概要
サービスのスケールに合わせてテーブル設計を改良した話。DynamoDBのテーブル設計はあまり記事がなかったので備忘録として残しておきます。
Phase 1: ストレージの選定
億単位のユーザ行動ログを残す要件があり、ストレージの選定として残ったのがDynamoDBとMongoDB。データの特性や保守面を考慮し、今回はDynamoDBを利用することにしました。
まず初めに行動ログを蓄積するためのテーブル user_log を作成します。
- Primary key:
- Partition key: id
- Sort key: timestamp
データ構成は次のようなイメージです。
| id | timestamp |
|---|---|
| iiDMkFAE323eraijIDNZJMKDU232 | 1456473647 |
| 49DWKdkmzffh8fakefkmfeakmcfa | 1456473644 |
| 49DWKdkmzffh8fakefkmfeakmcfa | 1456473634 |
| iiDMkFAE323eraijIDNZJMKDU232 | 1456473310 |
| 49DWKdkmzffh8fakefkmfeakmcfa | 1456473013 |
Phase 2: スループットのオートスケール対応
データが1,000万超えた辺りから、ユーザのアクセスが多い時間、少ない時間帯が分かってきたので、Dynamic DynamoDB を導入してスループットのオートスケールに対応しました。
Phase 3: 検索用インデックスの追加
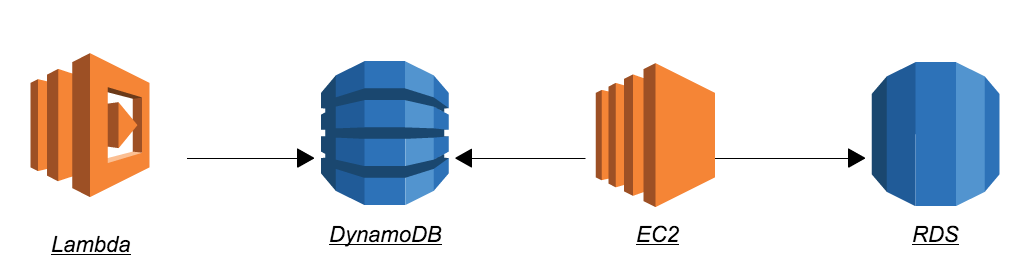
行動ログを日毎に集計する必要が出てきたので、user_log テーブルにGSIを追加。バッチ経由で集計結果をRDSに保存しました。
- Primary key:
- Partition key: id
- Sort key: timestamp
- GSI
- Partition key: date
- Sort key: timestamp
データ構成は次のようなイメージです。
| id | timestamp | date |
|---|---|---|
| iiDMkFAE323eraijIDNZJMKDU232 | 1456473647 | 20160226 |
| 49DWKdkmzffh8fakefkmfeakmcfa | 1456473644 | 20160226 |
| 49DWKdkmzffh8fakefkmfeakmcfa | 1456473634 | 20160226 |
| iiDMkFAE323eraijIDNZJMKDU232 | 1456473310 | 20160226 |
| 49DWKdkmzffh8fakefkmfeakmcfa | 1456473013 | 20160226 |
インフラ構成はこんな感じ。アプリケーションサーバが集計を行います。
Phase 4: Hot hash問題
データが3,000万超えた辺りからアクセスが集中するとCloudWatchからアラートが飛ぶように。。
The level of configured provisioned throughput for one or more global secondary indexes of the table was exceeded. Consider increasing your provisioning level for the under-provisioned global secondary indexes with the UpdateTable API
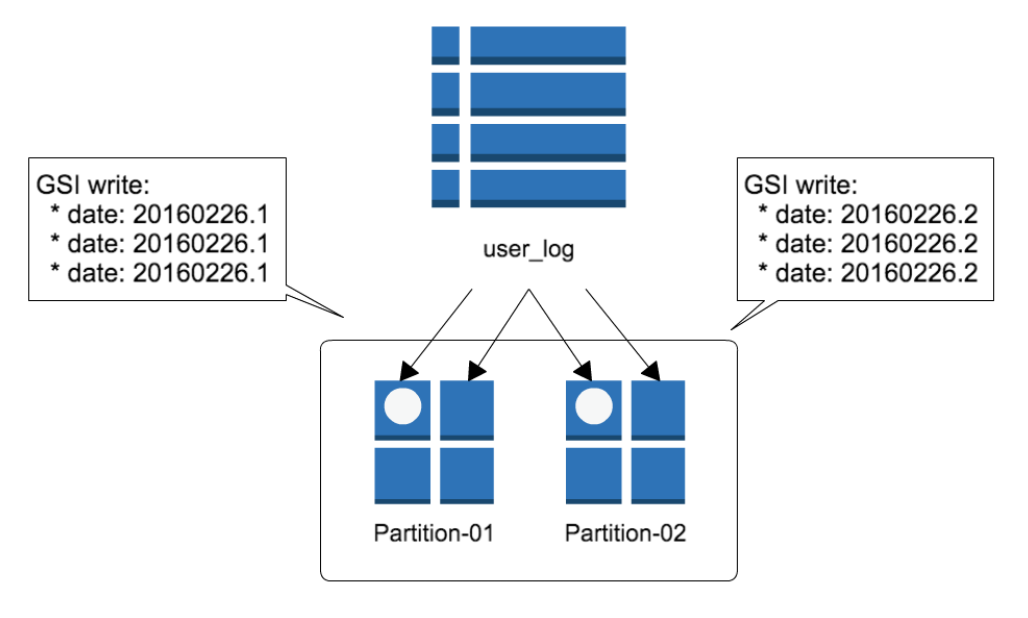
気付いたらいつの間にかデータサイズが10GB超。プロビジョニングされたスループットを超えた書き込みが発生していました。DynamoDBはデータ量が約10GBを超えると自動的にパーティションを分割するので、GSIの書き込みパーティションが1つに集中していたのが原因だったのです。

上記図で言えば、GSIの date キーによりパーティションが偏るため、Write capacity 500だと不足するのです。
CloudWatch上は Write(Read) capacity メトリクスでプロビジョニングされた閾値を超えていないように見えますが、Throttled write events を見るとスロットルが発生しまくる状態に。うーん分かりにくい。。
という訳で、書き込みが特定のパーティションに集中しないよう date キーにサフィックス 1〜10 を追加しました (この手法はAWSのページでも テーブル内のすべての項目に対して均一なデータアクセスを実現する設計 として紹介されています)。
今回、サフィックスの値はユーザの id を元にASCIIコードの除算で計算しました。
これで書き込みが並列に分散し、テーブルのスループットが全体的に向上しました。
Phase 5: テーブル分割
DynamoDBに書き込まれたデータはRDSで集計するため、集計が終われば古いログを参照することはほとんどありません。そのため、テーブルを月単位で分けるよう変更を加えました。user_log.201602 、user_log.201603 というイメージです。

毎月月末に翌月のテーブルを作成し、月初に前月テーブルのスループットを下げる (Write capacity: 1、Read capacity: 1) プログラムを加えました。これによりシステム全体のRead capacityを下げることができました。
またテーブル分割の利点として、古いログを参照する必要がなければData Pipeline経由でデータをS3に移し、テーブルをDropすることもできます (これによりDynamoDBの利用料金を抑えることが可能です)。