はじめに
例によって役に立つかどうかは分からないけど、JSONBに対する検索で何が性能に影響を与えるのか、気になったので調べてみた。
JSONBの検索に影響を与えそうなもの
単純に考えると以下の3つ。
- 階層数
- 同一階層のキー/値の組の数
- 配列要素数
とりあえず、どれが一番影響しそうかを調べてみた。
測定パターン
測定環境は手持ちのノートPC上のVM。
なので数値の絶対値にそれほど意味はない。
階層数の測定
検索対象のデータ
以下のようなJSONデータを100万件挿入する。
{"key00":{"key00":{"key00":{"key00":{"key00":{"key00":{"key00":{"key00":{"key00":{"key00":{"key00":{"key00":{"key00":{"key00":{"key00":{"key00":{"key00":{"key00":{"key00":{"key00":"dummy", "key01":"dummy","key02":"dummy","key03":"dummy","key04":"dummy","key05":"dummy","key06":"dummy","key07":"dummy","key08":"dummy","key09":"dummy"}, "key01":"dummy","key02":"dummy","key03":"dummy","key04":"dummy","key05":"dummy","key06":"dummy","key07":"dummy","key08":"dummy","key09":"dummy"}, "key01":"dummy","key02":"dummy","key03":"dummy","key04":"dummy","key05":"dummy","key06":"dummy","key07":"dummy","key08":"dummy","key09":"dummy"}, "key01":"dummy","key02":"dummy","key03":"dummy","key04":"dummy","key05":"dummy","key06":"dummy","key07":"dummy","key08":"dummy","key09":"dummy"}, "key01":"dummy","key02":"dummy","key03":"dummy","key04":"dummy","key05":"dummy","key06":"dummy","key07":"dummy","key08":"dummy","key09":"dummy"}, "key01":"dummy","key02":"dummy","key03":"dummy","key04":"dummy","key05":"dummy","key06":"dummy","key07":"dummy","key08":"dummy","key09":"dummy"}, "key01":"dummy","key02":"dummy","key03":"dummy","key04":"dummy","key05":"dummy","key06":"dummy","key07":"dummy","key08":"dummy","key09":"dummy"}, "key01":"dummy","key02":"dummy","key03":"dummy","key04":"dummy","key05":"dummy","key06":"dummy","key07":"dummy","key08":"dummy","key09":"dummy"}, "key01":"dummy","key02":"dummy","key03":"dummy","key04":"dummy","key05":"dummy","key06":"dummy","key07":"dummy","key08":"dummy","key09":"dummy"}, "key01":"dummy","key02":"dummy","key03":"dummy","key04":"dummy","key05":"dummy","key06":"dummy","key07":"dummy","key08":"dummy","key09":"dummy"}, "key01":"dummy","key02":"dummy","key03":"dummy","key04":"dummy","key05":"dummy","key06":"dummy","key07":"dummy","key08":"dummy","key09":"dummy"}, "key01":"dummy","key02":"dummy","key03":"dummy","key04":"dummy","key05":"dummy","key06":"dummy","key07":"dummy","key08":"dummy","key09":"dummy"}, "key01":"dummy","key02":"dummy","key03":"dummy","key04":"dummy","key05":"dummy","key06":"dummy","key07":"dummy","key08":"dummy","key09":"dummy"}, "key01":"dummy","key02":"dummy","key03":"dummy","key04":"dummy","key05":"dummy","key06":"dummy","key07":"dummy","key08":"dummy","key09":"dummy"}, "key01":"dummy","key02":"dummy","key03":"dummy","key04":"dummy","key05":"dummy","key06":"dummy","key07":"dummy","key08":"dummy","key09":"dummy"}, "key01":"dummy","key02":"dummy","key03":"dummy","key04":"dummy","key05":"dummy","key06":"dummy","key07":"dummy","key08":"dummy","key09":"dummy"}, "key01":"dummy","key02":"dummy","key03":"dummy","key04":"dummy","key05":"dummy","key06":"dummy","key07":"dummy","key08":"dummy","key09":"dummy"}, "key01":"dummy","key02":"dummy","key03":"dummy","key04":"dummy","key05":"dummy","key06":"dummy","key07":"dummy","key08":"dummy","key09":"dummy"}, "key01":"dummy","key02":"dummy","key03":"dummy","key04":"dummy","key05":"dummy","key06":"dummy","key07":"dummy","key08":"dummy","key09":"dummy"}, "key01":"dummy","key02":"dummy","key03":"dummy","key04":"dummy","key05":"dummy","key06":"dummy","key07":"dummy","key08":"dummy","key09":"dummy"}
長くてわかりづらいけど、10個の階層を持つJSON文書である。
検索パターン
これに対して、以下のようなクエリをそれぞれ5回ずつ発行して、そのacural timeの平均をとる。
EXPLAIN ANALYZE SELECT data #> '{key01}' FROM test;
EXPLAIN ANALYZE SELECT data #> '{key00,key00,key01}' FROM test;
EXPLAIN ANALYZE SELECT data #> '{key00,key00,key00,key00,key01}' FROM test;
EXPLAIN ANALYZE SELECT data #> '{key00,key00,key00,key00,key00,key00,key00,key00,key00,key01}' FROM test;
EXPLAIN ANALYZE SELECT data #> '{key00,key00,key00,key00,key00,key00,key00,key00,key00,key00,key00,key00,key00,key00,key01}' FROM test;
EXPLAIN ANALYZE SELECT data #> '{key00,key00,key00,key00,key00,key00,key00,key00,key00,key00,key00,key00,key00,key00,key00,key00,key00,key00,key00,key01}' FROM test;
測定結果
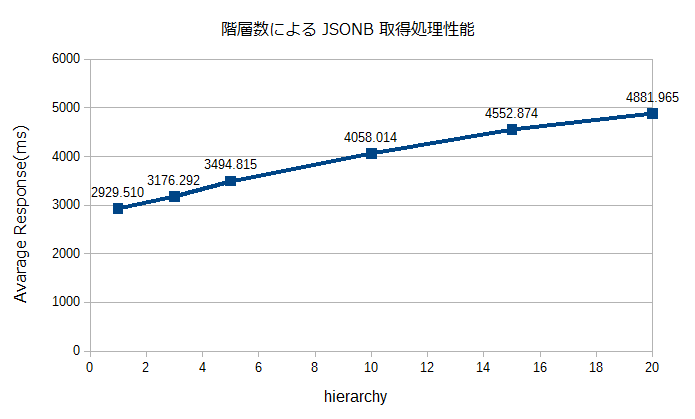
階層数は明らかに検索性能に影響していそうだ。
これが演算子に指定した配列数が主要因なのか、JSONBの内部構造のツリートラバース時間自体が主要因なのかまでは調査できていないが・・・。
まあ、それ以前に「そんな深い階層を持つようなJSON文書なんてつかわねーよ!」という説もあるが。
同一階層の項目数
同一階層に多数の項目数が合った場合、指定したキーによって性能に影響があるのか確認してみる。
検索対象のデータ
以下のようなJSONデータを100万件挿入する。
{ "key00":"val00" ,"key01":"val01" ,"key02":"val02" ,"key03":"val03" ,"key04":"val04" ,"key05":"val05" ,"key06":"val06" ,"key07":"val07" ,"key08":"val08" ,"key09":"val09" ,"key10":"val10" ,"key11":"val11" ,"key12":"val12" ,"key13":"val13" ,"key14":"val14" ,"key15":"val15" ,"key16":"val16" ,"key17":"val17" ,"key18":"val18" ,"key19":"val19" ,"key20":"val20" ,"key21":"val21" ,"key22":"val22" ,"key23":"val23" ,"key24":"val24" ,"key25":"val25" ,"key26":"val26" ,"key27":"val27" ,"key28":"val28" ,"key29":"val29" ,"key30":"val30" ,"key31":"val31" ,"key32":"val32" ,"key33":"val33" ,"key34":"val34" ,"key35":"val35" ,"key36":"val36" ,"key37":"val07" ,"key38":"val38" ,"key39":"val39" ,"key40":"val40" ,"key41":"val41" ,"key42":"val42" ,"key43":"val43" ,"key44":"val44" ,"key45":"val45" ,"key46":"val46" ,"key47":"val47" ,"key48":"val48" ,"key49":"val49" }
長くてわかりづらいけど、1つの階層に50個のキー/値のペアを持つJSON文書である。
検索パターン
これに対して、以下のようなクエリをそれぞれ5回ずつ発行して、そのacural timeの平均をとる。
EXPLAIN ANALYZE SELECT data #> '{key00}' FROM test;
EXPLAIN ANALYZE SELECT data #> '{key10}' FROM test;
EXPLAIN ANALYZE SELECT data #> '{key20}' FROM test;
EXPLAIN ANALYZE SELECT data #> '{key30}' FROM test;
EXPLAIN ANALYZE SELECT data #> '{key49}' FROM test;
測定結果
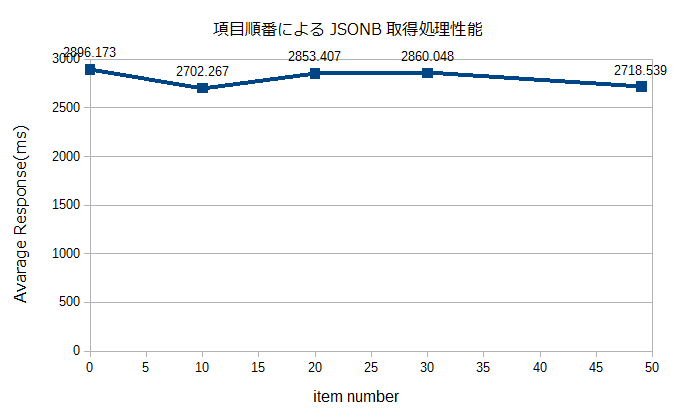
同一階層で50個程度のキー/値のペアがある場合、どのキーを指定しても、性能への影響はなさそうだ。
配列要素番号の指定
配列内に多数の要素があった場合、指定した配列番号によって性能に影響があるのか確認してみる。
検索対象のデータ
以下のようなJSONデータを100万件挿入する。
{ "key":[ "val00", "val01", "val02", "val03", "val04", "val05", "val06", "val07", "val08", "val09", "val10", "val11", "val12", "val13", "val14", "val15", "val16", "val17", "val18", "val19", "val20", "val21", "val22", "val23", "val24", "val25", "val26", "val27", "val28", "val29", "val30", "val31", "val32", "val33", "val34", "val35", "val36", "val37", "val38", "val39", "val40", "val41", "val42", "val43", "val44", "val35", "val46", "val47", "val48", "val49" ]}
長くてわかりづらいけど、1つの配列内に50個の要素を持つJSON文書である。
検索パターン
これに対して、以下のようなクエリをそれぞれ5回ずつ発行して、そのacural timeの平均をとる。
EXPLAIN ANALYZE SELECT data #> '{key, 0}' FROM test;
EXPLAIN ANALYZE SELECT data #> '{key,09}' FROM test;
EXPLAIN ANALYZE SELECT data #> '{key,19}' FROM test;
EXPLAIN ANALYZE SELECT data #> '{key,29}' FROM test;
EXPLAIN ANALYZE SELECT data #> '{key,49}' FROM test;
測定結果
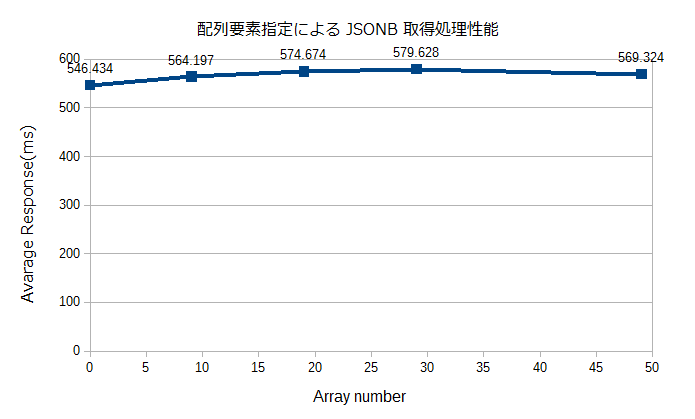
50個程度の配列であれば、どの要素番号を指定しても、性能への影響はなさそうだ。
まとめ
- JSONBの検索に影響を一番与えそうなのは階層の深さ。
- キー/値の組の数や、配列要素数は、それほど影響はなさげ。
おわりに
この測定が役に立つのかどうかは知らないが、自分の想定どおりだったので安心して眠れる。