下記論文のサーベイ記事です.
- タイトル: Generative and Discriminative Text Classification with Recurrent Neural Networks
- Deep Mindの論文
- 6 Mar 2017
- 著者: Dani Yogatama, Chris Dyer, Wang Ling, Phil Blunsom
主旨
- テキスト分類でデータの傾向が変わっても生成モデルは識別モデルより性能が落ちにくいことを実証.
要約
- 日常だとデータの傾向は流行によってデータの出現頻度とか変わるし,新たな概念とかもすぐできる.
- 傾向が変わるたびにデータセットを全て学習しなおすのは時間がかかるので,できれば新たなデータのみで学習させたい.(Continual learning)
- あと,未知のクラスであっても予測できるようにしたい.(Zero-shot leaning)
- こういったことを実現しやすいのが,どうも識別モデルより生成モデルらしいということを実証してみた.
考えるテキスト分類問題
- $x = { x_1, x_2, ..., x_T }$: $T$個の単語からなる文書
- $y \in \mathcal{Y}$: 当てたいクラスで$\mathcal{Y}$はクラスの集合
- 例: 文書$x$ = "I like coffee"がどのカテゴリ$y \in $ {Food, Animal}なのか当てる.
- 解法としては識別モデルと生成モデルに大別される.
識別モデルとは
- $y^* = \arg \max_{y \in \mathcal Y} p(y|x)$を求める方式.
- 文章$x$の言い回しや単語の専門性からカテゴリを推定する.
- ロジスティック回帰やCNNが該当
- データの傾向が変わらない場合は生成モデルより性能が良い場合が多い.
"I like chicken"がFoodとAnimalのどちらのカテゴリかを推定する場合.
\begin{align}
p(\rm{Food} \mid \rm{I}, \rm{like}, \rm{chiken}) = 0.6 \\
p(\rm{Animal} \mid \rm{I}, \rm{like}, \rm{chiken}) = 0.4
\end{align}
となってFoodの方がAnimalより高いのでFoodカテゴリと推定.(数値は適当)
識別式LSTM
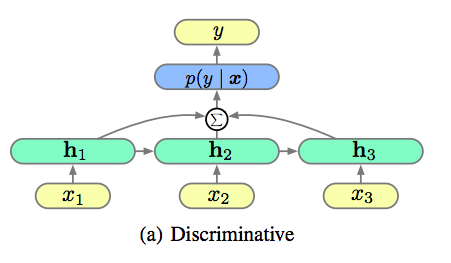
- peephole方式のLSTMを利用
- ここで$h_t$は$x_1,x_2,...,x_{t-1}$を何かの値に変換したものに対応.
- $\Sigma$は各$h_t(t=1,2,...,T)$からの出力の平均
- 最後の$h_T$だけ使って予測するより,$h_t$の平均を使ったほうが性能が良かったらしい.
識別式LSTMの例
"I like chicken"がFoodとAnimalのどちらのカテゴリかを推定する場合.
\begin{align}
\left ( p(\rm{Food} \mid \rm{I}) + p(\rm{Food} \mid \rm{I} ,\rm{like}) + p(\rm{Food} \mid \rm{I}, \rm{like}, \rm{chiken})\right) / 3 = 0.6 \\
\left( p(\rm{Animal} \mid \rm{I}) + p(\rm{Animal} \mid \rm{I},\rm{like}) + p(\rm{Animal} \mid \rm{I}, \rm{like}, \rm{chiken})\right) / 3 = 0.4
\end{align}
となってFoodの方がAnimalより高いのでFoodカテゴリと推定.(数値は適当)
生成モデルとは
- $y^* = \arg \max_{y \in \mathcal{Y}} p(x \mid y)p(y)$
カテゴリ$y$に対して文章$x$が偶然できる確率$p(x \mid y)p(y)$を求める.
この確率が最も高いカテゴリを正解だろうと推定する.
文章$x = $ "I like chicken"がFoodかAnimalのどちらのカテゴリか推定する場合を考えてみる.
\begin{align}
p(\rm{I}, like, chicken \mid Food)p(Food) &=
p(\rm{I} \mid \rm{Food}) p(\rm{like} \mid \rm{I}, \rm{Food})p(\rm{chicken} \mid \rm{I}, \rm{like}, \rm{Food})p(\rm{Food}) \\
&= 0.08 \\
p(\rm{I}, like, chicken \mid Animal)p(Animal) &=
p(\rm{I} \mid \rm{Animal})p(\rm{like} \mid \rm{I}, \rm{Animal})p(\rm{chicken} \mid \rm{I}, \rm{like}, \rm{Animal})p(\rm{Animal}) \\
&= 0.0032
\end{align}
となってFoodカテゴリと推定する.(数値は適当)
生成式LSTM
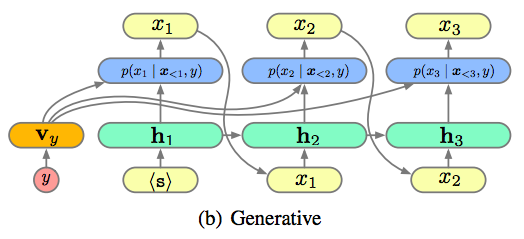
- $v_y$はカテゴリ$y$を別のベクトル空間に飛ばすためのパラメータ
生成式LSTMの欠点
- データの傾向が変わらないなら識別モデルのほうが性能は良い.
- 次に来るすべての単語の確率を求める必要があるので,識別モデルより学習に時間がかかってしまう.
- この問題を解消するよう近似計算する方法も提案されている[]が,それでも遅い.
- さらにクラスごとでもパラメータが異なるので,識別式より数十倍時間が掛かる. (その暇があれば識別式LSTMを最初から学習させれば一番性能が良くて早いのでは?とか思うけど,どうなんでしょ.)
生成式LSTM(Shared)
- ただ全部をカテゴリ$y$ごとに異なるようにしてしまうとパラメータ数が多くなるので,一部パラメータを共通にしましょうというのが生成式LSTM(Shared)
- $p(x \mid y) \propto u_{x_t}^T [h_t;v_y] + b_{y,x_t} $ ($\propto$は相似の意味)
- $u_{x_t}$と$b_{y,x_t}$は単語を予測するために必要なパラメータ
- 共有パラメータ
- Word Embedding層,
- LSTMのパラメータ$W$,
- 単語予測用パラメータ$U$
- 以降は区別が必要な場合
- クラス間での共有パラメータなしを生成式LSTM(Independent),
- クラス間での共有パラメータありを生成式LSTM(Shared)
3. 数値実験
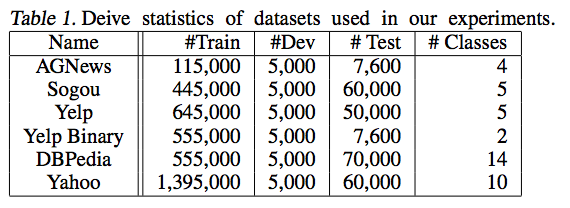
下記データセットでテキスト分類を行う.
実験して確かめたこと
- 識別式LSTMおよび生成式LSTMは従来手法に引け劣らない.
- 新規クラスのデータセットのみの学習でも生成式LSTMだと性能が劣化しづらい.
- 未知のクラス分類で生成式LSTM(Shared)だと良い性能が出た.
実験1. 従来手法との性能比較
計算量と正答率
- 理論的には線形モデルだと生成モデルは識別式より正答率が低いが証明されている(Ng & Jordan, 2001)
- 非線形モデル(例: RNN)だと証明が難しいので実証する.
実験1-A. 従来モデルとの性能評価
-
全てのデータセットを使った際の性能比較
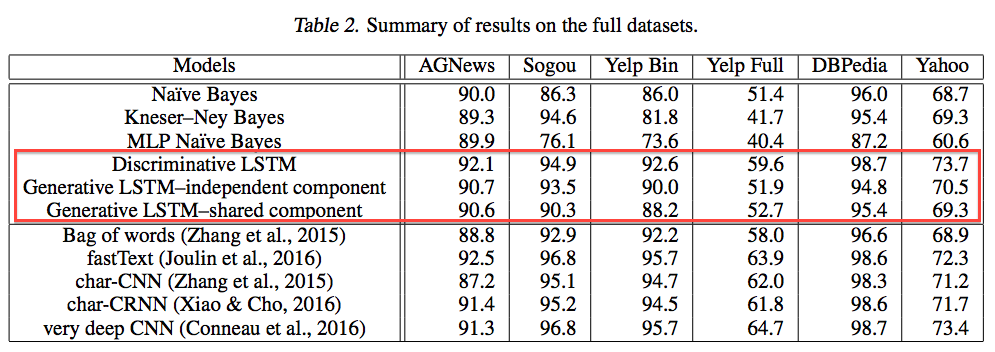
-
提案手法(赤枠)は他アルゴリズムと比べて遜色ない性能.
-
Sharedにしても性能がそんなに落ちてない.
実験1-B. 少ないデータ数での性能評価
- データセットのクラスごとのサンプル数を$5,20,100,1000$として学習.
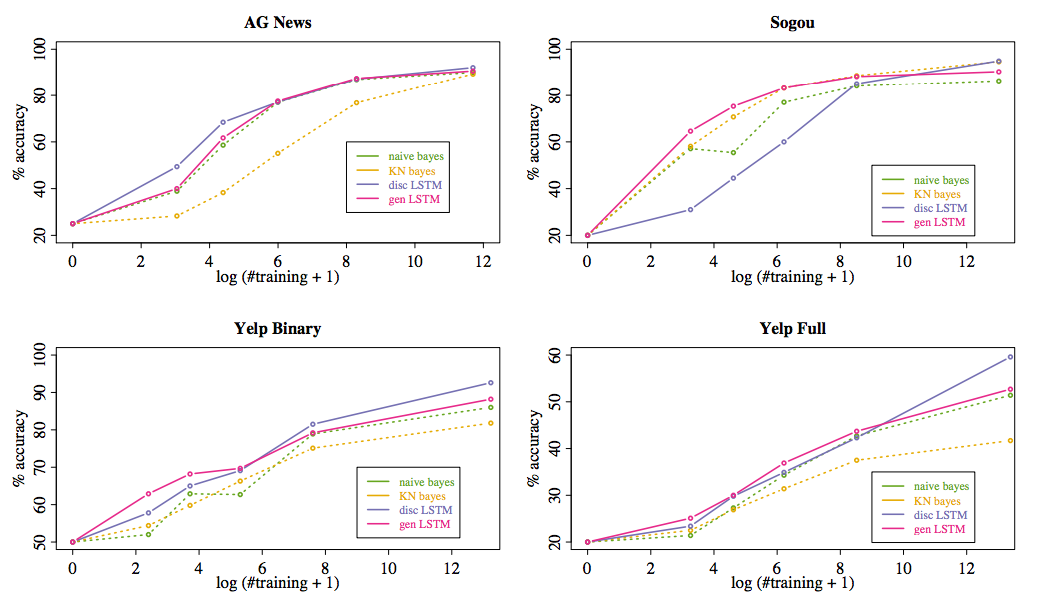
- 横軸は2の対数としたサンプル数とクラス数の積
- 小さいデータセットだと生成式LSTMの性能は他アルゴリズムよりAGNewsを除いて良い.
実験2. Continual learning
- 新規クラスデータのみ追加で学習させることで正答率が生成式LSTMと識別式LSTMでどの程度劣化するか確認.
- 実験手順としては,新規クラスとして学習させたいデータのみを除いたデータセットでまず学習.
- 次に新規クラスとして追加するデータのみで学習.
実験結果
- 識別式だと新規クラスのみ学習をしてしまうと,性能がガタ落ちてしまう
- 生成式ならそこまで落ちていない.
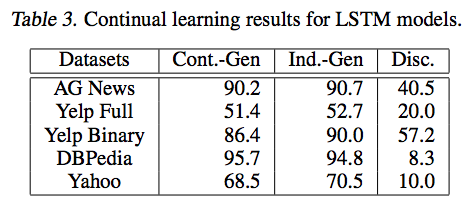
- Cont.-Gen: 最後に新規クラスのみの学習を行った方式.
- Ind.-Gen: 多分全部を学習させた場合の性能.
- Disc.: 識別式で最後に新規クラスのみの学習を行った方式.
識別式LSTM
- 識別式では新しく来たデータで過学習してしまい,性能がガタ落ちする(catastrophic forgettingっていうらしい)
- catastrophic forgettingが発生しないよう,パラメータのチューニングとか頑張ってみたけど無理でしたとのこと.
識別式だと性能がガタ落ちする理由(多分)
{I, like, chicken, dogs, drink, coffee}でクラスが{Food, Animal}の世界に{stars}でクラス{Science}が追加された場合を考える.
- 新たに"[Science]I like stars"を学習させると, $p(\rm Science \mid I, like)$の他にも$p(\rm Animal \mid I, like)$や$p(\rm{Food} \mid I, like)$でも同一パラメータを共有してしまっているので,変わってしまう.
- 逆に生成式だと$p(\rm like \mid Science, I)$となり,$p(\rm like \mid Animal, I)$や$p(\rm like \mid Food, I)$とパラメータを共有していないので,性能が劣化しづらい.
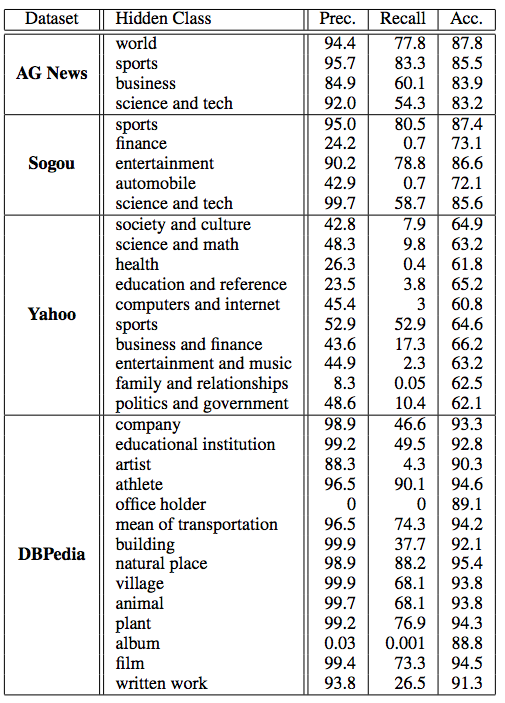
実験3: Zero-shot learning
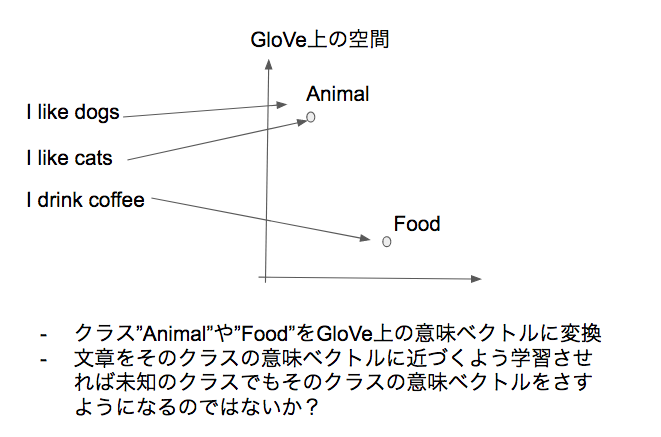
- 訓練時に含まれていないクラスの予測もできるようにしたい.
- クラス自体を当てるよう学習させるのではなくて,クラスのラベルを意味ベクトル空間上に変換した値となるだけ近づくように学習させる.
- Embedding層に関しては,既存の最適化された重みを利用.(GloVeを利用)
- 一つのクラスに複数のラベルが存在する(例: society and culture)場合は,どちらか一つのラベルを採用(例えばsociety)
- クラスの一つのデータセットを訓練データから除外して訓練させる.
- 検証時には隠されたラベルをそのモデルが予測できるか確かめる.
- GloVeによって変換されたラベルの意味ベクトル$v_y$は使っても良い.
識別式LSTMでの実験
- LSTMによって変換した文書の意味ベクトル値$\frac{1}{T} \Sigma_{t=0}^T h_t$がカテゴリ$y$のGloveでのベクトル値$v_y$となるだけ近くなるよう学習.
- $y^* = \arg \max_{y \in \mathcal{Y}} (\frac{1}{T} \Sigma_{t=0}^T h_t)^T v_y$
- このように学習させることで,未知のクラスに対するラベルとの類似度が高い文書の意味ベクトルが生成できるのではないかと考えて実験
- 結果としては,Recall: 0, Precision: 0で上手く学習できなかった.
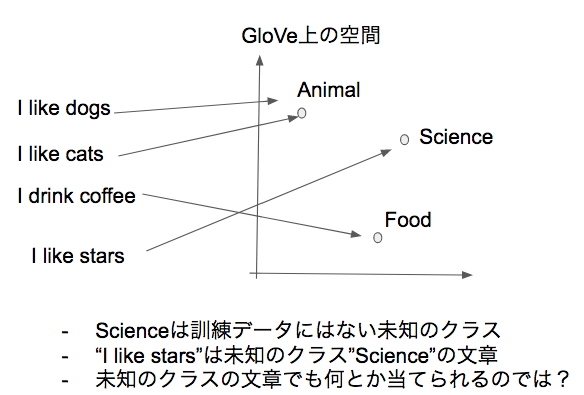
生成式LSTMでの実験
- 識別式LSTMと同様.
- クラスyの意味ベクトル空間を学習させるのではなくて,対象となるクラスのラベルのGloveでの意味ベクトル値を利用
- 生成式LSTM(Shared)だと高いrecallとprecisionで予測できた.
学習時間
- 学習にかかった時間は,下記の通りで,生成式LSTMのボトルネックはSoftmaxの計算部分.(全部の単語の確率とか求めているため.)
- Softmax部分を近似する方法も考えられているが,それでも識別式LSTMの方が早いらしい.
| サンプル数 | 生成式LSTM | 識別式LSTM |
|---|---|---|
| 115,000 | 2時間 | 20分 |
| 1,395,000 | 2日 | 6時間 |
データの分布
- 生成モデルだと文章$x$の生成確率$p(x) = \Sigma_{y \in \mathcal Y} p(x \mid y)p(y)$は簡単に導出可能
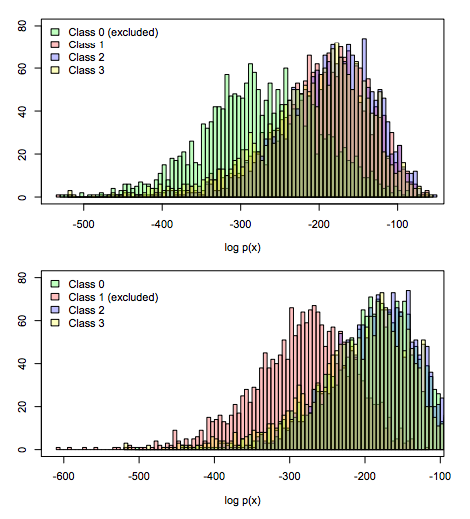
- このことを利用してAG Newsの一つのクラスを訓練データには含めずに学習させて,各クラスの$p(x)$を求めてみたら明らかに分布に違いがでた.
- これを使えば未知のクラスが含まれているかどうかは割りと分かりそう.
まとめ
- テキスト分類で生成式LSTMは識別式LSTMよりデータの傾向が変わっても性能が落ちづらいことを実証
- 新規データセットのみの学習でも生成式LSTMだとそこまで性能が落ちない.
- 生成式LSTMなら未知のクラスも予測できた.