DynamoDBは高機能なフルマネージドKVSで、以下のようなことができます。
- ハッシュキーをプライマリキーとしたItemの取得
- 普通のKVS的な使い方
- ハッシュキー, レンジキーをプライマリキーとした高速なクエリ
- レンジキーをtimestampなどにすることで、時系列クエリが可能
DynamoDBを時系列テーブルとして扱う場合、「一定期間内で最初(or 最後)の1項目だけを取得」といったことをしたいケースはあるかと思います。
ここで気になるのは消費キャパシティです。
結論から言うと、queryにおいてLimitを指定した場合、消費されるのはそのLimitで返される分のみとなります。
検証
DynamoDBのドキュメントには、次のような記述があります。
リクエストでは、Limit パラメータに、DynamoDB が結果を返す前に処理する項目数を設定します。
が、消費キャパシティがどうなるのか読み取りづらいため、念のため検証してみます。
こちらのScalaアプリ( https://github.com/ocadaruma/dynamodb-query-example )を使って、
- DynamoDBテーブルを作成し、RCUを
5に設定 - DynamoDBテーブルに、1KBくらいのItemを1000個put
- 2つのパターンのqueryを実行し、消費キャパシティの観察
- 1000個を取得するクエリを100回実行(Limit = 1000)
- 1個を取得するクエリを100回実行 (Limit = 1, レンジキーの範囲は↑と同じ)
を行います。
$ export AWS_ACCESS_KEY_ID=your_key
$ export AWS_SECRET_ACCESS_KEY=your_secret
$ sbt
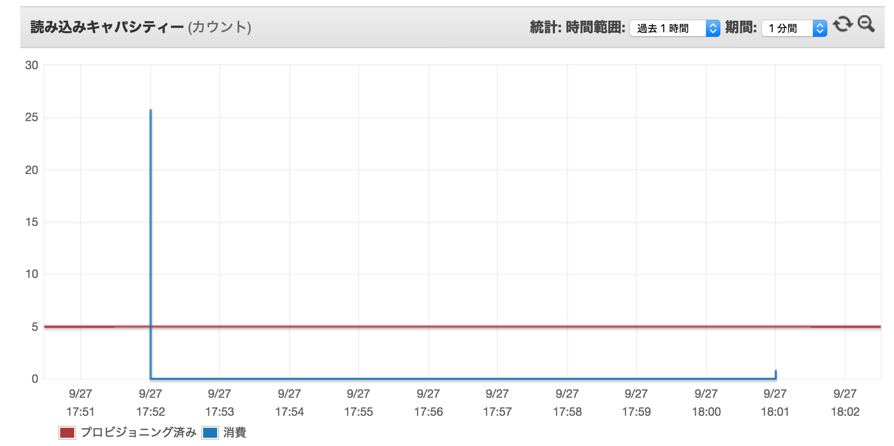
まず、Limit = 1000のパターンを実行すると、途中でキャパオーバーとなりますね。
バーストがあるので正確に見積もれなかったりしますが、RCU = 5だと1秒あたり40項目程度の(結果整合性のある)読み込みしかできないので、当然です。
> run query 1000 100
[info] Running com.example.Main query 1000 100
query items.
************** returned 1000 items. **************
************** returned 1000 items. **************
************** returned 1000 items. **************
************** returned 1000 items. **************
************** returned 1000 items. **************
************** returned 1000 items. **************
************** returned 1000 items. **************
************** returned 1000 items. **************
************** returned 1000 items. **************
************** returned 1000 items. **************
************** returned 1000 items. **************
************** returned 1000 items. **************
[error] (run-main-59) com.amazonaws.services.dynamodbv2.model.ProvisionedThroughputExceededException: The level of configured provisioned throughput for the table was exceeded. Consider increasing your provisioning level with the UpdateTable API (Service: AmazonDynamoDBv2; Status Code: 400; Error Code: ProvisionedThroughputExceededException 〜(省略)〜
at com.amazonaws.http.AmazonHttpClient.handleErrorResponse(AmazonHttpClient.java:1343)
at com.amazonaws.http.AmazonHttpClient.executeOneRequest(AmazonHttpClient.java:961)
at com.amazonaws.http.AmazonHttpClient.executeHelper(AmazonHttpClient.java:738)
at com.amazonaws.http.AmazonHttpClient.doExecute(AmazonHttpClient.java:489)
at com.amazonaws.http.AmazonHttpClient.executeWithTimer(AmazonHttpClient.java:448)
at com.amazonaws.http.AmazonHttpClient.execute(AmazonHttpClient.java:397)
at com.amazonaws.http.AmazonHttpClient.execute(AmazonHttpClient.java:378)
〜〜
次に、Limit = 1に制限してqueryしてみましょう。
> run query 1 100
[info] Running com.example.Main query 1 100
query items.
************** returned 1 items. **************
************** returned 1 items. **************
************** returned 1 items. **************
************** returned 1 items. **************
〜(省略)〜
************** returned 1 items. **************
************** returned 1 items. **************
************** returned 1 items. **************
[success]
キャパオーバーにならずに読み込めました。
AWS Consoleで確認しても、消費キャパシティが抑えられていることが確認できます。(17:52ごろのがパターン1, 18:01ごろのがパターン2です)