出力結果
概要
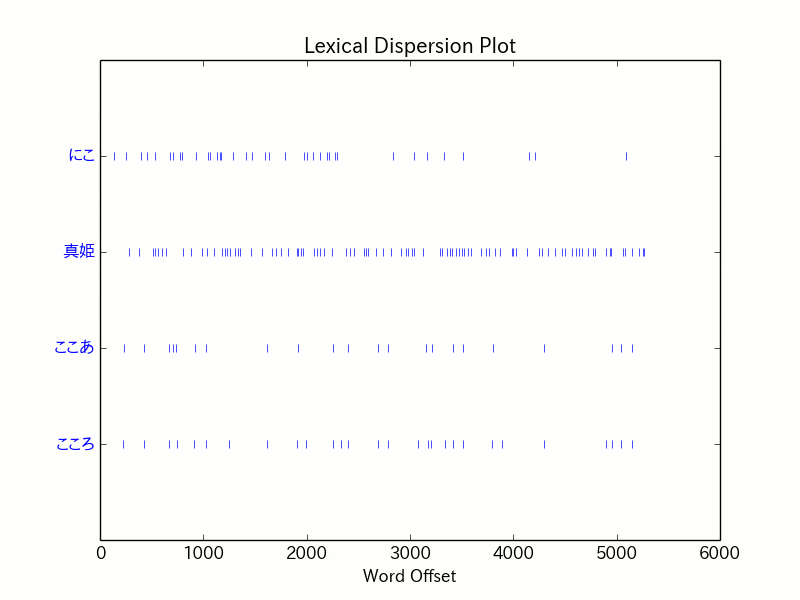
NLTK(自然言語処理用ライブラリ)のplot機能(グラフ出力)で、日本語が使えるようにする。
オライリー本「入門 自然言語処理」(->英語版[無料])のPython による日本語自然言語処理の章で、
"ただし、 matplotlib では、標準では日本語が文字化けしてしまうことに注意。"とあるが、
対処法が見当たらないので、自前で対処した。
前提知識
環境
LinuxMint13(Ubuntu12.04)
コード
NLTK日本語plot.py
# !/usr/bin/env python
# -*- coding: utf-8 -*-
import sys
reload(sys)
sys.setdefaultencoding('UTF-8')
import MeCab
import nltk
from numpy import *
from nltk.corpus.reader import *
from nltk.corpus.reader.util import *
from nltk.text import Text
import jptokenizer
### matplotデフォルトフォントの指定 ### ←ポイント1:明示的に日本語フォントを指定
import matplotlib
import matplotlib.font_manager as font_manager
# TTFファイル(フォント)のアドレスを指定
font_path = '/usr/share/fonts/truetype/fonts-japanese-gothic.ttf'
# フォントの詳細情報を取得
font_prop = font_manager.FontProperties(fname = font_path)
# フォントの名前を使い、matplotのデフォルトフォントに指定
matplotlib.rcParams['font.family'] = font_prop.get_name()
### 日本語コーパス(unicode)の作成 ### ←ポイント2:単語群はunicodeで管理
# コーパスを読み込み
jp_sent_tokenizer = nltk.RegexpTokenizer(u'[^ 「」!?。]*[!?。]')
reader = PlaintextCorpusReader("/home/ユーザ/デスクトップ", r'NKMK.txt',
encoding='utf-8',
para_block_reader=read_line_block,
sent_tokenizer=jp_sent_tokenizer,
word_tokenizer=jptokenizer.JPMeCabTokenizer())
# コーパスからunicode指定で単語群を取得
nkmk = Text(unicode(w) for w in reader.words())
### 描画 ### ←ポイント3:引数もunicodeで指定
nkmk.dispersion_plot([u'にこ',u'真姫',u'ここあ',u'こころ'])
解説
(ソース内コメント参照)
課題
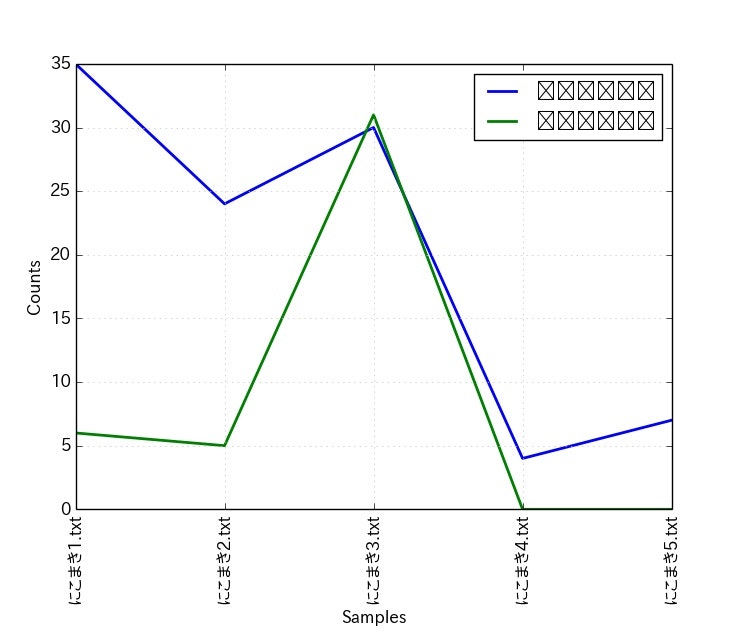
ConditionalFreqDist.plot()のラベルは日本語化できない。
/usr/local/lib/python2.7/dist-packages/nltk/probability.pyを読むと、
"kwargs['label'] = str(condition)"(1790行目)となっている。
つまり、ラベルの文字列はstr()関数を通して出力されるので、日本語は確実に化ける。
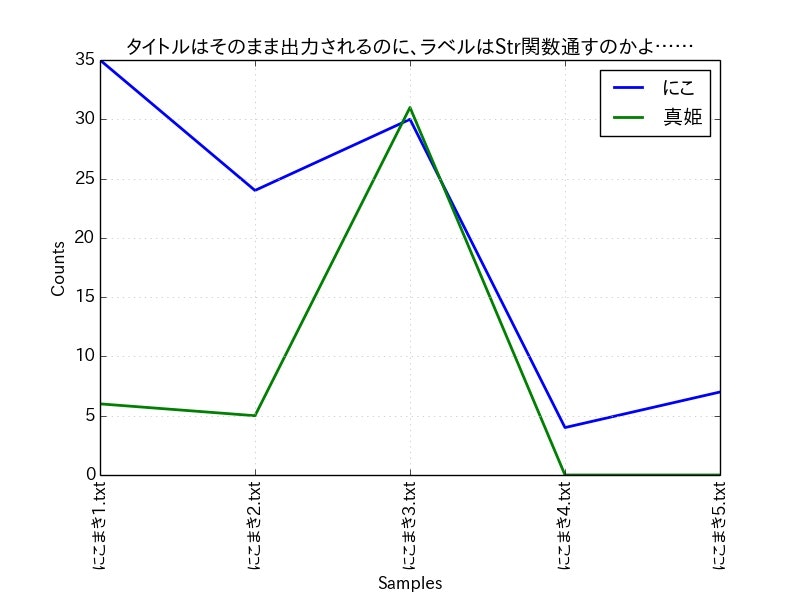
修正方法は先の行を"kwargs['label'] = unicode(condition)"にする事となる。
同様のケースがあった場合は、同様にライブラリに手を加える必要があると思われる。
[修正前]
[修正後]
参考サイト
-> Matplotlibにおける日本語について
-> nltk.FreqDist および nltk.ConditionalFreqDist の plot() で日本語を出力させる方法 - (主に)プログラミングのメモ