はじめに
これは Linux Advent Calendar 2016 の第 11 日目の記事です。Linux のタスクスケジューラーのソースコードや関連するドキュメントなどを読んで分かったことをまとめました。とても長いです・・・
はじめにスケジューラーのアーキテクチャと重要な概念を紹介し、その後はスケジューラーコアとシステムコールの実装について分かったことを延々と述べます。調べきれなかったことや分からなかったことは TODO に残したので、コメント欄とかツイッターで教えてもらえると嬉しいです。間違いの指摘も大歓迎です。
ちなみに私が読み始めたきっかけは、スケジューラーのアーキテクチャ、スケジューリングアルゴリズム、スケジューリングアルゴリズムの切り替え方、nice 値やプロセッサアフィニティがスケジューリングに及ぼす影響、プリエンプションの流れ、マルチプロセッサにおけるタスクのロードバランシング、などをソースコードレベルで理解したかったからで、この辺りの話が中心になります。
なお、本記事では Linux カーネルの v4.8 タグのついたコミットを元にしています。記事中で引用しているソースコードは大部分を省略おり、省略箇所はなるべくコメントで明記するようにしています。ソースコード中の日本語コメントはすべて私が書いたものです。
タスクスケジューラーの概要
本節ではスケジューラーの概要を説明していきます。
スケジューリング対象
スケジューラーを理解する上でまず重要なのが、何をスケジュールしようとしているのか理解することです。
Linux ではスレッドがスケジューリング対象になります。プロセスのメインスレッドとそこから派生したスレッドの間に区別はなく、どちらも同じようにスケジューリングが行われます。以後、スレッドのことをタスクと表現します。
Linux はスレッドを軽量プロセス(LWP: Light-Weight Process)という仕組みで実装しており、これをもって「スケジューリング対象はプロセスである」ともいえますが、本記事では「タスクはスレッドである」という前提で話を進めます。ちなみに軽量プロセスとはアドレス空間などの実行コンテキストを他のプロセスと共有するように作られるプロセスです。Linux の実装では通常プロセスと軽量プロセス(スレッド)は透過的に扱われており、例えば両者は同じ型の構造体で管理されますし、ID も同じ空間で割り当てが行われます。また、ソースコード中でタスクとプロセスとスレッドを同じように呼んでいる箇所が多く見られます(ややこしい)。
タスクキュー(ランキュー)
タスクスケジューラーはタスク群を管理し、優先度を付け、次に実行すべきタスクを選ぶ機構です。これらを実現する素朴な方法は、タスクを優先度付きのキューで管理することです。これを一般的にタスクキューもしくはランキューと呼んだりします。Linux の実装ではランキューと読んでいるため、以後ランキューと表現します。
さて、ランキューが一つあり、複数の CPU がこのキューを共有している場合を考えてみます。この環境では、もし複数の CPU が同時にキューからタスクを出し入れしようとすると、競合状態を引き起こす可能性があります。これを回避する方法の一つはロックによる同期処理を行うことです。これにより各 CPU が正しくタスクを取得することができる一方、CPU の数が増えるほどコンテンションを引き起こし、性能を低下させる恐れがあります。
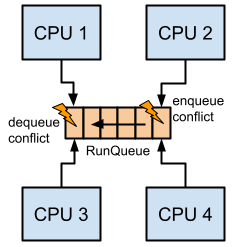
これを解決するために、Linux では CPU 毎にランキューを持ち、それぞれがタスクのスケジューリングを行うようになっています。
タスクの優先度
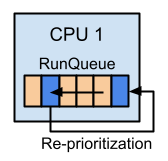
タスクはエンキューされた順番で実行されるとは限りません。タスクごとに優先度が設定され、それに応じてタスクの順番が随時入れ替わります。このタスクの順序付けのアルゴリズムをスケジューリングアルゴリズムと呼びます。優先度はタスクごとに設定され、各ランキュー内でのみ意味を持つ値となります。
ロードバランシング
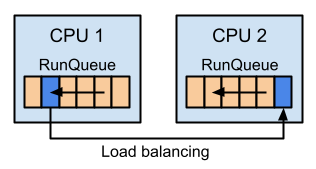
ある CPU のランキューが空の場合、他の CPU のランキューからタスクを移動し、それを実行することでアイドル状態の CPU の使用率を上げることができます。このような処理をロードバランシングといいます。
ロードバランシングを理解するには、まずスケジューラーが CPU をどのように管理しているかを知る必要があるでしょう。**スケジューラーは CPU をドメインとグループという単位で管理します。**これは CPU のアーキテクチャによって構成が変わります。
例として、次の図中の (1) のようにコアを二つ持つプロセッサを考えます。この構成では、各コア毎に一つのグループを形成し、それらをまとめたものをベースドメインとして管理します。次に (2) のようにコアを二つ持ち、かつ、ハイパースレッディングが有効になったプロセッサでは、各コア(2 論理 CPU)毎にグループを構成し、それらをまとめたものをベースドメインとして管理します。最後に (3) のような二つのノードを持つ NUMA 型のマルチプロセッサでは、ノード毎にベースドメインを形成し、さらに全体をまとめる第二ドメインが形成されます。
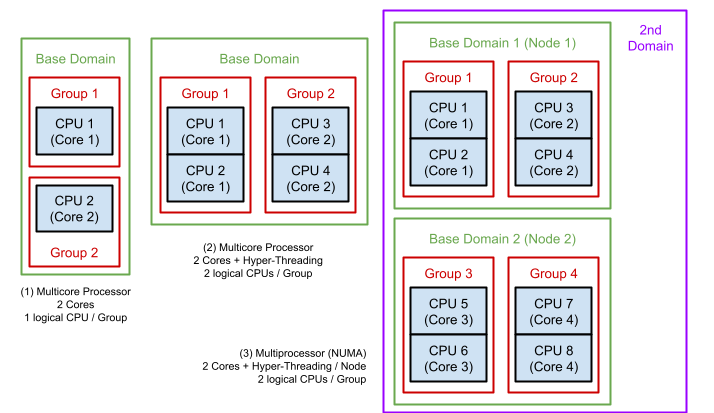
ロードバランシングはドメイン内で行われます。ドメイン内のグループ間で負荷に偏りがある場合にロードバランス処理が開始され、グループ間でタスクのマイグレーションが行われます。負荷の偏りの計算にはグループに所属する CPU のロードバランスの合計値が用いられます。
ロードバランシングは CPU の使用率向上という観点からすると合理的な機能ですが、タスクを移動するとキャッシュが効かなくなるなどデメリットもあるため、スケジューラはなるべく同じ CPU やグループ上で同じタスクを実行するようにスケジューリングを行います。
アフィニティ
タスクがどの CPU 上で実行可能かを表すマスクをアフィニティと呼びます。アフィニティはユーザプログラムから変更することができます。変更方法については後ほど説明します。アフィニティを変更した結果、現在の CPU 上でそのタスクを実行できなくなった場合、タスクは別の CPU へとマイグレーションされます。
スケジューリングクラス
Linux スケジューラーはプラガブルな構成になっており、スケジューラーのコア実装に様々なスケジューリングアルゴリズムを組み込むことが可能になっています。新しくスケジューラーアルゴリズムを追加するには、指定された関数群(インタフェース)を実装し、スケジューラークラスとしてコンパイル時に登録しておく必要があります。
現在スケジューリングクラスは五個実装されています。各クラスの実装を確認していきたいところですが、記事の文量がさらに膨大になってしまうため、本記事では軽く触れる程度に留めておきます。大事なことは、スケジューラーコアはスケジューラークラスの内部実装について(基本的に)関知せず、必要に応じてインタフェース経由で処理を依頼するだけ、ということです。
- Stop-Task スケジューリングクラス : 最も優先度の高いクラスです。実行中のあらゆるタスクにプリエンプトして、指定した関数を実行・完了するまで CPU を独占することができます。タスクを別のランキューにマイグレーションする時などに使われます。
- Deadline-Task スケジューリングクラス : デッドライン保証がされる二番目に優先度の高いクラスです。Earliest Deadline First (EDF) + Constant Bandwidth Server (CBS) というアルゴリズムを使っているそうです (Wikipedia)
- Realtime-Task スケジューリングクラス:三番目に優先度の高いクラスです。FIFO もしくはラウンドロビン式のスケジューリングアルゴリズムを持ちます。
- Fair-Task スケジューリングクラス:デフォルトのクラスです。Completely Fair Scheduler (CFS) というタスク間の公平性を重視したアルゴリズムが使用されています (Wikipedia)
- Idle-Task スケジューリングクラス:最も優先度の低いクラスです。他に実行すべきタスクがない時に実行されます。
スケジューラークラスについては sched(7) にも説明があります。
スケジューラーコアの実装
前節まででスケジューラーの全体像を説明しました。ここからはスケジューラーのコア部分がどのように実装されているのか見ていきます。
コードロケーションとドキュメンテーション
スケジューラーのソースコードは kernel/sched/ 以下にあります。特に本記事で関係してくるのは下記のファイルです。
kernel/sched/
├── core.c // コア実装
├── deadline.c // Deadline-Task 実装
├── fair.c // Fair-Task 実装
├── idle_task.c // Idle-Task 実装
├── rt.c // Realtime-Task 実装
├── sched.h // コア実装のヘッダーファイル
├── stop_task.c // Stop-Task 実装
また、ドキュメントは Documentation/scheduler/ 以下にあります。
重要な構造体
struct task_struct
task_struct はスレッドの実行状態を表す構造体です。470 行以上あるので説明に必要な箇所のみ抜粋しています。
// 大部分を省略しています
struct task_struct {
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
unsigned int flags; /* per process flags, defined below */
int prio, static_prio, normal_prio;
unsigned int rt_priority;
const struct sched_class *sched_class;
struct sched_entity se;
unsigned int policy;
int nr_cpus_allowed;
cpumask_t cpus_allowed;
/* scheduler bits, serialized by scheduler locks */
unsigned sched_reset_on_fork:1;
}
-
stateはこのタスクの実行状態を示しています。 -
prio、static_prio、normal_prio、rt_priorityはタスクの優先度を計算するために使われます。各値の違いは後述します。 -
sched_classはこのタスクが所属するスケジューラークラスへのポインタを格納しています。 -
seはこのタスクが所属しているグループを示しています。 -
policyはこのタスクが従うスケジューリングポリシーを表しており、sched_reset_on_forkビットと合わせて使用されます。 -
cpu_allowedはこのタスクが実行可能な CPU の一覧、つまりアフィニティを表しています。
struct rq
struct rq はランキューを表す構造体で、CPU 毎に存在します (rq = run queue)。ランキューという名前からこの構造体がタスクをキューイングしているイメージを受けますが、タスクの管理方法はスケジューリングクラスによって違うため、実際にタスクを管理しているのはスケジューリングクラスです。struct rq は各スケジューリングクラス固有のデータ領域を内包しており、スケジューリングクラスの実装からそれを参照するようになっています。
// 大部分を省略しています
/*
* This is the main, per-CPU runqueue data structure.
*
* Locking rule: those places that want to lock multiple runqueues
* (such as the load balancing or the thread migration code), lock
* acquire operations must be ordered by ascending &runqueue.
*/
struct rq {
/* runqueue lock: */
raw_spinlock_t lock;
unsigned int nr_running;
struct cfs_rq cfs;
struct rt_rq rt;
struct dl_rq dl;
struct task_struct *curr, *idle, *stop;
struct sched_domain *sd;
/* cpu of this runqueue: */
int cpu;
};
-
nr_runningはこのランキューに所属しているタスクの総数です。 -
cfs,rt,dlは各スケジューリングクラス固有のデータを保持しています。 -
currは現在実行中のタスクです。 -
idleとstopはそれぞれ Idle-Task クラスと Stop-Task クラスのタスクです。 -
sdはこのランキューが所属しているドメインです。 -
cpuはこのランキューを使用している CPU を表す ID です。
struct sched_class
スケジューラークラスのインタフェースを定義している構造体です。Documentation/scheduler/sched-design-CFS.txt の中に、各関数の処理に関する簡単な説明があります。
// コメントとマクロを省略してあります
struct sched_class {
const struct sched_class *next;
void (*enqueue_task) (struct rq *rq, struct task_struct *p, int flags);
void (*dequeue_task) (struct rq *rq, struct task_struct *p, int flags);
void (*yield_task) (struct rq *rq);
bool (*yield_to_task) (struct rq *rq, struct task_struct *p, bool preempt);
void (*check_preempt_curr) (struct rq *rq, struct task_struct *p, int flags);
struct task_struct * (*pick_next_task) (struct rq *rq,
struct task_struct *prev,
struct pin_cookie cookie);
void (*put_prev_task) (struct rq *rq, struct task_struct *p);
int (*select_task_rq)(struct task_struct *p, int task_cpu, int sd_flag, int flags);
void (*migrate_task_rq)(struct task_struct *p);
void (*task_woken) (struct rq *this_rq, struct task_struct *task);
void (*set_cpus_allowed)(struct task_struct *p,
const struct cpumask *newmask);
void (*rq_online)(struct rq *rq);
void (*rq_offline)(struct rq *rq);
void (*set_curr_task) (struct rq *rq);
void (*task_tick) (struct rq *rq, struct task_struct *p, int queued);
void (*task_fork) (struct task_struct *p);
void (*task_dead) (struct task_struct *p);
void (*switched_from) (struct rq *this_rq, struct task_struct *task);
void (*switched_to) (struct rq *this_rq, struct task_struct *task);
void (*prio_changed) (struct rq *this_rq, struct task_struct *task,
int oldprio);
unsigned int (*get_rr_interval) (struct rq *rq,
struct task_struct *task);
void (*update_curr) (struct rq *rq);
void (*task_change_group) (struct task_struct *p, int type);
}
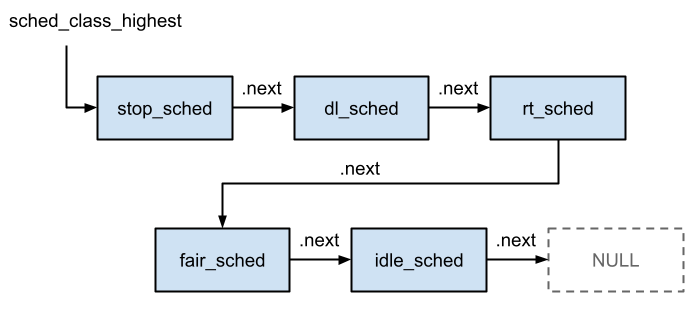
前述の通り、スケジューラークラスは五個定義されています。これらは次の図のように sched_class の next フィールドによってリスト構造をなしており、この順番に優先順位が付けられています。つまり、タスクの優先度付けは、スケジューラークラス内のタスクレベルの優先度とスケジューラークラス間での優先度の二段階になっています。これらの優先度付けがどのように作用するのかは後述します。
# define sched_class_highest (&stop_sched_class)
# define for_each_class(class) \
for (class = sched_class_highest; class; class = class->next)
extern const struct sched_class stop_sched_class;
extern const struct sched_class dl_sched_class;
extern const struct sched_class rt_sched_class;
extern const struct sched_class fair_sched_class;
extern const struct sched_class idle_sched_class;
スケジューラーの初期化
スケジューラーの初期化は kernel/sched/core.c にある sched_init() 関数によって行われます。この関数は init/main.c にある start_kernel() 関数から呼び出されています。
それでは sched_init() を見ていきましょう。まず for_each_possible_cpu() は CPU の数だけイテレーションを行うマクロです。i に CPU 番号が代入されます。このマクロ名にある possible の意味については後ほど説明します。cpu_rq() は引数で渡された CPU 番号に対応した rq 構造体を取得するマクロです。取得した rq に対して様々な初期化処理を行います。例えば、init_cfs_rq() ではランキューにある Fair-Task スケジューリングクラス固有のデータ領域の初期化を行っています。
void __init sched_init(void)
{
// 省略
for_each_possible_cpu(i) {
struct rq *rq;
rq = cpu_rq(i);
raw_spin_lock_init(&rq->lock);
rq->nr_running = 0;
rq->calc_load_active = 0;
rq->calc_load_update = jiffies + LOAD_FREQ;
init_cfs_rq(&rq->cfs);
init_rt_rq(&rq->rt);
init_dl_rq(&rq->dl);
// 省略
}
次に current の sched_class フィールドに Fair-Task スケジューリングクラスへのポインタをセットします。current というこの関数内では定義されていないシンボルが使われていますが、これはプロセッサアーキテクチャ毎に定義された現在のタスクを取得する関数の呼び出しに typedef されています。例えば、x86 では get_current() という関数呼び出しになっていて、その中で CPU 毎に用意された領域に保存してある task_struct へのポインタを返すようになっています。詳しくは arch/x86/include/asm/current.h を見てください。ちなみに前述の cpu_rq() もこの CPU 毎の領域にアクセスして rq へのポインタを取得しています。
/*
* During early bootup we pretend to be a normal task:
*/
current->sched_class = &fair_sched_class;
init_idle() 関数はアイドル時に実行されるタスクの初期化を行います。どうやら現在実行しているタスク (current) を Idle-Task クラスのタスクとして利用するようです。
/*
* Make us the idle thread. Technically, schedule() should not be
* called from this thread, however somewhere below it might be,
* but because we are the idle thread, we just pick up running again
* when this runqueue becomes "idle".
*/
init_idle(current, smp_processor_id());
init_sched_fair_class() 関数はロードバランス処理に関する重要な初期化処理を行います。これはロードバランシングの節で説明します。
init_sched_fair_class();
タスクのエンキューとデキュー
タスクのエンキューとデキューはそれぞれ enqueue_task() と dequeue_task() で行われます。どちらもタスクのスケジューラークラスの enqueue_task() と dequeue_task() を呼び出しており、実際のキュー操作はスケジューラークラス内で行われます(なので、本記事では深追いしません)。
static inline void enqueue_task(struct rq *rq, struct task_struct *p, int flags)
{
update_rq_clock(rq);
if (!(flags & ENQUEUE_RESTORE))
sched_info_queued(rq, p);
p->sched_class->enqueue_task(rq, p, flags);
}
static inline void dequeue_task(struct rq *rq, struct task_struct *p, int flags)
{
update_rq_clock(rq);
if (!(flags & DEQUEUE_SAVE))
sched_info_dequeued(rq, p);
p->sched_class->dequeue_task(rq, p, flags);
}
どちらも第三引数にフラグを取り、これによってキュー操作を柔軟にコントロールすることができます。フラグには次の値を指定することができます。
/*
* {de,en}queue flags:
*
* DEQUEUE_SLEEP - task is no longer runnable
* ENQUEUE_WAKEUP - task just became runnable
*
* SAVE/RESTORE - an otherwise spurious dequeue/enqueue, done to ensure tasks
* are in a known state which allows modification. Such pairs
* should preserve as much state as possible.
*
* MOVE - paired with SAVE/RESTORE, explicitly does not preserve the location
* in the runqueue.
*
* ENQUEUE_HEAD - place at front of runqueue (tail if not specified)
* ENQUEUE_REPLENISH - CBS (replenish runtime and postpone deadline)
* ENQUEUE_MIGRATED - the task was migrated during wakeup
*
*/
タスクをランキュー間で移動する場合は move_queued_task() が呼ばれます。この関数では dequeue_task() でタスクを取り出し、set_task_cpu() でタスクに紐付いたランキューの情報を更新し、enqueue_task() で新しいランキューに追加します。set_task_cpu() の中ではスケジューラークラスの migrate_task_rq() が呼ばれ、各スケジューラークラス固有の処理が行われます。
/*
* move_queued_task - move a queued task to new rq.
*
* Returns (locked) new rq. Old rq's lock is released.
*/
static struct rq *move_queued_task(struct rq *rq, struct task_struct *p, int new_cpu)
{
lockdep_assert_held(&rq->lock);
p->on_rq = TASK_ON_RQ_MIGRATING;
dequeue_task(rq, p, 0);
set_task_cpu(p, new_cpu);
raw_spin_unlock(&rq->lock);
rq = cpu_rq(new_cpu);
raw_spin_lock(&rq->lock);
BUG_ON(task_cpu(p) != new_cpu);
enqueue_task(rq, p, 0);
p->on_rq = TASK_ON_RQ_QUEUED;
check_preempt_curr(rq, p, 0);
return rq;
}
タスクの初期化処理
新しく作られたタスクがどのようにランキューに追加されるか見ていきます。新しいタスクは kernel/fork.c の _do_fork() 関数で作られます。copy_process() 関数で task_struct を生成した後に、wake_up_new_task() 関数を呼び出します。
long _do_fork(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr,
unsigned long tls)
{
struct task_struct *p;
// 省略
p = copy_process(clone_flags, stack_start, stack_size,
child_tidptr, NULL, trace, tls, NUMA_NO_NODE);
// 省略
wake_up_new_task(p);
// 省略
}
wake_up_new_task() はタスクを実行状態 TASK_RUNNING に設定し、select_task_rq() でランキューを選択して activate_task() を呼び出します。activate_task() は前述の enqueue_task() を呼び出し、エンキュー処理を行います。
/*
* wake_up_new_task - wake up a newly created task for the first time.
*
* This function will do some initial scheduler statistics housekeeping
* that must be done for every newly created context, then puts the task
* on the runqueue and wakes it.
*/
void wake_up_new_task(struct task_struct *p)
{
// 省略
p->state = TASK_RUNNING;
# ifdef CONFIG_SMP
/*
* Fork balancing, do it here and not earlier because:
* - cpus_allowed can change in the fork path
* - any previously selected cpu might disappear through hotplug
*
* Use __set_task_cpu() to avoid calling sched_class::migrate_task_rq,
* as we're not fully set-up yet.
*/
__set_task_cpu(p, select_task_rq(p, task_cpu(p), SD_BALANCE_FORK, 0));
# endif
// 省略
activate_task(rq, p, 0);
p->on_rq = TASK_ON_RQ_QUEUED;
// 省略
p->sched_class->task_woken(rq, p);
// 省略
}
select_task_rq() はスケジューラークラスの select_task_rq() を呼び出します。ランキューの選び方はスケジューラークラスに依存していることが分かります。
static inline
int select_task_rq(struct task_struct *p, int cpu, int sd_flags, int wake_flags)
{
lockdep_assert_held(&p->pi_lock);
if (tsk_nr_cpus_allowed(p) > 1)
cpu = p->sched_class->select_task_rq(p, cpu, sd_flags, wake_flags);
else
cpu = cpumask_any(tsk_cpus_allowed(p));
/*
* In order not to call set_task_cpu() on a blocking task we need
* to rely on ttwu() to place the task on a valid ->cpus_allowed
* cpu.
*
* Since this is common to all placement strategies, this lives here.
*
* [ this allows ->select_task() to simply return task_cpu(p) and
* not worry about this generic constraint ]
*/
if (unlikely(!cpumask_test_cpu(cpu, tsk_cpus_allowed(p)) ||
!cpu_online(cpu)))
cpu = select_fallback_rq(task_cpu(p), p);
return cpu;
}
スケジューリング処理
次にタスクのスケジュール処理を見ていきましょう。スケジュール処理のエントリポイントは kernel/sched/core.c の schedule() 関数です。
この関数では do-while 文で need_resched() が true の間、スケジュール処理を繰り返すようになっています。__schedule() 関数はスケジュールのメイン処理を担う関数です。スケジュール処理の間にプリエンプトされるのを防ぐため、__schedule() 関数の間はプリエンプションを無効化しています。need_resched() はその名の通り、スケジュール処理を再度実行する必要がある時に true を返します。 実体はスレッド情報を表すフラグの一つ TIF_NEED_RESCHED が現在のタスクにセットされているかどうかをチェックしており、このフラグは set_tsk_need_resched(struct task_struct*) を呼び出すとセットされるようです。
TODO: いつ TIF_NEED_RESCHED がセットされるのか調べる。
asmlinkage __visible void __sched schedule(void)
{
// 省略
do {
preempt_disable();
__schedule(false);
sched_preempt_enable_no_resched();
} while (need_resched());
}
EXPORT_SYMBOL(schedule);
__schedule() 関数がスケジューリングのメイン処理を行います。まず現在の CPU のランキューを取得し、現在実行中のタスクを prev に保持します。
static void __sched notrace __schedule(bool preempt)
{
struct task_struct *prev, *next;
unsigned long *switch_count;
struct pin_cookie cookie;
struct rq *rq;
int cpu;
cpu = smp_processor_id();
rq = cpu_rq(cpu);
prev = rq->curr;
次に実行タスクを選択します。pick_next_task() はスケジューリングクラスの中で最も優先度が高く、かつタスクを保持しているクラスを選択し、そのクラスの sched_class.pick_next_task() を呼び出します。詳細は後述します。
next = pick_next_task(rq, prev, cookie);
clear_tsk_need_resched(prev);
clear_preempt_need_resched();
rq->clock_skip_update = 0;
選び出されたタスクが前のタスクと異なる場合はランキューを更新し、コンテキストスイッチを行います。
if (likely(prev != next)) {
rq->nr_switches++;
rq->curr = next;
++*switch_count;
trace_sched_switch(preempt, prev, next);
rq = context_switch(rq, prev, next, cookie); /* unlocks the rq */
} else {
lockdep_unpin_lock(&rq->lock, cookie);
raw_spin_unlock_irq(&rq->lock);
}
次に sched_class.pick_next_task() を見ていきます。スケジューリングクラスの節で説明したとおり、タスクの優先度はスケジューリングクラスレベルでの優先度付けと、スケジューリングクラス内でのタスクレベルの優先度付けの二段階になっています。そこでまずは最も優先度の高く、かつ実行可能なタスクを持つスケジューリングクラスを選択し、その次にクラス内で最も優先度の高いタスクを選択する、という処理を順番に行わなくてはいけません。
この手間を回避するために最適化処理が加えられています。もし全ての実行可能タスクが Fair-Task スケジューリングクラスのタスクであれば、その中の最も優先度の高いタスクを取り出して返します。これは「次に選択されるのは標準のスケジューリングクラスである Fair-Task スケジューリングクラスである可能性が高い」という仮定にもとづいています。スケジューラーコアが把握している全スケジューリングクラスのトータルの実行可能タスク数 (rq->nr_running) と、Fair-Task スケジューリングクラスで管理されている実行可能タスク数 (rq->cfs.h_nr_running) を比較し、一致している場合は、Fair-Task スケジューリングクラスの pick_next_task() を直接呼び出します。この fair_sched_class.pick_next_task() が NULL を返した場合 (ランキューに実行可能なタスクが全くない場合) は、次の優先度を持つ Idle-Task スケジューリングクラスの pick_next_task() が呼ばれ、その結果を返します。
ここで「全実行可能タスク数と Fair-Task スケジューリングクラスの実行可能タスク数が一致しているなら、Idle-Task スケジューリングクラスの実行可能タスクは存在しないはず」と疑問に思うかもしれません。Idle-Task スケジューリングクラスは特殊なクラスとなっており、シングルトンなタスクが rq->idle にあらかじめ設定してあり、idle_sched_class.pick_next_task() はこれを返します。この設定をする際に rq->nr_running の値はインクリメントされないため、前述の条件式は成立しえます。
/*
* Pick up the highest-prio task:
*/
static inline struct task_struct *
pick_next_task(struct rq *rq, struct task_struct *prev, struct pin_cookie cookie)
{
const struct sched_class *class = &fair_sched_class;
struct task_struct *p;
/*
* Optimization: we know that if all tasks are in
* the fair class we can call that function directly:
*/
if (likely(prev->sched_class == class &&
rq->nr_running == rq->cfs.h_nr_running)) {
p = fair_sched_class.pick_next_task(rq, prev, cookie);
if (unlikely(p == RETRY_TASK))
goto again;
/* assumes fair_sched_class->next == idle_sched_class */
if (unlikely(!p))
p = idle_sched_class.pick_next_task(rq, prev, cookie);
return p;
}
さて、処理の続きを見ていきます。前述の最適化処理でタスクが選べなかった時、つまり全実行可能タスク数と Fair-Task スケジューリングクラスの実行可能タスク数が一致しなかった場合、高優先度のスケジューリングクラスから順に実行可能タスクがないか確認をしていきます。具体的には for_each_class() でスケジューリングクラスをイテレートしながら、pick_next_task() を呼び、タスクが見つかればそれを返します。スケジューリングクラスの内部実装に関わるため詳細は省きますが、pick_next_task() は RETRY_TASK というものを返す場合があり、この場合はイテレーションを再度実行し直します。
最終行の BUG() はコメントの通り、Idle-Task は必ず存在するため、そこにたどり着いた場合はバグであることが分かります。
again:
for_each_class(class) {
p = class->pick_next_task(rq, prev, cookie);
if (p) {
if (unlikely(p == RETRY_TASK))
goto again;
return p;
}
}
BUG(); /* the idle class will always have a runnable task */
}
ロードバランシング
次にロードバランシングを見ていきます。ロードバランシングについては Documentation/scheduler/sched-domains.txt に詳しい説明があるので、そちらもあわせて参照してください。
スケジューラーはタスクのロードバランシングを定期的に行うために、タイマー割り込みを使用します。まずタイマー割り込みによって、scheduler_tick() 関数が呼び出されます。この関数は現在実行中のタスクの実行時間やロードバランスの状況を更新し、trigger_load_balance() 関数を実行します。
/*
* This function gets called by the timer code, with HZ frequency.
* We call it with interrupts disabled.
*/
void scheduler_tick(void)
{
int cpu = smp_processor_id();
struct rq *rq = cpu_rq(cpu);
// 省略:タスクの統計情報などを更新
trigger_load_balance(rq);
}
trigger_load_balance() は Fair-Task スケジューリングクラスの一部として実装されています。ロードバランシングの実行予定時刻 next_balance() を経過していた場合にソフト割り込み SCHED_SOFTIRQ をスケジュールします。
- TODO: Fair-Task スケジューリングクラスの一部ということは、ロードバランシングはこのクラスのタスクに対してのみ行われる?
- TODO:
nohz_balancer_kick()について調べる。
/*
* Trigger the SCHED_SOFTIRQ if it is time to do periodic load balancing.
*/
void trigger_load_balance(struct rq *rq)
{
/* Don't need to rebalance while attached to NULL domain */
if (unlikely(on_null_domain(rq)))
return;
if (time_after_eq(jiffies, rq->next_balance))
raise_softirq(SCHED_SOFTIRQ);
# ifdef CONFIG_NO_HZ_COMMON
if (nohz_kick_needed(rq))
nohz_balancer_kick();
# endif
}
ちなみにソフト割り込み SCHED_SOFTIRQ の初期化処理は、Fair-Task スケジューリングクラスの初期化時に呼ばれる init_sched_fair_class() 内で行われます(「スケジューラーの初期化」の項を見てください)。SCHED_SOFTIRQ に対応するハンドラとして run_rebalance_domains() を設定します。
__init void init_sched_fair_class(void)
{
// 省略
open_softirq(SCHED_SOFTIRQ, run_rebalance_domains);
// 省略
}
ソフト割り込みが発生すると、run_rebalance_domains() 関数が呼び出されます。「ロードバランシング」の項で説明したとおり、ロードバランス処理はドメイン内のグループ間で行われ、ロードバランスに使われる値は各グループ内でのロードバランスの合計値でした。この時、もしグループ内にアイドル CPU とビジー CPU がいる場合、それらのロードバランスは偏ったままになってしまいます。nohz_idle_balance() の呼び出し直前のコメントを読むと、この事態を解決するために、先にアイドル CPU のロードバランスを解消してから、グループ間のロードバランス処理を行うようです。
TODO: アイドル CPU のロードバランシングについて調べる。
/*
* run_rebalance_domains is triggered when needed from the scheduler tick.
* Also triggered for nohz idle balancing (with nohz_balancing_kick set).
*/
static void run_rebalance_domains(struct softirq_action *h)
{
struct rq *this_rq = this_rq();
enum cpu_idle_type idle = this_rq->idle_balance ?
CPU_IDLE : CPU_NOT_IDLE;
/*
* If this cpu has a pending nohz_balance_kick, then do the
* balancing on behalf of the other idle cpus whose ticks are
* stopped. Do nohz_idle_balance *before* rebalance_domains to
* give the idle cpus a chance to load balance. Else we may
* load balance only within the local sched_domain hierarchy
* and abort nohz_idle_balance altogether if we pull some load.
*/
nohz_idle_balance(this_rq, idle);
rebalance_domains(this_rq, idle);
}
rebalance_domains() ではドメインを順番にチェックしていき、グループ間でタスクが適切に分散されているかチェックしていきます。for_each_domain(cpu, sd) は cpu が所属するドメインをベースドメインから順番にイテレートするマクロです。各イテレーション毎に sched_domain 型の構造体である sd に現在のドメインを代入します。load_balance() がロードバランスの実処理を行います。
/*
* It checks each scheduling domain to see if it is due to be balanced,
* and initiates a balancing operation if so.
*
* Balancing parameters are set up in init_sched_domains.
*/
static void rebalance_domains(struct rq *rq, enum cpu_idle_type idle)
{
int continue_balancing = 1;
int cpu = rq->cpu;
unsigned long interval;
struct sched_domain *sd;
/* Earliest time when we have to do rebalance again */
unsigned long next_balance = jiffies + 60*HZ;
// 省略
for_each_domain(cpu, sd) {
// 省略
interval = get_sd_balance_interval(sd, idle != CPU_IDLE);
// 省略
if (time_after_eq(jiffies, sd->last_balance + interval)) {
if (load_balance(cpu, rq, sd, idle, &continue_balancing)) {
/*
* The LBF_DST_PINNED logic could have changed
* env->dst_cpu, so we can't know our idle
* state even if we migrated tasks. Update it.
*/
idle = idle_cpu(cpu) ? CPU_IDLE : CPU_NOT_IDLE;
}
sd->last_balance = jiffies;
interval = get_sd_balance_interval(sd, idle != CPU_IDLE);
}
// 省略
}
// 省略
}
load_balance() もとても長い関数なので特に重要な部分だけ抜き出しています。struct lb_env はロードバランス処理の実行情報を保持する構造体です。dst_cpu と dst_rq フィールドはタスクのマイグレーション先の CPU とランキューを意味します。これらには現在の CPU とランキューがセットされます。つまり、ロードバランス処理は現在のランキューに別のランキューからタスクをマイグレーションしてくる処理になります。
/*
* Check this_cpu to ensure it is balanced within domain. Attempt to move
* tasks if there is an imbalance.
*/
static int load_balance(int this_cpu, struct rq *this_rq,
struct sched_domain *sd, enum cpu_idle_type idle,
int *continue_balancing)
{
int ld_moved, cur_ld_moved, active_balance = 0;
struct sched_domain *sd_parent = sd->parent;
struct sched_group *group;
struct rq *busiest;
unsigned long flags;
struct cpumask *cpus = this_cpu_cpumask_var_ptr(load_balance_mask);
struct lb_env env = {
.sd = sd,
.dst_cpu = this_cpu,
.dst_rq = this_rq,
.dst_grpmask = sched_group_cpus(sd->groups),
.idle = idle,
.loop_break = sched_nr_migrate_break,
.cpus = cpus,
.fbq_type = all,
.tasks = LIST_HEAD_INIT(env.tasks),
};
find_busiest_group() と find_busiest_queue() で最も負荷の大きなグループの中で最も負荷の大きいランキューを選択し、env.src と env.src_rq にセットします。
group = find_busiest_group(&env);
if (!group) {
schedstat_inc(sd, lb_nobusyg[idle]);
goto out_balanced;
}
busiest = find_busiest_queue(&env, group);
if (!busiest) {
schedstat_inc(sd, lb_nobusyq[idle]);
goto out_balanced;
}
// 省略
env.src_cpu = busiest->cpu;
env.src_rq = busiest;
detach_tasks() はマイグレーション元のランキュー env.src_rq からタスクを取り出し、env.tasks に格納します。detach_tasks() は detach_task()、deactivate_task() を経て、最終的には dequeue_task() を呼び出します。
TODO: デタッチするタスクの選び方を調べる。
if (busiest->nr_running > 1) {
// 省略
/*
* cur_ld_moved - load moved in current iteration
* ld_moved - cumulative load moved across iterations
*/
cur_ld_moved = detach_tasks(&env);
デタッチされたタスクがある場合は、attach_tasks() がマイグレーション先のランキュー env.dst_rq へとタスクをエンキューします。attach_tasks() は attach_one_task()、attach_task()、activate_task() を経て enqueue_task() を呼び出します。
if (cur_ld_moved) {
attach_tasks(&env);
ld_moved += cur_ld_moved;
}
CPU アフィニティの関係で現在の CPU にタスクをマイグレーションできなかった場合は、同じグループ内の別の CPU を選択し、マイグレーション処理を再実行します。
/*
* Revisit (affine) tasks on src_cpu that couldn't be moved to
* us and move them to an alternate dst_cpu in our sched_group
* where they can run. The upper limit on how many times we
* iterate on same src_cpu is dependent on number of cpus in our
* sched_group.
*
* This changes load balance semantics a bit on who can move
* load to a given_cpu. In addition to the given_cpu itself
* (or a ilb_cpu acting on its behalf where given_cpu is
* nohz-idle), we now have balance_cpu in a position to move
* load to given_cpu. In rare situations, this may cause
* conflicts (balance_cpu and given_cpu/ilb_cpu deciding
* _independently_ and at _same_ time to move some load to
* given_cpu) causing exceess load to be moved to given_cpu.
* This however should not happen so much in practice and
* moreover subsequent load balance cycles should correct the
* excess load moved.
*/
if ((env.flags & LBF_DST_PINNED) && env.imbalance > 0) {
/* Prevent to re-select dst_cpu via env's cpus */
cpumask_clear_cpu(env.dst_cpu, env.cpus);
env.dst_rq = cpu_rq(env.new_dst_cpu);
env.dst_cpu = env.new_dst_cpu;
env.flags &= ~LBF_DST_PINNED;
env.loop = 0;
env.loop_break = sched_nr_migrate_break;
/*
* Go back to "more_balance" rather than "redo" since we
* need to continue with same src_cpu.
*/
goto more_balance;
}
load_balance() と、それから呼ばれる attach_tasks() や detach_tasks() は他にも色々な処理を行いますが、処理を追うのはここまでにします(ちょっと疲れました)。
タスクの優先度
タスクの優先度を示す値には、nice 値と priority 値の二種類があります。nice 値は -20 から 19 までの整数で、数値が低いほど優先度が高くなります(他のタスクに実行権を譲ってくれるタスクはナイスである、つまり nice 値が高い、という意味)。一方 priority 値は 0 から 139 までの整数です。0 から 99 までが Realtime-Task 用のプライオリティになっており、100 から 139 までが Fair-Task 用のプライオリティです。nice 値の -20 と 19 は Priority 値の 100 と 139 に対応しています。デフォルトの priority 値は 120 で、これは nice 値 0 に対応します。Deadline-Task 用のプライオリティは特殊で、最も優先度が高いことを示すために負数が使用されます。これらをまとめたものが次の図です。
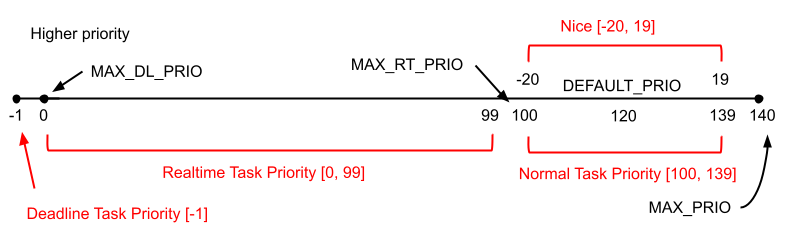
プライオリティに関しては include/linux/sched/prio.h に様々な定数定義とコメントがあります。計算式については上図を参考にしてもらえれば分かると思います。
# define MAX_NICE 19
# define MIN_NICE -20
# define NICE_WIDTH (MAX_NICE - MIN_NICE + 1)
/*
* Priority of a process goes from 0..MAX_PRIO-1, valid RT
* priority is 0..MAX_RT_PRIO-1, and SCHED_NORMAL/SCHED_BATCH
* tasks are in the range MAX_RT_PRIO..MAX_PRIO-1. Priority
* values are inverted: lower p->prio value means higher priority.
*
* The MAX_USER_RT_PRIO value allows the actual maximum
* RT priority to be separate from the value exported to
* user-space. This allows kernel threads to set their
* priority to a value higher than any user task. Note:
* MAX_RT_PRIO must not be smaller than MAX_USER_RT_PRIO.
*/
# define MAX_USER_RT_PRIO 100
# define MAX_RT_PRIO MAX_USER_RT_PRIO
# define MAX_PRIO (MAX_RT_PRIO + NICE_WIDTH)
# define DEFAULT_PRIO (MAX_RT_PRIO + NICE_WIDTH / 2)
/*
* Convert user-nice values [ -20 ... 0 ... 19 ]
* to static priority [ MAX_RT_PRIO..MAX_PRIO-1 ],
* and back.
*/
# define NICE_TO_PRIO(nice) ((nice) + DEFAULT_PRIO)
# define PRIO_TO_NICE(prio) ((prio) - DEFAULT_PRIO)
/*
* 'User priority' is the nice value converted to something we
* can work with better when scaling various scheduler parameters,
* it's a [ 0 ... 39 ] range.
*/
# define USER_PRIO(p) ((p)-MAX_RT_PRIO)
# define TASK_USER_PRIO(p) USER_PRIO((p)->static_prio)
# define MAX_USER_PRIO (USER_PRIO(MAX_PRIO))
task_struct にはプライオリティに関するフィールドが複数ありました。static_prio は nice 値を元に計算 (NICE_TO_PRIO()) された priority 値が入っています。Realtime-Task や Deadline-Task では nice 値は意味を持ちませんが、システムコールを通してセットすることはできます。normal_prio は各スケジューリングクラスごとの標準の priority 値です。この値は normal_prio() で計算されています。prio は static_prio、normal_prio、そしてそのほかの要因によって計算された実効 priority 値になります。これははじめは normal_prio で初期化され、その後 effective_prio() や rt_mutex_get_effective_prio() で計算されなおすようです。rt_priority は Realtime-Task スケジューリングクラスにおいて実効 priority 値を計算する際に使用されます。
struct task_struct {
// 省略
int prio, static_prio, normal_prio;
unsigned int rt_priority;
// 省略
}
normal_prio() について見ていきます。Deadline-Task では MAX_DL_PRIO-1、つまり -1 を返します(Deadline-Task が負数の priority 値を取るのは先程説明したとおりです)。Realtime-Task の場合は、MAX_RT_PRIO から rt_priority を引いた値になります。これはつまり、rt_priority が高いほど優先度が高いことを意味します。この辺りは priority 値の考え方と逆なので注意が必要です。その他のタスクの場合は static_prio の値がそのまま使われます。
/*
* __normal_prio - return the priority that is based on the static prio
*/
static inline int __normal_prio(struct task_struct *p)
{
return p->static_prio;
}
/*
* Calculate the expected normal priority: i.e. priority
* without taking RT-inheritance into account. Might be
* boosted by interactivity modifiers. Changes upon fork,
* setprio syscalls, and whenever the interactivity
* estimator recalculates.
*/
static inline int normal_prio(struct task_struct *p)
{
int prio;
if (task_has_dl_policy(p))
prio = MAX_DL_PRIO-1;
else if (task_has_rt_policy(p))
prio = MAX_RT_PRIO-1 - p->rt_priority;
else
prio = __normal_prio(p);
return prio;
}
次に effective_prio() を見ていきます。Realtime-Task 以外のスケジューリングクラスでは normal_prio の値がそのまま使われます。Realtime-Task の場合は prio が使われますが、これは前述の通り rt_mutex_get_effective_prio() によって再計算された値が入っているようです。
/*
* Calculate the current priority, i.e. the priority
* taken into account by the scheduler. This value might
* be boosted by RT tasks, or might be boosted by
* interactivity modifiers. Will be RT if the task got
* RT-boosted. If not then it returns p->normal_prio.
*/
static int effective_prio(struct task_struct *p)
{
p->normal_prio = normal_prio(p);
/*
* If we are RT tasks or we were boosted to RT priority,
* keep the priority unchanged. Otherwise, update priority
* to the normal priority:
*/
if (!rt_prio(p->prio))
return p->normal_prio;
return p->prio;
}
TODO: Realtime-Task スケジューリングクラスにおける実効 priority 値の計算方法について調べる。
スケジューラー関連のシステムコールの実装
前節まででスケジューラーのコア実装を読めるようになってきたと思います。本節からはスケジューリングに関するシステムコール (sched(7)) がどのように実装されているのか見ていき、スケジューラーの挙動について更に理解を深めていきます。
スケジューリングポリシーの取得と変更
タスクはスケジューリングクラスに属し、クラスごとに異なる優先度やスケジューリングアルゴリズムを持つことを学びました。それではアプリケーションからタスクのスケジューリングクラスを変更するにはどうすれば良いのでしょうか?
Linux ではタスクのスケジューリング方法を取得・変更するためのシステムコールとして sched_setscheduler() と sched_getscheduler() を提供しています。また、このシステムコールで選択できるスケジューリング方法のことをスケジューリングポリシーと呼びます。
スケジューリングポリシー
Linux ではスケジューリングポリシーとして以下の六種類を定義しています。SCHED_RESET_ON_FORK のみ基本のスケジューリングポリシーに OR 演算して使うものとなっており、これが設定されたタスクはプロセス fork 時に通常のスケジューリングポリシーにリセットされます。詳細は sched(7) のページに載っています。この fork 時の挙動は core.c 内の sched_fork() で行われており、これはタスクを生成する copy_process() から呼び出されます。
/*
* Scheduling policies
*/
# define SCHED_NORMAL 0
# define SCHED_FIFO 1
# define SCHED_RR 2
# define SCHED_BATCH 3
/* SCHED_ISO: reserved but not implemented yet */
# define SCHED_IDLE 5
# define SCHED_DEADLINE 6
/* Can be ORed in to make sure the process is reverted back to SCHED_NORMAL on fork */
# define SCHED_RESET_ON_FORK 0x40000000
スケジューリングポリシーとスケジューリングクラスの対応関係は次の通りです。ご覧の通り、スケジューリングポリシーとスケジューリングクラスは一対一に対応するわけではありません。Fair-Task スケジューリングクラスや Realtime-Task スケジューリングクラスには複数のスケジューリングポリシーが対応付けられています。このポリシーの違いにより、同じスケジューリングクラスであっても若干異なる挙動をするようになっています。
TODO: ポリシー毎の挙動の違いを調べる
static inline int idle_policy(int policy)
{
return policy == SCHED_IDLE;
}
static inline int fair_policy(int policy)
{
return policy == SCHED_NORMAL || policy == SCHED_BATCH;
}
static inline int rt_policy(int policy)
{
return policy == SCHED_FIFO || policy == SCHED_RR;
}
static inline int dl_policy(int policy)
{
return policy == SCHED_DEADLINE;
}
sched_getscheduler() システムコール
それでは sched_getscheduler() から見ていきます。引数はプロセス ID となっていますが、gettid() によって得られるスレッド ID を渡しても動作します。この辺りについては「スケジューリング対象」の項で説明しました。返り値は前述のスケジューリングポリシーを表す int 型の値となります。
まず find_process_by_pid() で pid に対応する task_struct を取得し、task_struct の policy フィールドを返り値として用います。このとき、task_struct の sched_reset_on_fork フィールドがセットされている場合は、policy フィールドの値に SCHED_RESET_ON_FORK を OR 演算し、それを返します。
/**
* sys_sched_getscheduler - get the policy (scheduling class) of a thread
* @pid: the pid in question.
*
* Return: On success, the policy of the thread. Otherwise, a negative error
* code.
*/
SYSCALL_DEFINE1(sched_getscheduler, pid_t, pid)
{
struct task_struct *p;
int retval;
if (pid < 0)
return -EINVAL;
retval = -ESRCH;
rcu_read_lock();
p = find_process_by_pid(pid);
if (p) {
retval = security_task_getscheduler(p);
if (!retval)
retval = p->policy
| (p->sched_reset_on_fork ? SCHED_RESET_ON_FORK : 0);
}
rcu_read_unlock();
return retval;
}
sched_setscheduler() システムコール
sched_setscheduler() システムコールは sched_getscheduler() よりも複雑な処理を行います。まずシステムコールのエントリポイントは sys_sched_setscheduler() という関数です。これは do_sched_setscheduler() を呼び出すだけです。引数の sched_param については後述します。
/**
* sys_sched_setscheduler - set/change the scheduler policy and RT priority
* @pid: the pid in question.
* @policy: new policy.
* @param: structure containing the new RT priority.
*
* Return: 0 on success. An error code otherwise.
*/
SYSCALL_DEFINE3(sched_setscheduler, pid_t, pid, int, policy,
struct sched_param __user *, param)
{
/* negative values for policy are not valid */
if (policy < 0)
return -EINVAL;
return do_sched_setscheduler(pid, policy, param);
}
do_sched_setscheduler() は渡された sched_param をユーザ空間からカーネル空間にコピーし、pid に対応する task_struct を取得して、sched_setscheduler() を呼び出します。do_sched_setscheduler() はスケジューリングのパラメータを変更する sched_setparam() システムコールからも呼び出されます。sched_setscheduler() システムコールと sched_setparam システムコールの違いは、後者が引数に policy を取らず、スケジューリングポリシーを変更しないだけのようです。
static int
do_sched_setscheduler(pid_t pid, int policy, struct sched_param __user *param)
{
struct sched_param lparam;
struct task_struct *p;
int retval;
if (!param || pid < 0)
return -EINVAL;
if (copy_from_user(&lparam, param, sizeof(struct sched_param)))
return -EFAULT;
rcu_read_lock();
retval = -ESRCH;
p = find_process_by_pid(pid);
if (p != NULL)
retval = sched_setscheduler(p, policy, &lparam);
rcu_read_unlock();
return retval;
}
sched_setscheduler() ですが、これは _sched_setscheduler() を呼ぶだけです。_sched_setscheduler() に渡す第三引数は権限チェックの処理を行うかどうかを示すブール値となっていて、_sched_setscheduler() に false を渡す sched_setscheduler_nocheck() という関数もあります。こちらはカーネルから呼ぶことを想定しているようです。
/**
* sched_setscheduler - change the scheduling policy and/or RT priority of a thread.
* @p: the task in question.
* @policy: new policy.
* @param: structure containing the new RT priority.
*
* Return: 0 on success. An error code otherwise.
*
* NOTE that the task may be already dead.
*/
int sched_setscheduler(struct task_struct *p, int policy,
const struct sched_param *param)
{
return _sched_setscheduler(p, policy, param, true);
}
EXPORT_SYMBOL_GPL(sched_setscheduler);
_sched_setscheduler() は引数として渡された sched_param を sched_attr に詰め替える処理を行います。何故このようなことをしているかというと、次に呼び出す __sched_setscheduler() が sched_attr を引数に取る sched_setattr() システムコールからも呼び出されるためです。sched_setattr() システムコールは Linux の独自拡張で、sched_setscheduler() システムコールや sched_setparam() システムコール両方の機能を持ち、より柔軟なパラメータ設定を行うことができます。
static int _sched_setscheduler(struct task_struct *p, int policy,
const struct sched_param *param, bool check)
{
struct sched_attr attr = {
.sched_policy = policy,
.sched_priority = param->sched_priority,
.sched_nice = PRIO_TO_NICE(p->static_prio),
};
/* Fixup the legacy SCHED_RESET_ON_FORK hack. */
if ((policy != SETPARAM_POLICY) && (policy & SCHED_RESET_ON_FORK)) {
attr.sched_flags |= SCHED_FLAG_RESET_ON_FORK;
policy &= ~SCHED_RESET_ON_FORK;
attr.sched_policy = policy;
}
return __sched_setscheduler(p, &attr, check, true);
}
sched_param と sched_attr の定義は次の通りです。sched_param は sched_priority しか定義していないのに対し、sched_attr はより柔軟なパラメータを提供していることが分かります。また、sched_attr の sched_priority のコメントから、このプライオリティは現在の実装では Realtime Task スケジューリング (SCHED_FIFO, SCHED_RR) でしか使われないことが分かります。このプライオリティの最大値と最小値は、それぞれ sched_get_priority_max() システムコールと sched_get_priority_min() システムコールで取得することができます。同様に、nice 値は Fair Task スケジューリング (SCHED_NORMAL, SCHED_BATCH) でしか使われないことも分かります。この辺りのことは「タスクの優先度」の項で説明しました。
struct sched_param {
int sched_priority;
};
// コメントの大部分を省略しています
/*
* Extended scheduling parameters data structure.
*
* @size size of the structure, for fwd/bwd compat.
*
* @sched_policy task's scheduling policy
* @sched_flags for customizing the scheduler behaviour
* @sched_nice task's nice value (SCHED_NORMAL/BATCH)
* @sched_priority task's static priority (SCHED_FIFO/RR)
* @sched_deadline representative of the task's deadline
* @sched_runtime representative of the task's runtime
* @sched_period representative of the task's period
*/
struct sched_attr {
u32 size;
u32 sched_policy;
u64 sched_flags;
/* SCHED_NORMAL, SCHED_BATCH */
s32 sched_nice;
/* SCHED_FIFO, SCHED_RR */
u32 sched_priority;
/* SCHED_DEADLINE */
u64 sched_runtime;
u64 sched_deadline;
u64 sched_period;
};
引き続きメインの処理である __sched_setscheduler() を見ていきます。かなり大きな関数なので、コードの大部分を省略して引用しています。まずはユーザ空間から呼ばれた場合に備えて権限の確認などを行います。
static int __sched_setscheduler(struct task_struct *p,
const struct sched_attr *attr,
bool user, bool pi)
{
int newprio = dl_policy(attr->sched_policy) ? MAX_DL_PRIO - 1 :
MAX_RT_PRIO - 1 - attr->sched_priority;
int retval, oldprio, oldpolicy = -1, queued, running;
int new_effective_prio, policy = attr->sched_policy;
const struct sched_class *prev_class;
struct rq_flags rf;
int reset_on_fork;
int queue_flags = DEQUEUE_SAVE | DEQUEUE_MOVE;
struct rq *rq;
// 省略:引数や権限のチェック、各スケジューリングクラス固有のチェック
次に変更対象のタスクがランキュー上にある場合は、一旦ランキューから取り除きます。また、実行状態だった場合は sched_class.put_prev_task() でスケジューラークラスに通知します。その後、パラメータ設定の実処理を行う __setscheduler() を呼び出します。
queued = task_on_rq_queued(p);
running = task_current(rq, p);
if (queued)
dequeue_task(rq, p, queue_flags);
if (running)
put_prev_task(rq, p);
prev_class = p->sched_class;
__setscheduler(rq, p, attr, pi);
__setscheduler() はプライオリティの変更とスケジューリングクラスの設定を行います。まず __setscheduler_params() を呼び出し、タスクの static_prio、rt_priority、normal_prio、そしてスケジューリングポリシーを attr で指定されたものに変更します。その後、prio の値を設定し、最後にポリシーに応じてスケジューリングクラスの設定を行います。
TODO: sys_sched_setscheduler() に SCHED_IDLE を渡した場合はどうなるのか?__setscheduler() を見た感じ、スケジューリングクラスは Fair-Task として処理されているようにみえる。一方、task_struct.policy は SCHED_IDLE になっている?
/* Actually do priority change: must hold pi & rq lock. */
static void __setscheduler(struct rq *rq, struct task_struct *p,
const struct sched_attr *attr, bool keep_boost)
{
__setscheduler_params(p, attr);
/*
* Keep a potential priority boosting if called from
* sched_setscheduler().
*/
if (keep_boost)
p->prio = rt_mutex_get_effective_prio(p, normal_prio(p));
else
p->prio = normal_prio(p);
if (dl_prio(p->prio))
p->sched_class = &dl_sched_class;
else if (rt_prio(p->prio))
p->sched_class = &rt_sched_class;
else
p->sched_class = &fair_sched_class;
}
static void __setscheduler_params(struct task_struct *p,
const struct sched_attr *attr)
{
int policy = attr->sched_policy;
if (policy == SETPARAM_POLICY)
policy = p->policy;
p->policy = policy;
if (dl_policy(policy))
__setparam_dl(p, attr);
else if (fair_policy(policy))
p->static_prio = NICE_TO_PRIO(attr->sched_nice);
/*
* __sched_setscheduler() ensures attr->sched_priority == 0 when
* !rt_policy. Always setting this ensures that things like
* getparam()/getattr() don't report silly values for !rt tasks.
*/
p->rt_priority = attr->sched_priority;
p->normal_prio = normal_prio(p);
set_load_weight(p);
}
__sched_setscheduler() の処理に戻ります。変更対象のタスクが実行状態だった場合はパラメータが変更されたことを sched_class.set_curr_task() を通して通知します。またもしランキュー上にあった場合は再度エンキューします。
if (running)
p->sched_class->set_curr_task(rq);
if (queued) {
/*
* We enqueue to tail when the priority of a task is
* increased (user space view).
*/
if (oldprio < p->prio)
queue_flags |= ENQUEUE_HEAD;
enqueue_task(rq, p, queue_flags);
}
check_class_changed(rq, p, prev_class, oldprio);
check_class_changed() は、タスクのスケジューリングクラスが変更された場合は変更前のクラスの switched_from() と変更後のクラスの switched_to() を呼び出し、もしタスクが Deadline-Task のままでプライオリティだけ変更された場合は Deadline-Task クラスの prio_changed() を呼び出します。
static inline void check_class_changed(struct rq *rq, struct task_struct *p,
const struct sched_class *prev_class,
int oldprio)
{
if (prev_class != p->sched_class) {
if (prev_class->switched_from)
prev_class->switched_from(rq, p);
p->sched_class->switched_to(rq, p);
} else if (oldprio != p->prio || dl_task(p))
p->sched_class->prio_changed(rq, p, oldprio);
}
タスクの yield
sched_yield() システムコールは、現在実行中のタスクが CPU の実行権を自発的に手放す時に用いられます。これはタスクスケジューリングの観点から見ると、現在実行中のタスクをランキューに戻し、ランキューから次のタスクを選び出して、それにコンテキストスイッチする、つまりスケジューリング処理をすることになります。
次のコードが sched_yield() システムコールの実装です。ここまでの説明を読んでいればとても簡単だと思います。まず現在実行中のタスクが所属するスケジューリングクラスの yield_task() を呼び出します。これはスケジューリングクラス固有の処理となるため詳細は省きますが、CPU を手放すための前処理などをしているようです。次に schedule() を呼び出して、新しいタスクを選び出し、それにコンテキストスイッチします。
/**
* sys_sched_yield - yield the current processor to other threads.
*
* This function yields the current CPU to other tasks. If there are no
* other threads running on this CPU then this function will return.
*
* Return: 0.
*/
SYSCALL_DEFINE0(sched_yield)
{
struct rq *rq = this_rq_lock();
schedstat_inc(rq, yld_count);
current->sched_class->yield_task(rq);
// 省略
schedule();
return 0;
}
アフィニティの取得と変更
CPU のアフィニティの取得と変更のためのシステムコールとして sched_getaffinity() と sched_setaffinity() を提供しています。task_struct のところで説明したとおり、cpumast_t 型の task_struct.cpu_allowed がタスクの CPU アフィニティを表しており、これらシステムコールはそのフィールドを取得・変更するように実装されています。
sched_getaffinity() システムコール
それではまず sched_getaffinity() システムコールのエントリポイントである sys_sched_getaffinity() を見ていきます。この関数内では引数の確認、実際の処理を行う sched_getaffinity() 関数の呼び出し、そしてその結果をユーザ空間へとコピーする処理を行っています。
/**
* sys_sched_getaffinity - get the cpu affinity of a process
* @pid: pid of the process
* @len: length in bytes of the bitmask pointed to by user_mask_ptr
* @user_mask_ptr: user-space pointer to hold the current cpu mask
*
* Return: size of CPU mask copied to user_mask_ptr on success. An
* error code otherwise.
*/
SYSCALL_DEFINE3(sched_getaffinity, pid_t, pid, unsigned int, len,
unsigned long __user *, user_mask_ptr)
{
int ret;
cpumask_var_t mask;
// 省略:引数チェックなど
ret = sched_getaffinity(pid, mask);
if (ret == 0) {
size_t retlen = min_t(size_t, len, cpumask_size());
if (copy_to_user(user_mask_ptr, mask, retlen))
ret = -EFAULT;
else
ret = retlen;
}
free_cpumask_var(mask);
return ret;
}
sched_getaffinity() もそんなに難しいことはしていません。基本的には引数で渡された pid に対応する task_struct を取得し、それの cpu_allowed フィールドを返すだけです。一点ポイントなのは cpumask_and(mask, &p->cpus_allowed, cpu_active_mask) です。これはタスクの持つアフィニティマスクと現在アクティブな CPU のマスクとを AND 演算し、有効な CPU セットのみを返すようにしています。
long sched_getaffinity(pid_t pid, struct cpumask *mask)
{
struct task_struct *p;
unsigned long flags;
int retval;
rcu_read_lock();
retval = -ESRCH;
p = find_process_by_pid(pid);
if (!p)
goto out_unlock;
retval = security_task_getscheduler(p);
if (retval)
goto out_unlock;
raw_spin_lock_irqsave(&p->pi_lock, flags);
cpumask_and(mask, &p->cpus_allowed, cpu_active_mask);
raw_spin_unlock_irqrestore(&p->pi_lock, flags);
out_unlock:
rcu_read_unlock();
return retval;
}
この cpu_active_mask というのは include/linux/cpumask.h で提供されており、他にも cpu_possible_mask、cpu_present_mask、cpu_online_mask といったバリエーションがあります。possible はこのコンピュータに接続されうる CPU の集合でブート時に静的に決まり、present は現在実際に接続されている CPU の集合、online はスケジューリング可能な CPU の集合、そして active はタスクのマイグレーションが可能な CPU の集合のようです。アフィニティの設定はタスクのマイグレーションが伴う可能性があるため、cpu_active_mask でマイグレーション可能な CPU セットのみを返すようにしているのだと思われます。
/*
* The following particular system cpumasks and operations manage
* possible, present, active and online cpus.
*
* cpu_possible_mask- has bit 'cpu' set iff cpu is populatable
* cpu_present_mask - has bit 'cpu' set iff cpu is populated
* cpu_online_mask - has bit 'cpu' set iff cpu available to scheduler
* cpu_active_mask - has bit 'cpu' set iff cpu available to migration
*
* If !CONFIG_HOTPLUG_CPU, present == possible, and active == online.
*
* The cpu_possible_mask is fixed at boot time, as the set of CPU id's
* that it is possible might ever be plugged in at anytime during the
* life of that system boot. The cpu_present_mask is dynamic(*),
* representing which CPUs are currently plugged in. And
* cpu_online_mask is the dynamic subset of cpu_present_mask,
* indicating those CPUs available for scheduling.
*
* 以下略
*/
sched_setaffinity() システムコール
それでは次に sched_setaffinity() システムコールのエントリポイントである sys_sched_setaffinity() を見ていきます。この関数はアフィニティの設定処理を行う sched_setaffinity() を呼び出します。
/**
* sys_sched_setaffinity - set the cpu affinity of a process
* @pid: pid of the process
* @len: length in bytes of the bitmask pointed to by user_mask_ptr
* @user_mask_ptr: user-space pointer to the new cpu mask
*
* Return: 0 on success. An error code otherwise.
*/
SYSCALL_DEFINE3(sched_setaffinity, pid_t, pid, unsigned int, len,
unsigned long __user *, user_mask_ptr)
{
cpumask_var_t new_mask;
int retval;
if (!alloc_cpumask_var(&new_mask, GFP_KERNEL))
return -ENOMEM;
retval = get_user_cpu_mask(user_mask_ptr, len, new_mask);
if (retval == 0)
retval = sched_setaffinity(pid, new_mask);
free_cpumask_var(new_mask);
return retval;
}
sched_setaffinity() では、まず引数 pid に対応する task_struct を取得し、cpuset_cpus_allowed() でアフィニティマスクを cpu_allowed に格納します。この cpuset_cpus_allowed() は task_struct を引数に取りますが、実際にはこれを使わず、cpu_allowed には cpu_possible_mask が格納されます。次に設定値として与えられた in_mask と AND 演算 cpumask_and() を行い、結果を new_mask に格納します。
その後、アフィニティマスクの設定処理を行う __set_cpus_allowed_ptr() を呼び出します。この後に、再度 cpuset_cpus_allowed() を呼び出し、cpumask_subset() で new_mask が cpus_allowed のサブセットになっているか確認します。これは、cpu_possible_mask が途中で変更されている可能性があり、その場合にタスクのアフィニティマスクに possible ではない CPU が含まれている可能性があるからです。もしサブセットになっていない場合は、再度 new_mask を計算し直し、__set_cpus_allowed_ptr() を実行し直します。
long sched_setaffinity(pid_t pid, const struct cpumask *in_mask)
{
cpumask_var_t cpus_allowed, new_mask;
struct task_struct *p;
int retval;
rcu_read_lock();
p = find_process_by_pid(pid);
// 省略:セキュリティチェックなど
cpuset_cpus_allowed(p, cpus_allowed);
cpumask_and(new_mask, in_mask, cpus_allowed);
// 省略:SCHED_DEADLINE 固有の処理
again:
retval = __set_cpus_allowed_ptr(p, new_mask, true);
if (!retval) {
cpuset_cpus_allowed(p, cpus_allowed);
if (!cpumask_subset(new_mask, cpus_allowed)) {
/*
* We must have raced with a concurrent cpuset
* update. Just reset the cpus_allowed to the
* cpuset's cpus_allowed
*/
cpumask_copy(new_mask, cpus_allowed);
goto again;
}
}
// 省略:リソースの解放処理など
}
__set_cpus_allowed_ptr() はタスクのアフィニティ設定を更新するとともに、新しいアフィニティ設定に合わせてタスクのマイグレーションを行います。
do_set_cpus_allowed() は内部で sched_class の set_cpus_allowed() が呼ばれます。Fair-Task スケジューラークラスの場合、これは task_struct の cpus_allowed フィールドと nr_cpus_allowed フィールドを更新するだけです。
/*
* Change a given task's CPU affinity. Migrate the thread to a
* proper CPU and schedule it away if the CPU it's executing on
* is removed from the allowed bitmask.
*
* NOTE: the caller must have a valid reference to the task, the
* task must not exit() & deallocate itself prematurely. The
* call is not atomic; no spinlocks may be held.
*/
static int __set_cpus_allowed_ptr(struct task_struct *p,
const struct cpumask *new_mask, bool check)
{
const struct cpumask *cpu_valid_mask = cpu_active_mask;
unsigned int dest_cpu;
struct rq_flags rf;
struct rq *rq;
int ret = 0;
// 省略
do_set_cpus_allowed(p, new_mask);
cpumask_any_and() は引数で与えられた二つの maskset_t を AND 演算した結果から、ランダムに一つ CPU を選択して、その CPU 番号を返します。
タスクのマイグレーション処理はタスクの現在の状態によって変わります。
もしタスクが実行中もしくは起床中である場合は、マイグレーション処理をそのタスクよりも高い優先度のタスクとして実行します。これを実現するために、StopTask スケジューリングクラスが使われていて、タスクの実行が完了するまでプリエンプトされることはありません。stop_one_cpu() がその機能を提供しています。この関数の第一引数で指定した CPU 上で、第二引数で渡した関数を実行します。ここでは、現在の CPU 上で migration_cpu_stop() が実行されることになります。
タスクの状態が実行中でも起床中でもなくランキュー上で待ち状態の場合は、move_queued_task() 関数を呼び出します。
dest_cpu = cpumask_any_and(cpu_valid_mask, new_mask);
if (task_running(rq, p) || p->state == TASK_WAKING) {
struct migration_arg arg = { p, dest_cpu };
/* Need help from migration thread: drop lock and wait. */
task_rq_unlock(rq, p, &rf);
stop_one_cpu(cpu_of(rq), migration_cpu_stop, &arg);
tlb_migrate_finish(p->mm);
return 0;
} else if (task_on_rq_queued(p)) {
/*
* OK, since we're going to drop the lock immediately
* afterwards anyway.
*/
lockdep_unpin_lock(&rq->lock, rf.cookie);
rq = move_queued_task(rq, p, dest_cpu);
lockdep_repin_lock(&rq->lock, rf.cookie);
}
タスクの優先度の変更
本節ではタスクの優先度の変更方法について見ていきます。タスクの優先度については「タスクの優先度」の項で既に説明しました。また Realtime-Task スケジューリングクラスにおける priority 値の計算は sched_setscheduler() システムコールの項で説明しました。本節では nice 値に焦点を当てて見ていきます。
nice 値の取得と設定には getpriority() システムコールと setpriority() システムコールが使用可能ですが、ここでは setpriority() システムコールをシンプルにした nice() システムコールを見ていきます。setpriority() と nice() は最終的には同じ関数の呼び出しになります。
nice() システムコールのエントリポイントは sys_nice() です。引数に int 型の increment を取ります。これは priority 値の増減値を意味します。負数を与えることで現在のタスクの優先度を上げることができますが、権限がないとできません。
まず clamp(increment, -NICE_WIDTH, NICE_WIDTH) によって、increment の値を nice 値が取れる範囲に押し込みます。task_nice(current) は現在のタスクの static_priority を nice 値に変換します (NICE_TO_PRIO())。increment が負数の場合は、can_nice() によって優先度を上げる権限があるか確認します。そして set_user_nice() を呼び出します。
/*
* sys_nice - change the priority of the current process.
* @increment: priority increment
*
* sys_setpriority is a more generic, but much slower function that
* does similar things.
*/
SYSCALL_DEFINE1(nice, int, increment)
{
long nice, retval;
/*
* Setpriority might change our priority at the same moment.
* We don't have to worry. Conceptually one call occurs first
* and we have a single winner.
*/
increment = clamp(increment, -NICE_WIDTH, NICE_WIDTH);
nice = task_nice(current) + increment;
nice = clamp_val(nice, MIN_NICE, MAX_NICE);
if (increment < 0 && !can_nice(current, nice))
return -EPERM;
retval = security_task_setnice(current, nice);
if (retval)
return retval;
set_user_nice(current, nice);
return 0;
}
set_user_nice() は実際に nice 値を変更し、ランキュー内のタスクの優先順位を再計算します。前述の通り、この関数は setpriority() システムコールからも共通して使用されます。
まず、与えられたタスクが Deadline-Task もしくは Realtime-Task かどうか確認します。これらタスクでは nice 値の値は意味を持ちませんが、後々スケジューリングポリシーが変更される場合に備え、static_prio に新しい値をセットし、リターンします。
void set_user_nice(struct task_struct *p, long nice)
{
int old_prio, delta, queued;
struct rq_flags rf;
struct rq *rq;
// 省略:nice の範囲チェックなど
/*
* The RT priorities are set via sched_setscheduler(), but we still
* allow the 'normal' nice value to be set - but as expected
* it wont have any effect on scheduling until the task is
* SCHED_DEADLINE, SCHED_FIFO or SCHED_RR:
*/
if (task_has_dl_policy(p) || task_has_rt_policy(p)) {
p->static_prio = NICE_TO_PRIO(nice);
goto out_unlock;
}
変更対象のタスクがランキューにある場合は一旦ランキューから取り出し、static_prio や prio の値を新しいものに変更します。また変更の差分を計算し、delta に格納しておきます。
queued = task_on_rq_queued(p);
if (queued)
dequeue_task(rq, p, DEQUEUE_SAVE);
p->static_prio = NICE_TO_PRIO(nice);
set_load_weight(p);
old_prio = p->prio;
p->prio = effective_prio(p);
delta = p->prio - old_prio;
タスクをランキューから取り出した場合は再度エンキューを行います。この時 delta の値をチェックし、タスクの優先度が上がったり、もしくは現在実行中のタスクの優先度が引き下げられた場合は、リスケジュール処理を行い、新しい優先度設定に応じてタスクを選び直します。
if (queued) {
enqueue_task(rq, p, ENQUEUE_RESTORE);
/*
* If the task increased its priority or is running and
* lowered its priority, then reschedule its CPU:
*/
if (delta < 0 || (delta > 0 && task_running(rq, p)))
resched_curr(rq);
}
out_unlock:
task_rq_unlock(rq, p, &rf);
}
EXPORT_SYMBOL(set_user_nice);
まとめ
ソースコードリーディングを通して次のようなことが分かりました。
- スケジューラーコアはプラガブルなアーキテクチャを採用しており、様々なスケジューリングアルゴリズムを組み込むことができる。現在スケジューリングアルゴリズムは五種類実装されている。スケジューリングポリシーを指定することでスケジューリングアルゴリズムを選択することができる。
- スケジューラーは CPU の構成をドメインとグループという単位で管理していて、ロードバランシングはグループ間のタスクマイグレーションによって実現されている。
- アフィニティによって、どの CPU 上でタスクを動かすことができるか指示することができる。アフィニティが変更されるとタスクのマイグレーションが発生する。
- nice 値によって、タスクのランキュー内での優先度を変更することができる。優先度は一つのランキュー内でのみ意味をなす値で、別のランキューにあるタスクには影響を与えない。
各スケジューリングクラスのアルゴリズムとその実装、CPU トポロジの構築方法、NUMA 固有の処理、cgroup による処理などが追えなかったので、別の機会に調べたいと思っています。