世の中の大半のことは、うまくいかないことが多いものです。ちょっとしたノイズや外乱でうまくいかなくなってしまうことは多いものです。
1.最小2乗法ではなくRANSACを使おう。
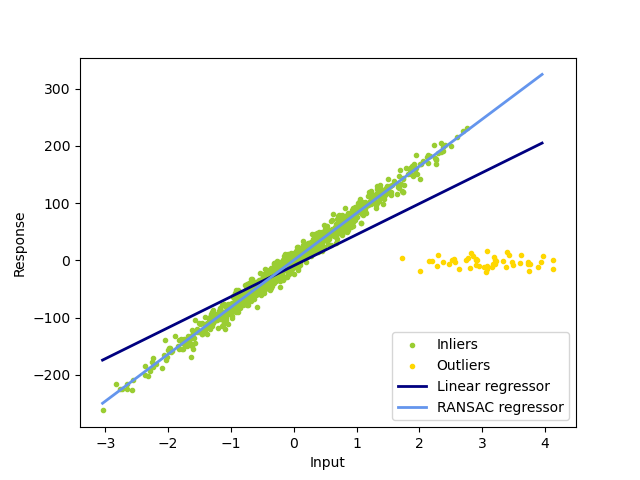
関数のあわせこみは最小2乗法が高校数学にあるように有名ですが、最小2乗法は仕事に耐えうる水準になることは私の経験上のありませんでした。
まずは、最小2乗法はノイズによる外れ値の影響を受けすぎるのです。そのため、入力データ群をプロットしたときに、外れ値と見られるものは、人が意図的に除外して、定規で線を引きなおすようなことがありました。
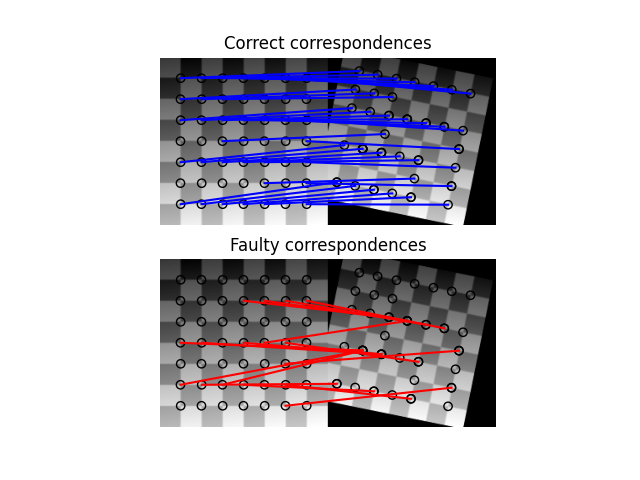
自動化しようとするときには、最小2乗法はまず使えないと思うことです。その代わりに使うべき手法はRANSACです。RANSACは単にフィッティングだけではなく、ステレオ画像での対応点のマッチングとか、他にもさまざまな用途で使われています。
-
Wikipedia RANSAC(Random sample consensus)
-
scikit-learn Robust linear model estimation using RANSAC
-
qiita【お勉強してみた】RANSACのおはなし
-
scikit-image Robust matching using RANSAC
-
keypoint matching; RANSAC とを使っている例 OpenCV panorama stitching

2.機械学習では汎化性能を重視しよう
学習したデータに対してだけは性能がよいが、学習していないデータに対してはうまくいかないということが起こりうる。
汎化性能があるのかどうか常に注意して機械学習の性能のテストをしてください。
自由度が高すぎるモデルよりは、自由度の低いモデルの方がよい結果を返すことがあります。
qiita 機械学習の性能を正しく評価するための検証手法
「そのモデルの精度、高過ぎませんか?」過学習・汎化性能・交差検証のはなし
3.多変量解析でも、説明変数の数を増やすぎないことがよい。
単純化して言えば「説明変数は、相関があるようなパラメータを用いてはいけないということです。」
データの分析をする際に、身長と体重とを説明変数にしてはいけないということです。身長とBMIとならば用いてよい変数になります。
説明変数の数を増やしすぎると、説明変数に相関を含んだ組み合わせを生じてしまいます。
多変量解析でのこのような知見は、機械学習に対するデータの前処理としても有用な知見を含んでいます。
4.制御の場合、外乱に受けにくい制御方式を利用しよう。
制御には、常に外乱が入ってくることが前提だとして物事を考える必要があります。センサのチャタリング(電圧レベルが閾値レベルを切り替わる際にon/offを頻繁に短時間に繰り返す現象)対策もその1つです。
信号線を用いている場合、信号線が断線することも考慮にしなければなりません。
センサの特性がロットごとにばらついている可能性も考慮しなくてはなりません。
アナログ信号の場合、測定対象外のノイズが混入することを考慮しなくてはなりません。
カメラ画像の場合に、最大限にゲインをあげて蓄積時間を増やしているときには、暗電流の性質を考慮しなくてはなりません。
制御を目的としている場合には、制御を失敗に導くさまざまな要因に対して考慮して、制御をうまくいくような方式の選択とパラメータの選択をします。(リモコンがうまくいくのは、そのようなことを設計者が既にしていてくれるからです。)
制御システムに中にあるモデルは、実際の系の値とは異なっていて、大なり小なり誤差をもっています。その誤差が、系の動作に系統的なズレを生じることがあります。
引用 「制御対象とモデルの間の誤差は制御系設計に重大な問題をもたらす.前節の例ではむだ時間要素を無視することが誤差の原因となっていたが,他にもさまざまな原因により制御対象とモデルの間に誤差が生じる.このような誤差は「モデルの不確かさ」あるいは「モデル化誤差」とよばれる.」 「ロバスト制御系設計入門」
・モデル集合に含まれるすべての伝達関数に対して閉ループ系を安定(ロバスト安定)にし,なおかつ,可能な限り高い性能を達成すること
・特にフィードバック補償器には,外乱の影響を取り除いたり,モデル化誤差の影響を小さくすることことが要求される
このような仕組みを取り入れることで、ロバストな制御が実現できる。
フィードバックなしに、制御を安定化することはできません。
ほかにも、電気回路で安定な増幅器を実現するオペアンプの反転増幅回路が一定の増幅率が実現できる、フィードバックが含まれていることによっています。
オペアンプ回路の基本設計法
5.ノイズや外乱の影響を受けにくいシステム設計をしよう。
○○という方式が常にうまくいくなんて信用しないことにしよう。「○○という方式は△△というときにはうまくいかなくなる限界をもっていることは百も承知なんです。ですから、○○という方式が100%うまくいく前提でシステムを設計しないことです。でも、□□な範囲では、▽▽なことは確かだから、□□な使い方をすれば、問題は避けられるんです。」 そのように、その問題に対して詳しい人は言ったりする内容に注意を払ってください。
「□□な範囲では、▽▽なことは確か」な範囲で十分に目的を遂げられるように上位側の設計をすることです。
ものごとには、外乱が避けられません。そのときにでもうまくいくやり方をしていきいましょう。
この記事の目的は、ロバストなアプローチをすることの必要性を述べるもので、個々の分野でどのようなアプローチをすればよいのかについては、別途、調査してください。
追記 (2019.6.11)
平均値を使わない。中央値を使う。
低い方の値には限界があるのに、高い方の分布には限界がないような統計量の場合、平均値が少数の値が高いデータによって引きずられることがあります。
その集団の特性を示すデータしては、平均値よりも中央値を使った方がいい場合があります。
所得の分布や金融資産の分布などは、そのような例でしょう。これらの統計データでは、平均値は中央値よりも高くでる傾向があります。
最大値・最小値を使わない。5パーセンタイル値や、95パーセンタイル値を使う。
最大値も最小値もロバスト性に欠ける指標です。それよりは5パーセンタイル値や、95パーセンタイル値を使う方が、外れ値の影響を受けにくくなります。
全てを機械学習にまかせない。先見的な知識があればそれも活用しよう
機械学習、深層学習が万能のように語られる日々であるが、機械学習や深層学習が従来の先験的な知識が無意味になったわけではない。
経験によって十分確かめられているルールがあるときには、それを安全確認に利用するという方法がある。
機械学習・深層学習は、学習データ依存である。そのために、学習データが少ない領域では、学習の精度が低下しがちだ。(例:黒ヒツジをヒツジと判定させるのは難しい。ヒツジの学習データの中に黒ヒツジのデータはまず含まれていない。数例の黒ヒツジ画像を加えたからといって黒ヒツジをヒツジと学習させることは簡単にはいかない。例 機械学習を用いるシステムでも、経験的な手法で精度と処理速度が得られる領域は、その従来からの手法を使ってもよいはずだ。
従来の手法では、どうしようない手付かずの領域で、今よりはマシな判断をできれば、機械学習・深層学習が価値を持つだろう。