Apache Lucene とは?
Java で書かれたオープンソースの検索エンジンライブラリ。
読み方は「ルシーン」。
Lucene を組み込んで検索サービスを提供する Apache Solr というのもある。
環境
OS
- Windows 7 64bit SP1
Java
- 1.8.0_20
デモを動かす
インストール
ここ から zip または tar をダウンロードする。
以後、 F:\tmp\lucene の下に以下のように解凍したと仮定して説明を続ける。
F:\tmp\lucene
`-lucene-4.9.0
|-CHANGES.txt
|-JRE_VERSION_MIGRATION.txt
|-LICENSE.txt
|-MIGRATE.txt
|-NOTICE.txt
|-README.txt
|-SYSTEM_REQUIREMENTS.txt
|-analysis/
|-benchmark/
|-classification/
|-codecs/
:
(以下略)
コマンドラインから F:\tmp\lucene に移動する。
>cd /d F:\tmp\lucene
クラスパスを設定する
>set classpath=lucene-4.9.0/core/lucene-core-4.9.0.jar;lucene-4.9.0/queryparser/lucene-queryparser-4.9.0.jar;lucene-4.9.0/analysis/common/lucene-analyzers-common-4.9.0.jar;lucene-4.9.0/demo/lucene-demo-4.9.0.jar
以下4つの jar ファイルを CLASSPATH に追加している。
- lucene-core-4.9.0.jar
- lucene-queryparser-4.9.0.jar(検索のときに使用する)
- lucene-analyzers-common-4.9.0.jar(インデックス作成のときに使用する)
- lucene-demo-4.9.0.jar(デモの実装)
インデックスを作成する
>java org.apache.lucene.demo.IndexFiles -docs lucene-4.9.0/docs
.\index の下にインデックスファイルが生成される(明示する場合は -index オプションで指定する)。
検索する
>java org.apache.lucene.demo.SearchFiles
Enter query:
検索したいキーワードを入力して Enter すると、検索結果が出力される。
apache
Searching for: apache
5757 total matching documents
1. lucene-4.9.0\docs\core\allclasses-noframe.html
2. lucene-4.9.0\docs\facet\allclasses-noframe.html
3. lucene-4.9.0\docs\test-framework\allclasses-frame.html
4. lucene-4.9.0\docs\test-framework\allclasses-noframe.html
5. lucene-4.9.0\docs\analyzers-common\overview-frame.html
6. lucene-4.9.0\docs\highlighter\allclasses-frame.html
7. lucene-4.9.0\docs\highlighter\allclasses-noframe.html
8. lucene-4.9.0\docs\core\overview-frame.html
9. lucene-4.9.0\docs\test-framework\overview-frame.html
10. lucene-4.9.0\docs\suggest\allclasses-frame.html
Press (n)ext page, (q)uit or enter number to jump to a page.
n で検索結果の続きを表示し、 q で表示を終了し、次の検索キーワード入力を待機する。
Ctrl + C で終了。
実装する
準備
依存関係
dependencies {
compile 'org.apache.lucene:lucene-queryparser:4.9.0'
compile 'org.apache.lucene:lucene-analyzers-common:4.9.0'
}
インデックスを生成する
package sample.lucene;
import java.io.BufferedReader;
import java.io.File;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.nio.file.Files;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.document.LongField;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.IndexWriterConfig.OpenMode;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class Main {
public static void main(String[] args) throws IOException {
// インデックスの出力先を定義
Directory indexDir = FSDirectory.open(new File("index"));
// テキストの解析方法(アナライザー)を定義
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_4_9);
// 解析方法の設定
IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_4_9, analyzer);
// インデックスが既に存在する場合の動作を定義する(OpenMode.CREATE の場合、新規に作成して上書きする)
config.setOpenMode(OpenMode.CREATE);
// インデックスを作成するファイル
File file = new File("MIGRATE.html");
try (IndexWriter writer = new IndexWriter(indexDir, config);
BufferedReader br = Files.newBufferedReader(file.toPath(), StandardCharsets.UTF_8)) {
// Document に、インデックスに保存する各ファイルの情報を設定する
Document doc = new Document();
doc.add(new StringField("path", file.getPath(), Store.YES));
doc.add(new TextField("contents", br));
// インデックスを書き出す
writer.addDocument(doc);
}
}
}
MIGRATE.html というファイル(docs の下にあるやつ)を対象にして、インデックスを作成してみている。
複数のファイルをインデックスに登録する
デモの IndexFiles の実装を見ればわかるけど、ゴリゴリ自前でフォルダの再帰検索を実装し、インデックスを作成する必要がある模様。
検索する
package sample.lucene;
import java.io.BufferedReader;
import java.io.File;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.nio.file.Files;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.document.LongField;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.IndexWriterConfig.OpenMode;
import org.apache.lucene.queryparser.classic.ParseException;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class Main {
public static void main(String[] args) throws IOException, ParseException {
// 検索文字列を解析するためのパーサーを生成する
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_4_9);
// 検索対象のフィールドを第二引数で指定している
QueryParser parser = new QueryParser(Version.LUCENE_4_9, "contents", analyzer);
// 検索文字列を解析する
String searchText = "lucene";
Query query = parser.parse(searchText);
// 検索で使用する IndexSearcher を生成する
Directory indexDir = FSDirectory.open(new File("index"));
IndexReader indexReader = DirectoryReader.open(indexDir);
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
// 検索を実行する(第二引数は、検索結果の最大数)
TopDocs results = indexSearcher.search(query, 10);
// 検索の結果、該当した Document を1つずつ取得する
for (ScoreDoc scoreDoc : results.scoreDocs) {
Document doc = indexSearcher.doc(scoreDoc.doc);
// Document の path を取得して出力する
String path = doc.get("path");
System.out.println(path);
}
}
}
作成したインデックスを元に、 lucene というキーワードを検索している。
※当然だけど、検索結果は MIGRATE.html の1つだけ。
行番号を出力する
行番号を表示しようと思ったら、 Document の作り方を工夫する必要があるっぽい。
実装例ではファイル1つにつき1つの Document を作成している。
これを、ファイル1行につき Document を1つ作成するように変更し、 Document のフィールドに行番号を保存するものを追加する。
try (IndexWriter writer = new IndexWriter(indexDir, config)) {
int lineNumber = 1;
for (String line : Files.readAllLines(file.toPath(), StandardCharsets.UTF_8)) { // 1行ずつ Document を生成する
Document doc = new Document();
doc.add(new StringField("path", file.getPath(), Store.YES));
doc.add(new TextField("contents", new StringReader(line)));
doc.add(new LongField("lineNumber", lineNumber++, Store.YES)); // ここで行番号を記録
writer.addDocument(doc);
}
}
日本語の解析
StandardAnalyzer の問題
前述の例では StandardAnalyzer を使用している。
しかし、この Analyzer だと、日本語の解析が期待する形にならない。
例えば、以下のようなテキストファイルがあったとする。
日本語で書かれた文書
これを StandardAnalyzer で解析すると、インデックスは以下のように作成される。
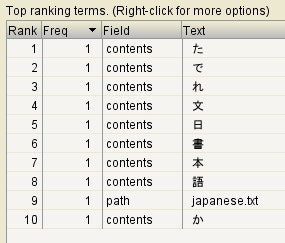
1文字1文字細切れになっていて、日本語の単語などは完全に無視されている。
この状態で、例えば「文字」という文字列で検索をしたとする。
「文字」という文字列は「文」と「字」に分割して検索される。
すると、japanese.txt は、「文」という文字をインデックスに持っているので、 Lucene は japanese.txt を対象として抽出してしまう(実際は「文字」なんて単語は含まれていないのに!)。
この辺の詳しい話は「検索エンジンの常識をApache Solrで身につける - @IT」とかが分かりやすいと思う。
インデックスの確認について
Lucene が生成したインデックスは、 Luke というツールを使うと内容を確認できる。
ただし、公式のアップデートは 4.0.0 で止まっているようで、 Lucene 4.9.0 で出力したインデックスは参照できない。
代わりに、有志?が最新の Lucene にも対応した Luke を GitHub で公開している ので、これを使う。
プロジェクトを落としてきて、 ant でビルドすると dist の下に lukeall-<バージョン>.jar が出力される。
あとは、 java -jar lukeall-<バージョン>.jar で起動できる。
lucene-gosen で日本語を解析する
lucene-gosen とは
上述の問題に対応するためには、__形態素解析__というのが必要になる。
lucene-gosen は、日本語の__形態素解析__ができるオープンソースのライブラリ。
lucene-gosen を使う
こちら から jar をダウンロードできる。
※最新版は「Donwloads」ではなく、「External links」からダウンロードできる。
lucene-gosen-4.9.0.1-naist-chasen.jar をダウンロードしてきて、プロジェクトのクラスパスに追加する。
※**-naist-chasen と **-ipadic は、 jar 内部に辞書が組み込まれている。
実装上の変更は、 StandardAnalyzer を使っていた部分を org.apache.lucene.analysis.gosen.GosenAnalyzer に置き換えるだけ。
Analyzer analyzer = new GosenAnalyzer(Version.LUCENE_4_9);
IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_4_9, analyzer);
Analyzer analyzer = new GosenAnalyzer(Version.LUCENE_4_9);
QueryParser parser = new QueryParser(Version.LUCENE_4_9, "contents", analyzer);
※Google で「lucene-gosen」の使い方を検索していると JapaneseAnalyzer を使った例が多く出てくるが、途中でパッケージ構成などが大きく変更され、現在は GosenAnalyzer を使うようになった模様。
生成されたインデックス
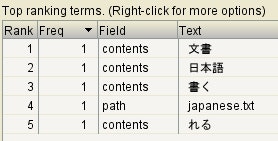
ちゃんと、日本語として意味のある単位に分割されている。
これだと、「文字」という文字列で検索しても japanese.txt が抽出対象になることはない。
参考
- Lucene Search Result with Line Numbers? | Lucene | Java-User
- 全文検索システムApache Luceneを使ってみる - Java入門
- Overview (Lucene 4.9.0 API)
- Luke - Luceneインデックスブラウザ | 関口宏司のLuceneブログ
- Luke (Lucene インデックスブラウザ) の lucene-4.x 対応版 - ソフトウェアエンジニア現役続行
- 【重要】lucene-gosen 2.0.0リリース | johtani の日記
- 形態素解析とは 【 morphological analysis 】 - 意味/解説/説明/定義 : IT用語辞典