF_MONTH,day);
String expected = "Date(" + year + "/" + month + "/" + day + ")";
String actual = sdf.format(cal.getTime());
System.out.println(expected + " = " + actual);
}
}
なので結局は「このインスタンスはスレッドごとに生成されているか?」を気にする必要があることになります。
スレッドセーフなクラスを使用する
標準 API の中には、スレッドセーフでないクラスと似たような機能を持ち、かつスレッドセーフなクラスが用意されている場合があります。
日付処理に関しては、 Java 8 から Date and Time API が追加されています。
この中には DateTimeFormatter というクラスがあります。このクラスは SimpleDateFormat と同じく日時をフォーマットする機能を提供しています(さらに日付文字列から LocalDate などのインスタンスを生成する機能も提供しています)。
このクラスはスレッドセーフなので、マルチスレッド下でも単一のインスタンスを共有して使用することができます。
Javadoc には次のように記載されています。
このクラスは不変でスレッドセーフです。
Date and Time API を使うと、ここまでの SimpleDateFormat を使った実装は次のように書き換えることができます。
package sample;
import java.time.LocalDate;
import java.time.format.DateTimeFormatter;
public class Main {
private static DateTimeFormatter formatter = DateTimeFormatter.ISO_DATE;
public static void main(String[] args) {
new Thread(() ->
printDate(2015, 10, 11)
).start();
new Thread(() ->
printDate(2016, 12, 31)
).start();
}
private static void printDate(int year, int month, int day) {
LocalDate date = LocalDate.of(year, month, day);
String expected = "Date(" + year + "/" + month + "/" + day + ")";
String actual = formatter.format(date);
System.out.println(expected + " = " + actual);
}
}
もちろん実行結果は、
※1回目
Date(2016/12/31) = 2016-12-31
Date(2015/10/11) = 2015-10-11
※2回目
Date(2015/10/11) = 2015-10-11
Date(2016/12/31) = 2016-12-31
※3回目
Date(2015/10/11) = 2015-10-11
Date(2016/12/31) = 2016-12-31
問題なく動作しています。
この場合、インスタンスは1つだけ作成すればよく、またスレッドの待機も発生しないのでパフォーマンスにも良さそうです。
(DateTimeFormatter の foramt() が実は死ぬほど遅いとかだとダメかもしれませんが、一応そんなことはなさそうです)
スレッドセーフなクラスを使えば完璧?
スレッドセーフなクラスを使えばマルチスレッドについての問題は全て解決かというと、そうでもありません。
使い方によっては、やっぱり synchronized が必要になってきます。
例えば、 HashMap というクラスについて考えてみます。
このクラスはスレッドセーフではありません。複数のスレッドから更新されると、無限ループが発生することがあったりします。2
一方、 Java 1.5 で追加された ConcurrentHashMap はスレッドセーフです。
このクラスはマルチスレッド下でも安全に使うことができます。
しかし、次のような実装を書くとスレッドセーフな ConcurrentHashMap を使っていてもマルチスレッド下で問題が発生します。
package sample;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
public class Main {
private static Map<String, Integer> map = new ConcurrentHashMap<>();
public static void main(String[] args) throws Exception {
new Thread(() ->
add(1)
).start();
new Thread(() ->
add(2)
).start();
Thread.sleep(100);
System.out.println(map.get("foo"));
}
private static void add(int n) {
Integer total = map.getOrDefault("foo", 0);
System.out.println("total = " + total + ", n = " + n);
map.put("foo", total + n);
}
}
Map から "foo" というキーで値を取得し、指定された数だけ加算した結果を再設定しています。
気持ちとしては add(1) と add(2) が実行されるので 3 が結果として出力されてほしいという感じです。
しかしこれを動かすと、結果は次のようになります。
※1回目
total = 0, n = 1
total = 0, n = 2
2
※2回目
total = 0, n = 1
total = 0, n = 2
2
※3回目
total = 0, n = 1
total = 1, n = 2
3
結果は 3 にはならず、 2 になる場合があります(もしかしたら 1 にもなるかも?)。
これは add(1) で Map に 1 が設定される前に add(2) が実行されてしまうために発生しています。
ConcurrentHashMap が保証しているスレッドセーフ性はクラスの中の話だけです。そのクラスを使用している外の実装のスレッドセーフ性までは保証してくれません(当たり前ですね)。
なので、スレッドセーフなクラスを使えばオールOKというわけではありません。やはり、プログラマはその実装が複数のスレッドから同時に実行されても問題ないかを意識しておかなければならない、ということです。
上の例は、現在の値を Map から取得してから結果を反映するまでの間に、他のスレッドが同じ処理を実行できてしまうことが問題です。
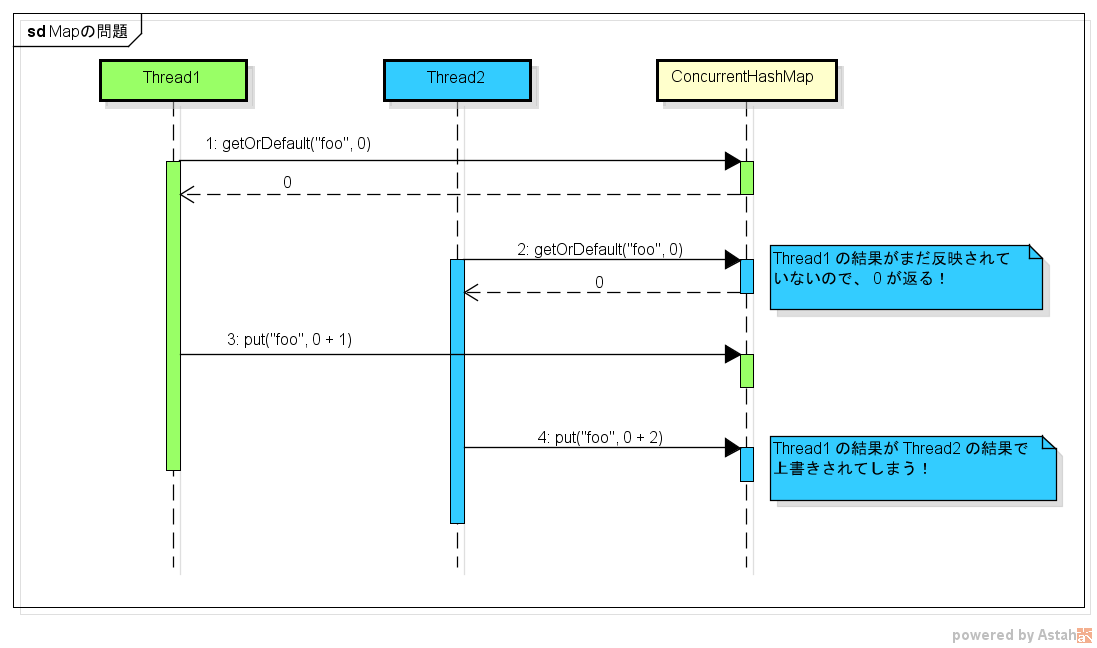
なので、1つのスレッドが一連の処理をしている間は、他のスレッドは処理ができないように排他制御しなければなりません。
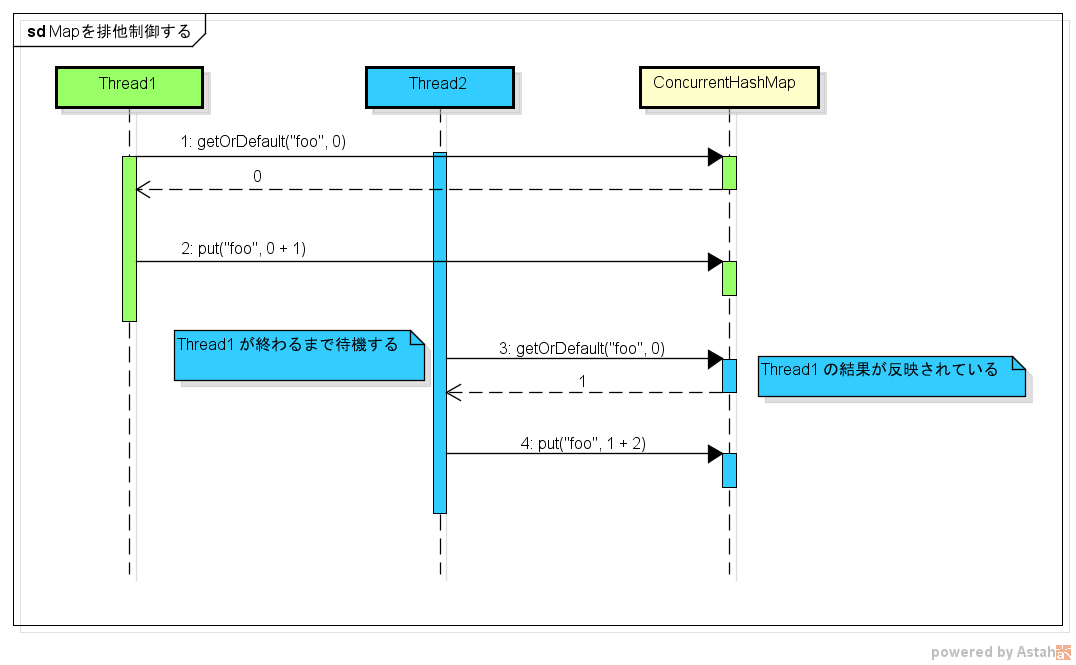
実装は次のように修正することで、意図した通りに動くようになります。
package sample;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
public class Main {
private static Map<String, Integer> map = new ConcurrentHashMap<>();
public static void main(String[] args) throws Exception {
new Thread(() ->
add(1)
).start();
new Thread(() ->
add(2)
).start();
Thread.sleep(100);
System.out.println(map.get("foo"));
}
// ★ add() メソッドに synchronized を追加
synchronized private static void add(int n) {
Integer total = map.getOrDefault("foo", 0);
System.out.println("total = " + total + ", n = " + n);
map.put("foo", total + n);
}
}
add() メソッドに synchronized を付けたので、このメソッドは排他制御がされるようになります。
その結果、意図通り 3 が確実に出力されるようになります。
長くなりましたが、スレッドセーフは Web アプリを含めマルチスレッドで動作するプログラムを作るうえでは避けては通れない話です。
しかも、これはあくまで基本です。
実際に Web アプリを作ろうと思うと、続く分類2・3・4への対応が必要になってきます。
複数プロセス×単一リクエスト
業務で使うアプリとなると、性能を上げるためなどの理由からクラスタリングが採用されることが多いと思います。
そうなると、前述した分類1(単一プロセス・単一リクエスト)の対応だけでは足りなくなります。
というのも、 synchronized は単一の JVM 上でスレッドの処理をロックするものなので、他の JVM で動いているスレッドまで排他制御することはできないからです。
このため、プロセスを跨って排他制御を実現する仕組みが必要になってきます。
私が知る限りでは、以下のような方法があります。
- ファイルを使ってロックする
- DB のロックの仕組みを使う
JVM のプロセスを跨る排他制御なので、必然的に JVM の外にあるものを利用した方法になります。
ファイルを使ってロックする
アプリケーションが動いているマシンのローカルにファイルを出力してロックを実現する方法です。
ファイルが存在するかどうかを見て自力で制御したり、 OS のファイルロックの仕組みを利用して制御する方法があります。
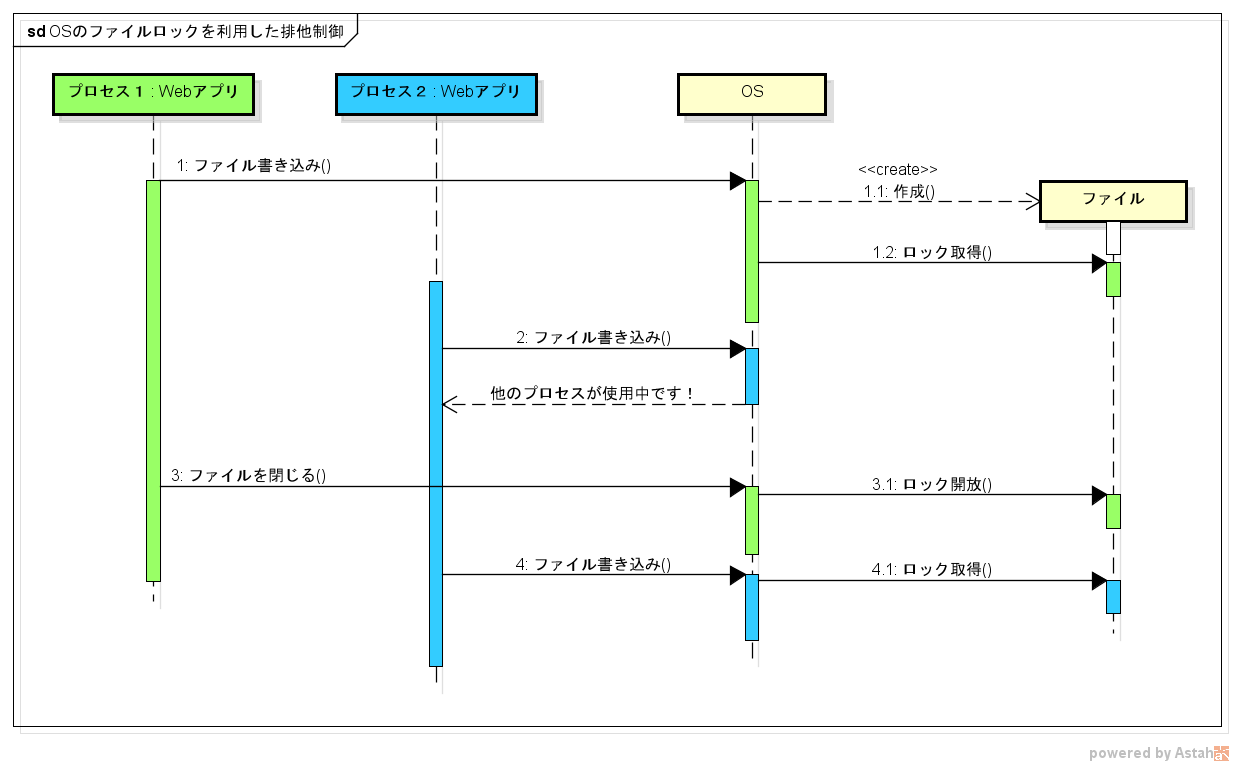
Java の場合はFileCannel クラス に lock() や tryLock() というファイルロックのためのメソッドが用意されています。
これを使えば、 OS のファイルロックの仕組みを利用して、複数の JVM プロセスを跨った排他制御を実現できます。
ただし、このファイルロックは異なる JVM プロセス間で排他制御をするためのものです。
同一プロセス内の複数のスレッドの排他制御には使用できません。スレッド間の排他制御は、やはり synchronized が必要になります。
(複数のスレッドが同じファイルロックを取得しようとすると OverlappingFileLockException がスローされる)
ファイルロックを使用した方法は、全てのアプリケーションのプロセスが同じファイルにアクセスできる環境上で動いている必要があります。
ネットワーク経由でマウントとかすれば実現できなくもないのかもしれませんが、環境構築が複雑化しそうな気はします。
参考
- Javaファイルロックメモ(Hishidama's Java FileLock Memo)
- java - File lock between threads and processes - Stack Overflow
DB のロックの仕組みを使う
システムが DB を使用しているなら、 DB のロックの仕組みを利用する方法があります。
私の経験した開発では、基本的にこの方法が採られていました。
例えば Oracle を使用しているなら SELECT 文に FOR UPDATE をつけてることで、行ロックを取得できます(Oracle 以外もだいたいこの方法だと思います)。
複数のトランザクション3が同じ行をロックしようとすると、後になった方が待機させられるようになります。
待機させられたトランザクションは、先にロックを取得したトランザクションが終了(コミット or ロールバック)すると、再開されます。
ちょうど、 synchronized でスレッドが排他制御されるのと同じ具合です(この場合、ロック対象となった行が synchronized のロックオブジェクトに対応します)。
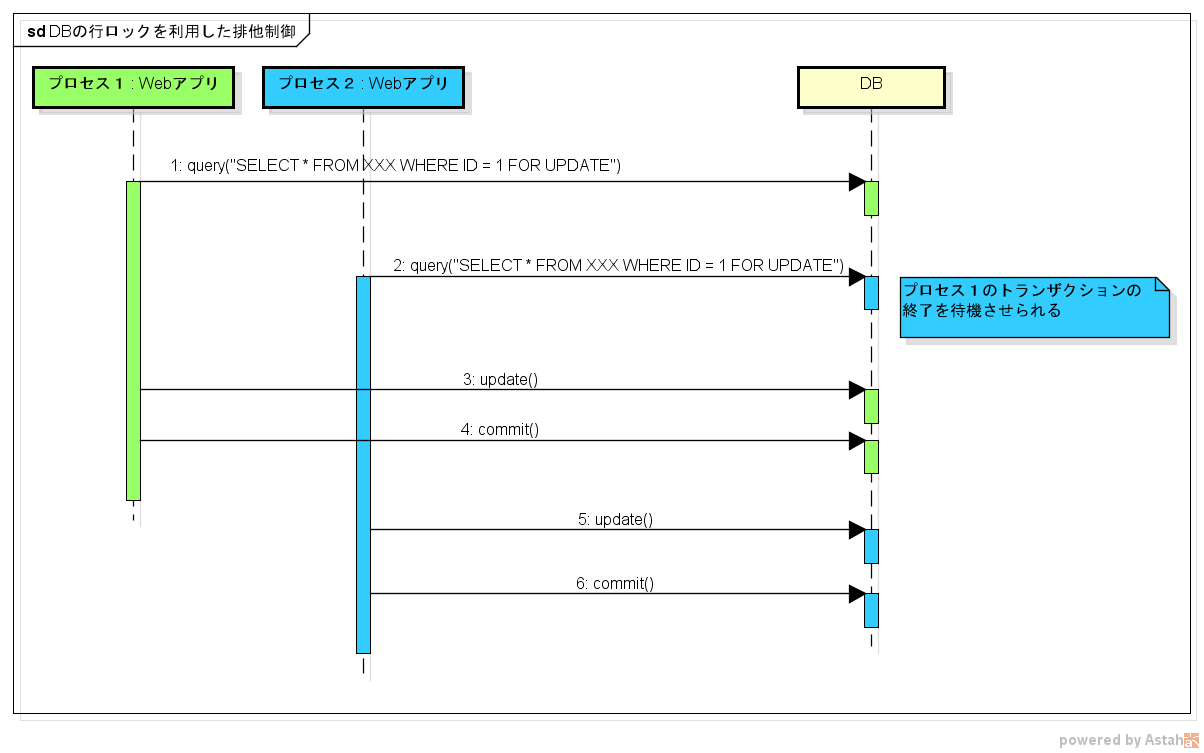
この方法なら、同一プロセス内の複数スレッドの排他制御にも利用できます。
更新対象が DB のデータであれば、分類1のケースでも synchronized の代わりにこの方法が採用されることが多いんじゃないかと思います。
補足:ロック対象を決める
更新対象が複数になる場合
排他制御をする際、 synchronized ならロックオブジェクトを、 DB の行ロックなら対象レコードを選択します。
更新対象のデータが1つの場合は、単純にその対象データを指定すればいいです。
しかし、対象データが複数にまたがるような場合はデッドロックへの注意が必要になります。
この問題には、私が知る限り以下のいずれかの対応が考えられます。
- データをロックする順番が常に一緒になるようにする
- ロック対象を1つにする
1は、例えば「注文」テーブルと「注文明細」テーブルの2つをロックするなら、必ず「注文」→「注文明細」の順番でロックを取るようにする、という方法です。間違って「注文明細」→「注文」の順にロックを取る処理があると、デッドロックが発生する可能性が生まれてしまいます。
更新対象となるテーブルや更新機能が増えてくると、順番を正確に守るのが難しくなってきます。
2は、「注文明細」のロックは取らず、常に親となる「注文」だけをロックするようにします。
順番を考えなくていい分1よりシンプルです。ただし、更新対象が「注文明細」だけであっても、親となる「注文」のロックを忘れずに取得しなければなりません。
また、こちらも更新対象となるテーブルが増えると、「このデータを更新する場合、ロックしなければならない親データはどれ?」というのが分かりにくくなることが考えられます。その場合は、DDD の集約のようなものをしっかり定義していれば、ルートエンティティをロックすればいいことになるので分かりやすいかもしれません。
重複チェックの場合
システムでユニークにならなければならない値が入力項目にある場合(ログインIDや、マスタデータのコード値など)、すでにその値が登録されていないことをチェックしなければなりません。
この場合、更新対象となる特定のオブジェクトやレコードが存在するわけではないので、表ロックなどもっと広い範囲のロックが必要になります。
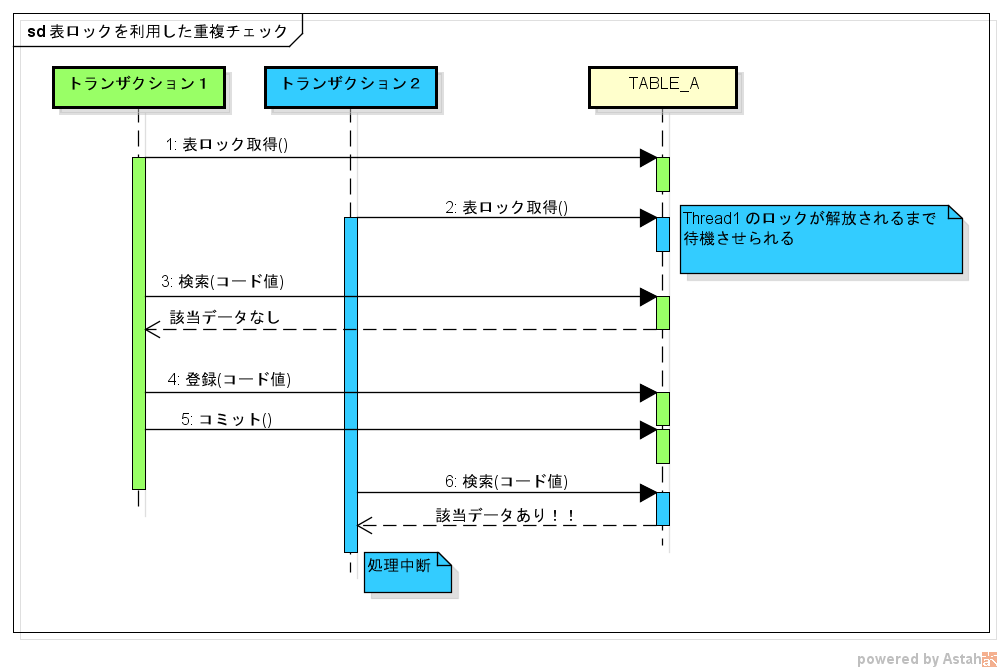
重複チェックは主に「登録」のときに必要になる処理です。
「同時更新」とかの言葉に釣られて「更新のときだけ注意すればいいのかぁ」と思っていると、つい忘れてしまうのではないでしょうか(私だけ?)
UKを利用して重複チェックをする
DB にユニークキー制約(UK)を指定していれば、重複の有無は DB に任せたほうが楽そうな気がします。
しかし、私がこれまで関わったプロジェクトでは、 UK を利用した重複チェックは行われていませんでした。
改めて、 UK を利用した方法を考えると、なんだか良くないような気もします。
理由を挙げるとすると、次のようなものが考えられるでしょうか。
- エラーコードによるハンドリングが必要になるので、例外の解析が必要になり、DB製品に強く依存してしまう
- 例外を使ってハンドリングすることになるので、パフォーマンス的に良くない
しかし、1については、
- そもそも DB を切り替えるようなことは普通起こらないし、起こったとしたらもっと広い範囲で影響が出るのでエラーコードのハンドリングだけ気にするのも変な話
- どうせ SQL とかは DB 製品に依存したものになりがち
と考えるとそんなに強い理由にもならない気はします。
また、 Spring Framework を使えばキー重複エラーを表す抽象的な例外がスローされるそうなので、 DB 製品に依存しない例外ハンドリングが可能になりそうです。
2については、ループで何回も実行でもしない限りはそんなに問題になることはない気はします。
世間一般的には、どうしているものなのでしょうか?
※ちなみに大人の事情4でユニークキーが設定できない場合もあると思います(涙)
複数リクエスト
分類3と4の違いはプロセス数の差ですが、そこで必要になる対応は分類2の場合と同じになると思います。
なので、ここではリクエストが複数に分かれることによって発生する問題と対処方に絞って整理します。
前述の ConcurrentHashMap の話は、スレッドをアプリケーションのユーザー、 Map をデータベースのテーブル に置き換えて考えることができます。
A さん、 B さんという2人のユーザーがいたとします。A さんと B さんがほぼ同時に画面を表示したとき、テーブルの値は 0 だったのでそれぞれ 0 と表示されます。A さんは 0 に +1 した値を入力して保存を行い、B さんは 0 に +2 した値を入力して保存を行いました。
何も制御をしていない場合、最終的にテーブルに書き込まれる値は後で更新が実行された方になります。
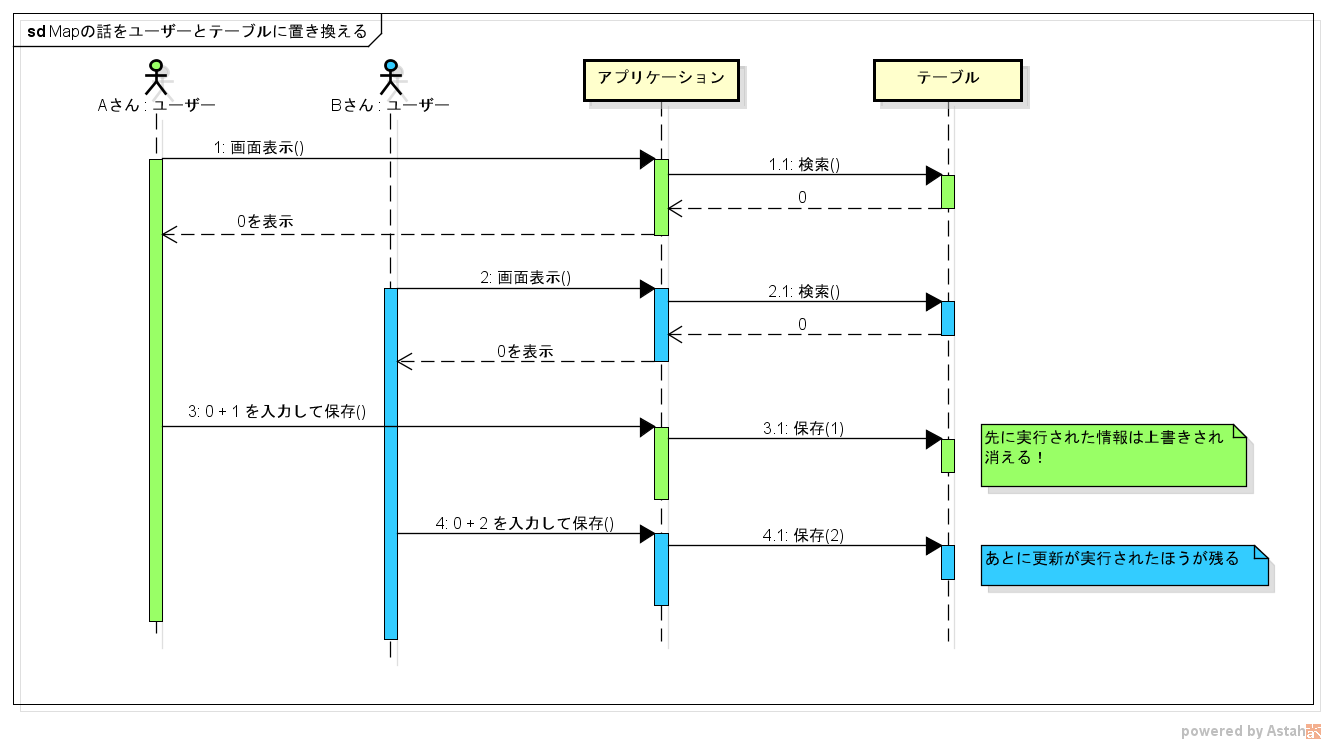
このように更新に関する一連の処理が複数のリクエストにまたがっている場合、 synchronized や DB の行ロックだけでは排他制御ができません。
そのため、また別の対策が必要になってきます。
対応方法
どちらかの変更が消えてしまうというのは、特に企業の重要な情報を扱う業務アプリとかだと好ましい挙動とは言えません。
この問題に関して、私が知る限り次の3つの対応策があります。
- 同時更新を許す
- 更新作業は1人のユーザーだけが行えるようにする
- 保存するときに同時更新されていないかチェックする
同時更新を許す
- 運用上、その更新機能を使うユーザーが1人しかいない
- データの更新頻度が非常に低く、万一後勝ちになっても特に問題のないデータである
重要な情報を扱う業務アプリといっても、全部が全部重要というわけでないでしょう。中にはこのような割と緩いデータもあるかもしれません(システムによっては無いかもしれませんが...)。
そのようなデータの更新機能については、無理に頑張って同時更新のための制御を入れるとコストパフォーマンスが悪くなるかもしれません。
この場合、同時更新を許してしまうのも選択肢としてアリかなと思います。
もちろん、後勝ちになっても問題ないかどうかの判断はお客さんと要相談です。
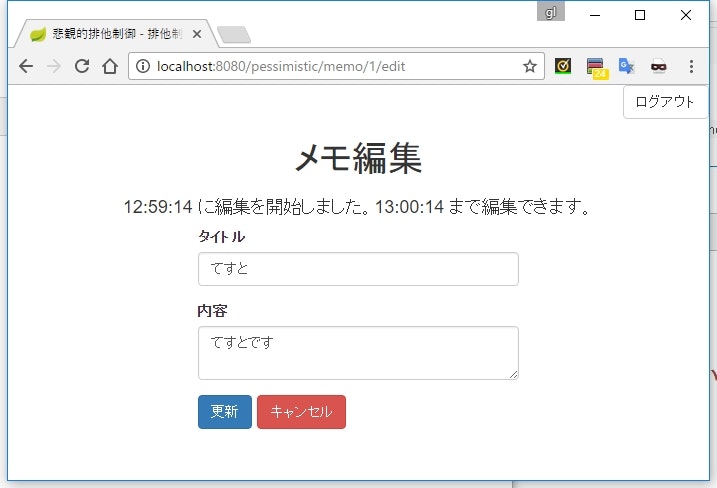
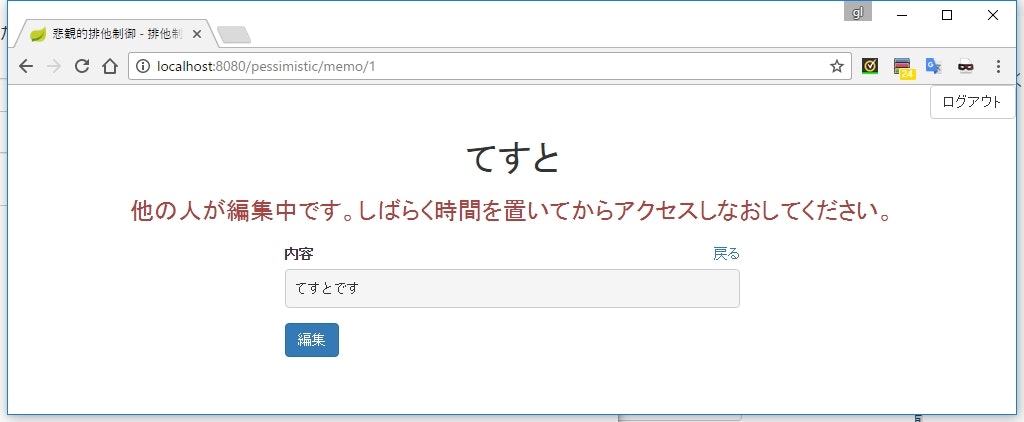
更新作業は1人のユーザーだけが行えるようにする
synchronized でスレッドが排他制御されるような仕組みを、アプリケーションの仕組みとして実装する方法です。
悲観的排他制御と呼ばれたりしている気がします。
最初に更新機能を使い始めたユーザーだけが作業を継続でき、他のユーザーは作業を開始することができないようにします。
ちょうど VSS のチェックアウトや、 SVN の needs lock のようなイメージです。
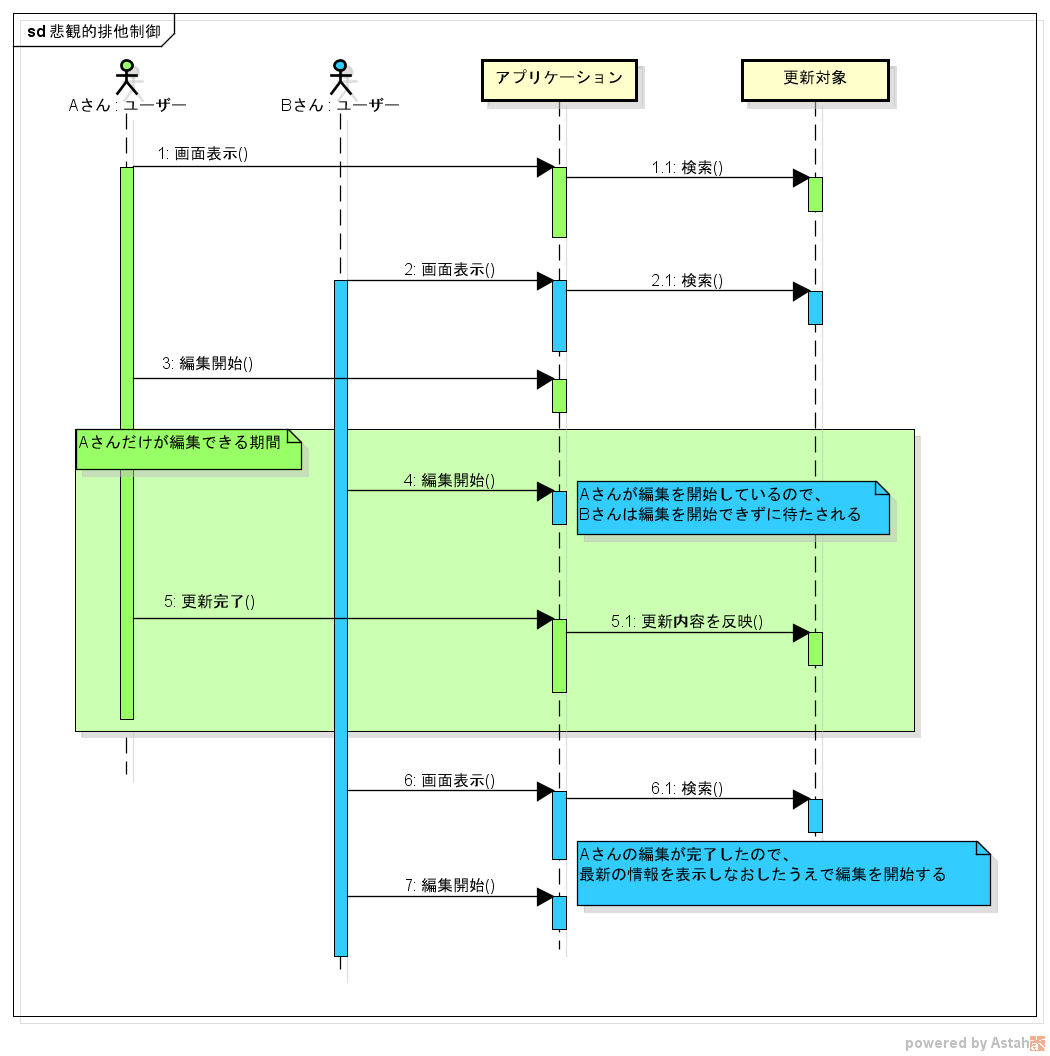
「一方のユーザーの知らないところで別の更新作業が進められていて、こちらの編集が無駄になった」というような余計なオーバーヘッドが発生しなくなります。
そのため、頻繁に同時更新されるような機能の場合は悲観的排他制御を行うことで、業務としてみたときの全体的なパフォーマンスが向上する可能性があります。
しかし、悲観的排他制御は後述する楽観的排他制御に比べて実装がかなり複雑になります。
そのせいか、実際に採用されているケースは私自身あまり見たことがありません。
唯一記憶にあるのは、Weblogic の管理コンソールくらいです(もしかしたら気付いていないだけで色々あるのかもしれません)。
私が今まで関わったプロジェクトは全て楽観的排他制御だったので、悲観的排他制御を実装した経験はありません。
もし悲観的排他制御を実現しようと思った場合、ざっと次のような制御になりそうな気がします。
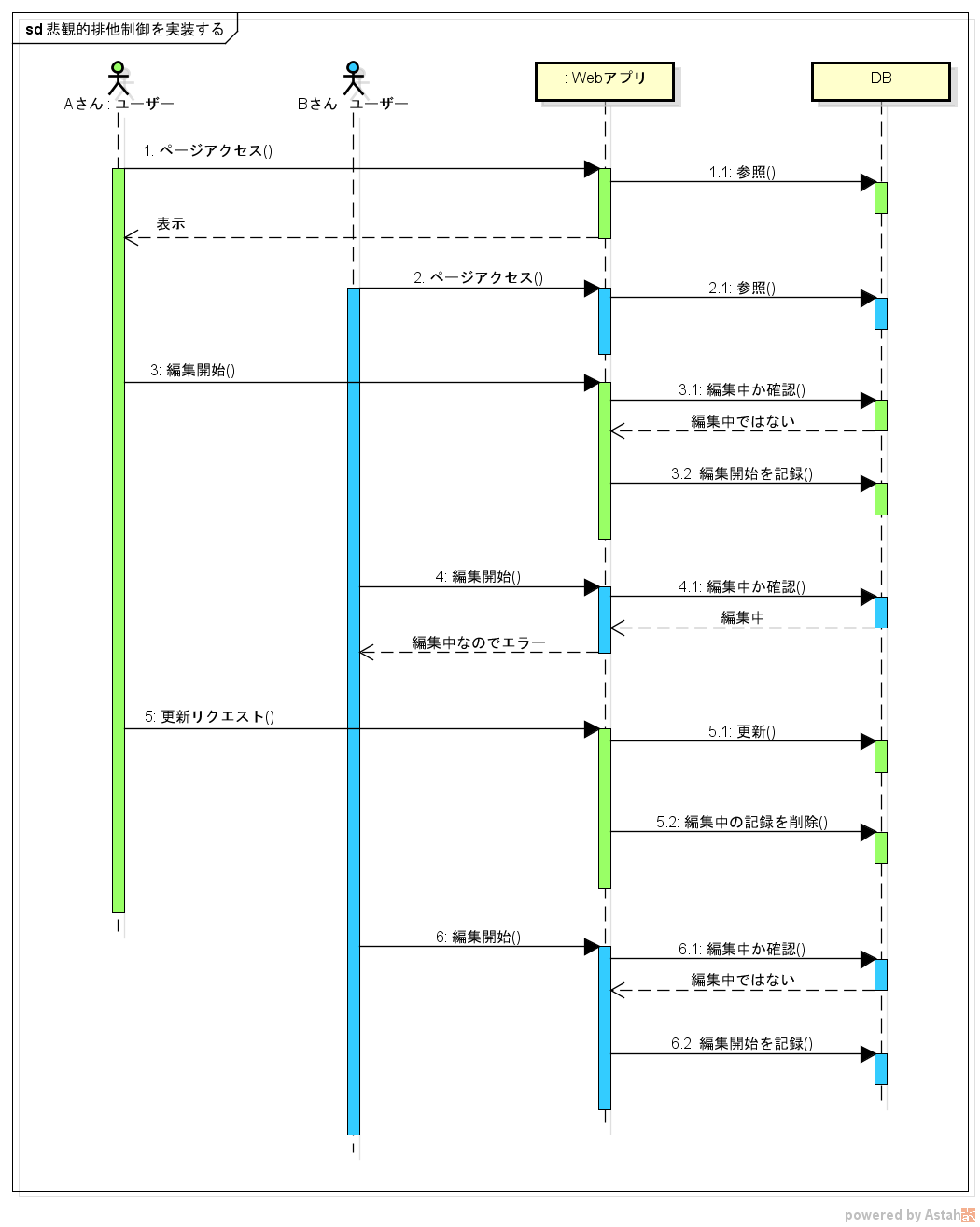
DB に編集中かどうかの情報を記録しておき、編集を開始するときにその情報を検索して編集開始の可否を判断します。
なんか複雑そうですね。
さらに、
- A さんが編集中のまま長期休暇に入ったらどうする?
- ロックに有効期限を設ける?
- ログアウトやセッション切れで確実にロックを解除しないといけない
- ログアウトはしないがページが切り替えらえたら?
- 編集のキャンセルができるように
- etc...
ちょっと考えただけで色々考慮しなければならないことが多そうです。
(※実際に作成してみましたが、とても大変でした。。。)
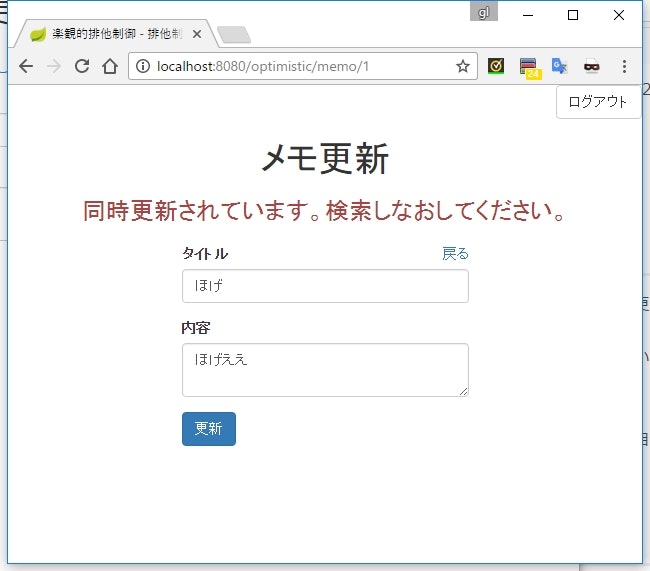
保存するときに同時更新されていないかチェックする
編集の開始時にはロックを取得せず、更新リクエストを送信したときに他のユーザーによって更新されていないかチェックする方法です。
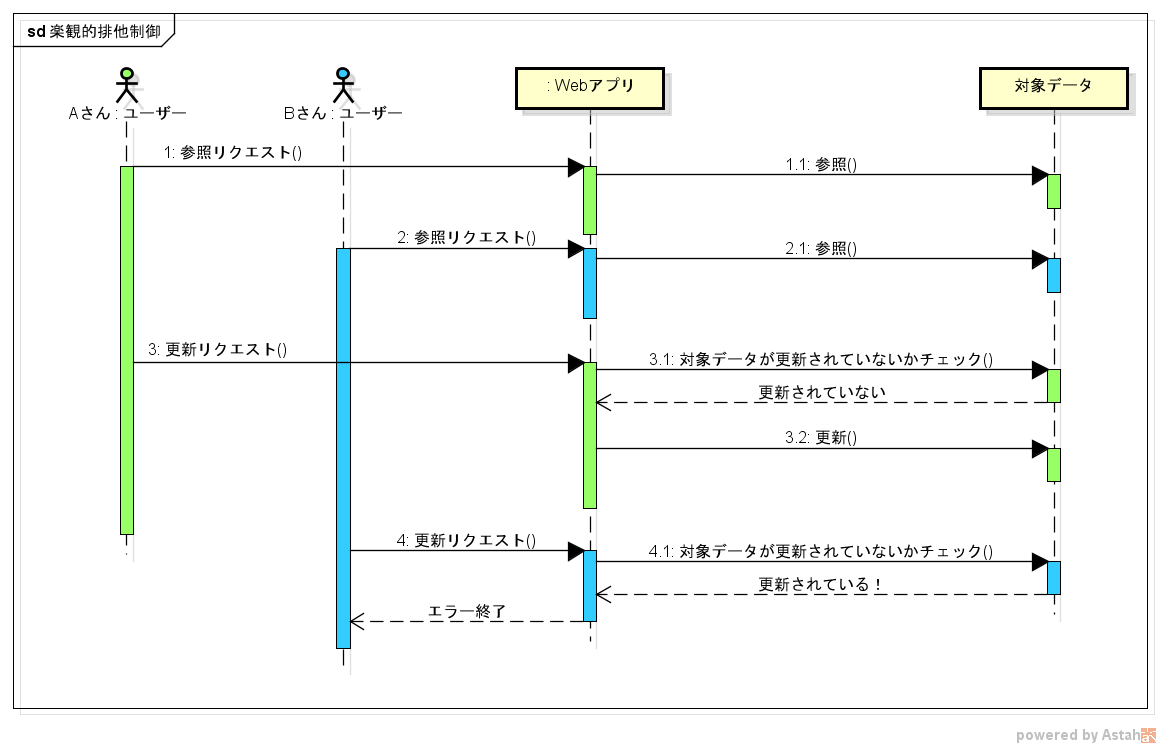
対象データが更新されているかどうかは、更新日時を対象データに持たせることで実現することが多いと思います。
最初に参照リクエストを受け取ったときに、その時の更新日時もユーザーに返すようにしておきます。
そして、更新リクエストを送信する際は、参照リクエストのときに受け取っていた更新日時も渡します。
ユーザーから受け取った更新日時 < 最新の対象データが持つ更新日時 の場合、対象データが誰か別のユーザーによって更新されていることになります。その場合は、アプリケーションはユーザーにエラーを返すようにします。
ここで注意なのが、「更新リクエスト」自体は分類1(クラスタ環境なら2)と同じものになる点です。
そのため、更新リクエストはしっかりと排他制御をする必要があります。
日付のチェックだけして安心していていると、結局更新リクエストが同時に来たときに正しくデータが更新されなくなってしまいます。
実装例
ここまでの話のうち、分類3・4の悲観的排他制御と楽観的排他制御について、実際にサンプルアプリを作ってみました。
こちら から sample.jar をダウンロードしてください。
java -jar sample.jar でサーバーが起動するので、ブラウザで http://localhost:8080/ にアクセスしてください。
まとめというか感想というか
データが同時に更新されるときに考慮しないといけないことは色々あります。
この辺を調べると、よくスレッドセーフや DB の行ロック、楽観的排他制御など様々なレベル感の情報が出てきます。
自分はこれらの情報に対して、それぞれの境界というか関係性みたいなのがモヤモヤした状態でした。
今回自分なりに整理しなおした結果、上のようになりました。個人的には割とすっきりしています。
基本は分類1のような状態から始まり、アプリケーションの特性(クラスタとか)によって段階的・複合的に適用されていくものなのかなぁ、と思いました。
参考
- データの同時更新を防ぐための排他制御 (1/3):CodeZine(コードジン)
- 悲観的排他制御と楽観的排他制御-同時更新の対処方法 | アイビースター
- 排他制御 - Wikipedia
- 表ロックの種類と相互関係 - オラクル・Oracleをマスターするための基本と仕組み