環境構築
JPA の基本的な話
JPQL の話
Criteria API の話
マッピング方法だけを確認しやすいようにした一覧を作成しました。
JPA マッピングカタログ - Qiita
はじめに
オブジェクト指向で考えられたドメインモデルと、正規化などを考慮して考えられたリレーショナルデータベースのテーブルでは、データの持たせ方に違いが生まれる。
この違いをインピーダンスミスマッチと言う。
インピーダンスミスマッチを解決するには、データベースから取得したレコードをオブジェクトにマッピングする処理が必要になる(さらに、永続化するときは逆変換が必要)。
オブジェクトとテーブルの構造が1対1で対応していれば、この変換はそこまで大変ではない。
しかし、そうでない場合、変換を自力で実装するのは非常に骨が折れる。
O/R マッパーはこの変換を自動でやってくれるフレームワークで、 JPA では、様々なマッピングをアノテーションで定義することができるようになっている。
ドメインモデルの実装に具体的な技術要素である JPA のアノテーションが設定されることに若干の拒絶反応が起こりそうになるが、そこはマッピングを自動化できることとのトレードオフとして目をつむるべきかなと個人的に思っている。
基本編
基本
エンティティ

package sample.javaee.jpa.entity.mapping;
import javax.persistence.Entity;
import javax.persistence.Id;
@Entity
public class Reimu {
@Id
private Long id;
@Override
public String toString() {
return "Reimu{" + "id=" + id + '}';
}
}
データベース
CREATE TABLE `reimu` (
`id` int(11) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
- デフォルトでは、エンティティは同じ名前のテーブルとマッピングされる。
- エンティティの名前は、特に指定しなければクラス名と同じになる。
- エンティティには、必ず1つは
@Idでアノテートされたフィールドが必要。 - エンティティは、 public または protected で、引数の無いコンストラクタが必要。
- フィールドは、可視性が private でもマッピングできる。
- デフォルトでは、フィールドは同じ名前のカラムとマッピングされる。
テーブル名・カラム名を指定する
エンティティ

package sample.javaee.jpa.entity.mapping;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.Id;
import javax.persistence.Table;
@Entity
@Table(name = "kirisame_marisa")
public class KirisameMarisa {
@Id
@Column(name = "id_column")
private Long id;
@Override
public String toString() {
return "KirisameMarisa{" + "id=" + id + '}';
}
}
データベース
CREATE TABLE `kirisame_marisa` (
`id_column` int(11) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`id_column`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
- エンティティ名とテーブル名が異なる場合は、
@Tableでクラスをアノテートし、name属性でテーブル名を指定する。 - フィールド名とカラム名が異なる場合は、
@Columnでフィールドをアノテートし、name属性でカラム名を指定する。
ID が自動生成されることを設定する
例えば、 MySQL の場合は AUTO_INCREMENT の仕組みを使って ID が採番される。
また、 Oracle の場合はシーケンスオブジェクトを使って ID を採番する。
ID がアプリケーション以外の仕組みによって生成されることを設定しておくと、 persist() するときにその仕組を利用して ID が自動生成される。
また、 ID が自動生成されることを設定しておくことで、 persist() した後に自動生成された ID を取得できるようになる(設定していないと、取得できない)。
MySQL の AUTO_INCREMENT
エンティティ

package sample.javaee.jpa.entity.mapping;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
@Entity
public class SinGyoku {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String value;
public void setValue(String value) {
this.value = value;
}
@Override
public String toString() {
return "SinGyoku{" + "id=" + id + ", value=" + value + '}';
}
}
データベース
CREATE TABLE `singyoku` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`value` varchar(45) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
動作確認
SinGyoku sinGyoku = new SinGyoku();
sinGyoku.setValue("test");
this.em.persist(sinGyoku);
System.out.println(sinGyoku);
this.em.flush();
System.out.println(sinGyoku);
情報: SinGyoku{id=null, value=test}
情報: SinGyoku{id=1, value=test}
-
@GeneratedValueでフィールドをアノテートすることで、そのフィールドが自動生成されることを設定できる。 -
strategy属性に、その項目がどのようにして生成されるかを指定する。 - MySQL の AUTO_INCREMENT では、
GenerationType.IDENTITYを指定する。 - MySQL の AUTO_INCREMENT は INSERT 文を発行するときに ID を採番する。よって
EntityManager#flush()で明示的にコミットを実行しないと、自動生成された ID を取得できない。
Oracle のシーケンスオブジェクト
※Oracle に接続するための JDBC Connection Pool と JDBC Resource を予め GlassFish に登録しておくこと(サンプル実装では、 OracleUnit という名前で永続ユニットを定義した)。
エンティティ

package sample.javaee.jpa.entity.mapping;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.SequenceGenerator;
import javax.persistence.Table;
@Entity
@Table(name = "yuugen_magan")
public class YuugenMagan {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE, generator = "yuugen_magan_seq_gen")
@SequenceGenerator(name = "yuugen_magan_seq_gen", sequenceName = "yuugen_magan_seq", allocationSize = 1)
private Long id;
private String value;
public void setValue(String value) {
this.value = value;
}
@Override
public String toString() {
return "YuugenMagan{" + "id=" + id + ", value=" + value + '}';
}
}
データベース
CREATE TABLE yuugen_magan (
ID NUMBER(10),
VALUE VARCHAR2(128),
PRIMARY KEY(ID)
);
CREATE SEQUENCE yuugen_magan_seq;
動作確認
YuugenMagan yuugenMagan = new YuugenMagan();
yuugenMagan.setValue("test");
this.em.persist(yuugenMagan);
System.out.println(yuugenMagan);
情報: YuugenMagan{id=1, value=test}
- シーケンスオブジェクトを使用する場合は、
@GeneratedValueのstrategyにGenerationType.SEQUENCEを指定する。-
generator属性には、 ID を生成するジェネレータの名前を指定する。 - ジェネレータの定義は、
@SequenceGeneratorアノテーションで行う。 -
name属性にジェネレータの名前を指定し、sequenceName属性でシーケンスオブジェクトの名前を指定する。
-
- シーケンスオブジェクトの場合は、コミット前でも EntityManager が次のシーケンス値を取得できるので、
flush()する前でも自動生成された ID を参照することができる。 -
allocationSizeはシーケンス値の増分(デフォルトは 50)。
シーケンス生成用のテーブルを使用する
エンティティ

package sample.javaee.jpa.entity.mapping;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.TableGenerator;
@Entity
public class Elis {
@Id
@GeneratedValue(strategy = GenerationType.TABLE, generator = "elis_seq_generator")
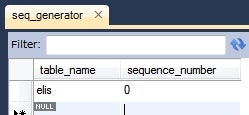
@TableGenerator(name = "elis_seq_generator",
table = "seq_generator",
pkColumnName = "table_name",
valueColumnName = "sequence_number",
pkColumnValue = "elis",
allocationSize = 1)
private Long id;
private String value;
public void setValue(String value) {
this.value = value;
}
@Override
public String toString() {
return "Elis{" + "id=" + id + ", value=" + value + '}';
}
}
データベース
CREATE TABLE `elis` (
`id` int(11) NOT NULL,
`value` varchar(45) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `seq_generator` (
`table_name` varchar(128) NOT NULL,
`sequence_number` int(11) NOT NULL,
PRIMARY KEY (`table_name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
動作確認
Elis elis = new Elis();
elis.setValue("test");
this.em.persist(elis);
System.out.println(elis);
情報: Elis{id=1, value=test}
- シーケンスを採番するための専用のテーブルを使用する場合、
strategyにGenerationType.TABLEを指定する。 -
generatorには、@TableGeneratorで定義した名前を指定する。 -
@TableGeneratorでは、シーケンス採番用のテーブルの情報を定義する。
| 属性 | 説明 |
|---|---|
| name | ジェネレータの名前 |
| table | シーケンスを採番するテーブルの名前 |
| pkColumnName | シーケンス採番テーブルの行を特定するためのカラムの名前 |
| valueColumnName | シーケンス値を保存しておくカラムの名前 |
| pkColumnValue | このジェネレータが採番に用いる行を特定するための値。pkColumnName に保存されている値。 |
| allocationSize | シーケンスの増分値(デフォルトは 50) |
複合主キーとマッピングする
@EmbeddedId を使用したパターン
エンティティ
package sample.javaee.jpa.entity.mapping;
import javax.persistence.EmbeddedId;
import javax.persistence.Entity;
@Entity
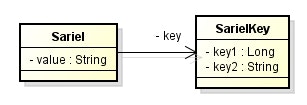
public class Sariel {
@EmbeddedId
private SarielKey key;
private String value;
public void setKey(SarielKey key) {
this.key = key;
}
public void setValue(String value) {
this.value = value;
}
@Override
public String toString() {
return "Sariel{" + "key=" + key + ", value=" + value + '}';
}
}
package sample.javaee.jpa.entity.mapping;
import java.io.Serializable;
import java.util.Objects;
import javax.persistence.Embeddable;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
@Embeddable
public class SarielKey implements Serializable {
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long key1;
private String key2;
public void setKey2(String key2) {
this.key2 = key2;
}
@Override
public String toString() {
return "SarielKey{" + "key1=" + key1 + ", key2=" + key2 + '}';
}
@Override
public int hashCode() {
// 省略
}
@Override
public boolean equals(Object obj) {
// 省略
}
}
データベース
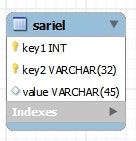
CREATE TABLE `sariel` (
`key1` int(11) NOT NULL AUTO_INCREMENT,
`key2` varchar(32) NOT NULL,
`value` varchar(45) DEFAULT NULL,
PRIMARY KEY (`key1`,`key2`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
動作確認
SarielKey key = new SarielKey();
key.setKey2("test");
Sariel sariel = new Sariel();
sariel.setKey(key);
sariel.setValue("TEST");
this.em.persist(sariel);
this.em.flush();
System.out.println(sariel);
情報: Sariel{key=SarielKey{key1=1, key2=test}, value=TEST}
- 複合主キーをマッピングする場合の1つの方法として、
@EmbeddedIdアノテーションを使用した方法がある。 - 複合主キーに指定したカラムを持つ主キー用のクラス(
SarielKey)を作成し、そのクラスを@Embeddableでアノテートする。 - メインのエンティティ側(
Sariel)には、主キー用のクラスをフィールドに持たせ、@EmbeddedIdでアノテートする。 - 主キーの一意性を保証するため、
equals()とhashCode()をオーバーライドする(コードは NetBeans の機能で自動生成したもの)。
equals() と hashCode() をオーバーライドする理由
デフォルトの equals() メソッドは、インスタンスが同じかどうかを比較するようになっている。
つまり、キー項目に同じ値が設定されていても、インスタンスが異なれば equals() メソッドは false を返してしまう。
そうなると、同じキー項目をもつ異なるエンティティオブジェクトが生成される可能性が生まれ、主キーの一意性が保証されなくなる。
このため、キー項目を持つクラスは equals() メソッドをオーバーライドしなければならない。
そして、 equals() メソッドをオーバーライドするので、合わせて hashCode() もオーバーライドしなければならない(詳しくは Effective Java を参照)。
@IdClass を使用したパターン
エンティティ
package sample.javaee.jpa.entity.mapping;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.IdClass;
@Entity
@IdClass(MimaKey.class)
public class Mima {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long key1;
@Id
private String key2;
private String value;
public void setKey2(String key2) {
this.key2 = key2;
}
public void setValue(String value) {
this.value = value;
}
@Override
public String toString() {
return "Mima{" + "key1=" + key1 + ", key2=" + key2 + ", value=" + value + '}';
}
}
package sample.javaee.jpa.entity.mapping;
import java.io.Serializable;
import java.util.Objects;
public class MimaKey implements Serializable {
private Long key1;
private String key2;
@Override
public int hashCode() {
// 省略
}
@Override
public boolean equals(Object obj) {
// 省略
}
}
データベース
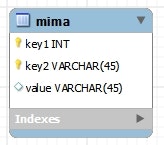
CREATE TABLE `mima` (
`key1` int(11) NOT NULL AUTO_INCREMENT,
`key2` varchar(45) NOT NULL,
`value` varchar(45) DEFAULT NULL,
PRIMARY KEY (`key1`,`key2`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
動作確認
Mima mima = new Mima();
mima.setKey2("key2");
mima.setValue("test");
this.em.persist(mima);
this.em.flush();
System.out.println(mima);
情報: Mima{key1=2, key2=key2, value=test}
-
@IdClassを使うことで複合主キーをマッピングすることもできる。 - この場合、主キーの項目はメインとなるエンティティ側(
Hoge)に定義し、@Idでアノテートする。 -
@IdClassに指定したクラスにはアノテーションを一切付与せずに複合主キーを指定できる。- つまり、複合主キーが既存のクラスで、自由にコードを書き変えられないときとかに使えるということか?
- でも、
equals()とhashCode()が正しくオーバーライドされていないと、主キーの一意性が担保されなくなるので注意が必要そう。
日付項目をマッピングする
エンティティ
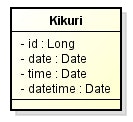
package sample.javaee.jpa.entity.mapping;
import java.util.Date;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.Temporal;
import javax.persistence.TemporalType;
@Entity
public class Kikuri {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Temporal(TemporalType.DATE)
private Date date;
@Temporal(TemporalType.TIME)
private Date time;
@Temporal(TemporalType.TIMESTAMP)
private Date datetime;
public void setDate(Date date) {
this.date = this.time = this.datetime = date;
}
}
データベース
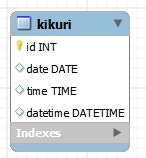
CREATE TABLE `kikuri` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`date` date DEFAULT NULL,
`time` time DEFAULT NULL,
`datetime` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
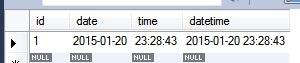
動作確認
Kikuri kikuri = new Kikuri();
kikuri.setDate(new Date());
this.em.persist(kikuri);
プログラム実行後のテーブルの状態。
- 日付項目をマッピングする場合は、
@Temporalでフィールドをアノテートする。 -
@Temporalの値には、データベース上の詳細な型(DATE,TIME,TIMESTAMP)を指定する。-
DATEは日付だけ。 -
TIMEは時刻だけ。 -
TIMESTAMPは日付と時刻の両方。
-
Java8 で追加された LocalTime とかは使える?
コンバーターを自作すれば使えるっぽい?
Using the Java 8 DateTime Classes with JPA! | Java.net
特定のフィールドを永続化の対象外にする
エンティティ

package sample.javaee.jpa.entity.mapping;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.Transient;
@Entity
public class Konngara {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String value;
@Transient
private String ignore;
public void setValue(String value) {
this.value = value;
}
public void setIgnore(String ignore) {
this.ignore = ignore;
}
}
データベース
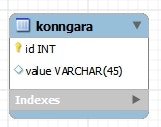
CREATE TABLE `konngara` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`value` varchar(45) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-
@Transientでフィールドをアノテートすると、そのフィールドは永続化の対象外になり、マッピングでは無視される。
列挙型をマッピングする
デフォルトの動き
エンティティ
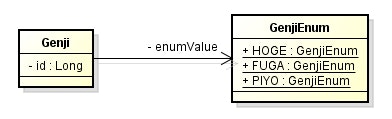
package sample.javaee.jpa.entity.mapping;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
@Entity
public class Genji {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "enum_value")
private GenjiEnum enumValue;
public void setEnumValue(GenjiEnum enumValue) {
this.enumValue = enumValue;
}
}
package sample.javaee.jpa.entity.mapping;
public enum GenjiEnum {
HOGE, FUGA, PIYO;
}
データベース
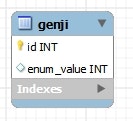
CREATE TABLE `genji` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`enum_value` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
動作確認
Genji genji = new Genji();
genji.setEnumValue(GenjiEnum.HOGE);
this.em.persist(genji);
genji = new Genji();
genji.setEnumValue(GenjiEnum.FUGA);
this.em.persist(genji);
プログラム実行後のテーブルの状態。
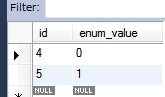
- enum の項目は、デフォルトでは対応する序数が保存される。
- しかし、これだと列挙子の順番を入れ替えた途端にデータが正しくマッピングされなくなる。
文字列でマッピングする
エンティティ
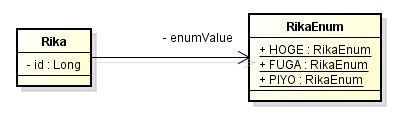
package sample.javaee.jpa.entity.mapping;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.EnumType;
import javax.persistence.Enumerated;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
@Entity
public class Rika {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "enum_value")
@Enumerated(EnumType.STRING)
private RikaEnum enumValue;
public void setEnumValue(RikaEnum enumValue) {
this.enumValue = enumValue;
}
}
データベース
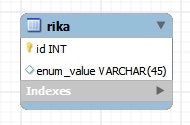
CREATE TABLE `rika` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`enum_value` varchar(45) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
動作確認
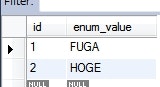
Rika rika = new Rika();
rika.setEnumValue(RikaEnum.HOGE);
this.em.persist(rika);
rika = new Rika();
rika.setEnumValue(RikaEnum.FUGA);
this.em.persist(rika);
プログラムを実行後のテーブルの様子.
-
@Enumeratedでアノテートして、EnumType.STRINGを指定すると、序数ではなく文字列で enum の情報を記録できる。 - これなら、列挙子の順番を書き変えてもデータマッピングで不整合が起こることはない。
基本型のコレクションのマッピング
エンティティ

package sample.javaee.jpa.entity.mapping;
import java.util.List;
import javax.persistence.CollectionTable;
import javax.persistence.Column;
import javax.persistence.ElementCollection;
import javax.persistence.Entity;
import javax.persistence.FetchType;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.OrderBy;
@Entity
public class Meira {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@ElementCollection(fetch = FetchType.EAGER)
@CollectionTable(name = "meira_list_value")
@Column(name = "value")
@OrderBy("DESC")
private List<String> list;
@Override
public String toString() {
return "Meira{" + "id=" + id + ", list=" + list + '}';
}
}
データベース
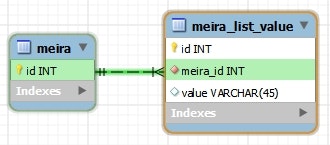
CREATE TABLE `meira` (
`id` int(11) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `meira_list_value` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`meira_id` int(11) NOT NULL,
`value` varchar(45) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `meira_fk_idx` (`meira_id`),
CONSTRAINT `meira_fk` FOREIGN KEY (`meira_id`) REFERENCES `meira` (`id`) ON DELETE NO ACTION ON UPDATE NO ACTION
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
動作確認
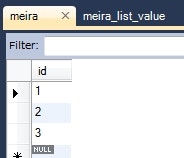
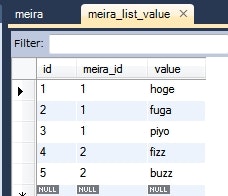
Meira meira = this.em.find(Meira.class, 1L);
System.out.println(meira);
情報: Meira{id=1, list=[zzz, yyy, xxx]}
-
@ElementCollectionでコレクション型のフィールドをアノテートすると、そのフィールドが基本型のコレクションであることを定義できる。- コレクション型の対象は、
Collection,Set,List。 - 基本型とは、エンティティではない型のこと。プリミティブ型、 String 型、組み込み可能クラス(詳細後述)などのことを指す。
-
fetch属性にFetchType.EAGERを指定することで、即時ロードさせることができる(詳細後述)。
- コレクション型の対象は、
-
@CollectionTableアノテーションで、コレクションの各要素を取得するためのテーブルを指定する。- 省略した場合は、「エンティティ名_フィールド名(
meira_list)」で解決される。
- 省略した場合は、「エンティティ名_フィールド名(
-
@Columnアノテーションで、どのカラムの値をコレクションの要素として取得するのかを指定する。- 省略した場合は、「フィールド名(
list)」で解決される。
- 省略した場合は、「フィールド名(
- ソート条件を指定したい場合は、
@OrderByでフィールドをアノテートする。
結合に用いるカラム名の解決
デフォルトの場合、エンティティ名_エンティティのキープロパティ名 で解決される。
つまり、前述のテーブルの場合は Meira_id で解決される。
meira_list_value テーブルと meria テーブルと結合するときのカラム名は、ちょうどこのデフォルト値と同じになっている(meria_id)。
そのため、特に指定なしで動作している。
もしデフォルト値と実際のカラム名が異なる場合(仮に meria_table_id とした場合)は、以下のように設定する。
@ElementCollection(fetch = FetchType.EAGER)
- @CollectionTable(name = "meira_list_value")
+ @CollectionTable(
+ name = "meira_list_value",
+ joinColumns = @JoinColumn(name = "meria_table_id")
+ )
@Column(name = "value")
@OrderBy("DESC")
private List<String> list;
-
@CollectionTableアノテーションのjoinColumns属性で設定する。
即時ロードと遅延ロード
エンティティが他のクラスをコレクション(List や Set)で持っている場合、デフォルトで遅延ロードが適用される。
遅延ロードの場合、エンティティが EntityManager#find(Class, Object) などで DB からロードされた時点では、まだその項目は DB から取得されていない。
値が取得されるのは、そのコレクションから実際に値を取得しようとしたときになる。
前述の Meira クラスに、 lazyList という遅延ロードするリストを追加して、動作を確認してみる。
package sample.javaee.jpa.entity.mapping;
import java.util.List;
import javax.persistence.CollectionTable;
import javax.persistence.Column;
import javax.persistence.ElementCollection;
import javax.persistence.Entity;
import javax.persistence.FetchType;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.OrderBy;
@Entity
public class Meira {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@ElementCollection(fetch = FetchType.EAGER)
@CollectionTable(name = "meira_list_value")
@Column(name = "value")
@OrderBy("DESC")
private List<String> list;
+ @ElementCollection
+ @CollectionTable(name = "meira_list_value")
+ @Column(name = "value")
+ public List<String> lazyList;
@Override
public String toString() {
- return "Meira{" + "id=" + id + ", list=" + list}';
+ return "Meira{" + "id=" + id + ", list=" + list + ", lazyList=" + lazyList + '}';
}
}
動作確認
Meira meira = this.em.find(Meira.class, 1L);
System.out.println(meira);
+ for (String value : meira.lazyList) {
+ System.out.println(value);
+ }
情報: Meira{id=1, list=[zzz, yyy, xxx], lazyList={IndirectList: not instantiated}}
情報: xxx
情報: yyy
情報: zzz
- 遅延ロードの場合、
listをただtoString()しただけでは、値が設定されていないのが分かる。 - しかし、拡張 for 文などを使って List から値を取得すると、実際の値が取れるようになる。
それぞれのメリットとデメリット
| - | メリット | デメリット |
|---|---|---|
| 即時ロード | 検索に時間がかかる場合は、予めロードしておくことができる。 | 結局使用しなくても読み込んでしまう。 |
| 遅延ロード | DB とのアクセスを必要なときだけに限定できる。 | 予めロードしておけない。 |
基本は遅延ロード(デフォルト)で、実際に動かしてみたらパフォーマンスに影響があった場合は即時ロードにする、くらいの方針でよいかと。
よく言われているが、動かしてもないのにパフォーマンスを気にして無駄に設定やモデルをいじくりまわしてしまう、というのは避けた方がいい。
また、 JPA 2.1 (Java EE 7) では、 Entity Graph という仕組みが追加されている。これを利用すると、エンティティ間の関連をどこまで掘り下げて一度に読み込むかなどを定義することができる(詳細後述)。
ソート用のカラムを使用する
エンティティ

package sample.javaee.jpa.entity.mapping;
import java.util.List;
import javax.persistence.Column;
import javax.persistence.ElementCollection;
import javax.persistence.Entity;
import javax.persistence.FetchType;
import javax.persistence.Id;
import javax.persistence.OrderColumn;
@Entity
public class Shinki {
@Id
private Long id;
@ElementCollection(fetch = FetchType.EAGER)
@Column(name = "value")
@OrderColumn(name = "order")
private List<String> list;
@Override
public String toString() {
return "Shinki{" + "id=" + id + ", list=" + list + '}';
}
}
データベース
CREATE TABLE `shinki` (
`id` int(11) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8;
CREATE TABLE `shinki_list` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`shinki_id` int(11) NOT NULL,
`order` int(11) NOT NULL,
`value` varchar(45) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `shinki_list_fk_idx` (`shinki_id`),
CONSTRAINT `shinki_list_fk` FOREIGN KEY (`shinki_id`) REFERENCES `shinki` (`id`) ON DELETE NO ACTION ON UPDATE NO ACTION
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8;
動作確認
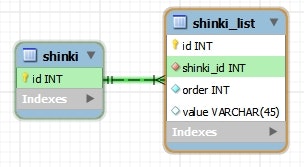
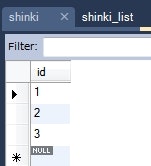
Shinki shinki = this.em.find(Shinki.class, 1L);
System.out.println(shinki);
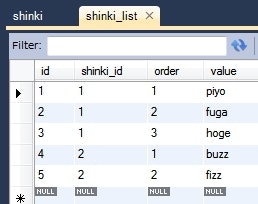
情報: Shinki{id=1, list={[piyo, fuga, hoge]}}
-
@OrderColumnアノテーションを使用することで、ソートのキーとなるカラムを指定することができる。
Map にマッピングする
エンティティ

package sample.javaee.jpa.entity.mapping;
import java.util.Map;
import javax.persistence.CollectionTable;
import javax.persistence.Column;
import javax.persistence.ElementCollection;
import javax.persistence.Entity;
import javax.persistence.FetchType;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.MapKeyColumn;
@Entity
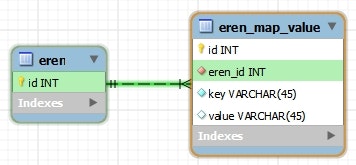
public class Eren {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@ElementCollection(fetch = FetchType.EAGER)
@CollectionTable(name = "eren_map_value")
@MapKeyColumn(name = "key")
@Column(name = "value")
private Map<String, String> map;
@Override
public String toString() {
return "Eren{" + "id=" + id + ", map=" + map + '}';
}
}
データベース
CREATE TABLE `eren` (
`id` int(11) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `eren_map_value` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`eren_id` int(11) NOT NULL,
`key` varchar(45) NOT NULL,
`value` varchar(45) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `eren_map_velu_fk_idx` (`eren_id`),
CONSTRAINT `eren_map_velu_fk` FOREIGN KEY (`eren_id`) REFERENCES `eren` (`id`) ON DELETE NO ACTION ON UPDATE NO ACTION
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
動作確認
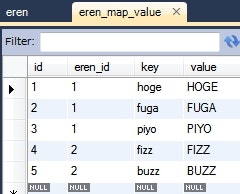
Eren eren = this.em.find(Eren.class, 1L);
System.out.println(eren);
情報: Eren{id=1, map={fuga=FUGA, piyo=PIYO, hoge=HOGE}}
-
@MapKeyColumnでアノテートすることで、Mapのキーバリューと DB の値をマッピングすることができる。 -
@MapKeyColumnのnameには、Mapのキーとなる値を持つカラム名を指定する。 - それ以外は、コレクションのときと同じ要領で設定する。
-
String以外にも、他のエンティティなどをキーやバリューに指定することもできる。
非エンティティクラスをマッピングする
エンティティ
package sample.javaee.jpa.entity.mapping;
import javax.persistence.Embedded;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
@Entity
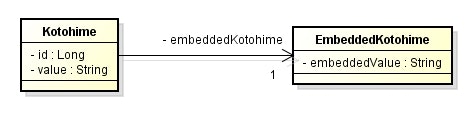
public class Kotohime {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String value;
@Embedded
private EmbeddedKotohime embeddedKotohime;
@Override
public String toString() {
return "Kotohime{" + "id=" + id + ", value=" + value + ", embeddedKotohime=" + embeddedKotohime + '}';
}
}
package sample.javaee.jpa.entity.mapping;
import javax.persistence.Column;
import javax.persistence.Embeddable;
@Embeddable
public class EmbeddedKotohime {
@Column(name = "embedded_value")
private String embeddedValue;
@Override
public String toString() {
return "EmbeddedKotohime{" + "embeddedValue=" + embeddedValue + '}';
}
}
データベース
CREATE TABLE `kotohime` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`value` varchar(45) DEFAULT NULL,
`embedded_value` varchar(45) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
動作確認
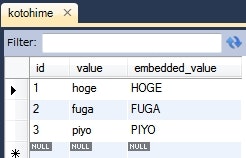
Kotohime kotohime = this.em.find(Kotohime.class, 1L);
System.out.println(kotohime);
情報: Kotohime{id=1, value=hoge, embeddedKotohime=EmbeddedKotohime{embeddedValue=HOGE}}
-
@Embeddableでクラスをアノテートすることで、非エンティティクラスをエンティティにマッピングすることができるようになる。 -
@Embeddableでアノテートしたクラスを、 組み込み可能クラス と呼ぶ。 - 組み込み可能クラスは ID を持たない = 識別する必要がない、すなわち DDD の ValueObject に該当する。
- エンティティ側では、
@Embeddedを使ってフィールドが組み込み可能クラスであることを指定する。
組み込み可能クラスの List をマッピングする
エンティティ
package sample.javaee.jpa.entity.mapping;
import java.util.List;
import javax.persistence.CollectionTable;
import javax.persistence.ElementCollection;
import javax.persistence.Embedded;
import javax.persistence.Entity;
import javax.persistence.FetchType;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.JoinColumn;
import javax.persistence.Table;
@Entity
@Table(name = "kana_anaberaru")
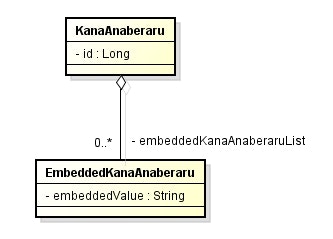
public class KanaAnaberaru {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Embedded
@ElementCollection(fetch = FetchType.EAGER)
@CollectionTable(
name = "kana_anaberaru_list_value",
joinColumns = @JoinColumn(name = "kana_anaberaru_id")
)
private List<EmbeddedKanaAnaberaru> embeddedKanaAnaberaruList;
@Override
public String toString() {
return "KanaAnaberaru{" + "id=" + id + ", embeddedKanaAnaberaruList=" + embeddedKanaAnaberaruList + '}';
}
}
package sample.javaee.jpa.entity.mapping;
import javax.persistence.Column;
import javax.persistence.Embeddable;
@Embeddable
public class EmbeddedKanaAnaberaru {
@Column(name = "embedded_value")
private String embeddedValue;
@Override
public String toString() {
return "EmbeddedKanaAnaberaru{" + "embeddedValue=" + embeddedValue + '}';
}
}
データーベース
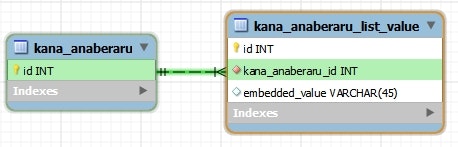
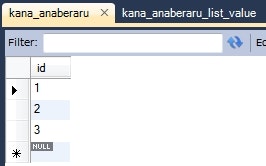
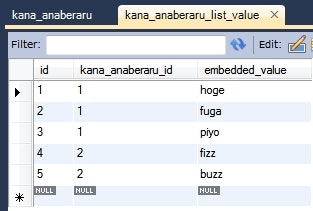
CREATE TABLE `kana_anaberaru` (
`id` int(11) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8;
CREATE TABLE `kana_anaberaru_list_value` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`kana_anaberaru_id` int(11) NOT NULL,
`embedded_value` varchar(45) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `kana_anaberaru_list_value_fk_idx` (`kana_anaberaru_id`),
CONSTRAINT `kana_anaberaru_list_value_fk` FOREIGN KEY (`kana_anaberaru_id`) REFERENCES `kana_anaberaru` (`id`) ON DELETE NO ACTION ON UPDATE NO ACTION
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8;
動作確認
KanaAnaberaru kotohime = this.em.find(KanaAnaberaru.class, 1L);
System.out.println(kotohime);
情報: KanaAnaberaru{id=1, embeddedKanaAnaberaruList=[EmbeddedKanaAnaberaru{embeddedValue=hoge}, EmbeddedKanaAnaberaru{embeddedValue=fuga}, EmbeddedKanaAnaberaru{embeddedValue=piyo}]}
-
@Embeddedアノテーションをフィールドに追加すれば、組み込み可能クラスを List でマッピングすることができる。
組み込み可能クラスを Map にマッピングする
エンティティ
package sample.javaee.jpa.entity.mapping;
import java.util.Map;
import javax.persistence.CollectionTable;
import javax.persistence.ElementCollection;
import javax.persistence.Embedded;
import javax.persistence.Entity;
import javax.persistence.FetchType;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.JoinColumn;
import javax.persistence.Table;
@Entity
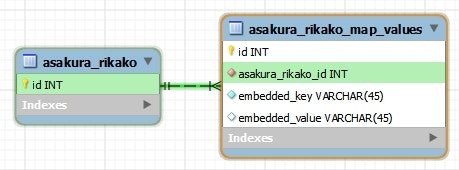
@Table(name = "asakura_rikako")
public class AsakuraRikako {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Embedded
@ElementCollection(fetch = FetchType.EAGER)
@CollectionTable(
name = "asakura_rikako_map_values",
joinColumns = @JoinColumn(name = "asakura_rikako_id")
)
private Map<AsakuraRikakoKey, AsakuraRikakoValue> map;
@Override
public String toString() {
return "AsakuraRikako{" + "id=" + id + ", map=" + map + '}';
}
}
package sample.javaee.jpa.entity.mapping;
import java.util.Objects;
import javax.persistence.Column;
import javax.persistence.Embeddable;
@Embeddable
public class AsakuraRikakoKey {
@Column(name = "embedded_key")
private String key;
@Override
public String toString() {
return "AsakuraRikakoKey{" + "key=" + key + '}';
}
@Override
public int hashCode() {
// NetBeans で自動生成
}
@Override
public boolean equals(Object obj) {
// NetBeans で自動生成
}
}
package sample.javaee.jpa.entity.mapping;
import javax.persistence.Column;
import javax.persistence.Embeddable;
@Embeddable
public class AsakuraRikakoValue {
@Column(name = "embedded_value")
private String value;
@Override
public String toString() {
return "AsakuraRikakoValue{" + "value=" + value + '}';
}
}
データベース
CREATE TABLE `asakura_rikako` (
`id` int(11) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8;
CREATE TABLE `asakura_rikako_map_values` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`asakura_rikako_id` int(11) NOT NULL,
`embedded_key` varchar(45) NOT NULL,
`embedded_value` varchar(45) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `asakura_rikako_map_values_fk_idx` (`asakura_rikako_id`),
CONSTRAINT `asakura_rikako_map_values_fk` FOREIGN KEY (`asakura_rikako_id`) REFERENCES `asakura_rikako` (`id`) ON DELETE NO ACTION ON UPDATE NO ACTION
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8;
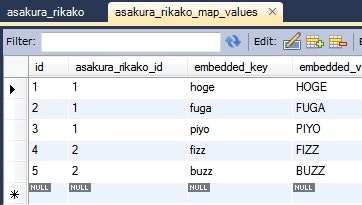
動作確認
AsakuraRikako asakuraRikako = this.em.find(AsakuraRikako.class, 1L);
System.out.println(asakuraRikako);
情報: AsakuraRikako{id=1, map={AsakuraRikakoKey{key=fuga}=AsakuraRikakoValue{value=FUGA}, AsakuraRikakoKey{key=piyo}=AsakuraRikakoValue{value=PIYO}, AsakuraRikakoKey{key=hoge}=AsakuraRikakoValue{value=HOGE}}}
-
@Embeddedをフィールドに追加することで、組み込み可能クラスを Map のキーやバリューとして使用することができる。
Lob カラムをマッピングする
エンティティ

package sample.javaee.jpa.entity.mapping;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.Id;
import javax.persistence.Lob;
import javax.persistence.Table;
@Entity
@Table(name = "patchouli_knowledge")
public class PatchouliKnowledge {
@Id
private Long id;
@Lob
@Column(name = "blob_value")
private byte[] blobValue;
@Lob
@Column(name = "clob_value")
private String clobValue;
public void setBlobValue(byte[] blobValue) {
this.blobValue = blobValue;
}
public void setClobValue(String clobValue) {
this.clobValue = clobValue;
}
}
データベース
CREATE TABLE `patchouli_knowledge` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`blob_value` blob,
`clob_value` longtext,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;
動作確認
PatchouliKnowledge patchouliKnowledge = new PatchouliKnowledge();
patchouliKnowledge.setBlobValue("blob text".getBytes(Charset.forName("UTF-8")));
patchouliKnowledge.setClobValue("clob text");
this.em.persist(patchouliKnowledge);
実行後のデータベースの様子。
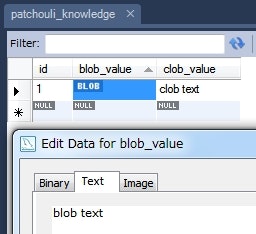
-
@Lobでフィールドをアノテートすると、 LOB 型のデータとしてマッピングできる。 - BLOB にマッピングされるか、 CLOB にマッピングされるかは、フィールドの型によって以下のように決定される。
-
byte[]、Byte[]、Serializableの場合は BLOB。 -
char[]、Character[]、Stringの場合は CLOB。
リレーションのマッピング
複数のエンティティが関連を持つ場合の、 DB とのマッピング方法について。
1対1
単方向
エンティティ

package sample.javaee.jpa.entity.mapping;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.JoinColumn;
import javax.persistence.Table;
@Entity
@Table(name = "kitashirakawa_chiyuri")
public class KitashirakawaChiyuri {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@JoinColumn(name = "okazaki_yumemi_id")
private OkazakiYumemi okazakiYumemi;
@Override
public String toString() {
return "KitashirakawaChiyuri{" + "id=" + id + ", okazakiYumemi=" + okazakiYumemi + '}';
}
}
package sample.javaee.jpa.entity.mapping;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.Table;
@Entity
@Table(name = "okazaki_yumemi")
public class OkazakiYumemi {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Override
public String toString() {
return "OkazakiYumemi{" + "id=" + id + '}';
}
}
データベース
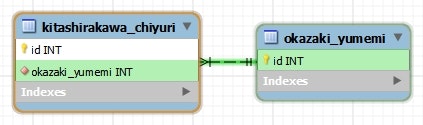
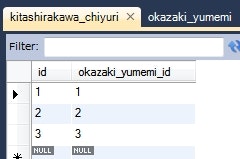
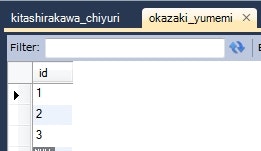
CREATE TABLE `kitashirakawa_chiyuri` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`okazaki_yumemi_id` int(11) NOT NULL,
PRIMARY KEY (`id`),
KEY `kitashirakawa_chiyuri_fk_idx` (`okazaki_yumemi_id`),
CONSTRAINT `kitashirakawa_chiyuri_fk` FOREIGN KEY (`okazaki_yumemi_id`) REFERENCES `okazaki_yumemi` (`id`) ON DELETE NO ACTION ON UPDATE NO ACTION
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8;
CREATE TABLE `okazaki_yumemi` (
`id` int(11) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8;
動作確認
KitashirakawaChiyuri kitashirakawaChiyuri = this.em.find(KitashirakawaChiyuri.class, 1L);
System.out.println(kitashirakawaChiyuri);
情報: KitashirakawaChiyuri{id=1, okazakiYumemi=OkazakiYumemi{id=1}}
- エンティティ間の多重度が1対1で、関連の向きが単方向の場合は、特に何も指定することなくマッピングすることができる。
- ただし、結合に用いられるカラム名が、デフォルトでは フィールド名_相手のキーカラム名 で解決される(
okazakiYumemi_id)ので、@JoinColumnアノテーションを使って結合に用いるカラム名を明示している。 - デフォルトのフェッチ方法は
EAGERになる。これを変更したい場合は、@OneToOne(fetch = FetchType.LAZY)の指定を追加する。
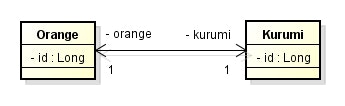
双方向
エンティティ
package sample.javaee.jpa.entity.mapping;
import javax.persistence.Entity;
import javax.persistence.Id;
@Entity
public class Orange {
@Id
private Long id;
private Kurumi kurumi;
public Long getId() {
return id;
}
@Override
public String toString() {
return "Orange{" + "id=" + id + ", kurumi.id=" + kurumi.getId() + '}';
}
}
package sample.javaee.jpa.entity.mapping;
import javax.persistence.Entity;
import javax.persistence.Id;
import javax.persistence.OneToOne;
@Entity
public class Kurumi {
@Id
private Long id;
@OneToOne(mappedBy = "kurumi")
private Orange orange;
public Long getId() {
return id;
}
@Override
public String toString() {
return "Kurumi{" + "id=" + id + ", orange.id=" + orange.getId() + '}';
}
}
データベース
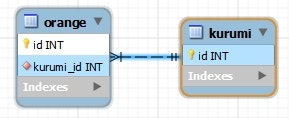
CREATE TABLE `kurumi` (
`id` int(11) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8;
CREATE TABLE `orange` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`kurumi_id` int(11) NOT NULL,
PRIMARY KEY (`id`),
KEY `orange_fk_idx` (`kurumi_id`),
CONSTRAINT `orange_fk` FOREIGN KEY (`kurumi_id`) REFERENCES `kurumi` (`id`) ON DELETE NO ACTION ON UPDATE NO ACTION
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8;
動作確認
Orange orange = this.em.find(Orange.class, 1L);
System.out.println(orange);
Kurumi kurumi = this.em.find(Kurumi.class, 2L);
System.out.println(kurumi);
情報: Orange{id=1, kurumi.id=1}
情報: Kurumi{id=2, orange.id=2}
- DB のテーブル上で、関連するエンティティを識別するためのカラムを持っている方のエンティティを 所有者 と呼ぶ。
- もしくは、エンティティ A がエンティティ B の参照を持っている場合、 A を所有者と呼ぶ。
- 逆側のエンティティを、 被所有者 と呼ぶ。
- 上記例でいうと、
Orangeが所有者で、Kurumiが被所有者となる。 - しかしエンティティが相互参照していると、それだけではどちらが所有者でどちらが被所有者なのか判断することができない。
- そこで、
Kurumiが被所有者であることを明示するために、@OneToOneアノテーションのmappedBy属性を使用する。 -
mappedByには、所有者が持っている被所有者を指すプロパティ名を指定する(上記例の場合は、kurumi)。
そもそも相互参照するようなクラス設計はダメじゃね?
1対多
単方向
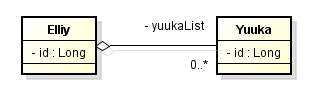
結合テーブルを使用する
エンティティ
package sample.javaee.jpa.entity.mapping;
import java.util.List;
import javax.persistence.Entity;
import javax.persistence.FetchType;
import javax.persistence.Id;
import javax.persistence.JoinColumn;
import javax.persistence.JoinTable;
import javax.persistence.OneToMany;
@Entity
public class Elliy {
@Id
private Long id;
@OneToMany(fetch = FetchType.EAGER)
@JoinTable(inverseJoinColumns = @JoinColumn(name = "yuuka_id"))
private List<Yuuka> yuukaList;
@Override
public String toString() {
return "Elliy{" + "id=" + id + ", yuukaList=" + yuukaList + '}';
}
}
package sample.javaee.jpa.entity.mapping;
import javax.persistence.Entity;
import javax.persistence.Id;
@Entity
public class Yuuka {
@Id
private Long id;
@Override
public String toString() {
return "Yuuka{" + "id=" + id + '}';
}
}
データベース
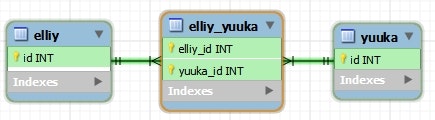
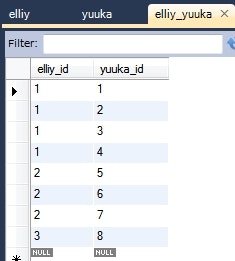
CREATE TABLE `elliy` (
`id` int(11) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8;
CREATE TABLE `yuuka` (
`id` int(11) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=9 DEFAULT CHARSET=utf8;
CREATE TABLE `elliy_yuuka` (
`elliy_id` int(11) NOT NULL,
`yuuka_id` int(11) NOT NULL,
PRIMARY KEY (`elliy_id`,`yuuka_id`),
KEY `elliy_yuuka_fk1_idx` (`elliy_id`),
KEY `elliy_yuuka_fk2_idx` (`yuuka_id`),
CONSTRAINT `elliy_yuuka_fk1` FOREIGN KEY (`elliy_id`) REFERENCES `elliy` (`id`) ON DELETE NO ACTION ON UPDATE NO ACTION,
CONSTRAINT `elliy_yuuka_fk2` FOREIGN KEY (`yuuka_id`) REFERENCES `yuuka` (`id`) ON DELETE NO ACTION ON UPDATE NO ACTION
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
動作確認
Elliy elliy = this.em.find(Elliy.class, 1L);
System.out.println(elliy);
情報: Elliy{id=1, yuukaList=[Yuuka{id=1}, Yuuka{id=2}, Yuuka{id=3}, Yuuka{id=4}]}
- 関連テーブルを使って1対多のエンティティをマッピングするケース。
- デフォルトでは、以下のようにテーブル名やカラム名が解決される。
| 対象 | デフォルト設定で解決された場合 | 例 |
|---|---|---|
| 関連テーブル名 | 所有者エンティティ名_被所有者エンティティ名 | Elliy_Yuuka |
| 所有者を結合するためのカラム名 | 所有者エンティティ名_ID項目名 | Elliy_id |
| 被所有者を結合するためのカラム名 | プロパティ名_ID項目名 | yuukaList_id |
- 関連テーブルの名前と所有者側を結合するためのカラム名は、デフォルトのままでも問題ない。
- しかし、被所有者側を結合するためのカラム名が、デフォルトのままだと問題がある。
- そこで、
@JoinTableアノテーションのinverseJoinColumns属性を使ってカラム名を明示的に指定している。 - 今回は必要なかったが、関連テーブル名や所有者を結合するためのカラム名を指定する場合は、以下のようにする。
@JoinTable(
name = "relation_table_name",
joinColumns = @JoinColumn(name = "join_column")
)
private List<Yuuka> yuukaList;
-
name属性で、関連テーブルの名前を指定する。 -
joinColumns属性で、所有者側を結合するためのカラム名を指定する。
結合テーブルを使用しない
エンティティ

package sample.javaee.jpa.entity.mapping;
import java.util.List;
import javax.persistence.Entity;
import javax.persistence.FetchType;
import javax.persistence.Id;
import javax.persistence.JoinColumn;
import javax.persistence.OneToMany;
@Entity
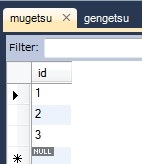
public class Mugetsu {
@Id
private Long id;
@OneToMany(fetch = FetchType.EAGER)
@JoinColumn(name = "mugetsu_id")
private List<Gengetsu> gengetsuList;
@Override
public String toString() {
return "Mugetsu{" + "id=" + id + ", gengetsuList=" + gengetsuList + '}';
}
}
package sample.javaee.jpa.entity.mapping;
import javax.persistence.Entity;
import javax.persistence.Id;
@Entity
public class Gengetsu {
@Id
private Long id;
@Override
public String toString() {
return "Gengetsu{" + "id=" + id + '}';
}
}
データベース
CREATE TABLE `mugetsu` (
`id` int(11) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8;
CREATE TABLE `gengetsu` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`mugetsu_id` int(11) NOT NULL,
PRIMARY KEY (`id`),
KEY `gengetsu_fk_idx` (`mugetsu_id`),
CONSTRAINT `gengetsu_fk` FOREIGN KEY (`mugetsu_id`) REFERENCES `mugetsu` (`id`) ON DELETE NO ACTION ON UPDATE NO ACTION
) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8;
動作確認
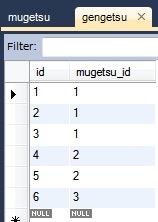
Mugetsu mugetsu = this.em.find(Mugetsu.class, 1L);
System.out.println(mugetsu);
情報: Mugetsu{id=1, gengetsuList=[Gengetsu{id=1}, Gengetsu{id=2}, Gengetsu{id=3}]}
- 関連テーブルを使わない単純なケース。
- 1対多の関連を解決する場合、 JPA は、デフォルトだと関連テーブルを使った方法を想定して関連の解決を行おうとする。
- そうではなく、上記のように単純な方法で1対多のデータを格納している場合は、所有者側に
@JoinColumnアノテーションを設定する。 - 結合条件となるカラムの名前は、デフォルトだと
プロパティ名_IDカラム名で解決される(上述の例の場合はgengetsuList_id)。 - これを上書きする場合は、
name属性を指定する。
双方向
結合テーブルを使用する
エンティティ
package sample.javaee.jpa.entity.mapping;
import java.util.List;
import javax.persistence.Entity;
import javax.persistence.FetchType;
import javax.persistence.Id;
import javax.persistence.JoinColumn;
import javax.persistence.JoinTable;
import javax.persistence.OneToMany;
@Entity
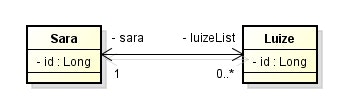
public class Sara {
@Id
private Long id;
@OneToMany(fetch = FetchType.EAGER)
@JoinTable(
inverseJoinColumns = @JoinColumn(name = "luize_id")
)
private List<Luize> luizeList;
public Long getId() {
return id;
}
@Override
public String toString() {
return "Sara{" + "id=" + id + ", luizeList=" + luizeList + '}';
}
}
package sample.javaee.jpa.entity.mapping;
import javax.persistence.Entity;
import javax.persistence.Id;
import javax.persistence.JoinTable;
@Entity
public class Luize {
@Id
private Long id;
@JoinTable(name="sara_luize")
private Sara sara;
@Override
public String toString() {
return "Luize{" + "id=" + id + ", sara.id=" + sara.getId() + '}';
}
}
データベース
CREATE TABLE `sara` (
`id` int(11) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8;
CREATE TABLE `luize` (
`id` int(11) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8;
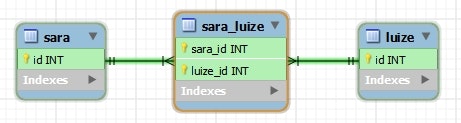
CREATE TABLE `sara_luize` (
`sara_id` int(11) NOT NULL,
`luize_id` int(11) NOT NULL,
PRIMARY KEY (`sara_id`,`luize_id`),
KEY `sara_luize_fk1_idx` (`sara_id`),
KEY `sara_luize_fk2_idx` (`luize_id`),
CONSTRAINT `sara_luize_fk1` FOREIGN KEY (`sara_id`) REFERENCES `sara` (`id`) ON DELETE NO ACTION ON UPDATE NO ACTION,
CONSTRAINT `sara_luize_fk2` FOREIGN KEY (`luize_id`) REFERENCES `luize` (`id`) ON DELETE NO ACTION ON UPDATE NO ACTION
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
動作確認
Sara sara = this.em.find(Sara.class, 1L);
System.out.println(sara);
Luize luize = this.em.find(Luize.class, 1L);
System.out.println(luize);
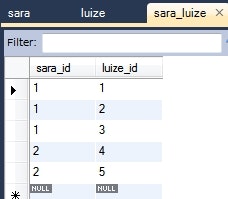
情報: Sara{id=1, luizeList=[Luize{id=1, sara.id=1}, Luize{id=2, sara.id=1}, Luize{id=3, sara.id=1}]}
情報: Luize{id=1, sara.id=1}
- 多の方のエンティティ(
Luizeクラス)が持つフィールド(sara)を、@JoinTableアノテートしてテーブル名を明示する。 - これをしないと、関連テーブルが
luize_saraで解決されてしまう。 -
Luizeクラスのsaraフィールドのフェッチを変更したい場合は、@ManyToOneアノテーションを使用する。
結合テーブルを使用しない
エンティティ
package sample.javaee.jpa.entity.mapping;
import java.util.List;
import javax.persistence.Entity;
import javax.persistence.FetchType;
import javax.persistence.Id;
import javax.persistence.JoinColumn;
import javax.persistence.OneToMany;
@Entity
public class Yuki {
@Id
private Long id;
@OneToMany(fetch = FetchType.EAGER)
@JoinColumn(name = "yuki_id")
private List<Mai> maiList;
public Long getId() {
return id;
}
@Override
public String toString() {
return "Yuki{" + "id=" + id + ", maiList=" + maiList + '}';
}
}
package sample.javaee.jpa.entity.mapping;
import javax.persistence.Entity;
import javax.persistence.Id;
@Entity
public class Mai {
@Id
private Long id;
private Yuki yuki;
@Override
public String toString() {
return "Mai{" + "id=" + id + ", yuki.id=" + yuki.getId() + '}';
}
}
データベース
CREATE TABLE `yuki` (
`id` int(11) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8;
CREATE TABLE `mai` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`yuki_id` int(11) NOT NULL,
PRIMARY KEY (`id`),
KEY `mai_fk_idx` (`yuki_id`),
CONSTRAINT `mai_fk` FOREIGN KEY (`yuki_id`) REFERENCES `yuki` (`id`) ON DELETE NO ACTION ON UPDATE NO ACTION
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8;
動作確認
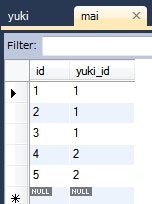
Yuki yuki = this.em.find(Yuki.class, 1L);
System.out.println(yuki);
Mai mai = this.em.find(Mai.class, 1L);
System.out.println(mai);
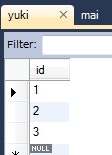
情報: Yuki{id=1, maiList=[Mai{id=1, yuki.id=1}, Mai{id=2, yuki.id=1}, Mai{id=3, yuki.id=1}]}
情報: Mai{id=1, yuki.id=1}
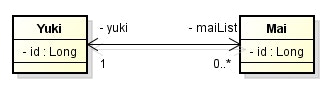
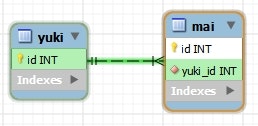
- 多(
Mai)から1(Yuki)側を結合するときのカラム名は、1対1のときと同じ方法で解決される。 - 明示したい場合は、
@JoinColumnを使う。
多対多
エンティティ

package sample.javaee.jpa.entity.mapping;
import java.util.ArrayList;
import java.util.List;
import javax.persistence.Entity;
import javax.persistence.FetchType;
import javax.persistence.Id;
import javax.persistence.JoinColumn;
import javax.persistence.JoinTable;
import javax.persistence.ManyToMany;
@Entity
public class Alice {
@Id
private Long id;
@ManyToMany(fetch = FetchType.EAGER)
@JoinTable(
joinColumns = @JoinColumn(name = "alice_id"),
inverseJoinColumns = @JoinColumn(name = "yumeko_id")
)
private List<Yumeko> yumekoList;
public Long getId() {
return id;
}
@Override
public String toString() {
List<String> ids = new ArrayList<>();
for (Yumeko yumeko : this.yumekoList) {
ids.add(String.valueOf(yumeko.getId()));
}
return "Alice{" + "id=" + id + ", yumekoList=" + String.join(", ", ids) + '}';
}
}
package sample.javaee.jpa.entity.mapping;
import java.util.ArrayList;
import java.util.List;
import javax.persistence.Entity;
import javax.persistence.FetchType;
import javax.persistence.Id;
import javax.persistence.ManyToMany;
@Entity
public class Yumeko {
@Id
private Long id;
@ManyToMany(fetch = FetchType.EAGER, mappedBy = "yumekoList")
private List<Alice> aliceList;
public Long getId() {
return id;
}
@Override
public String toString() {
List<String> ids = new ArrayList<>();
for (Alice alice : this.aliceList) {
ids.add(String.valueOf(alice.getId()));
}
return "Yumeko{" + "id=" + id + ", aliceList=" + String.join(", ", ids) + '}';
}
}
データベース
CREATE TABLE `alice` (
`id` int(11) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8;
CREATE TABLE `yumeko` (
`id` int(11) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8;
CREATE TABLE `alice_yumeko` (
`alice_id` int(11) NOT NULL,
`yumeko_id` int(11) NOT NULL,
PRIMARY KEY (`alice_id`,`yumeko_id`),
KEY `alice_yumeko_fk1_idx` (`alice_id`),
KEY `alice_yumeko_fk2_idx` (`yumeko_id`),
CONSTRAINT `alice_yumeko_fk1` FOREIGN KEY (`alice_id`) REFERENCES `alice` (`id`) ON DELETE NO ACTION ON UPDATE NO ACTION,
CONSTRAINT `alice_yumeko_fk2` FOREIGN KEY (`yumeko_id`) REFERENCES `yumeko` (`id`) ON DELETE NO ACTION ON UPDATE NO ACTION
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
動作確認
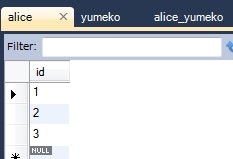
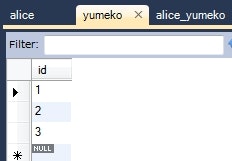
Alice alice = this.em.find(Alice.class, 1L);
System.out.println(alice);
Yumeko yumeko = this.em.find(Yumeko.class, 1L);
System.out.println(yumeko);
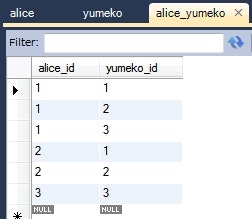
情報: Alice{id=1, yumekoList=1, 2, 3}
情報: Yumeko{id=1, aliceList=1, 2}
- 双方向の多対多をマッピングする場合は、
@ManyToManyアノテーションを使う。 - どちらか一方を所有者に決めて、そちらに
@JoinTableアノテーションで結合の条件を設定する。 - 被所有者側は、
@ManyToManyアノテーションのmappedBy属性で、所有者側のどのフィールドを紐付いているのかだけを指定すればいい。 - 実装してて気づいたけど、
toString()メソッド内で Stream API を使うと、アプリケーションロード時にエラーになるっぽい。原因はよくわからない。仕方ないので、 for 文を使って文字列を整形している。
継承のマッピング
クラス階層に属するエンティティを1つのテーブルにマッピングする
エンティティ
package sample.javaee.jpa.entity.mapping;
import javax.persistence.Entity;
import javax.persistence.Id;
import javax.persistence.Table;
@Entity
@Table(name = "rumia")
public class ParentRumia {
@Id
protected Long id;
protected String name;
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "ParentRumia{" + "id=" + id + ", name=" + name + '}';
}
}
package sample.javaee.jpa.entity.mapping;
import javax.persistence.Entity;
@Entity
public class ChildRumia extends ParentRumia {
private String value;
public void setValue(String value) {
this.value = value;
}
@Override
public String toString() {
return "ChildRumia{id=" + id + ", name=" + name + ", value=" + value + '}';
}
}
データベース
CREATE TABLE `rumia` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`dtype` varchar(45) NOT NULL,
`name` varchar(45) DEFAULT NULL,
`value` varchar(45) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8;
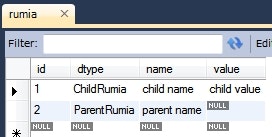
動作確認
ParentRumia parentRumia = new ParentRumia();
parentRumia.setName("parent name");
this.em.persist(parentRumia);
ChildRumia childRumia = new ChildRumia();
childRumia.setName("child name");
childRumia.setValue("child value");
this.em.persist(childRumia);
実行後のデータベースの様子。
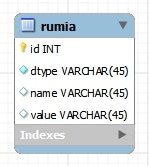
- 特に指定が無い場合、1つのクラス階層に属するエンティティは、1つのテーブルにマッピングされる。
- マッピングされるテーブルの名前は、デフォルトでは階層のルートとなるエンティティ名で解決される。
- テーブルには
dtypeという名前の文字列型のカラムを用意しておく。 - このカラムに、そのレコードがどのクラスのデータなのかを識別するための値が格納される。
- デフォルトでは、エンティティの名前が格納される。
- テーブルには、クラス階層の各エンティティが持つ全てのプロパティに対応するカラムを用意しなければならない。
メリット
- データの持ち方が単純で理解しやすい。
- 検索時にテーブルの JOIN が必要ない。
デメリット
- 階層にクラスが追加されると、テーブルのカラムも変更しなければならない。
- 項目に NOT NULL 制約を設けることができない。
- 子クラスで定義されたカラムには、親クラスのレコードでは NULL 値が設定されるため。
エンティティ名を保存するカラムの名前や値を変更する
デフォルトでは DTYPE という文字列型のカラムにエンティティ名が保存される。
これは、 @DiscriminatorColumn と @DiscriminatorValue アノテーションで変更することができる。
エンティティ
package sample.javaee.jpa.entity.mapping;
import javax.persistence.DiscriminatorColumn;
import javax.persistence.DiscriminatorType;
import javax.persistence.DiscriminatorValue;
import javax.persistence.Entity;
import javax.persistence.Id;
import javax.persistence.Table;
@Entity
@Table(name = "daiyousei")
@DiscriminatorColumn(name = "entity_type", discriminatorType = DiscriminatorType.INTEGER)
@DiscriminatorValue("1")
public class ParentDaiyousei {
@Id
private Long id;
private String value;
public void setValue(String value) {
this.value = value;
}
}
package sample.javaee.jpa.entity.mapping;
import javax.persistence.DiscriminatorValue;
import javax.persistence.Entity;
@Entity
@DiscriminatorValue("2")
public class ChildDaiyousei extends ParentDaiyousei {
}
データベース
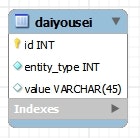
CREATE TABLE `daiyousei` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`entity_type` int(11) NOT NULL,
`value` varchar(45) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8;
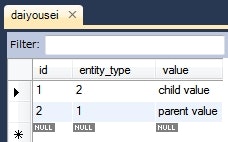
動作確認
ParentDaiyousei parentDaiyousei = new ParentDaiyousei();
parentDaiyousei.setValue("parent value");
this.em.persist(parentDaiyousei);
ChildDaiyousei childDaiyousei = new ChildDaiyousei();
childDaiyousei.setValue("child value");
this.em.persist(childDaiyousei);
実行後のデータベースの様子。
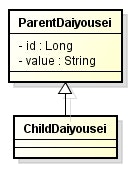
- ルートのエンティティを
@DiscriminatorColumnでアノテートして、name属性でカラムの名前を指定できる。 -
discriminatorType属性で型を指定することができる。 - 各エンティティでなんという値を設定するかは、
@DiscriminatorValueアノテーションで指定する。
サブクラスごとにテーブルをマッピングする
エンティティ
package sample.javaee.jpa.entity.mapping;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.Inheritance;
import javax.persistence.InheritanceType;
import javax.persistence.Table;
@Entity
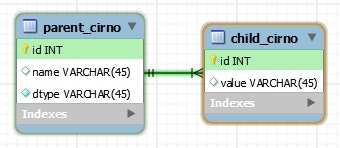
@Table(name = "parent_cirno")
@Inheritance(strategy = InheritanceType.JOINED)
public class ParentCirno {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
protected Long id;
protected String name;
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "ParentCirno{" + "id=" + id + ", name=" + name + '}';
}
}
package sample.javaee.jpa.entity.mapping;
import javax.persistence.Entity;
import javax.persistence.Table;
@Entity
@Table(name = "child_cirno")
public class ChildCirno extends ParentCirno {
private String value;
public void setValue(String value) {
this.value = value;
}
@Override
public String toString() {
return "ChildCirno{" + "id=" + id + ", name=" + name + ", value=" + value + '}';
}
}
データベース
CREATE TABLE `parent_cirno` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(45) DEFAULT NULL,
`dtype` varchar(45) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8;
CREATE TABLE `child_cirno` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`value` varchar(45) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `child_cirno_fk_idx` (`id`),
CONSTRAINT `child_cirno_fk` FOREIGN KEY (`id`) REFERENCES `parent_cirno` (`id`) ON DELETE NO ACTION ON UPDATE NO ACTION
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;
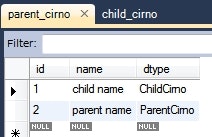
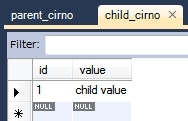
動作確認
ParentCirno parentCirno = new ParentCirno();
parentCirno.setName("parent name");
this.em.persist(parentCirno);
ChildCirno childCirno = new ChildCirno();
childCirno.setName("child name");
childCirno.setValue("child value");
this.em.persist(childCirno);
実行後のデータベースの様子。
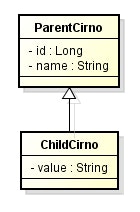
- ルートのエンティティを
@Inheritanceでアノテートし、strategyにInheritanceType.JOINEDを指定する。 - デフォルトは、
InheritanceType.SINGLE_TABLEを指定したのと同じになる。 - すると、クラス階層上の各エンティティを、それぞれ個別のテーブルにマッピングすることができる。
- 各テーブルは、 PK を外部参照制約で紐付ける。
- ルートのテーブルには、クラスを特定するための
dtypeカラムを定義する。 - こちらも
@DiscriminatorColumnアノテーションを使って変更することができる。
メリット
- 項目に NOT NULL 制約を設けることができる(
SINGLE_TABLEと比べた場合の話)。 - データが正規化される。
デメリット
- サブクラスのエンティティを取得するには、テーブルの結合が必要になる。
エンティティごとに独立したテーブルにマッピングする
エンティティ
package sample.javaee.jpa.entity.mapping;
import javax.persistence.Entity;
import javax.persistence.Id;
import javax.persistence.Inheritance;
import javax.persistence.InheritanceType;
import javax.persistence.Table;
@Entity
@Table(name = "parent_hong_meiling")
@Inheritance(strategy = InheritanceType.TABLE_PER_CLASS)
public class ParentHongMeiling {
@Id
private Long id;
private String name;
public void setName(String name) {
this.name = name;
}
}
package sample.javaee.jpa.entity.mapping;
import javax.persistence.Entity;
import javax.persistence.Table;
@Entity
@Table(name = "child_hong_meiling")
public class ChildHongMeiling extends ParentHongMeiling {
private String value;
public void setValue(String value) {
this.value = value;
}
}
データベース
CREATE TABLE `parent_hong_meiling` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(45) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;
CREATE TABLE `child_hong_meiling` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(45) DEFAULT NULL,
`value` varchar(45) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;
動作確認
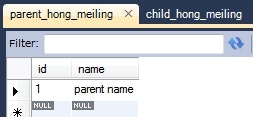
ParentHongMeiling parentHongMeiling = new ParentHongMeiling();
parentHongMeiling.setName("parent name");
this.em.persist(parentHongMeiling);
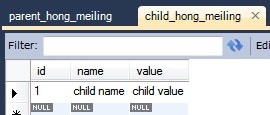
ChildHongMeiling childHongMeiling = new ChildHongMeiling();
childHongMeiling.setName("child name");
childHongMeiling.setValue("child value");
this.em.persist(childHongMeiling);
実行後のデータベースの状態。
-
@InheritanceでInheritanceType.TABLE_PER_CLASSを指定することで、各エンティティをそれぞれ独立したテーブルにマッピングできる。
メリット
-
SINGLE_TABLEと同様で、単一のエンティティの検索でテーブルの JOIN が発生することはない。
デメリット
- データが正規化されていない。
- 多態を利用したフィールドがあった場合、データの読み込みで複数回のデータベースアクセスが発生する可能性がある。
- 例えば、
List<ParentHongMeiling>という型のフィールドがあった場合、リストの中身は実はParentHongMeilingとChildHongMeilingのインスタンスが入り乱れて入っている可能性があり得る。 - その場合、
parent_hong_meilingとchild_hong_meilingのテーブルにそれぞれ検索しにいかなければならない。 -
UNIONが使えればいいが、サポートしていないデータベースも存在する。 - このマッピング方法は、オプションらしい(実装されていなくても JPA の仕様的にはかまわない)。
その他
マッピングのためだけのスーパークラスを定義する
エンティティ
package sample.javaee.jpa.entity.mapping;
import javax.persistence.Id;
import javax.persistence.MappedSuperclass;
@MappedSuperclass
public class MappedKoakuma {
@Id
private Long id;
private String name;
public void setName(String name) {
this.name = name;
}
}
package sample.javaee.jpa.entity.mapping;
import javax.persistence.Entity;
@Entity
public class Koakuma extends MappedKoakuma {
private String value;
public void setValue(String value) {
this.value = value;
}
}
データベース
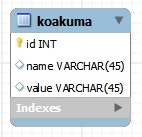
CREATE TABLE `koakuma` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(45) DEFAULT NULL,
`value` varchar(45) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;
動作確認
Koakuma koakuma = new Koakuma();
koakuma.setName("name");
koakuma.setValue("value");
this.em.persist(koakuma);
実行後のデータベースの様子。
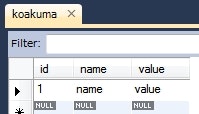
-
@MappedSuperclassでクラスをアノテートすると、そのクラスはエンティティとしては扱われず、マッピングの定義だけが有効になる。 - 既存の実装で共通項目が親クラスに定義されているけど、そのクラスは永続化する必要がない、という場合に使えると思われる。
- 新規に作るのであれば、共通項目は継承関係で解決するよりも組み込み可能クラスを利用して依存関係で解決した方がいいと思う。
Entity Graph で関連するエンティティの読み込みを制御する
関連するエンティティをどのタイミングでロードするかどうかは、これまではフィールド単位に静的にしか指定できなかった(即時ロードと遅延ロード)。
つまり、ある検索のときは即時ロードしたいけど、別の検索のときは遅延ロードにしたい、という細かい制御はできなかった。
しかし、 JPA 2.1 で追加された Entity Graph を使えば、この制御ができるようになる。
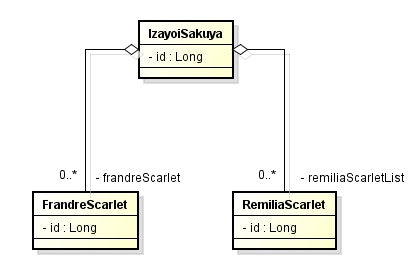
エンティティ
package sample.javaee.jpa.entity.mapping;
import java.util.List;
import javax.persistence.Entity;
import javax.persistence.Id;
import javax.persistence.JoinColumn;
import javax.persistence.NamedAttributeNode;
import javax.persistence.NamedEntityGraph;
import javax.persistence.Table;
@Entity
@Table(name = "izayoi_sakuya")
@NamedEntityGraph(
name = "IzayoiSakuya.remiliaScarletList",
attributeNodes = @NamedAttributeNode("remiliaScarletList")
)
public class IzayoiSakuya {
@Id
private Long id;
@JoinColumn(name = "izayoi_sakuya_id")
private List<RemiliaScarlet> remiliaScarletList;
@JoinColumn(name = "izayoi_sakuya_id")
private List<FrandreScarlet> frandreScarletList;
@Override
public String toString() {
return "IzayoiSakuya{" + "id=" + id + ", remiliaScarletList=" + remiliaScarletList + ", frandreScarletList=" + frandreScarletList + '}';
}
}
package sample.javaee.jpa.entity.mapping;
import javax.persistence.Entity;
import javax.persistence.Id;
import javax.persistence.Table;
@Entity
@Table(name = "remilia_scarlet")
public class RemiliaScarlet {
@Id
private Long id;
@Override
public String toString() {
return "RemiliaScarlet{" + "id=" + id + '}';
}
}
package sample.javaee.jpa.entity.mapping;
import javax.persistence.Entity;
import javax.persistence.Id;
import javax.persistence.Table;
@Entity
@Table(name = "frandre_scarlet")
public class FrandreScarlet {
@Id
private Long id;
@Override
public String toString() {
return "FrandreScarlet{" + "id=" + id + '}';
}
}
データベース
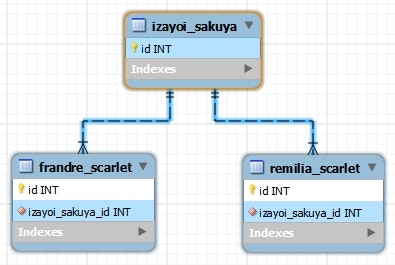
CREATE TABLE `izayoi_sakuya` (
`id` int(11) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8;
CREATE TABLE `frandre_scarlet` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`izayoi_sakuya_id` int(11) NOT NULL,
PRIMARY KEY (`id`),
KEY `frandre_scarlet_fk_idx` (`izayoi_sakuya_id`),
CONSTRAINT `frandre_scarlet_fk` FOREIGN KEY (`izayoi_sakuya_id`) REFERENCES `izayoi_sakuya` (`id`) ON DELETE NO ACTION ON UPDATE NO ACTION
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8;
CREATE TABLE `remilia_scarlet` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`izayoi_sakuya_id` int(11) NOT NULL,
PRIMARY KEY (`id`),
KEY `remilia_scarlet_fk_idx` (`izayoi_sakuya_id`),
CONSTRAINT `remilia_scarlet_fk` FOREIGN KEY (`izayoi_sakuya_id`) REFERENCES `izayoi_sakuya` (`id`) ON DELETE NO ACTION ON UPDATE NO ACTION
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8;
動作確認
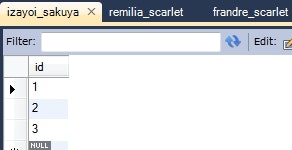
// デフォルト
IzayoiSakuya izayoiSakuya = this.em.find(IzayoiSakuya.class, 1L);
System.out.println(izayoiSakuya);
// Entity Graph を指定
EntityGraph graph = this.em.getEntityGraph("IzayoiSakuya.remiliaScarletList");
Map<String, Object> hint = new HashMap<>();
hint.put("javax.persistence.fetchgraph", graph);
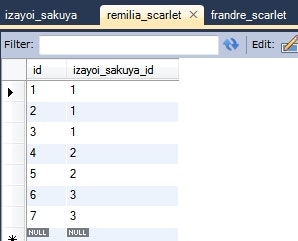
izayoiSakuya = this.em.find(IzayoiSakuya.class, 2L, hint);
System.out.println(izayoiSakuya);
情報: IzayoiSakuya{id=1, remiliaScarletList={IndirectList: not instantiated}, frandreScarletList={IndirectList: not instantiated}}
情報: IzayoiSakuya{id=2, remiliaScarletList={[RemiliaScarlet{id=4}, RemiliaScarlet{id=5}]}, frandreScarletList={IndirectList: not instantiated}}
-
@NamedEntityGraphアノテーションをエンティティに設定することで、 Entity Graph を静的に定義できる。 -
name属性で Entity Graph の名前を、attributeNodes属性で即時ロードするフィールドを指定する。 - Entity Graph を使うかどうかは、
EntityManager.find()の最後に Map を渡すことで指定できる。 - Entity Graph は、
EntityManager#getEntityGraph(String)を使って取得できる。 - キーに
javax.persistence.fetchgraphを、値に Entity Graph を設定した Map を、find()メソッドに渡す。 -
javax.persistence.loadgraphっていうのも指定できるみたいだけど、fetchgraphとの違いがよく分からなかった。。。 - Entity Graph を指定したときだけ、
attributeNodesで設定したフィールドが即時ロードされる。 -
subgraphs属性を指定すれば、さらに掘り下げて読み込み方を指定することができる。
Entity Graph を動的に作成する
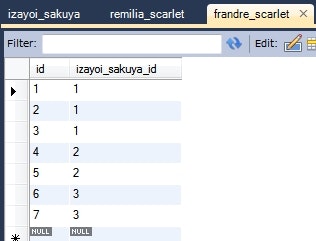
EntityGraph dynamicGraph = this.em.createEntityGraph(IzayoiSakuya.class);
dynamicGraph.addAttributeNodes("frandreScarletList");
hint = new HashMap<>();
hint.put("javax.persistence.fetchgraph", dynamicGraph);
izayoiSakuya = this.em.find(IzayoiSakuya.class, 3L, hint);
System.out.println(izayoiSakuya);
情報: IzayoiSakuya{id=3, remiliaScarletList={IndirectList: not instantiated}, frandreScarletList={[FrandreScarlet{id=6}, FrandreScarlet{id=7}]}}
-
EntityManager#createEntityGraph(Class)で、 Entity Graph を動的に作成することができる。
コンバーターを使用する
JPA 2.1 で、コンバーターという仕組みが追加された。
コンバーターを使えば、データベースとのマッピングを自由に実装することができる。
エンティティ

package sample.javaee.jpa.entity.mapping;
import javax.persistence.Convert;
import javax.persistence.Entity;
import javax.persistence.Id;
import javax.persistence.Table;
import sample.javaee.jpa.converter.LettyWhiterockConverter;
@Entity
@Table(name = "letty_whiterock")
public class LettyWhiterock {
@Id
private Long id;
@Convert(converter = LettyWhiterockConverter.class)
private String value;
@Override
public String toString() {
return "LettyWhiterock{" + "id=" + id + ", value=" + value + '}';
}
}
コンバーター
package sample.javaee.jpa.converter;
import java.util.Objects;
import javax.persistence.AttributeConverter;
import javax.persistence.Converter;
@Converter
public class LettyWhiterockConverter implements AttributeConverter<String, Integer>{
@Override
public Integer convertToDatabaseColumn(String attribute) {
return "hoge".equals(attribute) ? 1 : 0;
}
@Override
public String convertToEntityAttribute(Integer dbData) {
return Objects.equals(dbData, 1) ? "hoge" : "fuga";
}
}
データベース
CREATE TABLE `letty_whiterock` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`value` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8;
動作確認
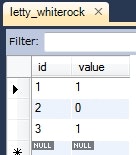
LettyWhiterock lettyWhiterock = this.em.find(LettyWhiterock.class, 1L);
System.out.println(lettyWhiterock);
情報: LettyWhiterock{id=1, value=hoge}
-
AttributeConverterインターフェースを実装することで、コンバーターを作成することができる。 -
convertToDatabaseColumn()メソッドで「Java → データベース」の変換を実装する。 -
convertToEntityAttribute()メソッドで「データベース → Java」の変換を実装する。 -
@Converterでアノテートすることで、 JavaEE サーバーが自動でそのクラスをコンバーターとして認識してくれる。 - コンバーターを使用するときは、フィールドを
@Convertでアノテートして、converter属性でコンバーターの Class を指定する。 -
@ConverterアノテーションのautoApply属性にtrueを設定すると、@Convetでアノテートしなくてもフィールドの型から推測して自動でコンバーターが適用されるようになる(Integerなど基本的な型にも適用されるので、独自の型以外では使わない方がいい)。
参考
- Amazon.co.jp: Beginning Java EE 6 GlassFish 3で始めるエンタープライズJava (Programmer’s SELECTION): Antonio Goncalves, 日本オラクル株式会社, 株式会社プロシステムエルオーシー: 本
- Amazon.co.jp: Enterprise JavaBeans 3.1 第6版: Andrew Lee Rubinger, Bill Burke, 佐藤 直生, 木下 哲也: 本
- Java Persistence/ElementCollection - Wikibooks, open books for an open world
- web用語辞典 - インピーダンス・ミスマッチ
- 東方Projectの登場人物 - Wikipedia
- Forward Everyday: JPA 2.1: Entity Graph
- Thoughts on Java: JPA 2.1 Entity Graph - Part 1: Named entity graphs
- Get current JTA transaction status from CMT EJB « Piotr Nowicki's Homepage
- Java Persistence/What is new in JPA 2.1? - Wikibooks, open books for an open world
- JavaEE 7 JPA 2.1の新機能コンバータ - しんさんの出張所 はてな編