1. はじめに
PyTorchの使い方にも少し慣れてきたので、arXivに公開されているディープラーニング関連の論文の実装にチャレンジをはじめました。まず今回はVisualizing and understanding convolutional networksを実装してみました。本論文はディープラーニングの可視化の文献としてよく参照されているので1、以前から興味がありました。
本論文の流れは、前半でCNNの可視化手法を中心に取り扱い、後半では構築したモデルのパフォーマンスを取り扱います。有名な論文ということもあり、Web上で日本語の解説もこちらに公開されています。
本論文の概要に関しては上記リンクの解説の通りなので、本記事では上記解説であまり触れられていない提案された可視化手法の実装に重点を置いて解説してみようと思います。
2. 本論文の概要
CNNは画像分類において高い精度を実現する一方、なぜそれが可能なのかがはっきりしていないという課題があります。本論文の前半では、中間層や分類器の動作を理解する手段として、CNNの各中間層で入力画像の最も反応している部分を可視化する方法が提案されています。
CNNでは入力画像から特徴マップが生成されますが、本論文ではその逆のプロセスとして任意の中間層の特徴マップから入力画像を復元する手法を利用します。
上記の手法では特徴マップ全体が復元対象ですが、ここではさらに工夫を加えます。復元したいCNNの各中間層の特徴マップに対して、活性度が最も高いpixelはそのままにし、それ以外の全てのpixelはすべて0となるように特徴マップを修正します。そしてこの修正された特徴マップに対して、上記手法を適用して入力画像の復元します。
この復元された入力画像は、中間層で最も反応している部分(=特徴マップにおいてもっとも大きな値を持つpixel)をもとに生成されています。つまり、これは入力画像から対象の中間層でもっとも反応した部分のみを抽出することに相当しています。本プロセスを入力層に近い中間層から順に適用していくことで、入力層側の浅い中間層から出力層側の深い中間層に進むにつれて、入力画像のどの部分に最も反応したかを確認することができます。
本論文では入力層に近い浅い中間層ほどコーナやエッジなど具体的な形状に強く反応する一方、出力層に近い深い中間層では犬やキーボードや人の顔などの抽象的な形状に反応していることが示されています。
下図Fig.2(本論文から抜粋)は、入力層に近い浅い中間層のLayer1から出力層に近い深い中間層のLayer5まで上記プロセスを行った結果です。左側の画像が復元された入力画像、右側が元の入力画像になります。深い層ほど抽象的なパターンが抽出できていることがわかります。

3. 取り組んでみたこと
次の4節では、中間層の特徴マップから入力画像を復元する提案手法で用いるMaxUnpooling処理およびDeconvolution処理の概要を記載しています。5節では本論文の提案手法を持ちいて各中間層の最も活性度が高いpixelを元に入力画像を復元してみました。どちらもPyTorchの充実したライブラリを利用することで極めて容易に実装できます。
4. MaxUnpooling処理およびDeconvolution処理
中間層の特徴マップから入力画像を復元する提案手法は、下図のFig.1に概要が記載されています。入力画像にConvolution(畳み込み)処理→ReLU関数→MaxPooling処理を適用して得た特徴マップを入力として、MaxUnPooling処理→ReLU関数→Deconvolution処理を順に適用することで入力画像を再現しています。すなわち復元処理ではConvolution処理にはDeconvolution処理を、ReLU関数には同じReLU関数を、MaxPooling処理にはMaxUnpooling処理を対応させています。
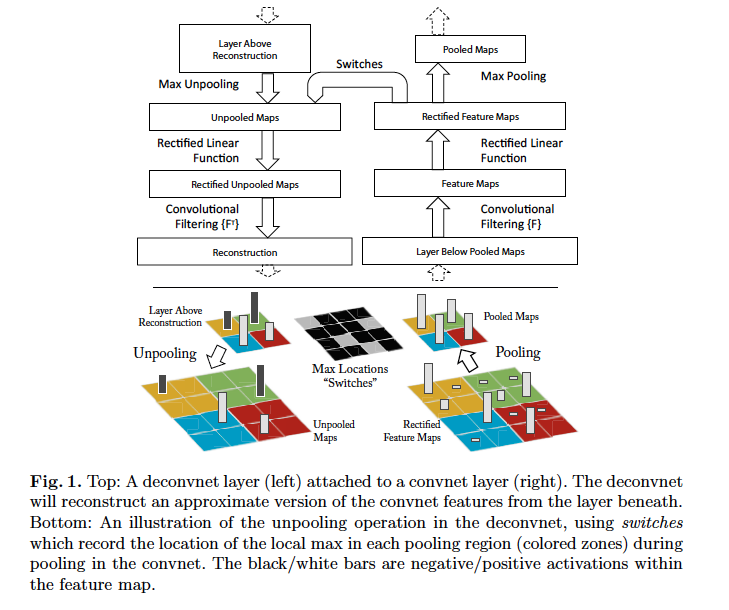
ここからは下の入力画像2を元にMaxUnpooling処理およびDeconvolution処理を見てみます。

4-1. MaxUnpooling処理
MaxUnpooling処理の概要を下図に載せました。左の3x3の入力に対して、カーネルサイズ2x2・ストライド1・パディング0としてMaxPool処理を適用すると中心の2x2の出力が得られます。これにカーネルサイズ2x2・ストライド1・パディング0のMaxUnpooling処理を適用すると、右のような3x3の出力が得られます。

MaxUnpooling処理はMaxPool処理の逆転に相当する処理です。しかし最大値以外の値は0となるため一部の情報は消失しまいます。MaxUnpoolingはPyTorchには既にMaxUnpool2dとして実装済みです。注意点としては、MaxUnpooling処理を行うには、MaxPool処理の適用時に最大値が存在したインデックスをindicesとして取得しておく必要があります。
MaxUnpooling処理の動作を確認するために、MaxPooling処理を行った画像にMaxUnpooling処理を行い元画像を復元してみました。下に処理の概要を抜粋しました。全体のソースコードはこちらにあります。
# MaxUnpooling処理の抜粋
# VGG16モデルの取得
model = models.vgg16(pretrained=True).eval()
# indicesを取得するためにreturn_indicesを設定
for i, layer in enumerate(model.features):
if isinstance(layer, torch.nn.MaxPool2d):
layer.return_indices = True
# VGG16のプーリング層の取得
maxpooling_layer = model.features[4]
# MaxPooling処理の実施およびindicesの取得
maxpooling_result, indices = maxpooling_layer(input_img)
# 入力画像→MaxPooling処理の可視化
visualize(maxpooling_result)
# MaxUnpooling用のパラメータの取得
kernel_size = maxpooling_layer.kernel_size
stride = maxpooling_layer.stride
padding = maxpooling_layer.padding
# MaxUnpooling層の作成
unpooling_layer = torch.nn.MaxUnpool2d(kernel_size, stride, padding)
# indicesを指定してMaxUnpooling処理の実施
unpooling_result = unpooling_layer(maxpooling_result, indices)
# 入力画像→MaxPooling処理→MaxUnpooling処理結果の可視化
visualize(unpooling_result)
下が入力画像→MaxPooling処理を適用した結果です。MaxPooling処理の最大値のみを取得するという動作のため、全体的に画像が粗くなっているのがわかります。

下が入力画像→MaxPooling処理→MaxUnpooling処理を続けて行い、入力画像を復元した結果です。元画像の再現とならず画像に欠損が存在しています。

4-2. Deconvolution処理
Deconvolutionの説明はこちらやこちらにあります。DeconvolutionはPyTorchには既にConvTranspose2dとして実装済みです。CNNにおいて畳み込み処理(Convolution)を行うと、一般的に出力結果の画像の高さや幅は小さくなりチャネル数が増大するのですが、Deconvolution処理ではその逆になります。
特に下のように特徴マップの生成に用いたConvolution処理と同じパラメータを用いてDeconvolution処理を行うことで、特徴マップの入力画像と同じチャネル数と高さと幅を持つ画像を取得できます。
Deconvolution処理の動作を確認するために、Convlution処理を行った画像にDeconvolution処理を行い元画像を復元してみました。下に処理の概要を抜粋しました。全体のソースコードはこちらにあります。
# Deconvolution処理の抜粋
# VGG16モデルの取得
model = models.vgg16(pretrained=True).eval()
# VGG16の畳み込み層の取得
conv_layer = model.features[0]
# 畳み込み処理の実施
conv_result = conv_layer(input_img)
# Deconvolution用のパラメータの取得
in_channels = conv_layer.out_channels
out_channels = input_img.shape[1]
kernel_size = conv_layer.kernel_size
stride = conv_layer.stride
padding = conv_layer.padding
# Deconvolution層の作成
deconv_layer = torch.nn.ConvTranspose2d(in_channels, out_channels, kernel_size, stride, padding)
deconv_layer.weight = conv_layer.weight
# Deconvolution処理の実施
deconv_result = deconv_layer(conv_result)
# 入力画像→Convolution処理→Deconvolution処理結果の可視化
visualize(deconv_result)
MaxUnPooling処理と同じく、入力に対してConvolution処理→DeConvolution処理を続けた結果は、元の入力の完全な再現とならず情報の欠落が発生します。
下が入力画像→Convolution処理→Deconvolution処理を適用して入力画像を復元した結果です。全体的に画像が薄くなっているのがわかります。

5. 再現確認
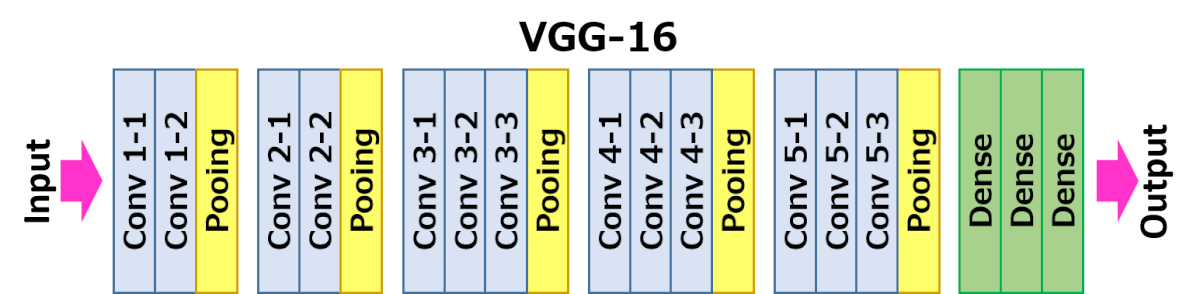
実際に本論文の提案手法を試してみました。ソースコードはこちらにあります。今回の実装ではPyTorchの学習済みモデルのVGG-16を利用しました。VGG−16には下のように全部で5つのMaxPooling層があります。各MaxPooling層経由後に特徴マップから元の入力画像を再現してみました。
入力画像は下のアメリカン・ショートヘアーの画像を利用しました。

入力画像の再現において、A.特徴マップ全体を用いた入力画像の再現と、B.特徴マップ中から値が最大となるpixelのみを用いた入力画像を再現を記載しています。以降の5-1から5-4において上の画像がAに下の画像がBに対応しています。
AとBのどちらにおいても再現する層が深くなるほど、MaxUnpooling処理やDeconvolution処理を行う回数が多くなるため再現された画像が不鮮明となっています。またCNNの各層において入力画像のどこに最も強く反応したのかを意味する下側のBに着目すると5-3.では目に、5-4.では耳に、5-5.では顔に反応しているのがわかります。
これらからCNNの層が深くなるほど、入力画像においてより複雑で抽象度の高いパターンに強く反応していることが可視化されています。
5-1. 1つめのMaxPooling層経由後


5-2. 2つめのMaxPooling層経由後


5-3. 3つめのMaxPooling層経由後


5-4. 4つめのMaxPooling層経由後


5-5. 5つめのMaxPooling層経由後

