はじめに
自分は別にPostgreSQLデベロッパーじゃないけど、PostgreSQL開発版を使って、期待の新しいパーティション機能を試してみましたよ。
この機能はAmit Langoteさんが主に開発した機能らしい。
PostgreSQL 9.6以前のパーティション
PostgreSQL 9.6までもいわゆるパーティション機能はあったが、パーティション専用のDDLが存在していたわけではなかった。
テーブルの継承機能やINSERTトリガを組み合わせて構築するという、いわば「なんちゃってパーティション」である。
もちろん「なんちゃってパーティション」であっても、
- パーティション単位でのパージ(TRUNCATE)
- パーティションキーが存在する場合には検索範囲を限定
というメリットは十分に受けられる。
ただ、問題はいろいろあって・・・。
- 親テーブルに対するINSERTが遅い。これはトリガベースで動作しているから?
- とあるPostgreSQLコミッタがちょろっと検証した結果(PostgreSQL Advent Calendar 2016)、10倍くらい高速化されるっぽい?
- 定義が面倒くさい!ていうか直感的じゃない。
- 親テーブルを作成する。
- 親テーブルの情報を継承した子テーブルと、子テーブルの特定のための制約を付与する。
- INSERTトリガ用の関数を作成する。
- 親テーブルにINSERTトリガを設定する。
といった問題がありましたよと。
PostgreSQL 10 パーティション
現在開発中のPostgreSQL 10には、これまでの方式と全く異なったパーティション方式が追加された。
新しいパーティション方式は何が違うのかというと、
- CREATE TABLE文にパーティション専用の構文が追加された。
- INSERTトリガが要らなくなった!
- 個々の子テーブルにCHECK制約を設定しなくても良くなった。
- 制約の矛盾のチェックもやってくれるのかな?
と、なかなかいい感じ。
早速試してみよう。(数日前の版だけど)PostgreSQLのHEADをビルドした環境でパーティションを組んでみる。
レンジパーティションの例は某コミッタのPostgreSQL10でテーブルパーティションへのINSERT性能が大幅Upする件で紹介済みなので、今回はリストパーティションを試してみることにする。
作ってみよう
こんな感じの多段リストパーティションを組んでみる。
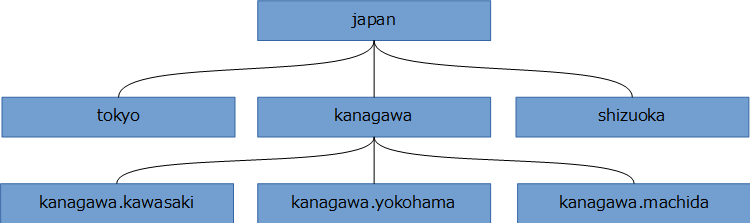
まず、大本のjapanテーブルを定義する。
CREATE TABLE japan (
pref text,
city text,
data text
)
PARTITION BY LIST (pref);
PARTITINO BY LIST という構文でパーティションキー(pref)を指定する。
そして、japanの子となるパーティションテーブル、tokyo, kanagawa, shizuokaを定義する。
CREATE TABLE tokyo PARTITION OF japan
FOR VALUES IN ('東京');
CREATE TABLE kanagawa PARTITION OF japan
FOR VALUES IN ('神奈川')
PARTITION BY LIST (city);
CREATE TABLE shizuoka PARTITION OF japan
FOR VALUES IN ('静岡');
FOR VALUES INでパーティションキーの値を指定する。IN構文を使っているので、単一値だけではなく複数の値も指定可能っぽい(試してないけど)。
そしてkanagawaテーブルの定義に着目。そう、パーティションの子側のテーブル自体にもPARTITION構文が使える。つまり、多段パーティションの定義が可能になっている!
kanagawaテーブルの子テーブルとして、kanagawa.yokohama, kanagawa.kawasaki, kanagawa.machida も定義しましょう。
CREATE TABLE "kanagawa.yokohama" PARTITION OF kanagawa
FOR VALUES IN ('横浜');
CREATE TABLE "kanagawa.kawasaki" PARTITION OF kanagawa
FOR VALUES IN ('川崎');
CREATE TABLE "kanagawa.machida" PARTITION OF kanagawa
FOR VALUES IN ('町田');
念のため。町田は神奈川ですから!
データ挿入
テーブル定義ができたのでデータを挿入しよう。
INSERT INTO japan VALUES ('神奈川','横浜','麺恋亭');
INSERT INTO japan VALUES ('神奈川','横浜','吉村家');
INSERT INTO japan VALUES ('神奈川','川崎','クマさん');
INSERT INTO japan VALUES ('神奈川','川崎','ニュータンタン本舗 本店');
INSERT INTO japan VALUES ('神奈川','町田','竹の助');
INSERT INTO japan VALUES ('静岡','熱海','雨風本舗');
INSERT INTO japan VALUES ('静岡','藤枝','池田屋');
INSERT INTO japan VALUES ('東京','品川','丸直');
INSERT INTO japan VALUES ('東京','八丈島','蓮華');
prefのフィールドに、'神奈川', '静岡'. '東京'以外が指定したらどうなるかというと、きちんとエラーにしてくれる。else的な挙動は許さない。慈悲はない。
part=# INSERT INTO japan VALUES ('埼玉','川越','頑者');
ERROR: no partition of relation "japan" found for row
DETAIL: Failing row contains (埼玉, 川越, 頑者).
検索してみよう
全件検索
この状態で親テーブルjapanを検索してみる。
part=# TABLE japan;
pref | city | data
--------+--------+-------------------------
東京 | 品川 | 丸直
東京 | 八丈島 | 蓮華
静岡 | 熱海 | 雨風本舗
静岡 | 藤枝 | 池田屋
神奈川 | 横浜 | 麺恋亭
神奈川 | 横浜 | 吉村家
神奈川 | 川崎 | クマさん
神奈川 | 川崎 | ニュータンタン本舗 本店
神奈川 | 町田 | 竹の助
(9 rows)
きちんと各パーティションをマージした結果が返却される。
EXPLAINをとってみると
part=# EXPLAIN TABLE japan;
QUERY PLAN
-----------------------------------------------------------------------------
Append (cost=0.00..82.50 rows=3252 width=96)
-> Seq Scan on japan (cost=0.00..0.00 rows=1 width=96)
-> Seq Scan on tokyo (cost=0.00..16.50 rows=650 width=96)
-> Seq Scan on kanagawa (cost=0.00..0.00 rows=1 width=96)
-> Seq Scan on shizuoka (cost=0.00..16.50 rows=650 width=96)
-> Seq Scan on "kanagawa.yokohama" (cost=0.00..16.50 rows=650 width=96)
-> Seq Scan on "kanagawa.kawasaki" (cost=0.00..16.50 rows=650 width=96)
-> Seq Scan on "kanagawa.machida" (cost=0.00..16.50 rows=650 width=96)
(8 rows)
当たり前だけど、全てのパーティションを検索してAppendしている。
パーティションキーを付与する
WHERE句にパーティションキーを付与して検索してみる。
part=# SELECT * FROM japan WHERE pref = '神奈川';
pref | city | data
--------+------+-------------------------
神奈川 | 横浜 | 麺恋亭
神奈川 | 横浜 | 吉村家
神奈川 | 川崎 | クマさん
神奈川 | 川崎 | ニュータンタン本舗 本店
神奈川 | 町田 | 竹の助
(5 rows)
このときのEXPLAIN結果を見ると
part=# EXPLAIN SELECT * FROM japan WHERE pref = '神奈川';
QUERY PLAN
---------------------------------------------------------------------------
Append (cost=0.00..54.38 rows=11 width=96)
-> Seq Scan on japan (cost=0.00..0.00 rows=1 width=96)
Filter: (pref = '神奈川'::text)
-> Seq Scan on kanagawa (cost=0.00..0.00 rows=1 width=96)
Filter: (pref = '神奈川'::text)
-> Seq Scan on "kanagawa.yokohama" (cost=0.00..18.12 rows=3 width=96)
Filter: (pref = '神奈川'::text)
-> Seq Scan on "kanagawa.kawasaki" (cost=0.00..18.12 rows=3 width=96)
Filter: (pref = '神奈川'::text)
-> Seq Scan on "kanagawa.machida" (cost=0.00..18.12 rows=3 width=96)
Filter: (pref = '神奈川'::text)
(11 rows)
きちんと神奈川に属するパーティションだけプルーニングしているのが分かる。
検索条件にprefとcityを付与する。
part=# SELECT * FROM japan WHERE pref = '神奈川' AND city = '横浜';
pref | city | data
--------+------+--------
神奈川 | 横浜 | 麺恋亭
神奈川 | 横浜 | 吉村家
(2 rows)
part=# EXPLAIN SELECT * FROM japan WHERE pref = '神奈川' AND city = '横浜';
QUERY PLAN
---------------------------------------------------------------------------
Append (cost=0.00..19.75 rows=3 width=96)
-> Seq Scan on japan (cost=0.00..0.00 rows=1 width=96)
Filter: ((pref = '神奈川'::text) AND (city = '横浜'::text))
-> Seq Scan on kanagawa (cost=0.00..0.00 rows=1 width=96)
Filter: ((pref = '神奈川'::text) AND (city = '横浜'::text))
-> Seq Scan on "kanagawa.yokohama" (cost=0.00..19.75 rows=1 width=96)
Filter: ((pref = '神奈川'::text) AND (city = '横浜'::text))
(7 rows)
kanagawaパーティションに属するkanagawa.yokohamaパーティションのみをプルーニングしているのが確認できる。すげえぜ!
いろいろ試してみる
パーティションに対する操作、いろいろ気になるので試してみた。
親テーブルに対するTRUNCATE
親テーブルに対するTRUNCATEはパーティションテーブルに伝播する。すばらしい。
pref | city | data
--------+--------+-------------------------
東京 | 品川 | 丸直
東京 | 八丈島 | 蓮華
静岡 | 熱海 | 雨風本舗
静岡 | 藤枝 | 池田屋
神奈川 | 横浜 | 麺恋亭
神奈川 | 横浜 | 吉村家
神奈川 | 川崎 | クマさん
神奈川 | 川崎 | ニュータンタン本舗 本店
神奈川 | 町田 | 竹の助
(9 rows)
part=# TRUNCATE japan;
TRUNCATE TABLE
part=# TABLE japan ;
pref | city | data
------+------+------
(0 rows)
親テーブルに対するCOPY FROM
親テーブルに対するCOPY FROMによるバルクロードも可能のようだ。
part=# COPY japan FROM '/tmp/japan.txt';
COPY 9
part=# TABLE japan ;
pref | city | data
--------+--------+-------------------------
東京 | 品川 | 丸直
東京 | 八丈島 | 蓮華
静岡 | 熱海 | 雨風本舗
静岡 | 藤枝 | 池田屋
神奈川 | 横浜 | 麺恋亭
神奈川 | 横浜 | 吉村家
神奈川 | 川崎 | クマさん
神奈川 | 川崎 | ニュータンタン本舗 本店
神奈川 | 町田 | 竹の助
(9 rows)
ただ、子テーブルにCOPYそのものが伝播しているのかは不明。たぶん、内部的にはINSERTになっている気がする。これは件数を増やしてCOPY時間を測定予定。
予想が正しければ、バルクロードを最適に行うためにはCOPY用テーブルを子テーブル別に分割して個々にCOPYする必要がありそうだ。
(pg_bulkloadに関してもPostgreSQL 10対応版が出たら試してみなくては)
親テーブルに対するDROP TABLE
親テーブルに対してDROP TABLE ... を単に実行した場合、依存するテーブルがあるから削除できないというエラーになる。
part=# DROP TABLE japan;
ERROR: cannot drop table japan because other objects depend on it
DETAIL: table tokyo depends on table japan
table kanagawa depends on table japan
table "kanagawa.yokohama" depends on table kanagawa
table "kanagawa.kawasaki" depends on table kanagawa
table "kanagawa.machida" depends on table kanagawa
table shizuoka depends on table japan
HINT: Use DROP ... CASCADE to drop the dependent objects too.
親テーブルに対してDROP TABLE ... CASCADEを実施すると、きちんと子テーブルもまとめて削除してくれる。
part=# DROP TABLE japan CASCADE;
NOTICE: drop cascades to 6 other objects
DETAIL: drop cascades to table tokyo
drop cascades to table kanagawa
drop cascades to table "kanagawa.yokohama"
drop cascades to table "kanagawa.kawasaki"
drop cascades to table "kanagawa.machida"
drop cascades to table shizuoka
DROP TABLE
この辺はpg_dependによる依存性管理を巧く使っているのだろうなあ。
とりあえず、TRUNCATEもCOPYもDROPもどれも問題なく実行できた。なかなかいい感じ。
VACUUM、CLUSTER、ANALYZE、REINDEXなどは件数を増やしてから試してみる予定。
パーティション間の移動
さて、世の中には 「町田は東京都である」という妄想 を抱いている人たちが多いのか、町田が神奈川に属していると「ちげーよ」と指摘する人もいる。
part=# SELECT * FROM japan ;
pref | city | data
--------+--------+-------------------------
東京 | 品川 | 丸直
東京 | 八丈島 | 蓮華
静岡 | 熱海 | 雨風本舗
静岡 | 藤枝 | 池田屋
神奈川 | 横浜 | 麺恋亭
神奈川 | 横浜 | 吉村家
神奈川 | 川崎 | クマさん
神奈川 | 川崎 | ニュータンタン本舗 本店
神奈川 | 町田 | 竹の助
(9 rows)
子テーブル(tokyo, kanagawa)別に見るとこんな感じで格納されている。
part=# SELECT * FROM tokyo ;
pref | city | data
------+--------+------
東京 | 品川 | 丸直
東京 | 八丈島 | 蓮華
(2 rows)
part=# SELECT * FROM kanagawa ;
pref | city | data
--------+------+-------------------------
神奈川 | 横浜 | 麺恋亭
神奈川 | 横浜 | 吉村家
神奈川 | 川崎 | クマさん
神奈川 | 川崎 | ニュータンタン本舗 本店
神奈川 | 町田 | 竹の助
(5 rows)
仕方がないので、町田を神奈川から東京に移動することにする。
part=# UPDATE japan SET pref = '東京' WHERE city = '町田';
ERROR: new row for relation "kanagawa.machida" violates partition constraint
DETAIL: Failing row contains (東京, 町田, 竹の助).
残念!パーティションキーを変更するようなUPDATEはやっぱりできません!
まあ、素直にDELETEしてINSERTするしかなさそう。
ただ、PostgreSQLのDMLにはRETURNING句が使えるので、WITH句を組み合わせて、以下のようなSQL文を書けばUPDATEの代替は可能っぽい。
part=# SELECT * FROM japan WHERE city = '町田';
pref | city | data
--------+------+--------
神奈川 | 町田 | 竹の助
(1 row)
part=# WITH tmp AS
(DELETE FROM japan WHERE city = '町田' RETURNING '東京', city, data)
INSERT INTO japan SELECT * FROM tmp;
INSERT 0 1
part=# SELECT * FROM japan WHERE city = '町田';
pref | city | data
------+------+--------
東京 | 町田 | 竹の助
(1 row)
きちんとtokyoパーティションに移動しているのかも確認してみる。
part=# SELECT * FROM tokyo ;
pref | city | data
------+--------+--------
東京 | 品川 | 丸直
東京 | 八丈島 | 蓮華
東京 | 町田 | 竹の助
(3 rows)
part=# SELECT * FROM kanagawa ;
pref | city | data
--------+------+-------------------------
神奈川 | 横浜 | 麺恋亭
神奈川 | 横浜 | 吉村家
神奈川 | 川崎 | クマさん
神奈川 | 川崎 | ニュータンタン本舗 本店
(4 rows)
町田は東京に奪われました・・・ぐぬぬ・・・。
今後の検証予定
- FDW(postgres_fdw)との併用
- パーティションのメンテナンス
- いろんな異常ケースの挙動