はじめに
Mroonga/Groongaでは、トークナイザにより文章が分割されて、分割されたトークン(語句)で転置インデックスが作成されます。
Mroonga/Groongaでは、様々な環境に柔軟に対応できるよう、多数のトークナイザが用意されています。
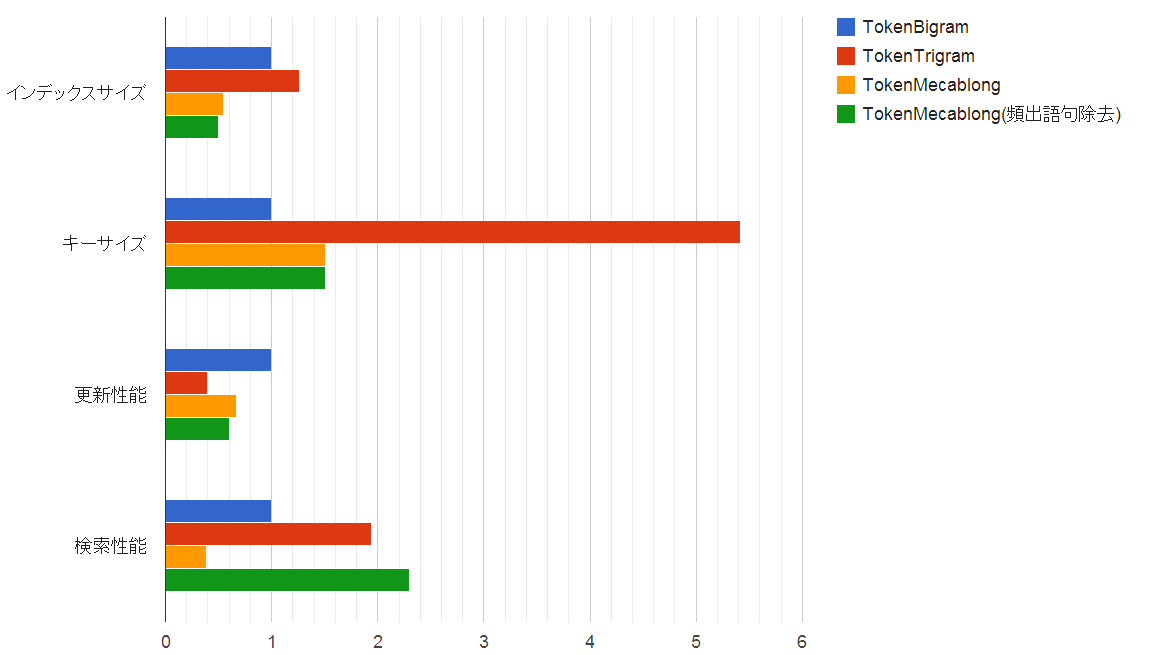
トークナイザの種別に応じて、分割ルールが異なり、転置インデックスの語句のサイズや、種別数および出現回数が異なります。
Ngramのサイズに応じたMroonga/Groongaの全文検索性能についてでは、NgramのNのサイズが大きいほど、良好な検索性能が得られることが判りました。特にTokenUnigramでは、顕著に検索性能が劣化しました。
MeCabトークナイザでは、形態素解析用辞書に応じて、様々なサイズで文章が分かち書きされます。たとえば、「今日は雨です。」という文章は、「今日/は/雨/です/。」と、分かち書きされます。「は」等の助詞は、文章中の出現頻度が極めて高く、データベース規模が大きくなるにつれて、語句の出現回数が爆発的に増えます。
このような助詞等の頻出語句は、(たいして)検索に寄与をしないにも関わらず、検索性能に大きな影響を与えます。
そこで、このような頻出語句を除去させた場合のMeCabトークナイザの全文検索性能と、頻出語句を除去させない場合のMeCabトークナイザの全文検索性能およびNgramトークナイザの全文検索性能を比較してみます。