ビット演算テクニック Advent Calendar 2016 12日目の記事です。
みんな大好きbitDPの話です。編集距離 (Edit Distance: ED) をbitDPを使って計算する話を少々。
編集距離とは
まずは定義から。
編集距離 (ED; レーベンシュタイン距離: Levenshtein Distanceとも) は、2つの文字列の間で定義され、片方の文字列をもう一方の文字列に変換する場合の最小の {置換, 挿入, 削除} 回数を表す。
例えば、abcdefgとabxdegの編集距離は2で、うちわけは置換が1回 (c → x)、挿入が0回、削除が1回 (f)となります。
ふつうに解く
2次元のDPで解けることが知られています。ここでは漸化式だけ示します。
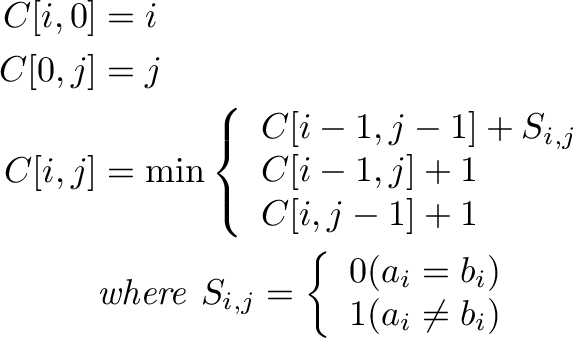
bitDPで解く
Myersのアルゴリズムという、ビット並列のアルゴリズムが知られています。日本語の解説記事も多く書かれており、知っている人も多いかと思います。
DP変数1セルに対し1bitのカラムを割り当て、64bitのレジスタを使って64セル並列に漸化式を計算するアルゴリズムとなっています (すごい)。もちろん上に示した漸化式のままでは1セル1bitで表現することはできないので、このアルゴリズムでは、セル値の代わりに隣接するセル値の差分を表現することで必要なビット幅を圧縮する工夫をしています。編集距離の漸化式ではこの差分が {-1, 0, 1} の3通りとなるため (証明は論文にあります)、pとmの2つの変数を用意し {(p, m)} = {(0, 1), (0, 0), (1, 0)} に対応させることで、1セル1bit x レジスタ4本 (p, mを縦横それぞれ) を実現しています。
1セル1bitなので、そこらのSIMD並列より並列度が高いことと、依存関係のチェインを加算命令のキャリーを使って解決しているところがうまい点です。
LLCSも解けるはず
最長共通部分列長 (Length of Longest Common Substring: LLCS) も類似の2次元DPで解くことができます。これも隣り合うDP変数の差分が {0, 1} のいずれかとなるため、編集距離の場合と同様にbitDPに帰着させることができます。現在もっとも綺麗なアルゴリズムはHyyröによるもののようです。発想はEDのアルゴリズムと同様ですが、片方の変数 (水平差分) を反転させることで演算の回数を減らしています。
とりあえず実装しよう
このアルゴリズムが強力なのは、必要なデータをすべてレジスタにのせたまま64セルの更新が可能な点です。この特徴を損ねないよう注意深く記述します。
しかし任意長の入力を受け取れるようにするのはなかなか面倒なので、入力は最長64文字までという仕様にします。 uint64_t editdist(char const *a, uint64_t alen, char const *b, uint64_t blen); とすればそこそこに実用的に使えるかなと。例えば文章中一部を切り出してEDを計算するような場合に、zero-copyで実現できますね。
コード
uint64_t editdist(
char const *a,
uint64_t alen,
char const *b,
uint64_t blen)
{
v32i8_t a1 = _loadu_v32i8(a), a2 = _loadu_v32i8(a + 32);
uint64_t ph = 0xffffffffffffffff, mh = 0;
for(char const *p = b; p < b + blen; p++) {
v32i8_t b = _set_v32i8(*p);
uint64_t eq = (_m(_eq_v32i8(b, a2))<<32) | _m(_eq_v32i8(b, a1));
uint64_t xh = eq | mh, xv = (((eq & ph) + ph) ^ ph) | eq;
uint64_t pv = mh | ~(xv | ph), mv = ph & xv;
pv<<=1; mv<<=1; pv |= 0x01ULL;
ph = mv | ~(xh | pv); mh = pv & xh;
}
uint64_t mask = (0x01ULL<<alen) - 1;
return(blen + popcnt(ph & mask) - popcnt(mh & mask));
}
uint64_t llcs(
char const *a,
uint64_t alen,
char const *b,
uint64_t blen)
{
v32i8_t a1 = _loadu_v32i8(a), a2 = _loadu_v32i8(a + 32);
uint64_t h = 0xffffffffffffffff;
for(char const *p = b; p < b + blen; p++) {
v32i8_t b = _set_v32i8(*p);
uint64_t eq = (_m(_eq_v32i8(b, a2))<<32) | _m(_eq_v32i8(b, a1));
uint64_t v = h & eq; h = (h + v) | (h - v);
}
uint64_t mask = (0x01ULL<<alen) - 1;
return(alen - popcnt(h & mask));
}
コンパイル結果
clang-3.9 -O3 -msse4.1 on macです。EDの実装の再内のループのみ示します。意図通りメモリへの退避/リロードはなくせました。
LBB0_2: ## =>This Inner Loop Header: Depth=1
movzbl (%rdx), %ebx
movd %ebx, %xmm5
pshufb %xmm4, %xmm5
movdqa %xmm5, %xmm6
pcmpeqb %xmm2, %xmm6
pmovmskb %xmm6, %ebx
movdqa %xmm5, %xmm6
pcmpeqb %xmm3, %xmm6
pmovmskb %xmm6, %ecx
shll $16, %ecx
orl %ebx, %ecx
shlq $32, %rcx
movdqa %xmm5, %xmm6
pcmpeqb %xmm0, %xmm6
pmovmskb %xmm6, %edi
pcmpeqb %xmm1, %xmm5
pmovmskb %xmm5, %ebx
shll $16, %ebx
orl %edi, %ebx
orq %rcx, %rbx
movq %rbx, %rcx
andq %rax, %rcx
addq %rax, %rcx
xorq %rax, %rcx
orq %rbx, %rcx
orq %r13, %rbx
movq %rcx, %rdi
orq %rax, %rdi
notq %rdi
orq %r13, %rdi
andq %rax, %rcx
addq %rcx, %rcx
leaq 1(%rdi,%rdi), %rdi
movq %rdi, %rax
orq %rbx, %rax
notq %rax
orq %rcx, %rax
andq %rdi, %rbx
incq %rdx
cmpq %r12, %rdx
movq %rbx, %r13
jb LBB0_2
おわりに
- ベンチマークとらないとね
- 配列のロード、ページ境界をまたぐとSEGVする可能性があるね......
- UTF-8を食えるようにするにはどうすればいいだろうか...
というわけで、これらの問題が解決したら随時アップデートします。
明日 (今日) はそすうさん (@_primenumber) の並列Bit Scan Reverseだそうです。