2015/11/04にdocker 1.9がリリースされた。
libnetworkのコンセプトはそのままだが、コマンド体系は前回の検証時点からかなり変更されている。そこで再度検証を行った。
検証環境の準備
今回もSoftLayerのVMを用いて検証環境を構築する。
| DC | hostname | private IP address (eth0) | private network address | |
|---|---|---|---|---|
| ホスト1 | Dallas9 | docker01 | 10.154.25.169 | 10.154.25.128/26 |
| ホスト2 | Dallas9 | docker02 | 10.154.25.171 | 10.154.25.128/26 |
| ホスト3 | Dallas6 | docker03 | 10.106.39.197 | 10.106.39.192/26 |
| version | |
|---|---|
| distribution | Ubuntu 14.04.3 LTS |
| kernel | 3.19.0-33-generic |
| consul | 0.5.2 |
| docker | 1.9.0, build 76d6bc9 |
カーネルアップデート
前回同様、overlay networkはkernel3.16以上が必要となるため、カーネルアップデートを行う。
root@docker01:~# apt-get install linux-generic-lts-vivid -y
root@docker01:~# reboot
パッケージインストール
前回同様、全てのホストで必要なパッケージをインストールする。
root@docker01:~# apt-get update
root@docker01:~# apt-get upgrade -y
root@docker01:~# apt-get install curl unzip git build-essential bridge-utils -y
consulのインストール
Dockerが公開しているマルチホストネットワーキングのGetting Stargedでは、consul専用のコンテナを一つ起動して全てのdocker-engineはそのコンテナを参照する形になっている。
しかしその手順は踏襲せず、前回同様全てのホストに最新版のconsulをインストールすることにする。
root@docker01:~# curl -OL https://releases.hashicorp.com/consul/0.5.2/consul_0.5.2_linux_amd64.zip
root@docker01:~# unzip consul_0.5.2_linux_amd64.zip
root@docker01:~# mv consul /usr/local/bin/
dockerのインストール
Docker公式のubuntuへのインストール手順に従い、aptからDockerをインストールする。
root@docker01:~# apt-key adv --keyserver hkp://p80.pool.sks-keyservers.net:80 --recv-keys 58118E89F3A912897C070ADBF76221572C52609D
root@docker01:~# echo 'deb https://apt.dockerproject.org/repo ubuntu-trusty main' >> /etc/apt/sources.list.d/docker.list
root@docker01:~# apt-get update
root@docker01:~# apt-get install linux-image-extra-$(uname -r)
root@docker01:~# apt-get install docker-engine -y
検証
ここまでで環境が準備できたので、正式版のdocker overlay networkの検証を行う。
consulクラスタの起動
前回同様、ホスト1を起点としてconsulクラスタを構成する。
root@docker01:~# rm -rf /tmp/consul
root@docker01:~# nohup consul agent -server -bootstrap-expect 3 -data-dir=/tmp/consul -node=docker01 -bind=10.154.25.169 &
root@docker02:~# rm -rf /tmp/consul
root@docker02:~# nohup consul agent -server -data-dir=/tmp/consul -node=docker02 -bind=10.154.25.171 &
root@docker02:~# consul join 10.154.25.169
root@docker03:~# rm -rf /tmp/consul
root@docker03:~# nohup consul agent -server -data-dir=/tmp/consul -node=docker03 -bind=10.106.39.197 &
root@docker03:~# consul join 10.154.25.169
docker daemonにKVSの位置を指定
前回同様、docker daemonの起動オプションにconsulクラスタのエンドポイントを指定する。ただし既に起動している他のdocker engineのIPアドレスを明示的に指定する必要が無くなったため、オプションの設定が容易になった。
今回はaptからdockerをインストールしたため、/etc/default/dockerに必要な起動オプションを設定してdockerを再起動すれば良い。
root@docker01:~# echo 'DOCKER_OPTS="--cluster-store=consul://localhost:8500 --cluster-advertise=eth0:2376"' >> /etc/default/docker
root@docker01:~# service docker restart
マルチホストネットワークの作成
前回同様、明示的にoverlay driverを指定してoverlay networkを作成する。
root@docker01:~# docker network create --driver=overlay vnet
何のオプションも指定しなければ、overlay networkは10.0.0.0/24というサブネットアドレスで作成される。
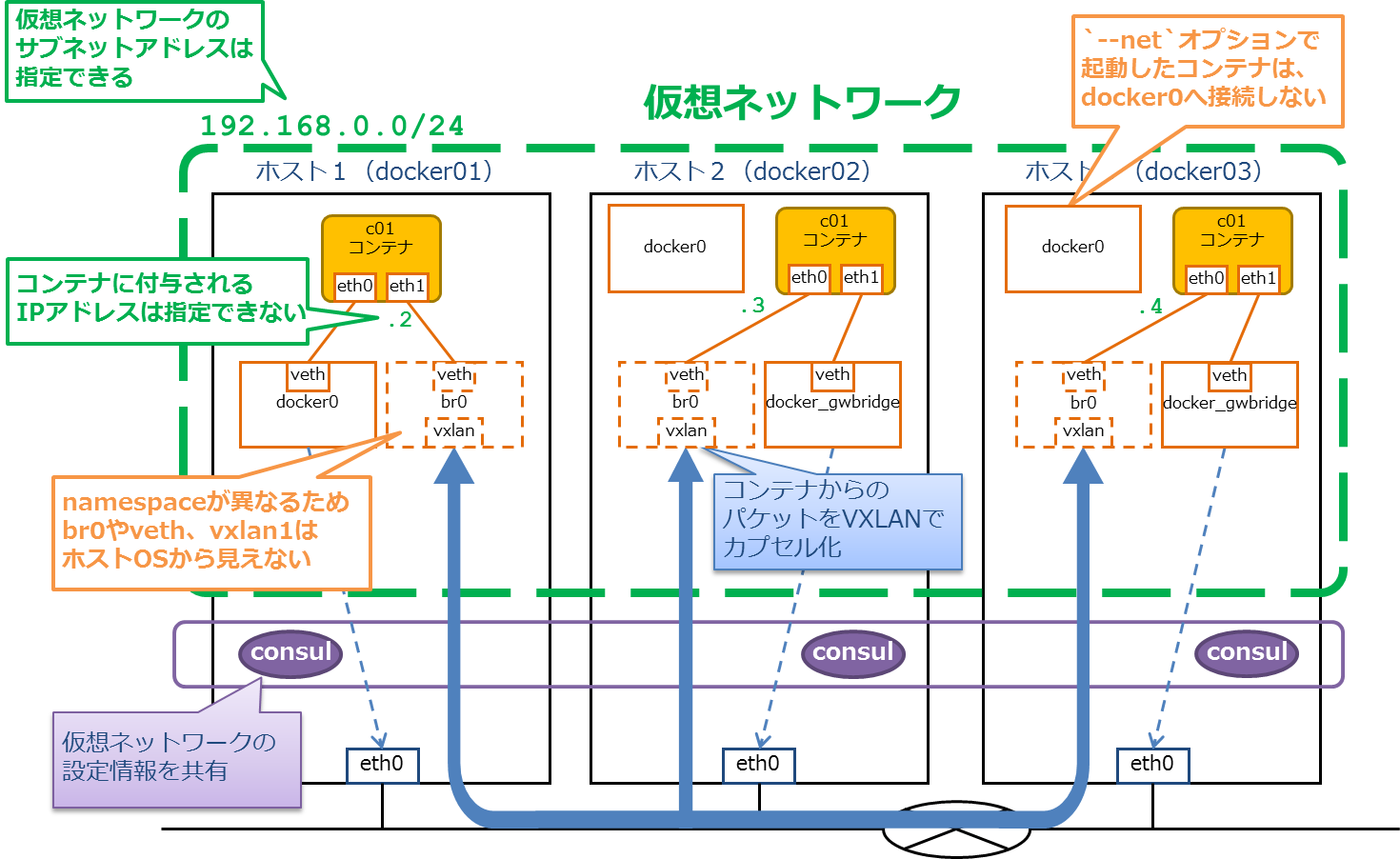
一方正式版では、明示的にサブネットアドレスを指定することもできるようになっている。今回は192.168.0.0/24というサブネットアドレスでoverlay networkを作成して検証を進める。
root@docker01:~# docker network create --driver=overlay --subnet=192.168.0.0/24 vnet
90ce4304fc8ab0e2852c75afc3c996ed30e4beec727ef552d22214bb2366e6ae
consulクラスタが適切に動作しており、かつdocker daemon起動時にadvertiseが届いていれば、全てのdocker engineでネットワークの情報が共有されているはず。
root@docker01:~# docker network ls
NETWORK ID NAME DRIVER
90ce4304fc8a vnet overlay
116ff595e265 bridge bridge
263f8fb74651 none null
73128d81e70d host host
root@docker02:~# docker network ls
NETWORK ID NAME DRIVER
90ce4304fc8a vnet overlay
686f8e0ebb70 bridge bridge
0a2fd807bf27 none null
e3b5a4f78425 host host
root@docker03:~# docker network ls
NETWORK ID NAME DRIVER
90ce4304fc8a vnet overlay
90d0b511aa8d bridge bridge
9a4101fa61af none null
797fbf638039 host host
vnetと名付けたoverlay networkのIDが、全て90ce4304fc8aとなっていることに着目してほしい。
コンテナ起動後に作成したネットワークへ接続
前回検証した時点では、docker service publishというコマンドでnetworkにserviceを作成し、コンテナへattachするようなコマンド体系になっていた。
しかし正式版ではこのコマンド体系は大きく変更されており、docker runしたコンテナをdocker network connectで作成済みのnetworkに接続するような形式になっている。
1.通常どおりの手順でコンテナ起動
まずは通常通りの手順でコンテナを起動する。
root@docker01:~# docker run -itd --name=c01 --hostname=c01 ubuntu:14.04
root@docker01:~# docker exec c01 ip addr show eth0
5: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.2/16 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::42:acff:fe11:2/64 scope link
valid_lft forever preferred_lft forever
この段階では、これまで通り仮想ブリッジに接続されたeth0のみが作成される。
2.ネットワークに接続
次に作成したoverlay network名とコンテナ名を指定して、コンテナをネットワークに接続する。
root@docker01:~# docker network connect vnet c01
root@docker01:~# docker exec c01 ip addr show eth1
8: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP group default
link/ether 02:42:c0:a8:00:02 brd ff:ff:ff:ff:ff:ff
inet 192.168.0.2/24 scope global eth1
valid_lft forever preferred_lft forever
inet6 fe80::42:c0ff:fea8:2/64 scope link
valid_lft forever preferred_lft forever
この段階で、overlay networkに設定したサブネット内のIPアドレスが付与されたeth1がコンテナに差し込まれる。
(採番されるIPアドレスは、docker0の場合と同様に単なる昇順のようだ)
作成したネットワークへ接続したコンテナを起動
今度は--netオプションを用いて、ネットワークに接続した状態でコンテナを起動する。前回検証した時点よりも、オプションがシンプルになっている。
root@docker02:~# docker run -itd --name=c02 --hostname=c02 --net=vnet ubuntu:14.04
コンテナは、overlay networkに接続したeth0と、仮想ブリッジに接続したeth1が作成された状態で起動する。通常の手順で起動してからネットワークに接続した場合とは、NICの順序が逆転していることに注意。
root@docker02:~# docker exec c02 ip addr show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
6: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP group default
link/ether 02:42:c0:a8:00:03 brd ff:ff:ff:ff:ff:ff
inet 192.168.0.3/24 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::42:c0ff:fea8:3/64 scope link
valid_lft forever preferred_lft forever
9: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:12:00:02 brd ff:ff:ff:ff:ff:ff
inet 172.18.0.2/16 scope global eth1
valid_lft forever preferred_lft forever
inet6 fe80::42:acff:fe12:2/64 scope link
valid_lft forever preferred_lft forever
root@docker03:~# docker run -itd --name=c03 --hostname=c03 --net=vnet ubuntu:14.04
コンテナc03のeth0には192.168.0.4/24が付与された。
名前解決
dockerのoverlay networkは親切で、新しいコンテナが接続してくるたびに、同じoverlay networkに接続している全てのコンテナの/etc/hostsを書き換え、適切な名前解決を行ってくれる。
root@docker01:~# docker exec c01 cat /etc/hosts
172.17.0.2 c01
127.0.0.1 localhost
::1 localhost ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
192.168.0.3 c02
192.168.0.3 c02.vnet
192.168.0.4 c03
192.168.0.4 c03.vnet
root@docker02:~# docker exec c02 cat /etc/hosts
192.168.0.3 c02
127.0.0.1 localhost
::1 localhost ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
192.168.0.2 c01.vnet
192.168.0.2 c01
192.168.0.4 c03
192.168.0.4 c03.vnet
なお立ち上げたコンテナをdocker stopすると、同一のoverlay networkに所属する各コンテナの/etc/hostsから、該当するエントリを自動で削除してくれる。非常に便利っ!!
疎通確認
ここまでで、各ホストに立ち上げたコンテナがoverlay networkに接続された。では疎通確認をしてみよう。
コンテナのルーティング
各コンテナのdefault gatewayはホストの仮想ブリッジに接続されているNICに向けられている。
root@docker01:~# docker exec c01 ip route show
default via 172.17.0.1 dev eth0
172.17.0.0/16 dev eth0 proto kernel scope link src 172.17.0.2
192.168.0.0/24 dev eth1 proto kernel scope link src 192.168.0.2
root@docker02:~# docker exec c02 ip route show
default via 172.18.0.1 dev eth1
172.18.0.0/16 dev eth1 proto kernel scope link src 172.18.0.2
192.168.0.0/24 dev eth0 proto kernel scope link src 192.168.0.3
コンテナ間の通信
overlay network用のNIC経由で、他のホスト上のコンテナと通信することができる。
root@c01:/# ping -c2 192.168.0.3
PING 192.168.0.3 (192.168.0.3) 56(84) bytes of data.
64 bytes from 192.168.0.3: icmp_seq=1 ttl=64 time=0.332 ms
64 bytes from 192.168.0.3: icmp_seq=2 ttl=64 time=0.156 ms
root@c01:/# ping -c2 c02
PING c02 (192.168.0.3) 56(84) bytes of data.
64 bytes from c02 (192.168.0.3): icmp_seq=1 ttl=64 time=0.321 ms
64 bytes from c02 (192.168.0.3): icmp_seq=2 ttl=64 time=0.160 ms
root@c01:/# ping -c2 c02.vnet
PING c02.vnet (192.168.0.3) 56(84) bytes of data.
64 bytes from c02 (192.168.0.3): icmp_seq=1 ttl=64 time=0.330 ms
64 bytes from c02 (192.168.0.3): icmp_seq=2 ttl=64 time=0.168 ms
root@c01:/# ping -c2 192.168.0.4
PING 192.168.0.4 (192.168.0.4) 56(84) bytes of data.
64 bytes from 192.168.0.4: icmp_seq=1 ttl=64 time=4.05 ms
64 bytes from 192.168.0.4: icmp_seq=2 ttl=64 time=1.23 ms
root@c01:/# ping -c2 c03
PING c03 (192.168.0.4) 56(84) bytes of data.
64 bytes from c03 (192.168.0.4): icmp_seq=1 ttl=64 time=1.35 ms
64 bytes from c03 (192.168.0.4): icmp_seq=2 ttl=64 time=1.25 ms
root@c01:/# ping -c2 c03.vnet
PING c03.vnet (192.168.0.4) 56(84) bytes of data.
64 bytes from c03 (192.168.0.4): icmp_seq=1 ttl=64 time=1.37 ms
64 bytes from c03 (192.168.0.4): icmp_seq=2 ttl=64 time=1.23 ms
ホストとの通信
各コンテナのdefault gatewayはホストの仮想ブリッジに接続されているNICに向けられているため、bridge networkを経由してホストと通信することができる。
root@c01:/# ping -c2 10.154.25.169
PING 10.154.25.169 (10.154.25.169) 56(84) bytes of data.
64 bytes from 10.154.25.169: icmp_seq=1 ttl=64 time=0.046 ms
64 bytes from 10.154.25.169: icmp_seq=2 ttl=64 time=0.025 ms
root@c01:/# ping -c2 10.154.25.171
PING 10.154.25.171 (10.154.25.171) 56(84) bytes of data.
64 bytes from 10.154.25.171: icmp_seq=1 ttl=63 time=0.325 ms
64 bytes from 10.154.25.171: icmp_seq=2 ttl=63 time=0.144 ms
root@c01:/# ping -c2 10.106.39.197
PING 10.106.39.197 (10.106.39.197) 56(84) bytes of data.
64 bytes from 10.106.39.197: icmp_seq=1 ttl=56 time=1.31 ms
64 bytes from 10.106.39.197: icmp_seq=2 ttl=56 time=1.18 ms
インターネットとの通信
ホストのネットワークがインターネットに接続しているならば、各コンテナはホストを経由してインターネットまで通信することができる。
root@c01:/# ping -c2 8.8.8.8
PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data.
64 bytes from 8.8.8.8: icmp_seq=1 ttl=57 time=1.27 ms
64 bytes from 8.8.8.8: icmp_seq=2 ttl=57 time=1.14 ms
root@c01:/# ping -c2 www.yahoo.co.jp
PING www.g.yahoo.co.jp (124.83.183.243) 56(84) bytes of data.
64 bytes from f3.top.vip.ogk.yahoo.co.jp (124.83.183.243): icmp_seq=1 ttl=48 time=149 ms
64 bytes from f3.top.vip.ogk.yahoo.co.jp (124.83.183.243): icmp_seq=2 ttl=48 time=149 ms
root@c02:/#
root@c02:/# ping -c2 8.8.8.8
PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data.
64 bytes from 8.8.8.8: icmp_seq=1 ttl=55 time=1.44 ms
64 bytes from 8.8.8.8: icmp_seq=2 ttl=55 time=1.16 ms
root@c02:/# ping -c2 www.yahoo.co.jp
PING www.g.yahoo.co.jp (124.83.155.249) 56(84) bytes of data.
64 bytes from f2.top.vip.ogk.yahoo.co.jp (124.83.155.249): icmp_seq=1 ttl=49 time=156 ms
64 bytes from f2.top.vip.ogk.yahoo.co.jp (124.83.155.249): icmp_seq=2 ttl=49 time=156 ms
Docker native overlay networkの状態
最後に、ホストからみたNetwork Namespaceの状態を確認する。
通常通りの手順で立ち上げたコンテナをoverlay networkに接続した場合と、--netを用いてoverlay networkに接続した状態で立ち上げたコンテナで、若干ネットワーク周りの状況が異なる。
コンテナ立ち上げ → overlay networkへ接続
bridge networkの状態
従来通りの手順で立ち上げたコンテナは、従来通りdocker0へ接続される。
root@docker01:~# ip addr show docker0
4: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:74:8a:b2:bf brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 scope global docker0
valid_lft forever preferred_lft forever
inet6 fe80::42:74ff:fe8a:b2bf/64 scope link
valid_lft forever preferred_lft forever
root@docker01:~# brctl show docker0
bridge name bridge id STP enabled interfaces
docker0 8000.0242748ab2bf no veth8b6c18c
root@docker01:~# ip link show veth8b6c18c
6: veth8b6c18c: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP mode DEFAULT group default
link/ether 0e:f1:e8:7a:5f:b0 brd ff:ff:ff:ff:ff:ff
root@docker01:~# ethtool -S veth8b6c18c
NIC statistics:
peer_ifindex: 5
root@docker01:~# docker exec c01 ip link show eth0
5: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff
overlay networkの状態
overlay networkはSandboxに隔離されているため、ホストのネットワークからは確認できない。libnetworkが作成したNetwork Namespaceをip netnsで確認してみると、以下のような状態になっている。仮想ブリッジbr0とvxlanが作成されている。
root@docker01:~# mkdir -p /var/run/netns
root@docker01:~# ln -s /var/run/docker/netns/1-90ce4304fc /var/run/netns/overlay
root@docker01:~# ip netns exec overlay ip addr show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: br0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP group default
link/ether ae:8a:7d:12:b1:2d brd ff:ff:ff:ff:ff:ff
inet 192.168.0.1/24 scope global br0
valid_lft forever preferred_lft forever
inet6 fe80::e8d3:a9ff:feb4:5a10/64 scope link
valid_lft forever preferred_lft forever
7: vxlan1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master br0 state UNKNOWN group default
link/ether fa:e6:d1:a3:4b:55 brd ff:ff:ff:ff:ff:ff
inet6 fe80::f8e6:d1ff:fea3:4b55/64 scope link
valid_lft forever preferred_lft forever
9: veth2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master br0 state UP group default
link/ether ae:8a:7d:12:b1:2d brd ff:ff:ff:ff:ff:ff
inet6 fe80::ac8a:7dff:fe12:b12d/64 scope link
valid_lft forever preferred_lft forever
sandbox内に作成された仮想ブリッジbr0を確認すると、コンテナc01とvxlanに接続されていることがわかる。
root@docker01:~# ip netns exec overlay brctl show br0
bridge name bridge id STP enabled interfaces
br0 8000.ae8a7d12b12d no veth2
vxlan1
root@docker01:~# ip netns exec overlay ethtool -S veth2
NIC statistics:
peer_ifindex: 8
root@docker01:~# docker exec c01 ip link show eth1
8: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP mode DEFAULT group default
link/ether 02:42:c0:a8:00:02 brd ff:ff:ff:ff:ff:ff
overlay networkへ接続した状態でコンテナ立ち上げ
bridge networkの状態
--netオプションを用い、overlay networkへ接続した状態で立ち上げたコンテナは、実はdocker0には接続していない。
root@docker02:~# brctl show docker0
bridge name bridge id STP enabled interfaces
docker0 8000.0242f1590a45 no
その代わり、新たにdocker_gwbridgeという仮想ブリッジが作成され、そこにコンテナは接続されている。
root@docker02:~# ip addr show docker_gwbridge
8: docker_gwbridge: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:27:96:37:c4 brd ff:ff:ff:ff:ff:ff
inet 172.18.0.1/16 scope global docker_gwbridge
valid_lft forever preferred_lft forever
inet6 fe80::42:27ff:fe96:37c4/64 scope link
valid_lft forever preferred_lft forever
root@docker02:~# brctl show docker_gwbridge
bridge name bridge id STP enabled interfaces
docker_gwbridge 8000.0242279637c4 no veth9f4e1cf
root@docker02:~# ip link show veth9f4e1cf
10: veth9f4e1cf: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker_gwbridge state UP mode DEFAULT group default
link/ether 8e:23:38:77:3f:ea brd ff:ff:ff:ff:ff:ff
root@docker02:~# ethtool -S veth9f4e1cf
NIC statistics:
peer_ifindex: 9
root@docker02:~# docker exec c02 ip link show eth1
9: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default
link/ether 02:42:ac:12:00:02 brd ff:ff:ff:ff:ff:ff
ホスト2のdocker networkを確認すると、確かにdocker_gwbridgeがbridge networkとして自動的に追加されている。
root@docker02:~# docker network ls
NETWORK ID NAME DRIVER
90ce4304fc8a vnet overlay
686f8e0ebb70 bridge bridge
0a2fd807bf27 none null
e3b5a4f78425 host host
cdbe0353fe77 docker_gwbridge bridge
一方ホスト1にはdocker_gwbridgeが作成されていない。
root@docker01:~# docker network ls
NETWORK ID NAME DRIVER
90ce4304fc8a vnet overlay
116ff595e265 bridge bridge
263f8fb74651 none null
73128d81e70d host host
あえてdocker0を使わず、docker_gwbridgeを新規作成するデザインを選択した理由は良くわからない。。。
overlay networkの状態
ホスト1と同様、Sandboxに隔離された状態でoverlay networkが構成されている。
root@docker02:~# mkdir -p /var/run/netns
root@docker02:~# ln -s /var/run/docker/netns/1-90ce4304fc /var/run/netns/overlay
root@docker02:~# ip netns exec overlay ip addr show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: br0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP group default
link/ether 52:5b:4c:ec:60:63 brd ff:ff:ff:ff:ff:ff
inet 192.168.0.1/24 scope global br0
valid_lft forever preferred_lft forever
inet6 fe80::e8f3:4bff:feaf:fa8/64 scope link
valid_lft forever preferred_lft forever
5: vxlan1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master br0 state UNKNOWN group default
link/ether fa:4b:4d:c1:9a:57 brd ff:ff:ff:ff:ff:ff
inet6 fe80::f84b:4dff:fec1:9a57/64 scope link
valid_lft forever preferred_lft forever
7: veth2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue master br0 state UP group default
link/ether 52:5b:4c:ec:60:63 brd ff:ff:ff:ff:ff:ff
inet6 fe80::505b:4cff:feec:6063/64 scope link
valid_lft forever preferred_lft forever
root@docker02:~# ip netns exec overlay brctl show br0
bridge name bridge id STP enabled interfaces
br0 8000.525b4cec6063 no veth2
vxlan1
root@docker02:~# ip netns exec overlay ethtool -S veth2
NIC statistics:
peer_ifindex: 6
root@docker02:~# docker exec c02 ip link show eth0
6: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP mode DEFAULT group default
link/ether 02:42:c0:a8:00:03 brd ff:ff:ff:ff:ff:ff
まとめ
正式版のdocker overlay networkは、前回の検証時点よりも更に進化し、使いやすくなった。個人的には、docker linkよりもよほど理解しやすく使いやすいと思う。