マイクロサービスにおける障害と Failurewall
こちらは Scala Advent Calendar 2015 25日目の記事です。
Scalist の皆さん、一年間お疲れさまでした。
当記事の目的はマイクロサービス(に限らないですが)における失敗の怖さについて説明することと、それを克服するためのライブラリ、Failurewall を紹介することです。
障害は怖い
障害の連鎖
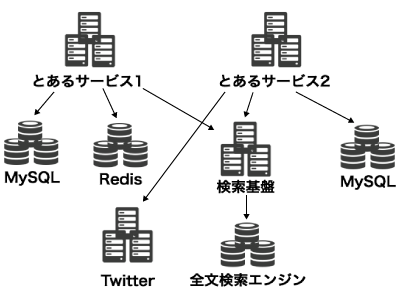
現代的な Web アプリケーションは多くの依存を抱えています。MySQL のようなデータベースに依存することもあれば、Twitter API のような外部サービスに依存することもあるでしょう。マイクロサービスを実践している環境では社内 Web API に依存していたり、あるいは他のシステムが自分のシステムに依存していたりするかもしれません。
このように優秀なミドルウェアや Web API を組み合わせることで、アプリケーションは高い性能を発揮したり、豊かな機能を提供したり、よりよいアーキテクチャを実現したりすることができます。
 !
!
とはいえ、ミドルウェアや外部サービスの API はいつか壊れます。例えば、全文検索を提供するミドルウェアが応答を返せなくなったとしましょう。この場合、検索機能を提供するサービスへのリクエストは、全文検索エンジンへのクエリがタイムアウトするまで待たされることとなるかもしれません。
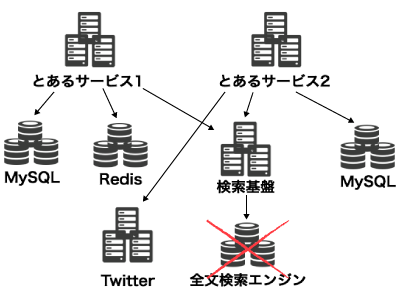
ナイーブな実装だと、検索アプリケーションそのものが壊れてしまうかもしれませんね。例えば、検索クエリにアプリケーションのスレッドがすべて食いつぶされる、というのは想像しやすいシチュエーションではないでしょうか。
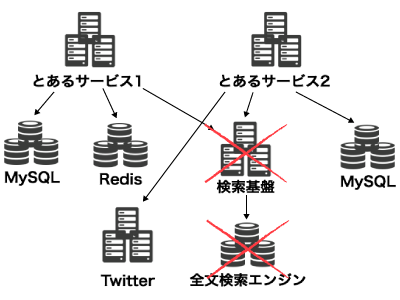
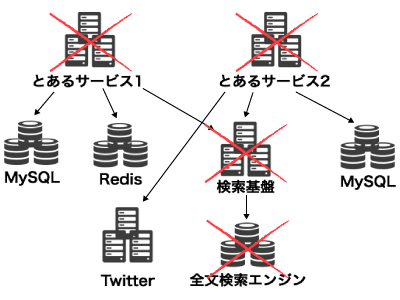
マイクロサービスな環境では、被害はさらに拡大する可能性があります。
Hystrix
今流行りの Netflix は、このような問題に対処するために Hystrix というライブラリを開発しました。Hystrix は以下の要領で、依存リソースの障害に対応します。
スレッドプールの分離
Hystrix は依存リソースの呼び出しをコマンドパターンで記述するインターフェースとなっています。そうして実装されたコマンドは、依存リソースごとに異なるスレッドプールを持つこととなります。
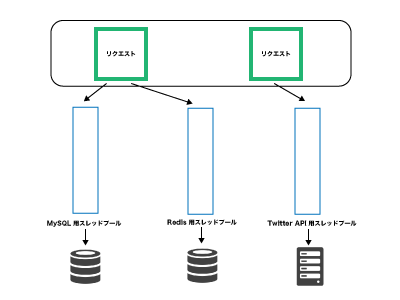
こうすることで、例えば Twitter API を呼び出すスレッドでブロックが多発するような自体に陥っても、その他の処理が動作するスレッドが健在であることを保証できます。
サーキットブレーカー
スレッドプールを分離しても、ユーザーがリクエストする限り、依存リソースへのアクセスは続きます。ダウンした依存リソースへのアクセスはレイテンシの増加を引き起こし、滞留したリクエストは余分なリソースを消費し、そしてユーザーは長時間レスポンスを待つ必要が出てきます。
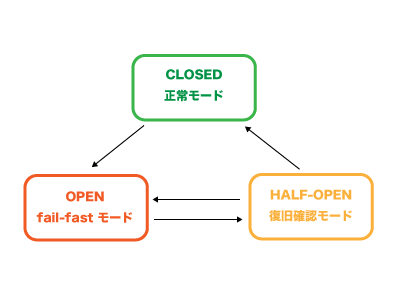
持続的な障害に対し、速やかにエラーを返す仕組みを導入するのが Circuit Breaker Patternです。
サーキットブレーカーはおおまかには以下のように動作します。
- 依存リソースが返すエラー数を記録
- エラーの数が閾値を超えると fail-fast モードへ
- fail-fast モードに移行すると、依存リソースへのアクセスを諦めてすぐにエラーを返すようになる
- fail-fast モードに移行してしばらく経つと、正常モードに戻ろうとする
Failurewall
Failurewall は Hystrix のようなエラー処理を、Scala でシンプルに実現することを目的として作られたプロジェクトです。
以下の二点を重視して作りました。
- 標準ライブラリの
scala.concurrent.Futureに特化したシンプルな API の提供 - エラーハンドリングを必要な分だけ容易に合成できる仕組みの提供
シンプルなインターフェース
Failurewall の使い方は簡単、ハンドリングしたい処理を call メソッドでラップするだけです。
val failurewall: Failurewall[Response, Response] = ???
failurewall.call(httpClient.get("https://github.com/okumin"))
このメソッドを実装することで、新たな機能を持った Failurewall を作成できます。
class RetryFailurewall[A](max: Int)(implicit executor: ExecutionContext) extends Failurewall[A, A] {
override def call(body: => Future[A]): Future[A] = {
def retry(i: Int): Future[A] = {
body.recoverWith {
case e if i == max => Future.failed(e)
case _ => retry(i + 1)
}
}
retry(1)
}
}
Future API に乗っかっているので、実行コンテキストの指定やフォールバック処理の指定もお手のものです。
val mysqlExecutor: ExecutionContext = ???
failurewall.call(Future(sql.execute("SELECT * FROM `tweets`"))(mysqlExecutor))
Failurewall の合成
compose メソッドを用いると、Failurewall の持つ能力を合成することができます。
val wallSina: Failurewall[Int, String] = ???
val wallRose: Failurewall[Int, Int] = ???
val wallMaria: Failurewall[Double, Int] = ???
val humanField: Failurewall[Double, String] = wallSina compose wallRose compose wallMaria
試しにリトライパターンとサーキットブレーカーパターンを組み合わせてみましょう。こうすることで、以下のように動作する Failurewall を作ることが可能です。
- 一時的なエラーはリトライでリカバリー
- 持続的な障害にはサーキットブレーカーで対応
val retryFailurewall: Failurewall[Response, Response] = new RetryFailurewall[Response](max = 10)
val circuitBreakerFailurewall: Failurewall[Response, Response] = ???
val apiFailurewall: Failurewall[Response, Response] = circuitBreakerFailurewall compose retryFailurewall
合成機能により、セマフォによる同時アクセス数の制御、フォールバック機能、モニタリング機能、チャットやメールによるエラー通知機能など、必要な仕組みを手軽にデコレートしていくことが可能です。
その他
導入方法やデフォルトで提供されている Failurewall(e.g. セマフォ、サーキットブレーカー、リトライ) について詳しく知りたい方は github レポジトリをご覧ください。
まとめ
以上、障害の話と Failurewall の紹介でした。
今年も日本 Scala 界は大盛り上がりでしたね。来年は年明け早々 ScalaMatsuri もあることですし、さらなる飛躍が期待できるのではないでしょうか。私も日ごろの感謝をこめて、忍者スポンサーに申し込みました。
みんなで Scala 界を盛り上げていきましょう!
Happy Hacking!