はじめに
「かんぽ生命、IBM「ワトソン」で保険金支払い審査 」
http://www.nikkei.com/article/DGXLASFS11H21_R10C17A4EE9000/
(引用)
両社は2015年2月に審査業務への導入の検討を始め、ワトソンには約500万件の過去の支払い事例を機械学習させた。3月21日に審査業務に導入、4月中にコールセンターでの顧客対応にもワトソンを導入する。
生命保険会社が機械学習を導入したという記事が出ていて、気になったので、実際にIBMワトソンを使ってみました。の覚書です。
Natural Language Classifier
NLCはWatsonの自然言語を扱うサービスのことで、
機械学習で作成した分類器を用いて、入力した文章がどういう意味なのかを分類することができます。
料金
気になるのは料金体系で、2017年6月20日現在で、
Natural Language Classifierの場合は、
インスタンス : ¥2,100.00 JPY/ 月 (1個まで無料)
API : 呼び出し ¥0.3675 JPY / 回 (1,000件まで無料)
学習 : ¥315.00 JPY / 回 (4回まで無料)
という料金体系になっていて、若干学習にかかる金額が結構高い気がするなぁと。
100回やると3万円超え。。個人開発にはちょっと厳しいかもなぁという印象。
demo
既にdemoというサイトがあって、こちらで試すことができます。
試しに How hot will it be today? とか打ってみると「99% confident that the question submitted is talking about temperature.」と返ってきます。
https://natural-language-classifier-demo.mybluemix.net/
チュートリアルをやってみる
demoで試したことを実際に1から作ってみます。
(ここから書くことはNLCのチュートリアルをやった覚書です。)
元データはこちらにあるので、あらかじめダウンロードして、設置したパスをメモしておきます。
https://watson-developer-cloud.github.io/doc-tutorial-downloads/natural-language-classifier/weather_data_train.csv
中身はこういう感じのcsvファイルで、txtと分類が書かれています。
How hot is it today?,temperature
Is it hot outside?,temperature
Are we expecting sunny conditions?,conditions
Is it overcast?,conditions
1.アプリを作成する
2.資格情報を確認
サービス資格情報のタブからusernameとpasswordを確認
{
"url": "https://gateway.watsonplatform.net/natural-language-classifier/api",
"username": "",
"password": ""
}
3.学習させるファイルを指定して実行(training_dataはPC上のディレクトリを指定)
データ量によって実行後時間かかる
curl -i -u "{username}":"{password}" -F training_data=@/Users/hoge/blumix_demo/weather_data_train.csv -F training_metadata="{\"language\":\"en\",\"name\":\"TutorialClassifier\"}" "https://gateway.watsonplatform.net/natural-language-classifier/api/v1/classifiers"
4.分類の確認
学習が行われているか調べます。
curl -u "{username}":"{password}" "https://gateway.watsonplatform.net/natural-language-classifier/api/v1/classifiers/{classifier_id}"
5.テキスト分類
実際に分類してみる
curl -G -u "{username}":"{password}" "https://gateway.watsonplatform.net/natural-language-classifier/api/v1/classifiers/{classifier_id}/classify" --data-urlencode "text=How hot will it be today?"
{
"classifier_id" : "{classifier_id}",
"url" : "https://gateway.watsonplatform.net/natural-language-classifier/api/v1/classifiers/hoge",
"text" : "How hot will it be today?",
"top_class" : "temperature",
"classes" : [ {
"class_name" : "temperature",
"confidence" : 0.993505072649582
}, {
"class_name" : "conditions",
"confidence" : 0.0064949273504179865
} ]
6.分類子の削除
いらないやつは消しちゃおう
curl -X DELETE -u "{username}":"{password}" "https://gateway.watsonplatform.net/natural-language-classifier/api/v1/classifiers/{classifier_id}"
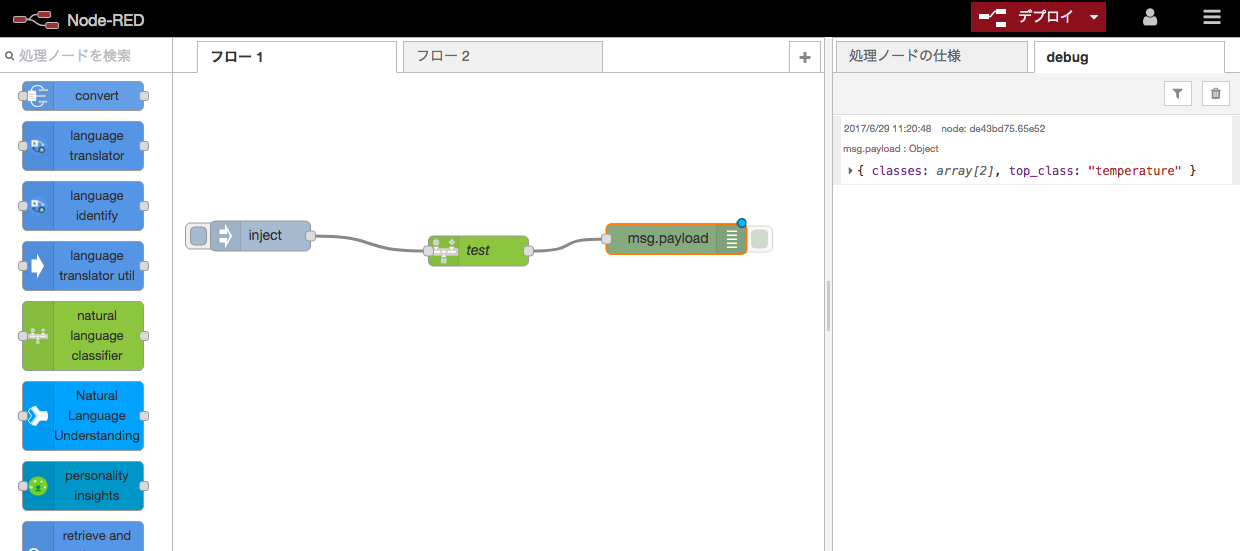
7.Node-REDと組み合わせてみる
Blumix上で展開されているNode-REDというGUIの開発環境を使うと
プログラムせずに色々使えそう。下記はdemo同様にtxtを入力して、途中にNLCを噛ませて、debugした例で、出力に「top_class: "temperature"」と出ています。
おしまい
これで一旦、分類までは完了したのですが、冒頭のかんぽ生命の例を実現するには、
Retrieve and Rankという仕組みを用いて、回答を準備する必要がありますので、これについては次の記事に記載しようと思います。
さて、分類器などはScikit learnなどのPython分類器などもこれまで色々使っていたのですが、
お手軽感はさすがにPaaSに軍配が上がるのと、
今後、R&Rや、Slack連携などいろんなことを考えていくとNode-REDのようなモジュールを繋ぐ仕組みはとても便利だなぁと思う反面、気になるのはコストかな。。
色々なデータを試しながら分類器を作ることになると、1回300円前後のコストは結構地味に聞いてくるので、最初は自前のマシンで実験して、ある程度プロダクションに移行してバンバンAPIからcallするような課程になったら移行するなど選択肢の一つとして持っておくという強みはあるのかなぁと思いました。