はじめに
システム作ってるとかライブラリ作ってるみたいなある程度Pythonを綺麗に1書くことが求められる方々に向けた記事です。
(機械学習系のライブラリを使うためにPython書いてる方とか、初学者の方にはちょっとあわないかも知れません)
綺麗に書くための作法の難しさって共有が面倒なところだと思うんですよね。その書き方は間違いじゃない、間違いじゃないけどもっといい書き方があるぞみたいなやつってなかなか指摘し辛いですし、じゃあ1人に対してレビューしたら他のメンバーにはどう伝える?そもそも伝える必要?俺の工数は?みたいになりがちです。
一番いいのはこういう時はこう書く!みたいなドキュメントを作って「ドキュメント違反です」ってレビューをしてあげることなんですが、まーそれもそれで超面倒じゃないですか。なのでこの記事がそのドキュメントの代わり、とまではいかなくとも礎くらいになればいいなと思って書きました。
ポエム終わり。あと仕事でPython書くなら全員What's New in Pythonくらい読め
本題
以降の章題は
"{重要度} {機能名}【{必要なバージョン}】"
というフォーマットを用います。重要度については
★★★ … 絶対使って欲しい
☆★★ … 使うと嬉しい
☆☆★ … 人による
くらいのイメージでお願いします。
★★★ 型アノテーション【3.6~】
おなじみの。関数の引数や戻り値、変数に型を書くことができます。
よく言われるのが「ただのコメントだから強制力はない」ということでそれは事実そうなのですが、実行時にエラーは出なくともpylanceやmypyを使えばエディタ上で警告を出してくれますし、何より後から読む人のことを考えれば上と下のコードどちらが良いかは一目瞭然でしょう。
現代において(少なくとも関数の戻り値については)型アノテーションは最低限のマナー。
型アノテーションをつけない人は挨拶できない人と同じです。
from datetime import date
from urllib.request import urlopen
from urllib.parse import urlencode
import json
URL = "https://disclosure.edinet-fsa.go.jp/api/v1/documents.json"
def request_count_of_submitted_docs(date_):
query = urlencode({"date": date_})
resp = json.load(urlopen(f"{URL}?{query}"))
return resp["metadata"]["resultset"]["count"]
print(request_count_of_submitted_docs(date(2020, 11, 20)))
>>> 504
↓
...
def request_count_of_submitted_docs(date_: date) -> int:
query: str = urlencode({"date": date_})
resp: dict = json.load(urlopen(f"{URL}?{query}"))
return resp["metadata"]["resultset"]["count"]
...
(VS Code上で見るとより分かりやすいですね)

さて、ここまではよく聞く話なのですが、これ関連の話でどうしても私がお伝えしたいことがあります。
typingライブラリのドキュメントを読んでください。
それなりに量があるうえバージョンアップのたびにドンドン増えるので、そんな書き方あったの!?みたいな話がぼろぼろ見つかるはずです。紹介します系の記事で知った気になるだけじゃもったいねえ。以下に私がよく使うものをいくつかピックアップします。
Final (3.8~)
従来のアッパースネークは定数として扱うみたいなふわふわした不文律ではなくキチンと定数を型チェッカーに通知できます。
上の例で言うと
from typing import Final
URL: Final[str] = "https://disclosure.edinet-fsa.go.jp/api/v1/documents.json"
URL = "https://disclosure.edinet-fsa.go.jp/api/v1/documents" # 型チェッカーに怒られる
こう。
サブクラスで上書きするのもダメです。
from typing import Final
class Connection:
TIMEOUT: Final[int] = 10
class FastConnector(Connection):
TIMEOUT = 1 # 怒られる
ジェネリック型エイリアス
型変数ってクラスとか関数だけじゃなくて型エイリアスに使っても面白いぜ!みたいな話です。
例えばGo風にエラートラップを書きたい時、
from typing import TypeVar, Union
from datetime import date
from urllib.request import urlopen
from urllib.parse import urlencode
from urllib.error import URLError
import json
T = TypeVar("T")
Err = Union[tuple[T, None], tuple[None, Exception]]
URL = "https://disclosure.edinet-fsa.go.jp/api/v1/documents.json"
def request_count_of_submitted_docs(date_: date) -> Err[int]:
query: str = urlencode({"date": date_})
try:
resp: dict = json.load(urlopen(f"{URL}?{query}"))
except URLError as err:
return None, err
return resp["metadata"]["resultset"]["count"], None
cnt, err = request_count_of_submitted_docs(date(2020, 11, 20))
if err:
print(err)
print(cnt)
型エイリアスにも[]をつけられるのはアツいですよね。
@overload
ご存じの通りPythonにオーバーロードはありませんが、型チェッカーにオーバーロードっぽいものを伝えることだけは出来るようになっています。
例えば先ほどから使用している関数は「日付を渡すとその日EDINETに提出された書類の数を返す」ものでしたが、これを「日付を渡さない場合は日付ごとの提出数を辞書で返す」ようにしましょう。
@overload
def request_count_of_submitted_docs() -> Err[dict[date, int]]:
...
@overload
def request_count_of_submitted_docs(date_: date) -> Err[int]:
...
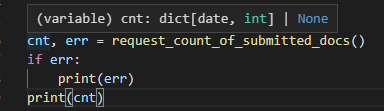
def request_count_of_submitted_docs(date_=None):
# 実装はここに書く
こうすると…
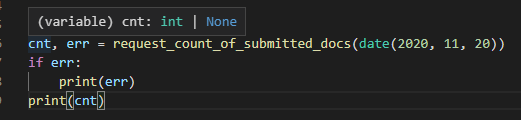
引数の有無だけでキチンと型チェッカーが戻り値の型を自動判別してくれるようになりました。
NamedTuple
ちょっとした構造体のためにわざわざクラス書きたくね~を叶えるためのcollections.namedtupleを更に使いやすくしたものです。
from typing import NamedTuple
class Address(NamedTuple):
row: int
col: int
class Range(NamedTuple):
start: Address
end: Address
宣言これだけ。欲しければDocstringsもプロパティもつけられます。
s = Address(2, 4)
e = Address(6, 8)
rng = Range(s, e)
print(rng[0][1])
>>> 4
print(rng.start.col)
>>> 4
どう考えてもペアでしか使わないだろみたいな値、ついついタプルで渡してしまいがちですが積極的に型をつけていきましょう。
Protocol (3.8~)
なんかこれ私も勘違いしてたんですが構造的部分型自体は以前からサポートしていたらしいですね。
マジかと思って試してみたら
from collections.abc import Container
class Hoge:
def __contains__(self, item):
return True
print(isinstance(Hoge(), Container))
>>> True
マジでした。
で、以前はcollections.abcみたいな組み込みのABCでしか構造的部分型を使えなかったのが3.8からは自作のクラスでもOKになりましたよっていうのが話の流れみたいです。
from typing import Protocol, runtime_checkable
@runtime_checkable
class Greeter(Protocol):
def greet(self):
...
class Japanese:
def greet(self):
print("おはよー!こんちわー!こんばんわー!おやすみー!")
print(issubclass(Japanese, Greeter))
>>> True
構造的部分型(静的ダックタイピング)の何がいいって「インターフェースに対してプログラミングしろ」とかいう古来より伝わるアレが感覚的にできることですよね。例えばよく見るこういう型アノテーション↓
def concat(prefix: str, words: list[str]) -> str:
return ", ".join(f"{prefix} {word}" for word in words)
print(concat("a", ["dog", "cat"]))
>> a dog, a cat
そのwordsは本当にlistが欲しいのか?って思いません?
この「意味もなくlist型でとる」書き方には大きく分けて2つの問題点があります。
1つは単純に使い勝手が悪いこと。この場合はforで回せてstrが取れればなんでもいいわけですから、タプルもセットもイテレータだって実際には渡せるわけです。渡せるものをわざわざ絞って書くのは関数の使い勝手を損ねます。
2つめは結構見落としがちですが、list型を受け入れる関数はリストに対する操作ならなんでもできます。例えばリストにはappendとかsortみたいな破壊的操作のできるメソッドが備わってるわけですが、そういった操作をしないという保証はlistを受け入れる限りできません。関数を使う人にとっては結構なリスクです。
というわけでこのconcat関数が取るwordsはforで回せることだけを保証したい。
from collections.abc import Iterable
def concat(prefix: str, words: Iterable[str]) -> str:
return ", ".join(f"{prefix} {word}" for word in words)
それがこの書き方です。
forで回せるとは即ち__iter__が実装されているオブジェクトということなので、「__iter__が実装されている型」を総称できるIterable型をインポートします。そしてconcatはforで回せることだけが保証されたオブジェクトに対してforだけを行う。これってつまり__iter__というインターフェースに対するプログラミングですよね。
これが!あらゆるインターフェースに対してできるようになる!
それがProtocol登場の嬉しさなわけです。
(※ちなみにですがcollections.abcのページにメソッドとABC(インターフェース)の対応表が乗っています。typingのページと併せて必読です。)
★★★ dataclasses【3.7~】
△¥▲
[ ㊤皿㊤] がしゃーん
/|_肉_|\ がしゃーん
_| |_
dataclassだよ
__init__, __repr__, __eq__, __hash__,
__lt__, __le__, __gt__, __ge__,
__setattr__, __delattr__
を自動で付与してくれるすごいやつだよ
マジですごい。こいつ抜きでクラス宣言なんてもうダルすぎてやってられません。
基本的な使い方は
from dataclasses import dataclass
@dataclass
class Hoge:
hoge: str
fuga: int
piyo: bool
これだけです。
__init__も__repr__もdataclassがよしなにしてくれるので
hoge = Hoge("hoge", 4649, False)
print(hoge)
>>> Hoge(hoge='hoge', fuga=4649, piyo=False)
こうなります。
比較として従来の宣言を置いておきますね。
class Hoge:
def __init__(self, hoge: str, fuga: int, piyo: bool):
self.hoge = hoge
self.fuga = fuga
self.piyo = piyo
hoge = Hoge("hoge", 4649, False)
print(hoge)
>>> <__main__.Hoge object at 0x000001E3CB8F4460>
dataclassを使うメリットは大きく2つです。
1つはご覧のように特殊メソッドを書く手間が省けること。
そして2つ目が型アノテーションを強制できること。
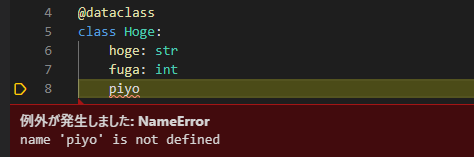
このようにアノテーションを書かないとエラーになるので、自然と型を書く文化が身につきます。
詳細な使い方については@tag1216さんのこちら↓の記事が詳しすぎるので特に私から書くことはありません。
Python3.7からは「Data Classes」がクラス定義のスタンダードになるかもしれない
なのでちょっとした小話だけ。
@dataclass
class Hoge:
hoge: str
fuga: InitVar[int]
def __post_init__(self, fuga):
self.piyo = bool(fuga)
のように__post_init__の中で属性を定義してしまうとdataclassが作ってくれる諸々の特殊メソッドの中にpiyoが反映されません。
hoge = Hoge("hoge", 4649)
fuga = Hoge("hoge", 4649)
print(hoge == fuga)
>>> True
fuga.piyo = False
print(hoge == fuga)
>>> True # [㊤皿㊤ ]!?
こういった場合も必ず最初に全てのフィールドを定義するようにしましょう。
from dataclasses import dataclass, InitVar, field
@dataclass
class Hoge:
hoge: str
fuga: InitVar[int]
piyo: bool = field(init=False)
def __post_init__(self, fuga):
self.piyo = bool(fuga)
hoge = Hoge("hoge", 4649)
fuga = Hoge("hoge", 4649)
print(hoge == fuga)
>> True
fuga.piyo = False
print(hoge == fuga)
>> False # [㊤皿㊤ ]b
☆★★ 代入式【3.8~】
:=セイウチ演算子です。
from typing import Optional
from secrets import randbelow
def perhaps_hoge() -> Optional[str]:
if round(randbelow(9) / 10):
return "hoge"
hg = perhaps_hoge()
if hg:
print(f"my answer: {hg}")
これが
from typing import Optional
from secrets import randbelow
def perhaps_hoge() -> Optional[str]:
if round(randbelow(9) / 10):
return "hoge"
if (hg := perhaps_hoge()):
print(f"my answer: {hg}")
こうなる。
1行じゃんって思うかもしれませんが結構使うんですよコレ。
ifがあるところなら何でも使えるので
print(f"my answer: {hg if (hg := perhaps_hoge()) else 'None'}")
>>> my answer: None
hgs = [hg for _ in range(10) if (hg := perhaps_hoge())]
print(f"my answer: {', '.join(hgs)}")
>>> my answer: hoge, hoge, hoge, hoge, hoge
while not (hg := perhaps_hoge()):
print(f"my answer: {hg}")
>>> my answer: hoge
>>> my answer: hoge
意外にも頻度が高い。
ですがドキュメントにもある通り
セイウチ演算子の使用は、複雑さを減らしたり可読性を向上させる綺麗なケースに限るよう努めてください。
なので濫用は禁物です。
内包表記とか三項演算子にも言えることですが、これらは可読性を高めるという本来の目的を忘れないことが大切ですね。
セイウチくんとのお約束!

☆★★ フォーマット済み文字列リテラル【3.6~】
さっきから地味にちょいちょい使ってるfから始まるアレです。
from secrets import randbelow
rnd = randbelow(9)
# どっちも同じ
print("num {rnd}".format(rnd=rnd))
print(f"num {rnd}")
>>> num 2
f文字列は内部的にformatを使うので基本的には全部f文字列で書いて欲しいんですが、この項では逆にformatを使った方がいい場面についてお話します。
from typing import Iterator, Iterable
from enum import Enum
class FMT(Enum):
greater = "up {num}"
less = "down {num}"
equal = "stay"
def format_diffseq(seq: Iterable[int]) -> Iterator[str]:
def format_(num: int) -> str:
if num > 0:
fmt = FMT.greater
elif num < 0:
fmt = FMT.less
else:
fmt = FMT.equal
return fmt.value.format(num=abs(num))
return map(format_, seq)
seq = [9, 10, 3, 100, 100]
dseq = (y - x for x, y in zip(seq, seq[1:]))
fdseq = format_diffseq(dseq)
print(*fdseq, sep="\n")
>>> up 1
>>> down 7
>>> up 97
>>> stay
このプログラムはこの問題の回答を一部抜粋したもので、[9, 10, 3, 100, 100]という数列の階差数列を規定のフォーマットに変換しています。
こういう既定の文字列があってそれに変数を代入するタイプのやつってf文字列でやろうとするとゴチャるんですよね。
def format_(num: int) -> str:
if num > 0:
return f"up {num}"
if num < 0:
return f"down {num}"
return "stay"
実際の開発ではエラーメッセージをこのように後からフォーマットで処理することが多いです。
なおf文字列は3.8でちょっとした機能追加が入ったのですが、私はあまり使わないので割愛します。多分サーバーサイドでPython使ってる人とかがデバッグ目的で使うんだと思う。
☆☆★ 高レベルのasyncio API【3.7~】
私はあんまり使わないんですが、多分非同期処理の書き方も3.5と3.7からでかなり違っている、はず。
基本的には非同期処理を書く必要が生じうる処理については大体高レベルのAPIが用意されているので(以下asyncioから引用)、自分でイベントループを作ったり閉じたりする必要はない、はず。
- 並行に Python コルーチンを起動 し、実行全体を管理する
- ネットワーク IO と IPC を執り行う
- subprocesses を管理する
- キュー を使ってタスクを分散する
- 並列処理のコードを 同期 させる
例としてStreamsを使って非同期にWeb APIを叩いてみます。
この記事の一番最初のサンプルコードでやってるやつの非同期版ですね。
import asyncio
from datetime import date
from urllib.parse import urlsplit, urlencode
import json
URL = "https://disclosure.edinet-fsa.go.jp/api/v1/documents.json"
async def request_count_of_submitted_docs(date_: date) -> int:
url = urlsplit(f"{URL}?{urlencode(dict(date=date_))}")
reader, writer = await asyncio.open_connection(url.hostname, 443, ssl=True)
writer.write(f"GET {url.geturl()} HTTP/1.0\n\n".encode("latin-1"))
resp = await reader.read()
writer.close()
parsed = json.loads(resp.split(b"\r\n\r\n")[-1])
return parsed["metadata"]["resultset"]["count"]
async def main():
counts = await asyncio.gather(
*(
request_count_of_submitted_docs(date_)
for date_ in (
date(2020, 9, 1),
date(2020, 10, 10),
date(2020, 11, 20),
)
)
)
print(*counts, sep="\n")
asyncio.run(main())
>>> 157
>>> 0
>>> 504
こういうのも日本語で探すと全然情報ないんですけど、公式ドキュメントを読む感じとにかくエントリーポイントを作ってasyncio.runに投げろ!というのが最近の書き方みたいです。私も詳しくないのでこのあたりで許してください。
おわりに
というわけで3.6以降のめぼしい書き方をザッとさらってみました。
こうして見るとかなり綺麗に書くための道具が揃ってきたな感がありますよね。
時代によって全く異なる役割を期待されてきたPythonにいよいよ大規模開発で使いたいというニーズが乗ってきたんだなという流れを感じます。
最近のPythonはバージョンアップのペースも上がって追いつくのが大変ですが、今後もこの流れはドンドン加速していくはずなので頑張ってキャッチアップしていきたいと思います。
Pythonを綺麗に書こう!
-
保守性(可読性含む)を高く、とも言います ↩