Spark上で実行されるmahout
sparkのモジュールに、mllibと呼ばれる機械学習ライブラリが含まれていますが、mahoutもsparkに対応しました。
ただし、mahoutサイトにも記載されていますが、
Please keep in mind that this code is still in a very early experimental stage
まだ実験段階のようですので感じだけでもつかめたらと思います。
今回、Playing with Mahout's Spark Shellを参考にspark-shell上でのmahoutの実行環境を構築しました。
Install
予めインストールしておくもの
oracle JDK 7以上
maven 3.2.x以上
subversion
Apache sparkのインストール
今回はcdh5のApache sparkをインストールしました。
ここで、インストールするsparkバージョンは0.9.xです。
(1.0.xでためしたところ、サンプルの実行時にエラーが出力されました。)
// CDH5のリポジトリを登録
$ sudo wget http://archive.cloudera.com/cdh5/one-click-install/redhat/6/x86_64/cloudera-cdh-5-0.x86_64.rpm
$ sudo yum --nogpgcheck localinstall cloudera-cdh-5-0.x86_64.rpm
// sparkのインストール
$ sudo yum install spark-core spark-master spark-worker spark-python
installが完了したらsparkを起動しておきます。
$ sudo service spark-master start
$ sudo service spark-worker start
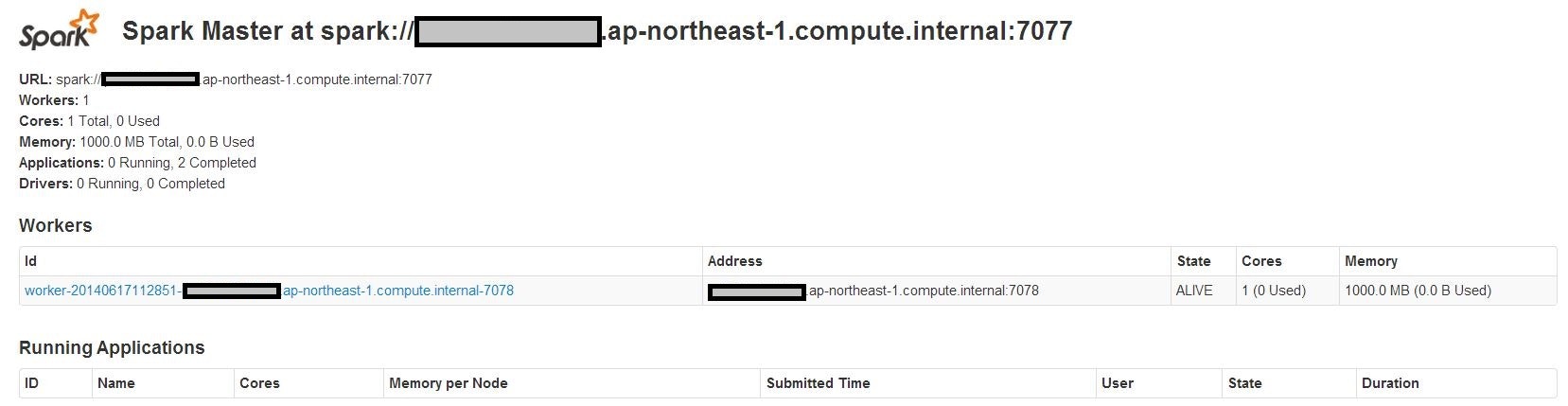
http://<hostname>:18080にアクセスすることで、以下のような画面が確認できると思います。
mahoutのビルド
最新のリポジトリをsvnを利用してチェックアウトし、ビルドを実行します.
mahoutは、任意の場所で構いません。
cd ~/
svn co https://svn.apache.org/repos/asf/mahout/trunk/ mahout
cd mahout/
mvn -DskipTests clean install
mahout shellの起動
環境変数を設定します。
//チェックアウトしたmahoutディレクトリの場所
$ export MAHOUT_HOME=/home/<user>/mahout
// "spark://"から始まるmaster url
$ export MASTER=spark://ip-xxx-xxx-xxx-xxx.ap-northeast-1.compute.internal:7077
// apache sparkのインストールディレクトリ
$ export SPARK_HOME=/usr/lib/spark
shellの実行
cd $MAHOUT_HOME
bin/mahout spark-shell
MAHOUT_LOCAL is not set; adding HADOOP_CONF_DIR to classpath.
14/06/17 11:29:35 INFO spark.HttpServer: Starting HTTP Server
14/06/17 11:29:35 INFO server.Server: jetty-7.x.y-SNAPSHOT
14/06/17 11:29:35 INFO server.AbstractConnector: Started SocketConnector@0.0.0.0:50964
...
Type :help for more information.
mahout>
エラーが発生せず、mahoutシェルが起動すればOKです。
回帰分析処理を実行してみる。
Playing with Mahout's Spark Shellのexampleを実行してみました。
このexampleは、dataset about cerealsに穀類についてのデータの一部を使用しています。
DRM (線形代数処理)用の関数にデータを取り込みます。
drmParallelizeと呼ばれる関数に渡すことで分散処理をさせることができるみたいです。
mahout > val drmData = drmParallelize(dense(
(2, 2, 10.5, 10, 29.509541), // Apple Cinnamon Cheerios
(1, 2, 12, 12, 18.042851), // Cap'n'Crunch
(1, 1, 12, 13, 22.736446), // Cocoa Puffs
(2, 1, 11, 13, 32.207582), // Froot Loops
(1, 2, 12, 11, 21.871292), // Honey Graham Ohs
(2, 1, 16, 8, 36.187559), // Wheaties Honey Gold
(6, 2, 17, 1, 50.764999), // Cheerios
(3, 2, 13, 7, 40.400208), // Clusters
(3, 3, 13, 4, 45.811716)), // Great Grains Pecan
numPartitions = 2);
drmData: org.apache.mahout.sparkbindings.drm.CheckpointedDrm[Int] = org.apache.mahout.sparkbindings.drm.CheckpointedDrmBase@2bc41091
.
.
mahout> val drmX = drmData(::, 0 until 4)
drmX: org.apache.mahout.sparkbindings.drm.DrmLike[Int] = org.apache.mahout.sparkbindings.drm.plan.OpMapBlock@3605a553
.
.
mahout> val y = drmData.collect(::, 4)
y: org.apache.mahout.math.Vector = {0:29.509541,1:18.042851,2:22.736446,3:32.207582,4:21.871292,5:36.187559,6:50.764999,7:40.400208,8:45.811716}
.
.
mahout> val drmXtX = drmX.t %*% drmX
drmXtX: org.apache.mahout.sparkbindings.drm.DrmLike[Int] = OpAB(OpAt(org.apache.mahout.sparkbindings.drm.plan.OpMapBlock@3605a553),org.apache.mahout.sparkbindings.drm.plan.OpMapBlock@3605a553)
.
.
mahout> val drmXval drmXty = drmX.t %*% y
drmXty: org.apache.mahout.sparkbindings.drm.DrmLike[Int] = OpAx(OpAt(org.apache.mahout.sparkbindings.drm.plan.OpMapBlock@3605a553),{0:29.509541,1:18.042851,2:22.736446,3:32.207582,4:21.871292,5:36.187559,6:50.764999,7:40.400208,8:45.811716})
.
.
mahout> val XtX = drmXtX.collect
XtX: org.apache.mahout.math.Matrix =
{
0 => {0:69.0,1:40.0,2:291.0,3:137.0}
1 => {0:40.0,1:32.0,2:207.0,3:128.0}
2 => {0:291.0,1:207.0,2:1546.25,3:968.0}
3 => {0:137.0,1:128.0,2:968.0,3:833.0}
}
.
.
mahout> val Xty = drmXty.collect(::, 0)
Xty: org.apache.mahout.math.Vector = {0:821.6857190000001,1:549.744517,2:3978.7015894999995,3:2272.779989}
.
.
mahout> val beta = solve(XtX, Xty)
beta: org.apache.mahout.math.Vector = {0:5.247349465378446,1:2.750794578467531,2:1.1527813010791554,3:0.10312017617608908}
.
.
mahout> val yFitted = (drmX %*% beta).collect(::, 0)
yFitted: org.apache.mahout.math.Vector = {0:29.131693510783975,1:25.819756349376444,2:23.172081947084997,3:27.266650111384287,4:25.716636173200357,5:32.514955735899626,6:56.68608824372747,7:36.95163570033205,8:39.393069750271316}
.
.
mahout> (y - yFitted).norm(2)
res1: Double = 14.200396723606845
.
.
mahout> def ols(drmX: DrmLike[Int], y: Vector) = {
| val XtX = (drmX.t %*% drmX).collect
| val Xty = (drmX.t %*% y).collect(::, 0)
| solve(XtX, Xty)
| }
ols: (drmX: org.apache.mahout.sparkbindings.drm.DrmLike[Int], y: org.apache.mahout.math.Vector)org.apache.mahout.math.Vector
.
.
mahout> def goodnessOfFit(drmX: DrmLike[Int], beta: Vector, y: Vector) = {
| val fittedY = (drmX %*% beta).collect(::, 0)
| (y - fittedY).norm(2)
| }
goodnessOfFit: (drmX: org.apache.mahout.sparkbindings.drm.DrmLike[Int], beta: org.apache.mahout.math.Vector, y: org.apache.mahout.math.Vector)Double
.
.
mahout> val drmXwithBiasColumn = drmX.mapBlock(ncol = drmX.ncol + 1) {
| case(keys, block) =>
| val blockWithBiasColumn = block.like(block.nrow, block.ncol + 1)
| blockWithBiasColumn(::, 0 until block.ncol) := block
| blockWithBiasColumn(::, block.ncol) := 1
| keys -> blockWithBiasColumn
| }
drmXwithBiasColumn: org.apache.mahout.sparkbindings.drm.DrmLike[Int] = org.apache.mahout.sparkbindings.drm.plan.OpMapBlock@19170713
.
.
mahout> val betaWithBiasTerm = ols(drmXwithBiasColumn, y)
betaWithBiasTerm: org.apache.mahout.math.Vector = {0:-1.3362653883272289,1:-13.15770132067483,2:-4.152654199020216,3:-5.679908094232256,4:163.1793268784127}
.
.
mahout> 14/06/17 12:35:09 INFO scheduler.TaskSchedulerImpl: Remove TaskSet 23.0 from pool
.
.
mahout> goodnessOfFit(drmXwithBiasColumn, betaWithBiasTerm, y)
res2: Double = 7.623280714561956
最後、 7.62... という数字がでました。
この数値が0に近ければ近いほど分析の結果(線の形?)が良いということになる。
感想
- R言語に近い感覚で式を書くことができるということだが、SparkRと呼ばれるものがあるので、どちらが解析などに向いているのか気になる
- mahoutのことも勉強しないと・・・。