はじめに
この記事は【転職会議】クチコミをword2vecで自然言語処理して会社を分類してみるの続きです。
前回は転職会議のクチコミをword2vecで自然言語処理をした結果、似ている会社や単語を調べることが出来たという内容を書きましたが、今回はその結果を可視化してみます。
注意
前回の記事にも書きましたが、今回の手法では「クチコミが残業の話をしているのは理解できるけどそれが多いか少ないか分からない」という欠陥がありました。
今回の可視化ではその欠陥を直していないのであくまで可視化サンプルとして見ていただければ幸いです。
また、前回は会社のアドベントカレンダーで書きましたが今回は個人として書きましたので、本稿の内容は所属する組織の見解とは一切関係ありません。
もくじ
- 前回学習したモデルを読み込み
- 単語と遊ぶ
- 分布図を書いてみる
- 樹形図を書いてみる
- 会社と遊ぶ
- 分布図を書いてみる
- クラスタリングして、クラスタを考慮した分布図を書いてみる
使用するもの
- Python
- Gensim
- Scikit-learn
- SciPy
前回学習したモデルを読み込み
前回の記事のここでセーブしたモデルを読み出します。
model = models.Doc2Vec.load('./data/doc2vec.model')
単語と遊ぶ① 分布図を書いてみる
分布図を書くメソッドを以下のように定義しました。
通常、単語のベクトル表現は100次元とか300次元とかでモデルに学習させます。
それを次元圧縮して2次元に落とし込んだ後に可視化を行っています。
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
def draw_word_scatter(word, topn=30):
""" 入力されたwordに似ている単語の分布図を描くためのメソッド """
# 似ている単語を求めるためにはGensim word2vecの以下の機能を利用
# model.most_similar(word, topn=topn)
words = [x[0] for x in sorted(model.most_similar(word, topn=topn))]
words.append(word)
# 各単語のベクトル表現を求めます。Gensimのmost_similarをベースとして
# 単語のベクトルを返すメソッド(model.calc_vec)を定義しています
# 長くなるので実装は本稿の末尾に記載しました。
vecs = [model.calc_vec(word) for word in words]
# 分布図
draw_scatter_plot(vecs, words)
def draw_scatter_plot(vecs, tags, clusters)
""" 入力されたベクトルに基づき散布図(ラベル付き)を描くためのメソッド """
# Scikit-learnのPCAによる次元削減とその可視化
pca = PCA(n_components=2)
coords = pca.fit_transform(vecs)
# matplotlibによる可視化
fig, ax = plt.subplots()
x = [v[0] for v in coords]
y = [v[1] for v in coords]
# 各点のクラスターが設定されていればクラスタを考慮
# エラーハンドリングは適当
if clusters:
ax.scatter(x, y, c=clusters)
else:
ax.scatter(x, y)
for i, txt in enumerate(tags):
ax.annotate(txt, (coords[i][0], coords[i][1]))
plt.show()
準備ができたところで分布図を書いてみます。
# "残業"に似てる単語を可視化
draw_word_scatter('残業', topn=40)

涙なしでは見られないような結果になってしまいました。
真ん中やや上あたりの 朝帰り, 午前様, 終電, サービス残業が集まっているエリアが特に悲惨です。さらに恐ろしいのは、そのエリアから一番遠い場所に"睡眠"がプロットされています。サラリーマンの哀愁と過労死の危険性を感じざるをえません…。
ちょっと寂しいので、ポジティブな言葉でもトライしてみます。
# "やりがい"に似てる単語を可視化
draw_word_scatter('やりがい')
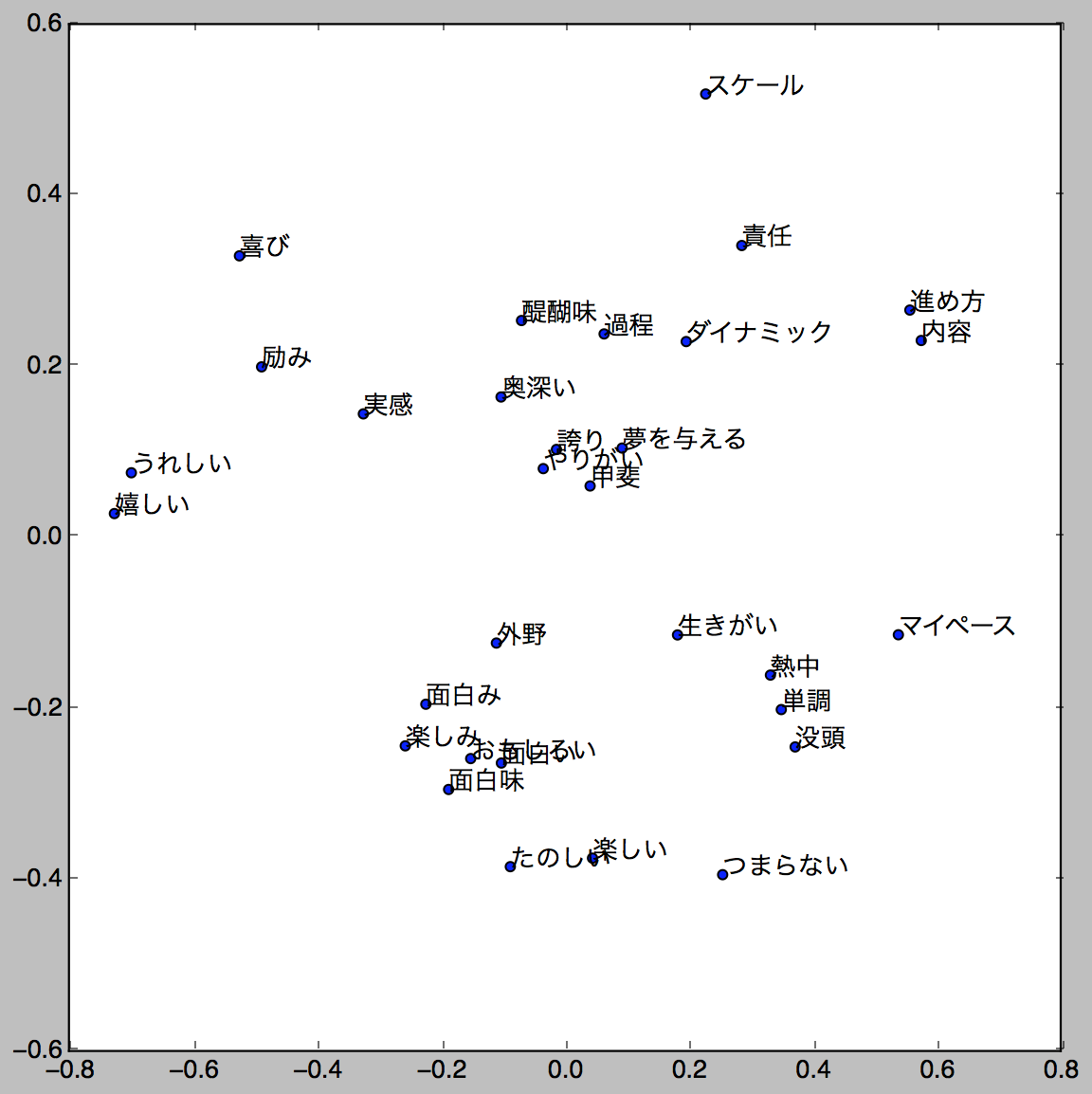
さっきの分布図とは大違い…!誇り、やりがい、夢を与える、いいですね。
ちなみに当社では共にやりがいのある仕事を成し遂げる同志を絶賛募集中です。
単語と遊ぶ② 樹形図を書いてみる
WEBサイトを運営していると、単語をグルーピングしたいことも結構あります。
個人的には、WELQやMERYがSEOで圧倒的な強さを誇った理由の一つには、タグの適切な階層化とグルーピングの影響も合ったんじゃないかと思っています。そういうことにも使えるし、あとは、リスティング広告での流入キーワードを自動で分類してランディングページ作るとかもいいですね。
ここでは、適切な階層化とグルーピングをするために樹形図を書いてみましょう。
import pandas as pd
from scipy.spatial.distance import pdist
from scipy.cluster.hierarchy import linkage, dendrogram
def draw_similar_word_dendrogram(word, topn=30):
""" 入力されたwordに似ている単語の樹形図を描くためのメソッド """
# draw_word_scatterと同じ(qiita記事用に冗長に書いてます)
words = [x[0] for x in sorted(model.most_similar(word, topn=topn))]
words.append(word)
vecs = [model.calc_vec(word) for word in words]
# SciPyの機能を用いて可視化
# Python機械学習プロフェッショナルのコードを参考にしました
df = pd.DataFrame(vecs, index=words)
row_clusters = linkage(pdist(df, metric='euclidean'), method='complete')
dendrogram(row_clusters, labels=words)
plt.show()
書いてみる。
# "残業"と似た単語の樹形図を書く
draw_similar_word_dendrogram('残業')

単語の文字が小さくて恐縮ですが、それなりに上手く樹形図が書けました。当たり前ですが、ココでも朝帰り、午前様、終電、は仲良く並んでいます。早く帰って…。
この樹形図を適切な高さの部分でカットすればグルーピングが出来ます。
会社と遊ぶ① 分布図を書いてみる
次に、会社の分布図を書いてみます。
ここでは各社の社風関係のみのクチコミから各社の分布図を書いてみましょう。似てる社風の会社見つかったら良いな、という狙いです。
既に学習したモデルを用いてベクトル表現の算出する際にGensim Doc2Vec の infer_vector という機能を利用します。ちなみにこの機能は先日の記事でもコメント頂きましたが、正直あまり精度が高いものではないです。
が、そもそも会社クチコミを処理する際にword2vecがはらむ問題に比べるとあまり大きな問題ではないと思ったため、そのまま利用しています。
まずは会社ベクトル表現の算出します。
対象は一定の口コミ数以上を持つWeb系企業としました。
# modelの読み出し
model = models.Doc2Vec.load('./data/doc2vec.model')
# 会社, クチコミデータのDBからの読み出し
companies = connect_mysql(QUERY_COMPANIES, DB_NAME)
reviews = connect_mysql(QUERY_COMPANY_CULTURE, DB_NAME)
# クチコミデータの形態素解析
# utils.stem にMeCabによる形態素解析の処理が入っている
words = [utils.stems(review) for review in reviews]
# クチコミデータから各会社のベクトル表現を算出
vecs = [models.Doc2Vec.infer_vector(model, word) for word in words]
※ utils.stemsはラーメン屋の分類の記事とほぼ同じ
ベクトル表現が算出できたので可視化してみます。
# 上記で定義したメソッドを用いて可視化
draw_scatter_plot(vecs, companies)
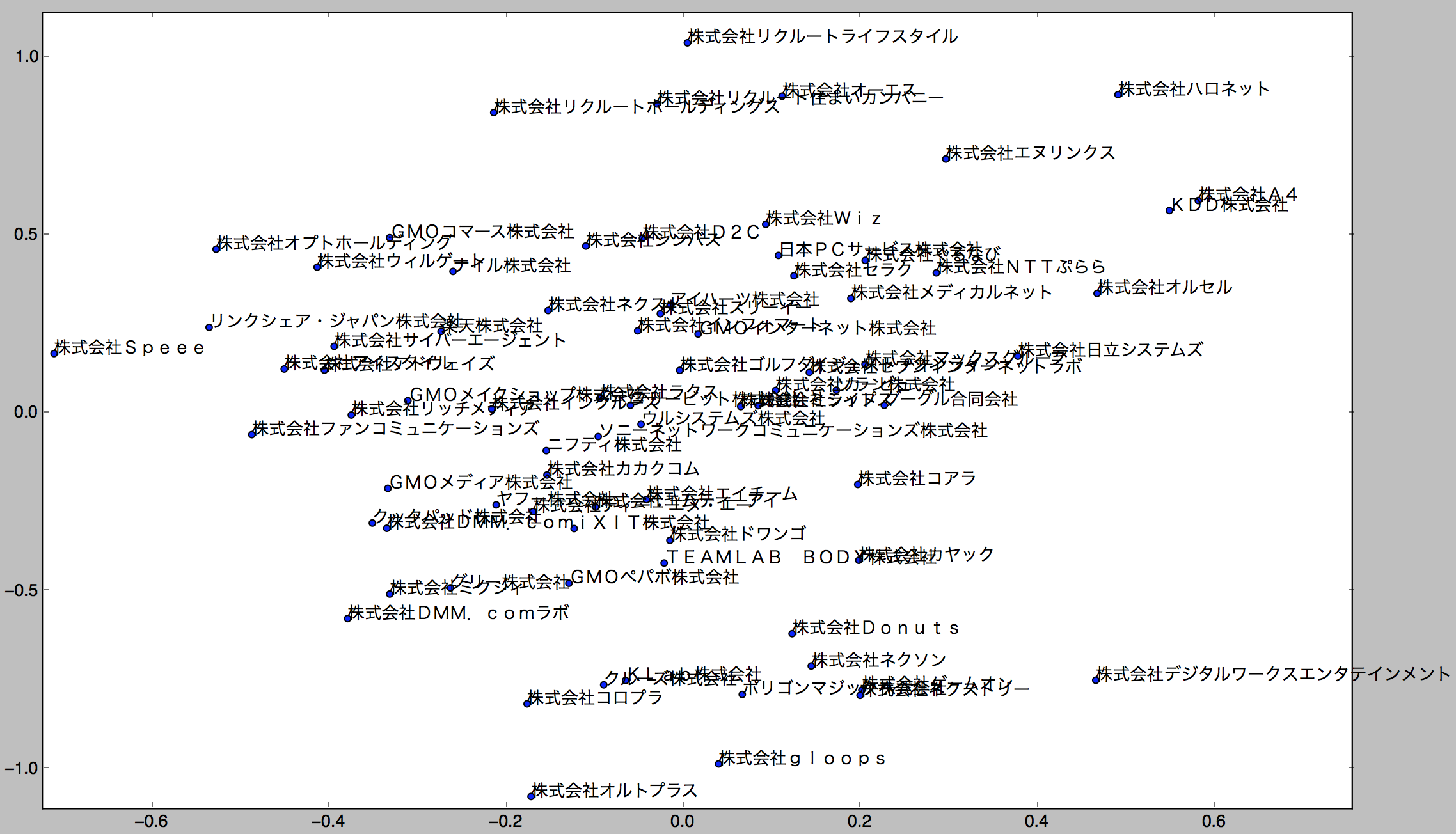
ごちゃっとしてて見にくいのですが、リクルート系列が上の方に固まってたり、下の方にゲーム系の会社が集まってたりします。
ただ、グリーとミクシィが似てる位置にあったりして、本当?ってところもあるので、word2vecおよびinfer_vectorの精度問題や、100次元ベクトルを無理やり2次元に落とし込んだ歪みが出ているのかもしれません。
会社と遊ぶ② クラスタリングを考慮して分布図を書いてみる
上に示した分布図はごちゃっとしてて見づらいものでした。
クラスタリングを行ってプロットを色付けすれば少しは見やすくなるので、各会社のクラスタを求めた上で分布図を書いてみましょう。
import pandas as pd
from sklearn.cluster import KMeans
def kmeans_clustering(tags, vecs, n_clusters):
""" K平均法クラスタリングを行うメソッド """
km = KMeans(n_clusters=n_clusters,
init='k-means++',
n_init=20,
max_iter=1000,
tol=1e-04,
random_state=0)
clusters = km.fit_predict(vecs)
return pd.DataFrame(clusters, index=tags)
クラスタリングの実行とそれを考慮した可視化
# クラスタ数は適当(いちおうエルボー法でそれなりの数は探した)
clusters = kmeans_clustering(companies, vecs, 10)
# クラスタ情報を付与して分布図をプロット
draw_scatter_plot(vecs, companies, clusters)
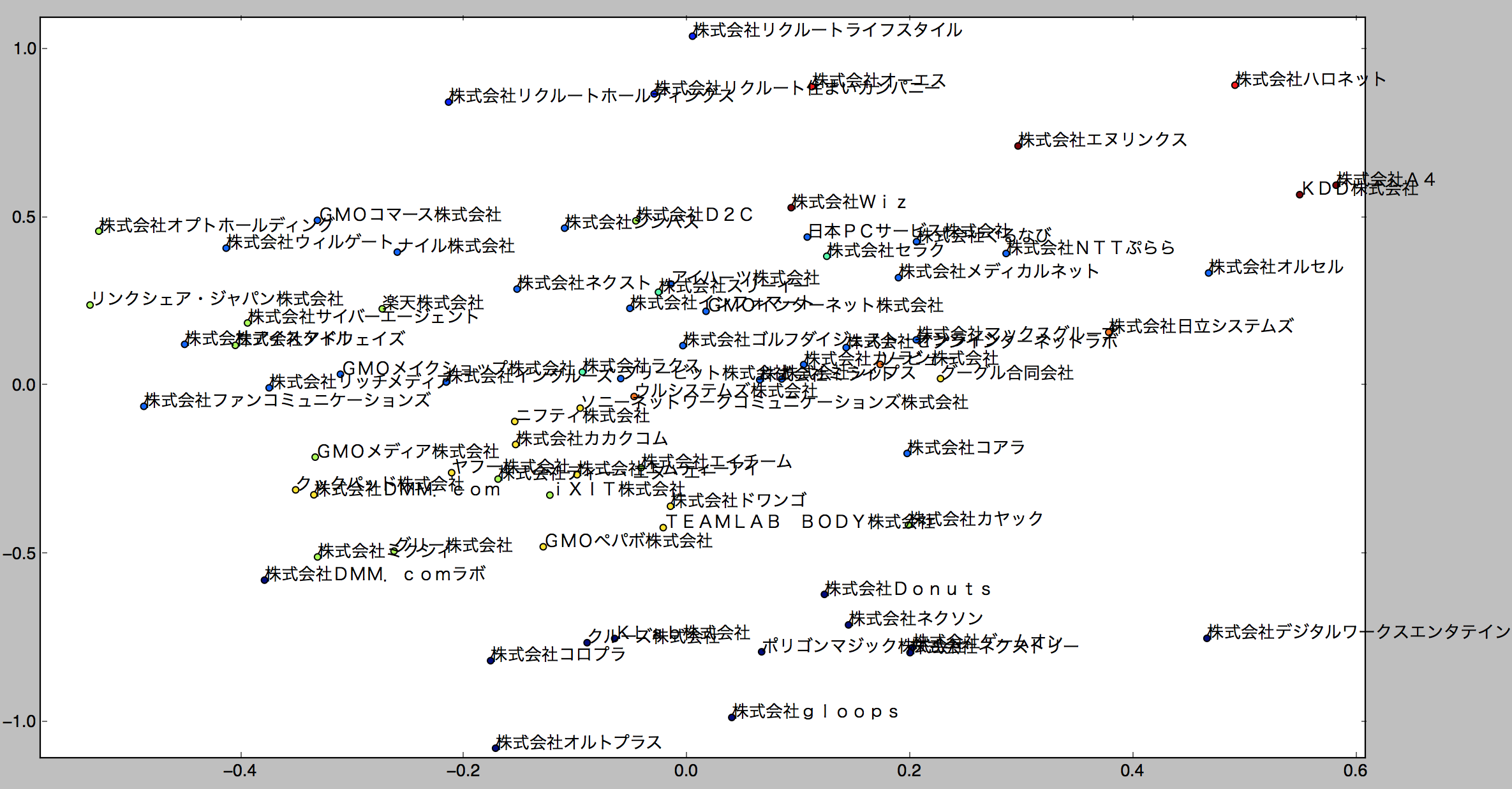
あんまり変わらないかな…。ただ、無理やり2次元に落とし込んだ歪みもある程度考慮して見れるのがメリットかもしれません。
あと、クックパッドさんとDMMさんが似た位置にあって波紋を呼びそうですが、きっと恵比寿ガーデンプレイスに同居してるから飯を食いに行く店とかも似てて、似た社風になるんだと思い、ます…(苦しい言い訳)
今回、クラスタリングの可視化がいまいちでしたが、次元圧縮の方法を変更して実施することで多少は改善できるかもしれません。PCAの部分をScikit-learnのmanifold.TSNEに変更するとか色々改善の工夫しがいはありそうです。