ディープラーニングでスリーサイズを予想
性やプライバシーの問題に対する姿勢
身体的特徴が、何らか数値化されるのは気分のいいものではありません。
しかし、実生活上、服を購入する際に、メジャーで測られるのは必須であり、私はこれがかなり苦手です。
知らない人に手で触れるのが苦手で、このプロセスを省略したいと考えています。
ディープラーニングでは素性を数値としてみなして四則演算などを計算できます(Seq2Seqで足し算引き算掛け算割り算ができる)。
こういう特性があることから、KPIの数値予想に使えることが想像できるかと思います。
実際、ドワンゴの研究ではイラストのユーザの閲覧数を深層学習で予想するなどを行っておりうまく行っているようです[1]。
数値化されて(もちろん、望まない限り行われないが原則)便利になる領域であれば、開拓する意義はあると考えています。
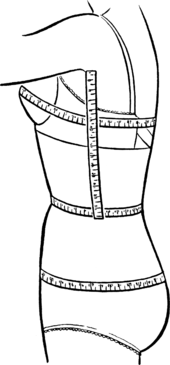
前処理1. データを集める
身体的特徴を商業的に利用しているグラビア女優に関して、予想を行います。
収集対象の女優一覧はこちらのWikipediaの一覧を用いました。
古すぎる写真だとインターネット上にデータが存在しなかったり、年代によるの文化の違いから様相が違く、うまく学習できなかったりするので、1980年台以降に生まれた方に絞っています。
収集方法は、Microsoft社のBingという検索エンジンに女優の名前をクエリに入力し、画像を集めます。スクレイパーは自分で設計したものをもちいました。
前処理2. スクレイピングで集めた必要でない写真(本人以外の写真など)を削る
途中で、大量の検索対象の方と関係のないノイズデータが含まれてしまうのですが、ニートをつかったノイズフィルタリングシステムを導入することで、この問題をクリアしました[2]
わざわざこのために、ネットワークを一個設計することになったので、結構労力必要です。

活性化関数&何を最小化するかの検討
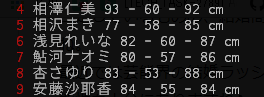
数値化されるデータはバスト80cm, ウェスト58cm, ヒップ82cmなどというデータです。
ディープラーニングで扱うにはセンチメートル表記は、大きすぎる値のため、0.0 ~ 1.0程度の値におさめている必要があります(しかし、別に超えてもいい)
そこで乱暴ですがすべての値を100.0で割ってしまうことにしました。
(B80cm, W52cm, H82cm) -> (0.80, 0.52, 0.82)
ロジットにいれるとか色々考えたのですが、100cmを超える方も存在するので、そうなると予想できなくなるので、リニアな出力に単純にmean squared errorを取りました。
検討していないアプローチですが、例えば150cm位を上限として、各パラメータをとってロジットをとってmean squared errorを取るというのもありかもしれません。
ネットワークの選択
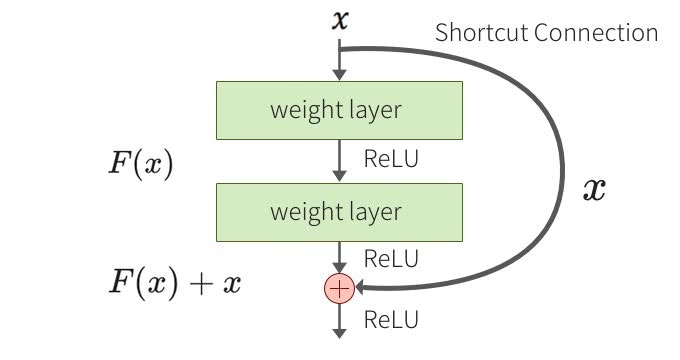
ResNetでいいでしょう。
私物のGPUなので、そんなに火力はないので、ResNet50で転移学習させました。
ResNetはResidual Networkの通り残差を学習していきます。精度や表現パターンを学習するなら、これにまさるものは今は無いように思えます。(存在するのなら知らないだけなので許してください)
学習&評価
-
学習用データセット 35000枚の写真
-
評価用データセット 4311枚の写真
MSEを学習するだけのなので、過学習にならないように注意しながらやってみましょう。
Testデータにおいて、MSEの誤差値が途中から上昇する現象が発生するはずです。そこから過学習が発生していと考えられるので、学習はそこで打ち切りです。 -
学習
デフォルトでは35000枚の写真を利用しますが、閾値を変更する場合は手動で行ってください
$ python3 deep_bwh.py --train
- テストデータによる評価
ダンプした各エポックのmodel群にたいして、誤差の累積値が最小化している点をいくつか選ぶとよいです
$ python3 deep_bwh.py --eval
未知のデータを予想してみる
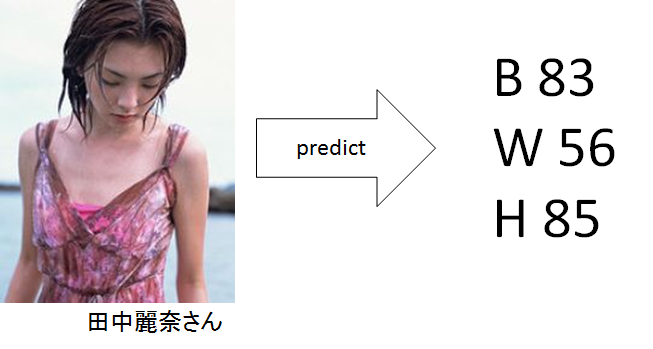
学習用データセットに含まれていらっしゃらない方で水着でメディアに露出されている方がいます。
去年、ドラマで有名になったガッキーや田中麗奈さん、上坂すみれさん、清水あいりさんを予想してみました。



独自データセットでの学習
どなたでも環境があれば学習できます。
コードはgithub上で公開しており、再配布は自由ですが商用利用はおやめください。
$ git clone https://github.com/GINK03/keras-bwh-predictor
まず、学習したい対象の画像を縮小します。
ResNetを使う場合は224x224のサイズなのでそのサイズに収まるように縦横比を維持してリサイズして、何もない画像に貼り付けます。
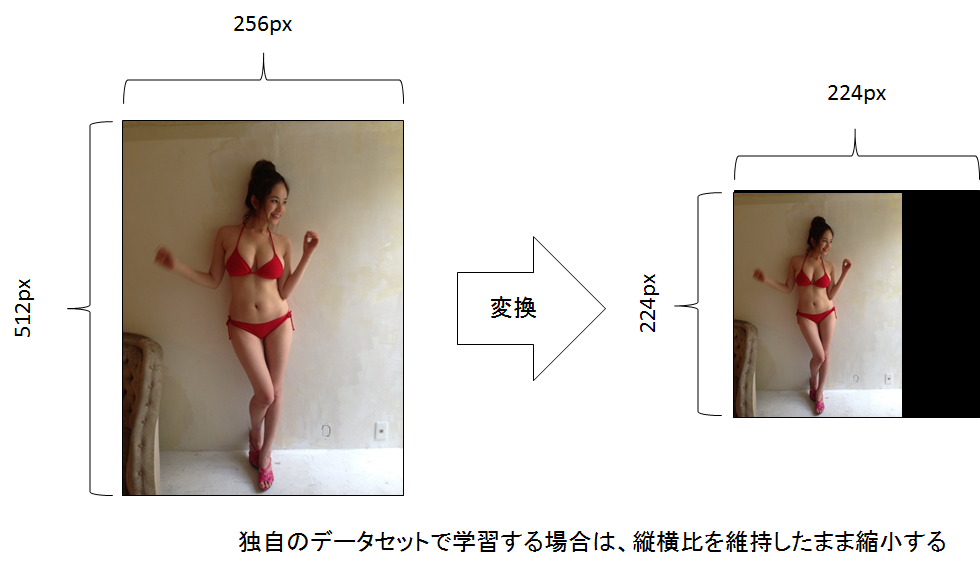
そして、特定のディレクトリに、決まった規則の名前で保存してください。(名前がスリーサイズのデータのキーとなります)
bwh.txtファイルを編集して予想したい三つのパラメータを記述します。
コードなかに、trainMaxという変数があり、学習に使うデータの最大値を決定しているパラメータがあるので、適宜編集してください。
配置が完了したら、学習です。
$ python3 deep_bwh.py --train
何回目のepochが良いか、--evalという引数で評価できます。(出力される値が少ないほどよい)
$ python3 deep_bwh.py --eval
任意の画像のbwhを予想します。予想する画像はto_predに入れておいてください
$ python3 deep_bwh.py --pred
感想
上坂すみれさんのような写真に対して反応するので、わかっているのかなと言う印象があります。
今後の改善点としてグラビアなど芸能界特有の盛る現象とかあると思うので、下着メーカや水着メーカが頑張ってきれいで膨大なデータセットを揃えてくれれば、実用の可能性はあるように思えます。
お店でメジャーで測るんじゃなくて、スマホで自撮りすると、自分のプライベートな値が管理できるようになって、ネットとかで通販ができるようになると良いですね。
参考
[1] ドワンゴ視聴数予想
[2] ディープ前処理ツールキット