方針
オンライン学習プラットフォームCourseraで一番人気の講座、Stanford大学のMachine Learning。講師はAndrew Ng先生。授業はレクチャーとプログラミング課題からなるが、プログラミング課題に使用する言語はOctaveまたはMatlabが指定されている。
このプログラミング課題をPythonを使って粛々と実装していく。ただし、
- オリジナルの課題はアルゴリズムの理解を助けることを目的としているため、一部の処理は機械学習のライブラリを使用せずに自らコードを書くように設計されている。これをそのままPythonで再現するのではなく、できる限りPythonにある機械学習ライブラリを使って効率よく実装したい。
という方針。
さっそくex1
最初の課題となるex1では線形回帰(Linear Regression)をやります。レストランチェーン経営において、過去に出店した街の人口とレストランの利益額が対になったデータセットをもとに、新たに出店する場合の利益額を予想するというものです。
さっそくコードはこちら。
ex1.py
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import linear_model
# データ読み込み
data = pd.read_csv("ex1data1.txt", header=None)
plt.scatter(data[0], data[1], marker='x', c='r')
plt.xlabel("Population of city in 10,000s")
plt.ylabel("Profit in $10,000s")
X = np.array([data[0]]).T
y = np.array(data[1])
model = linear_model.LinearRegression()
model.fit(X, y)
px = np.arange(X.min(),X.max(),.01)[:,np.newaxis]
py = model.predict(px)
plt.plot(px, py, color="blue", linewidth=3)
plt.show()
結果のプロットはこのように出力されます。
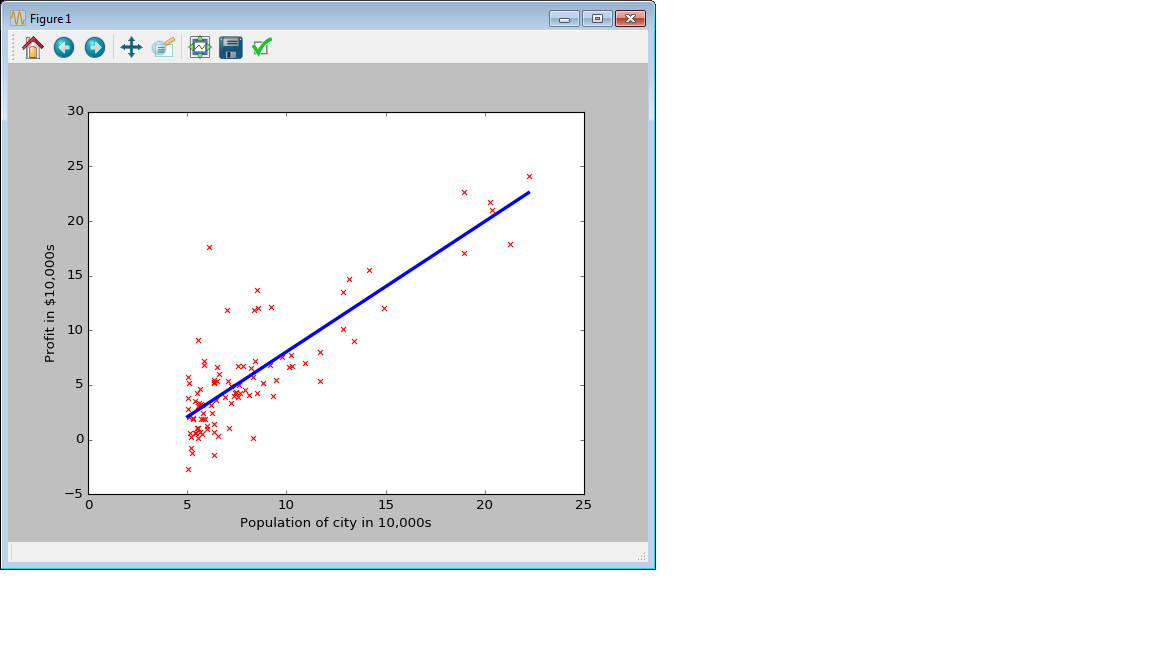
今回のポイント
線形回帰モデルは、scikit-learn のsklearn.linear_model.LinearRegression()クラスを使用する。まずインスタンスを作成し、model.fit(X,y)で学習を実施。学習結果である切片と傾きはそれぞれmodel.intercept_とmodel.coef_のように取り出せる。モデルを使って新しいXの値に対して予測をするにはmodel.predict(X)とする。
numpyの1次元ベクトルについて
Matlab/Octaveと違い、Pythonでは1次元の縦ベクトルと横ベクトルが区別されない。明示的に縦ベクトルを作成するには、
np.array([[1,2,3,4,5]]).T
とするか、
np.array([1,2,3,4,5])[:,np.newaxis)]
とする。--> 参考記事