前回の記事でOracle Database Cloud Service上に機械学習環境を構築するところまでを書かせていただきました。今回は構築した環境で実際に、Oracle Database Cloud Service上で機械学習を行ってみたいと思います。
機械学習で行える分析とは?
機械学習環境でどんな分析ができるかは、その環境がサポートしているアルゴリズムの種類に依存します。Oracle Database Cloud Serviceで機械学習を行う際には、Oracle DatabaseのOracle Data Miningの機能を活用しますので、Oracle Data Miningでサポートされるアルゴリズムが重要となります。
Oracle Data Miningでは、行いたい分析によって、使用されるアルゴリズムが自動的に選択されるため、アルゴリズムの特性をゼロから学ばなくても簡単に分析を始めることができます。
以下の種類の分析がOracle Database Cloud Service上の機械学習環境で可能です。
1. 回帰
2. 分類
3. 異常検出
4. クラスタリング
5. 相関
6. 属性評価
7. 特徴抽出
1. 回帰
利益や売上などのように予測する値が連続的な量的データのときに使用します。
一般化線形モデル(GLM)とサポート・ベクター・マシン(SVM)がサポートされます。
2. 分類
性別や婚姻ステータスのように予測する値が質的データのときに使用します。
ディシジョン・ツリー(DT),Naive Bayes(NV),GLMとSVMがサポートされます。
ただし、GLMは2クラス・分類という質的値が二種類のものだけをサポートします。
3. 異常検出
機器の故障のような稀に起こった異常値を検出するときに使用します。
1クラス・分類という分類の一種で実装されており、SVMがサポートされています。
4. クラスタリング
どんな顧客セグメントが存在するかなど、とりあえず持っているデータに対してグルーピングをするときに使用します。
k-Means,O-Cluster,EMアルゴリズムがサポートされます。
5. 相関
トランザクションデータの中から、何かと何かがどれくらい関連して発生しているかを検出するときに使用します。
Aprioriがサポートされます。
6. 属性評価
人が離職した際にどんなことが要因だったのかなど、属性の影響度を評価するときに使用します。
Minimum Description Length(MDL)がサポートされます。
7. 特徴抽出
身長、体重、筋肉量など様々な属性を体格と一つに絞るなど、データの可視化の前の次元削減を行う時に使用します。
Non-Negative Matrix Factorization (NMF), Singular Value Decomposition(SVD)とPrincipal Component Analysis(PCA)がサポートされます。
Oracle Database Cloud Service上で機械学習を試してみる
今回も前置きが長くなりましたが、Oracle Database Cloud Service上で機械学習を試してみます。環境は前回構築済みなので、Oracle SQL Developerを立ち上げて接続まで完了したところから始めます。
今回はOracle Data Minerのリポジトリをインストールした際に入るデモ・データでクラスタリングと分類を試していきます。
- プロジェクトとワークフローを作成する
- 元データを選択する
- 元データに対してクラスタリングを行う
- クラスタリングの結果を見る
- 分類モデルを構築する
- 分類モデルを比較する
- 分類モデルを見る
- 予測分析を行う
1.プロジェクトとワークフローを作成する
Oracle Data Minerにおいては、プロジェクトとワークフローという単位で分析フローを管理することができます。一つ一つの機械学習のフローはワークフローに設計し、複数のワークフローはプロジェクトとして管理することができます。
ワークフローで、ノードと呼ばれるOracle Data Minerのアイコンをつないで機械学習フローを設計していきます。
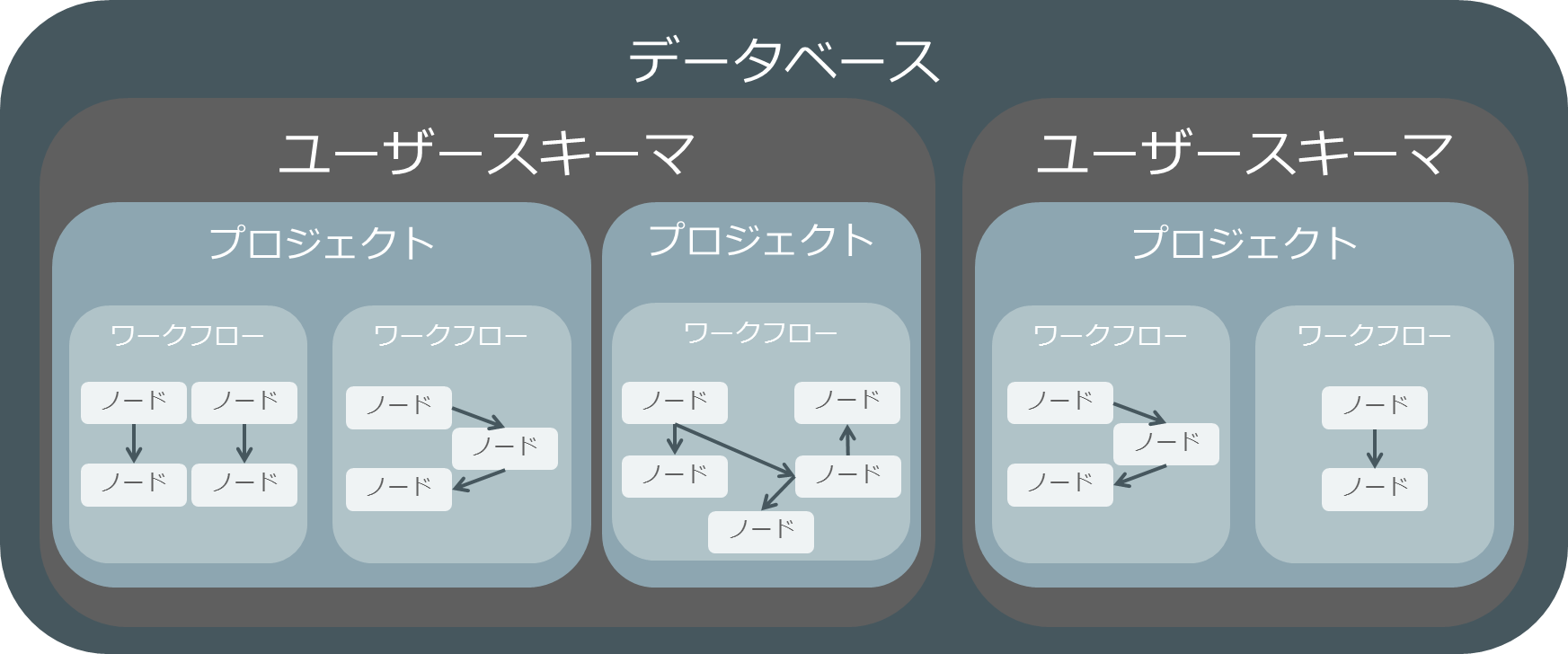
ワークフローはxml形式でエクスポート、インポートが可能です。チームで分析を行って、一部の処理、例えば学習用データ準備のためのETL処理などをチーム内で簡単に共有可能です。
プロジェクトを作成するには、Data Minerの接続タブから作成された接続名を右クリックして、新規プロジェクトを選択します。
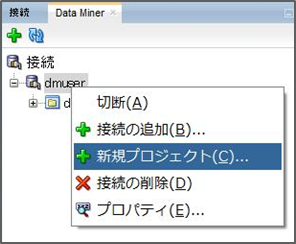
プロジェクト名と必要であれば、コメントを入力してOKを押せば無事にプロジェクトが接続の下に表示されます。
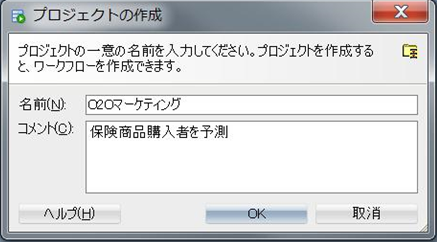
ワークフローは一つのプロジェクトに紐づくため、プロジェクトを右クリックして、新規ワークフローを選択することによって、選択したプロジェクトに紐づいたワークフローを作成できます。
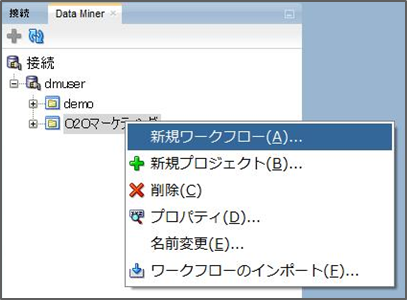
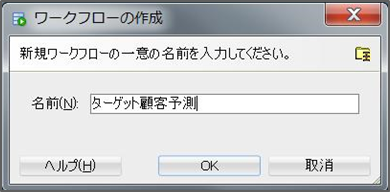
ワークフロー名を入力してOKを押せばワークフロー名がプロジェクトの下に表示され、中心に白い画面が表示されます。
2. 元データを選択する
デフォルトだと画面右側に表示されているOracle Data Minerのワークフロー・エディタからデータソースノードを選択して、中心の白い画面にドラッグ&ドロップしていきます。
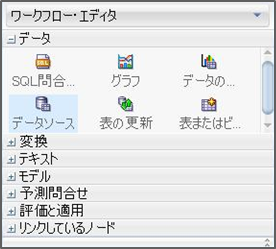
ドロップすると、データソースとして使用可能な表一覧が表示されるため、対象の表を選択します。今回はINSUR_CUST_LTV_SAMPLE表を選択します。
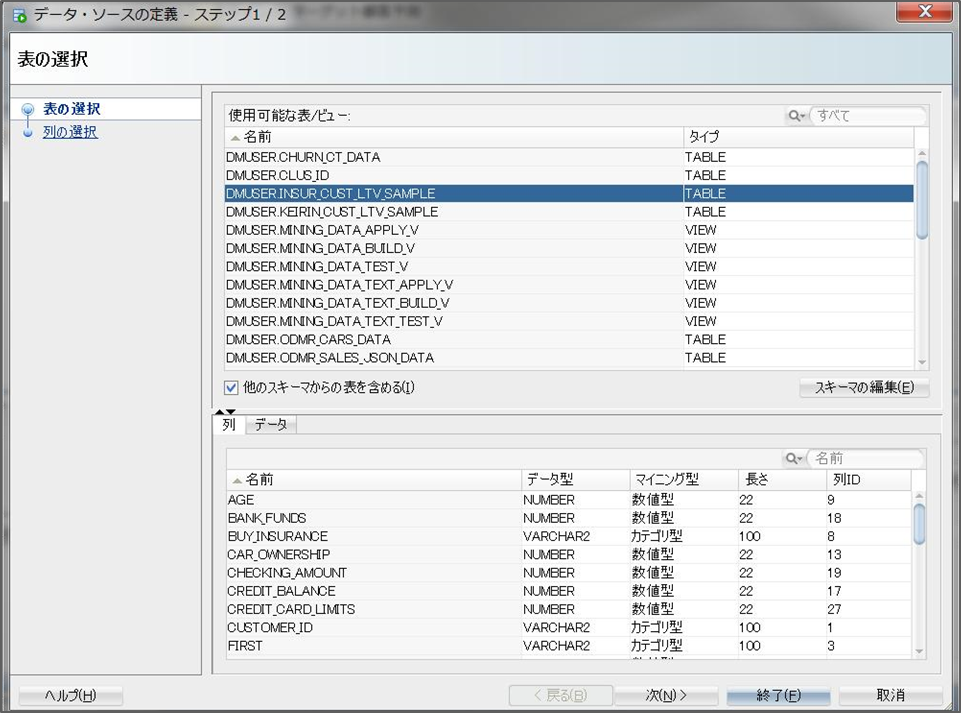
次を選択すると使用する列を指定することもできますが、今回はすべての列を使うため、終了を押します。終了を押すと、中心の白い画面に表名の記されたデータソースノードが表示されます。
3. 元データに対してクラスタリングを行う
データソースに対してクラスタリングを実行するには、ワークフロー・エディタからクラスタリングノードをドラッグ&ドロップしてきます。

ドロップするとクラスタリング構築というノードが作成されます。この時点では右上にWarningのマークが出ており、実行することはできません。データソースノードを右クリックし、接続を選択します。接続を選択すると線が出てくるため、クラスタリング構築のノードに合わせてクリックします。
そうするとデータソースノードとクラスタリング構築のノードが矢印で結ばれます。
ここまでで実行する準備が整ったため、クラスタリング構築のノードを右クリックし、実行を選択します。
実行が完了すれば、ノードの右上に緑色のチェックマークがつきます。これでクラスタリングは完了です。データソースとクラスタリング構築のノードを二つ持ってきて、矢印で結んで実行するだけでクラスタリング分析ができます。
4. クラスタリングの結果を見る
せっかくクラスタリングを行ったので、その結果についてみていきたいと思います。クラスタリング構築では、三つのアルゴリズム(k-Means,O-Cluster,EMアルゴリズム)がデフォルトだと同時に実行されて構築されます。今回は、k-Meansの結果についてみていきたいと思います。
クラスタリング構築ノードを右クリックして、モデルの表示からCLUS_KM_x_xを選択します。xとした部分は、クラスタリングモデルを構築した際に、名前が重複しないように数字が入って来ますので、それぞれの環境や実行した回数によって違う数字が入るかと思います。
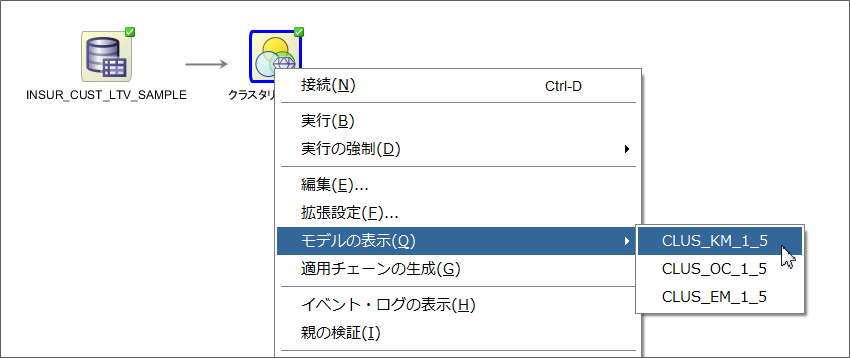
選択すると新たにタブが開き、クラスタリングモデルの結果を確認することができます。Oracle Database Cloud Serviceで提供されているk-Meansは正確には拡張k-meansとなっており、階層型のクラスタリングを構築します。デフォルトだと、末端のクラスタの数が10になるようにクラスタリングを行います。ツリー構造をGUIで確認でき、特定のクラスタを選択すると、重心やそのクラスタに入るための条件を確認することができます。

ツリータブの横のクラスタタブを選択すると、クラスタごとの属性別のヒストグラムを確認することができます。そのクラスタの各属性がどのような分布を持つかを確認することによって、機械が自動的にふるい分けたクラスタの特徴を見つけ出すことができます。

他にも比較というタブからはクラスタ同士の相違点をチェックすることなど、自動的に分けられたクラスターを人間が理解できるように直感的にわかりやすい形で表示する機能を持っています。
5. 分類モデルを構築する
データソースに対して分類モデルを構築するには、ワークフロー・エディタから分類ノードをドラッグ&ドロップしてきます。
ドロップすると分類構築というノードが作成されます。クラスタリング分析のときと同じように、データソースノードを右クリックし、接続を選択し、分類ノードに合わせてクリックします。
分類ノードをクリックすると、ウィンドウが立ち上がります。分類はクラスタリングと違い、教師あり学習という種類の機械学習を行うため、正解データ(ラベル)がどれかを機械に教える必要があります。ウィンドウの中のターゲットと書かれている箇所にラベルとなる列名を選択します。ケースIDは一意なキーがどの列かを機械に教えることによってパフォーマンスが向上します1。
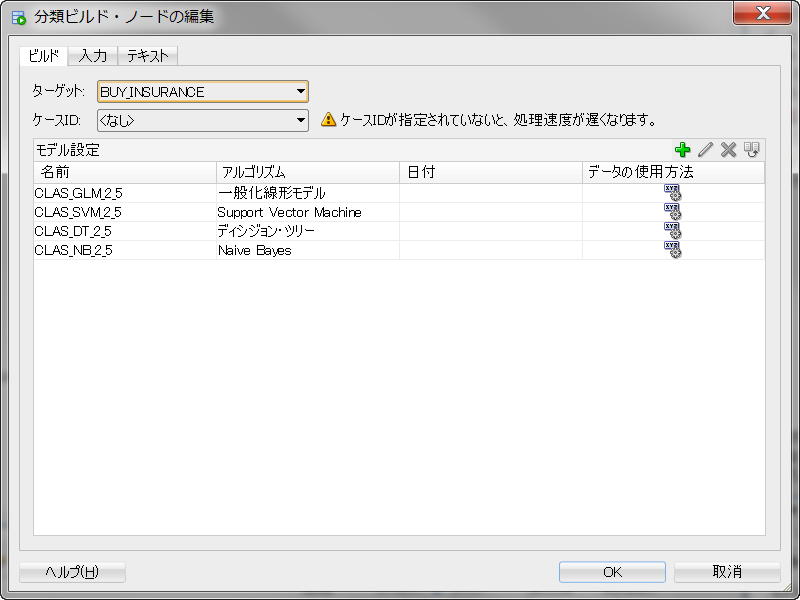
ターゲットとケースIDの選択が終われば、あとはOKを押します。OKを押すと、データソースノードと分類ノードが矢印で結ばれます。
実行する準備が整ったため、分類ノードを右クリックし、実行を選択します。実行が完了すれば、ノードの右上に緑色のチェックマークがつきます。分類もクラスタリングと同じような手順で行うことができます。
6. 分類モデルを比較する
それでは作成した分類モデルを見ていきたいと思います。分類では、四つのアルゴリズム(DT,NV,GLMとSVM)がデフォルトだと同時に実行されます。クラスタリングは教師なし学習という種類の機械学習だったため、正解を求めるものではなく、モデルの精度などを考える必要はありませんでした。分類は教師あり学習のため、作成したモデルがどれくらいの精度を持つものかを把握する必要があります。
テスト結果を比較するには、分類構築ノードを右クリックして、テスト結果の比較を選択します。
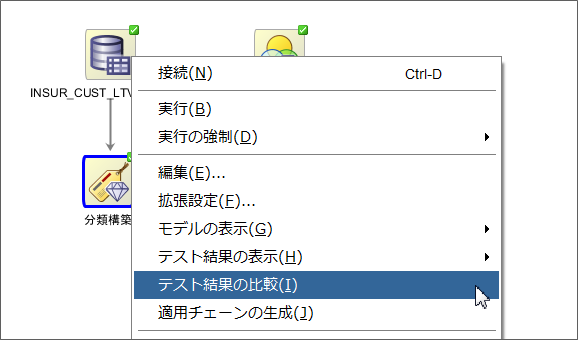
テスト結果の比較を選択するとタブが開き、実行したアルゴリズム全てをグラフィカルに比較することができます。
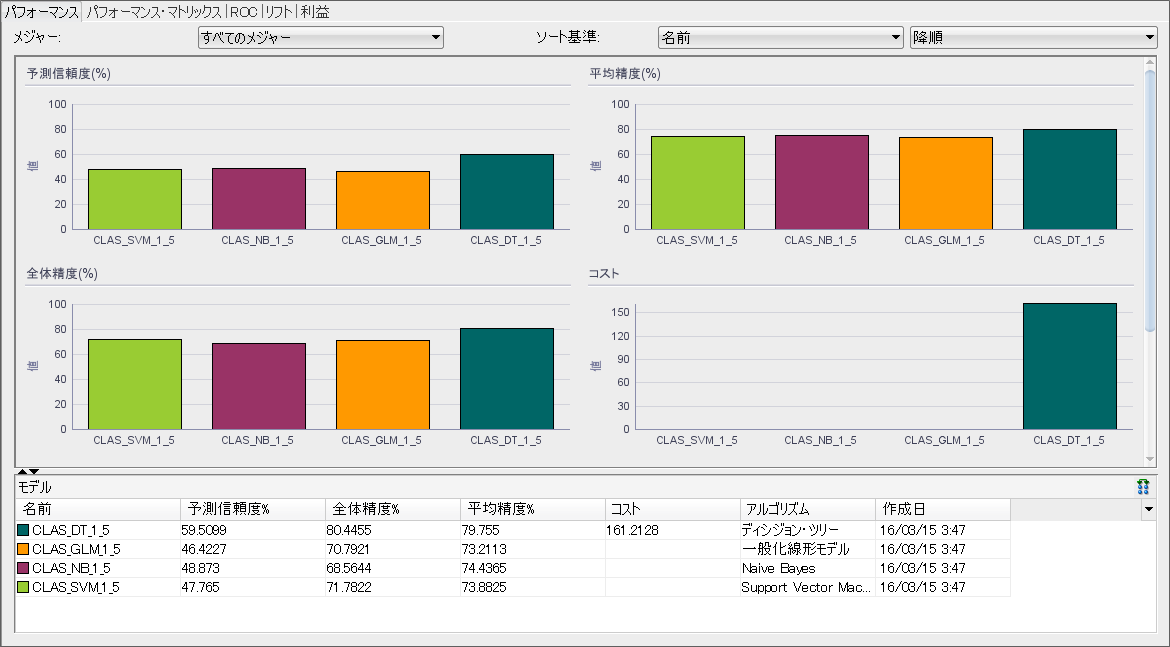
パフォーマンスからは各モデルの予測信頼度や全体精度、平均精度等をアルゴリズムごとに棒グラフで比較して見れます。基本的には一番棒グラフが高いアルゴリズムがいいことになります。画面ショットの例だとディシジョン・ツリーが一番良さそうに見えます。ただ、これだけだと正しくターゲットを当てられた割合(真陽性:True Positive)、ターゲットであったのに当てられなかった割合(偽陽性:False Positive)、ターゲットでないのに間違ってターゲットとしたもの(偽陰性:False Negative)、ターゲットでないものを正しく当てられた割合(真陰性:True Negative)がわかりません。パフォーマンス・マトリックスタブを選択すると、各モデルの詳細精度を見ることができます。
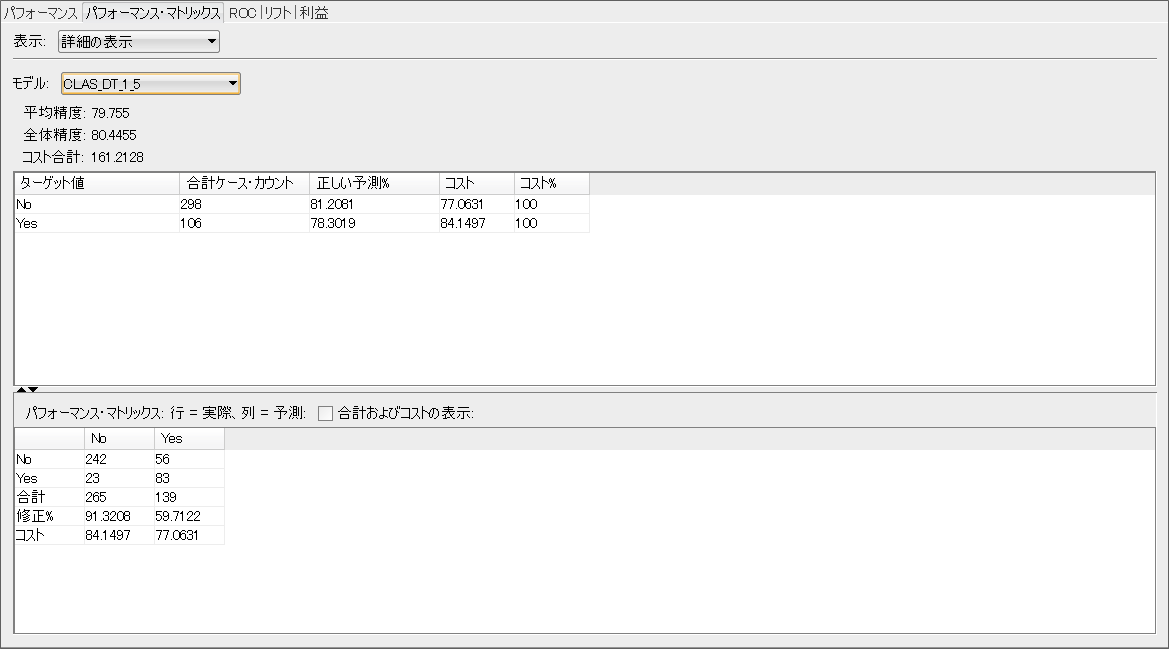
パフォーマンス・マトリックスより、行を実際の値、列を予測として確認できます。スクリーンショットの例では、ディシジョン・ツリーのモデル(CLAS_DT_x_x)におけるTrue Positiveが83、False Positiveが23、False Negativeが56、True Negativeが242となっていることが確認できます。
この値を閾値を変えて全て見比べていくのも大変なので、True Positive Rateを縦軸に、False Positive Rate横軸にしたROC曲線(受信者動作特性曲線:Receiver Operatorating Characteristic curve)というものがあります。ROCタブから全モデルのROC曲線を確認できます。
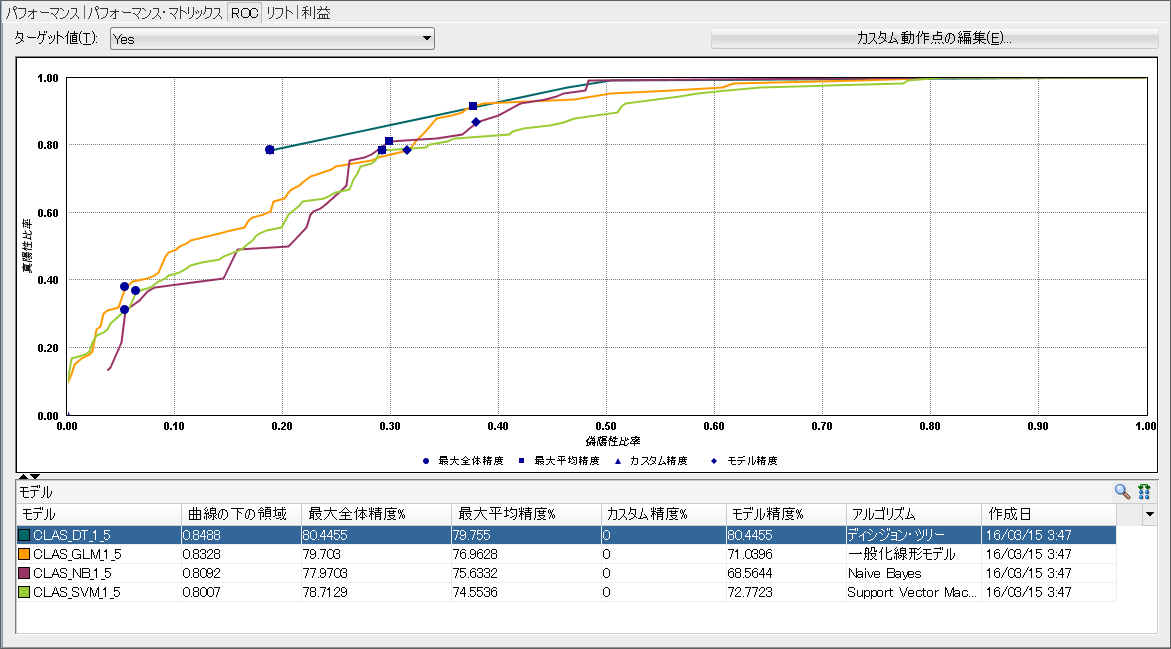
True PositiveとFalse Positiveの組み合わせなので、曲線が左上に近いところでカーブしているほど、ターゲットを正しく当てながら、漏れが少ないモデルとなります。曲線を一つの変数として評価する値はAUC(Area Under Curve)と呼ばれますが、ここでは曲線の下の領域として表示されています。この値が高いほど良いモデルといえます。
DM顧客の抽出、チャーン顧客分析などで、ターゲットの何割にアプローチしたらどれだけのTrue Positiveになるかだけを知りたいことも多くあります。そのような場合にはリフトチャートを使います。リフトタブを選択すると全モデルのリフトチャートを確認できます。
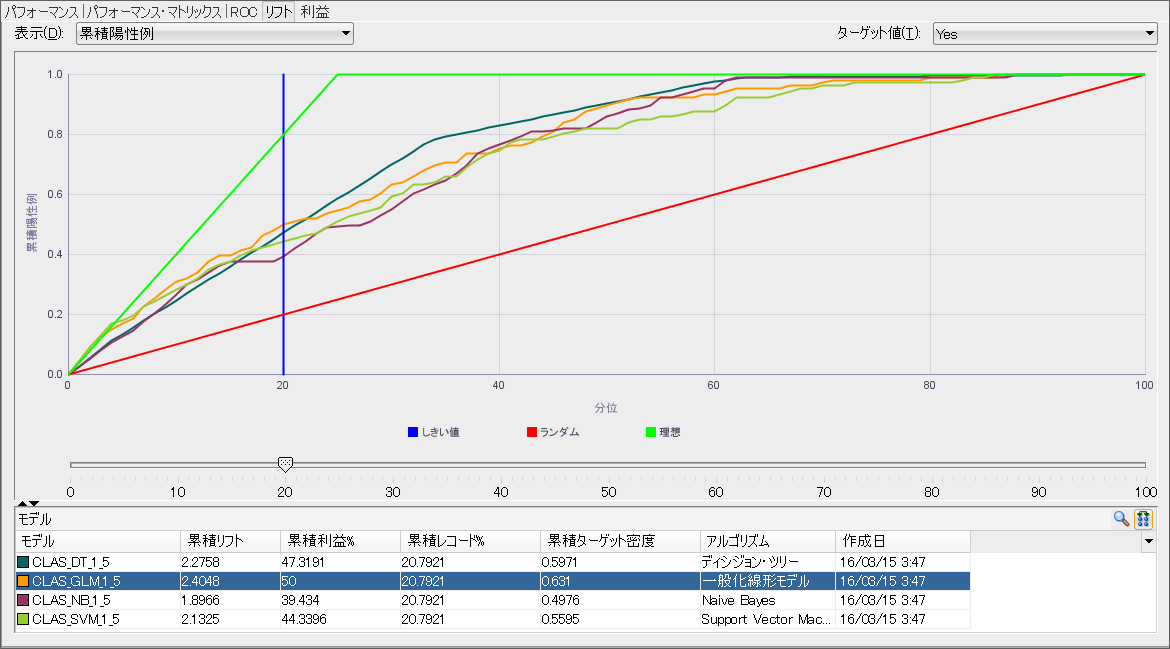
リフトチャートはTrue Positive Rateを縦軸に、アプローチした数を横軸としています。左上に急に立ち上がっているグラフほど、より少ない数のアプローチでターゲットに当たることができるため、効率の良いモデルとなります。今回のスクリーンショットの例だと、アプローチの数が少ない場合には、一般化線形モデルの精度がいいですが、アプローチの数がある程度増えてくるとディシジョン・ツリーがよりターゲットに当たる割合が多くなることがわかります。
リフトチャートまで、考えていくとターゲットに当たった際の収益とアプローチごとにかかるコストから、どれだけの利益が出るかを見たい場合があります。その場合には、利益タブを選択することによって、全モデルの最大利益を比較することができます。
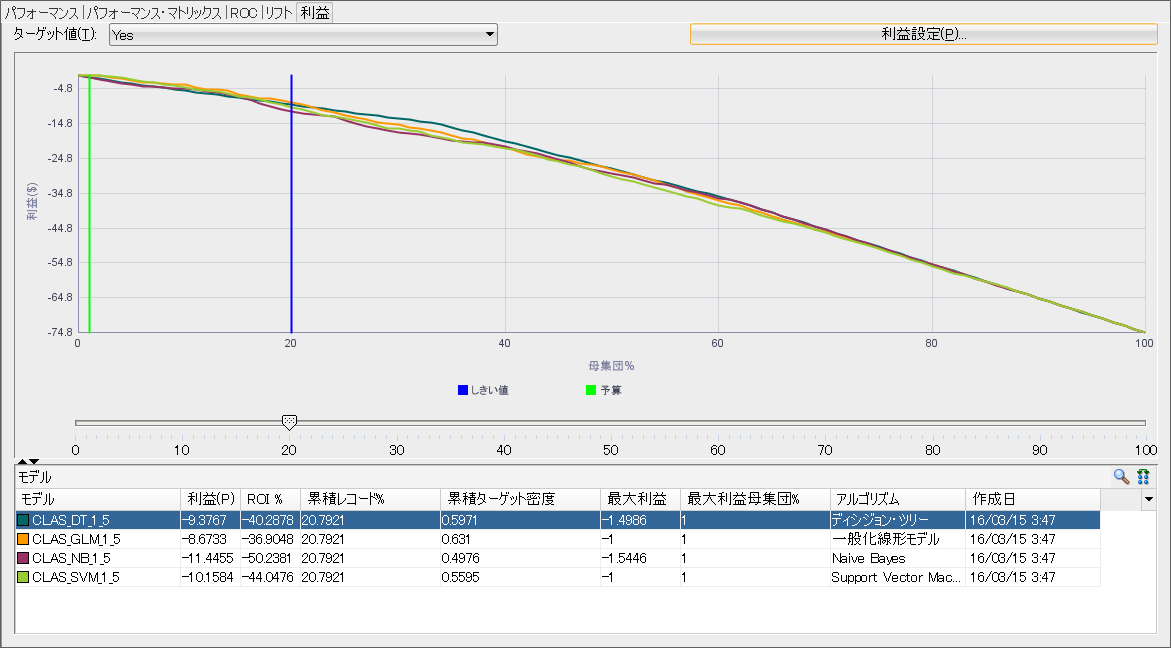
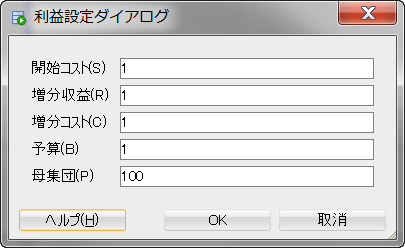
デフォルトでは、利益設定が開始コスト、増分収益、増分コスト、予算がすべて1で母集団が100と設定されています。実際のビジネスにあった値に更新し、OKを選択することによって、値を反映したグラフに書き換わります。
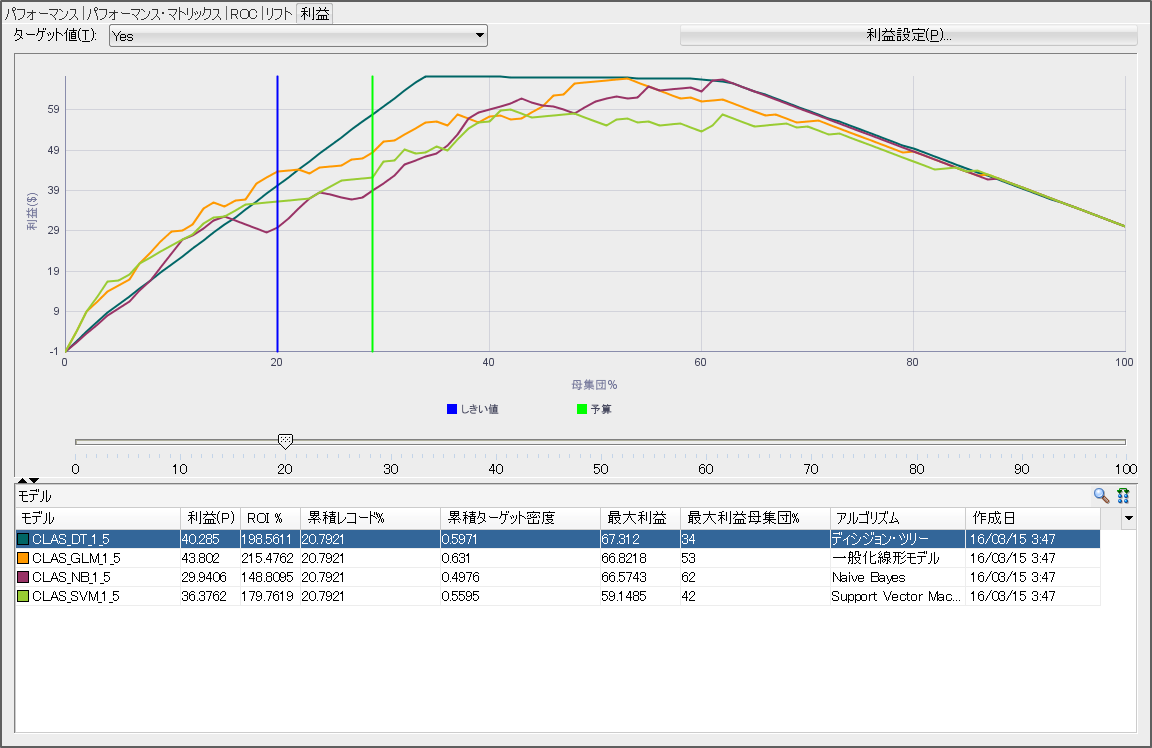
増分収益を5、予算を30に更新した場合の状態を下に載せます。
モデルを作るの方法はシンプル化されていますが、モデルを見る方法は様々な方法が提供されています。用途に合ったモデルの精度の確認方法が一通り提供されていることを確認できるかと思います。
7. 分類モデルを見る
四つのアルゴリズム(DT,NV,GLMとSVM)で分類モデルを構築し、モデルの精度に関してみてきましたが、ディシジョン・ツリーの中身をもう少し見ていきたいと思います。ワークフローの画面に戻り、分類構築のノードを右クリックし、モデルの表示から、ディシジョン・ツリーに該当するモデルを選択します。今回の例だとCLAS_DT_x_xがディシジョン・ツリーに該当するので、こちらを選択します。
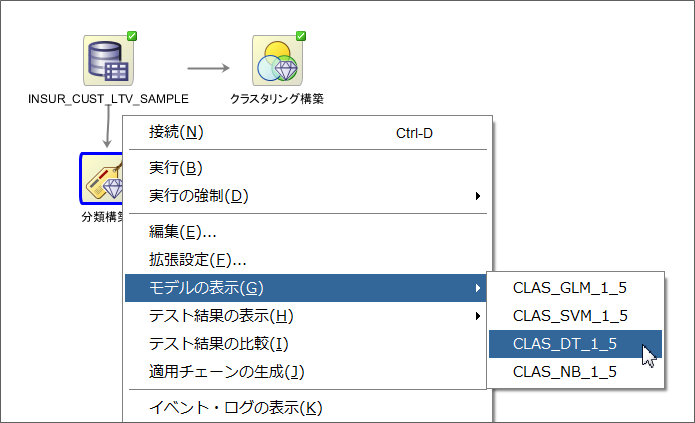
タブが開いて、ディシジョン・ツリーがどのような条件を元に分類しているかを確認できます。各ノードごとにラベルとして設定した列の値の割合を表示しながら、どの列を元に条件分岐しているかが表示されています。特定のノード2を選択すると、そのノードに入るための条件式、信頼度とサポート(出現頻度)が確認できます。
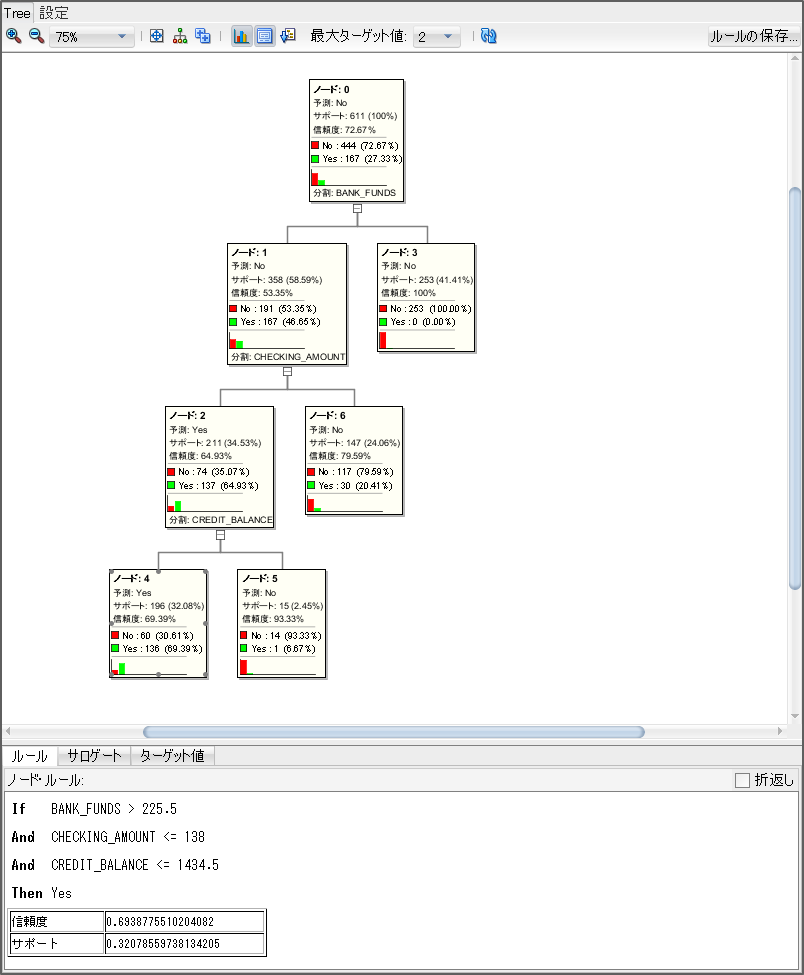
モデルによって見える内容が違いますが、人の感覚でモデルのロジックをとらえやすいものはディシジョン・ツリーと一般化線形モデルになると思います。同じ手順で一般化線形モデルのモデルを選択すると各列がどれくらい影響があるのかがわかります。

8. 予測分析を行う
モデルも無事に作成できているので、新しいデータに対して予測を行って行きます。ワークフロー・エディタから適用ノードとデータソースノードをドラッグ&ドロップしてきます。データソースノードは本来は予測するテーブルを選択しますが、今回はデモデータを使用しているため、学習用で使用したINSUR_CUST_LTV_SAMPLE表を再度選択します。内部的には同じ列名でスコアリングして動作する仕組みなので、列名さえ同じであれば問題ありません。わかりやすくするために、データソースのアイコンの名前だけ(INSUR_CUST_LTV_SAMPLE->INSUR_CUST_LTV_APPLY)変えています。
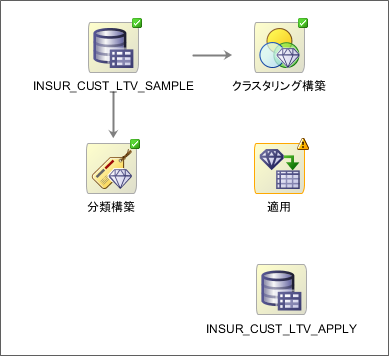
分類構築とINSUR_CUST_LTV_APPLYをそれぞれ右クリックして適用ノードと結びます。これまでは、一つのノードを一つのノードと接続していましたが、適用ノードはどのモデルをどのデータに反映させるかを表すために二つのノードと結ぶ必要があります。このまま実行しても結果が出力されますが、出力結果をわかりやすくするために、出力結果を編集します。適用ノードを右クリックして編集を選択します。
ウィンドウが開かれるとこのまま出力される予定の列がすべて表示されます。このまま実行すると全モデルでの予測値などが表示されることになるので、今回はディシジョン・ツリー以外の出力はなくすことにします。自動設定のチェックボックスがチェックされていると編集できないため、チェックを外して不要な列を削除していきます。
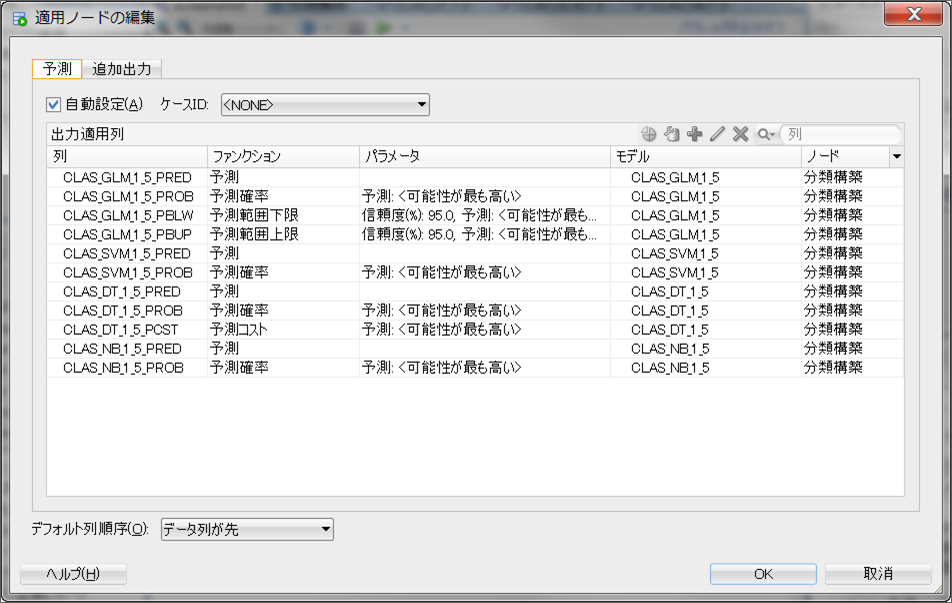
また、このままでは予測値しか出力されないため、追加出力タブから追加したい列名を選択します。今回は、CUSTOMER_ID列を追加します。
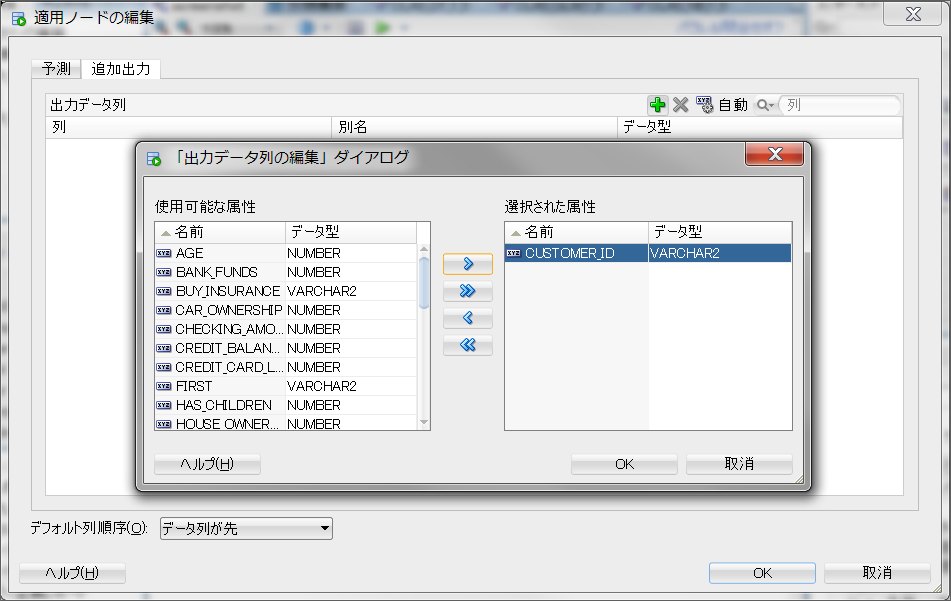
あとは、これまでと同様に、適用ノードを実行すれば完了です。実行が完了したら、適用ノードを右クリックしてデータの表示を選択します。
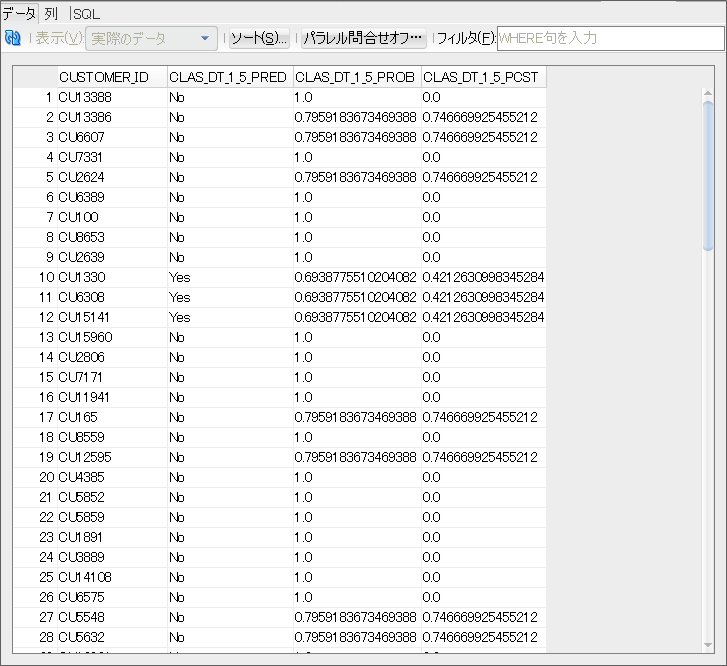
CUSTOMER_IDごとに予測値となるyes,noが出力されているのを確認できるかと思います。
Oracle Database Cloud Service上で機械学習を試してみたはこれで終了となります。
次回はこの環境で実際にデータをロードして分析を行い、特定の分析に深く焦点を当てていきたいと思います。