2014年10月からTreasure Dataでソフトウェアエンジニアをやっている中村です。前職ではテクニカルアーキテクトをやっていました。Ruby、OSS方面では、なひ、NaHiと名乗っています。
Treasure Dataでは、お客様からお預かりしたデータを処理する各種サーバのイベントデータをTreasure Data自身に入れており、定期的、またはアドホックにクエリを走らせて、結果を各種基幹システムに反映させています。今回その一部機能として、社内向けにTreasure DataとSalesforce.comとのつなぎ込み部分を開発したのでご紹介します。一般には未公開で使えない機能を紹介するという、現時点では立ち位置の不明な記事ですが、今後遠くないうちに使えるようになると思うのでご容赦ください。
Salesforce.com連携機能の位置づけ
Treasure Dataの提供する価値は3つあります。
- Treasure Dataにはデータ発生のタイプに応じたデータ取り込み方法があり、大容量データ資産の行き先に悩まずに済みます。
- 取り込んだデータを動的に型付けされるテーブルとして、様々なインターフェース経由で効率的にSQL分析でき、お客様ビジネスのためのデータ解析要件・その変化に柔軟に追従します。
- 分析結果はTreasure Data内に書き戻してさらなる分析に利用する以外に、BIツールと連携して可視化する、外部システムに書き出すことにより、分析から得られた知見を多様な方法で利活用できます。
利活用とかいいだすと、アーキテクトっぽいですね。
さて今回Salesforce.com連携として拡張したのは、このうち2と3の部分です。以下の図では赤字でそれぞれ、Apex client library、SFDC Result Outputというコンポーネント名で描かれています。
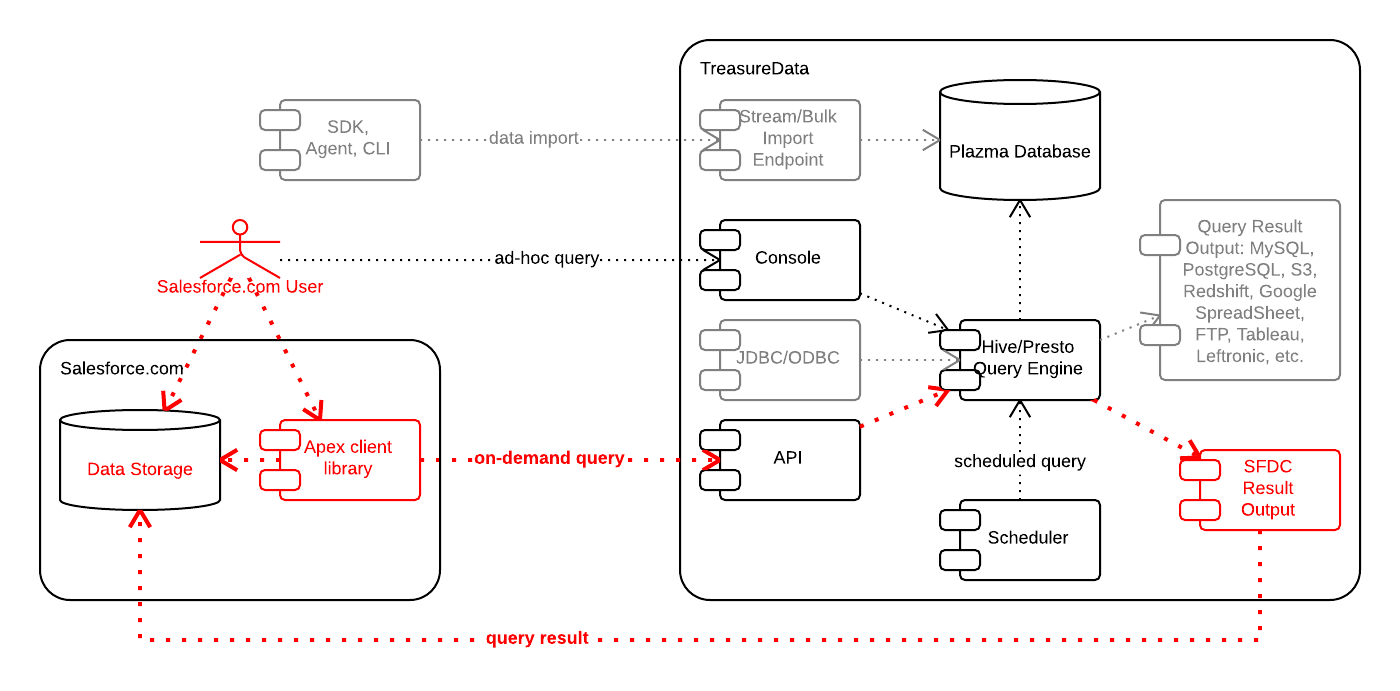
以下それぞれご紹介します。
Apex client library
Treasure DataのAPIでは、SQLクエリの発行に加えて、テーブルの管理やクエリ実行状態、履歴の参照などの機能も提供されています。これら機能を、Salesforce.comのPaaS基盤用プログラミング言語であるApexから利用できるようにしたのがApex client libraryです。以下のように認証、クエリ実行、状態取得機能を提供します。
TDAPI api = new TDAPI();
api.login('nahi@example.com', 'password');
String query = 'SELECT time, user_id, client_ip, uri, referrer_uri FROM sfdc_event_log_files WHERE event_type = \'URI\' and ...';
String jobId = api.issuePrestoQuery(query, 'sfdc_org', null); # issueHiveQuery() for Hive
System.debug(api.getJob(jobId));
# => TDJob:[jobId=18958486, status=success, database=sfdc_org, duration=1,
# startAt=2014-12-24 21:24:13, endAt=2014-12-24 21:24:14, resultSize=20,
# url=http://console.treasuredata.com/jobs/18958486, ...]
Salesforce.comのApexには、マルチテナントならではの実行時間制限(正確には計算リソース利用制限)があるため、高速レスポンスのPrestoを利用した場合でも、必ずしもクエリが終了するまで待てるとは限りません。そのため必要であれば、jobIdをブラウザ、もしくはSalesforce.comオブジェクトに格納し、非同期で終了確認をする必要があります。この辺は各種Apexテクニックが必要なところなので、いずれApex client libraryの一部として提供してもいいかもしれませんね。
今のところ、内部では特に難しいことはしていません。HttpRequestインスタンスを適切に初期化し、レスポンスをJSON.deserializeUntyped()で解析した後、モデルオブジェクトにセットして返します。Test.setMock(HttpCalloutMock.class, mock)で単体テスト。
SFDC Result Output
上記サンプルでは、Treasure Dataに対するクエリ結果は一旦Treasure Data内に保存されています(issuePrestoQuery()の意味深な第三引数nullがそれを表しています)。この結果を取得するには、getJob()の結果に含まれるURL、ここではhttp://console.treasuredata.com/jobs/18958486(HTTPSにリダイレクトされます)にアクセスして、ブラウザまたはコマンドラインツールでCSV/TSV/JSON形式でダウンロードすることになります。
従来はここで、BIツールに連携したり、Redshift、PostgreSQL、MySQLのURLを指定して書き出すところですが、SFDC Result OutputはSalesforce.comのオブジェクトとして書き出すことを可能にします。同じようにクエリを発行し、結果をSalesforce.comのOrgAccess__cカスタムオブジェクトに書き込むコードが以下です。TDSFDCResultTargetクラスと、認証のためSalesforce.comのセッションIDを使います。
(追記: 必ずしもSalesforce.com側からpullする必要はなく、この例のような静的なクエリであれば、Queryを上図の"scheduled query"として事前登録しておけば、定期的にpushされます。条件部分等、クエリを動的に組み立てる必要がなければそちらを使ってください < 構成ミス)
query = 'SELECT TD_TIME_FORMAT(time, "yyyy-MM-dd\'T\'HH:mm:ss\'Z\'", "UTC") AS Time__c, ' +
'user_id AS User__c, ' +
'client_ip AS ClientIp__c, ' +
'uri AS Uri__c, ' +
'referrer_uri AS ReferrerUri__c ' +
'FROM sfdc_event_log_files WHERE ...';
TDSFDCResultTarget target = new TDSFDCResultTarget('OrgAccess__c', UserInfo.getSessionId());
jobId = api.issueHiveQuery(query, 'sfdc_org', target.toResultUrl());
しばらく待つと、OrgAccess__cオブジェクトにクエリ結果が追記されます。
連携はSalesforce.comのBulk APIをJavaから叩いています。上記はオブジェクトに対するレコード追記ですが、target.mode = 'truncate';とすると、全オブジェクトを一旦消してから書き込みます。この削除実装がつらかった。。。target.hardDelete = trueやtarget.concurrencyMode = 'serial'もあります。Lockでハマったことのある人ならわかるでしょうか。残念ながら汎用に作ってあるので、親オブジェクトごとにソートするような機能はありません。
まとめ
開発したSalesforce.com連携機能は、型付き、宣言的データ管理(およびアプリ)プラットフォームSalesforce.comと、ビッグデータ解析フレキシブルプラットフォームTreasure Dataをつなぎ、これまで捨てられていたデータ資産の利活用を助けます。まだ未公開ですいません。
おまけ: Event Log Files
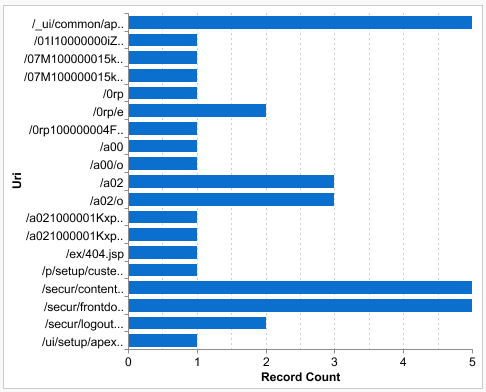
本記事のサンプルで出てきた'sfdc_event_log_files'とはなんでしょうか。"Event Log Files"はSalesforce.comのWinter '15(年3回リリースの最新版)で公開された機能で、Salesforce.comの各種アクティビティログを取得できるようになったものです(従来は取得できず、監査ログ要件のためのカスタム開発が必要でした)。今回これをTreasure Dataに取り込んでサンプルに使っています。例にしたクエリは直近のページアクセスログをフィルタしてからSalesforce.comに書き出しており、これを元にURI別アクセス頻度レポートを作るとこんな感じ。蓄積データが少なくて貧相ですね。/a02はSFDC Result Outputの連携先オブジェクト。
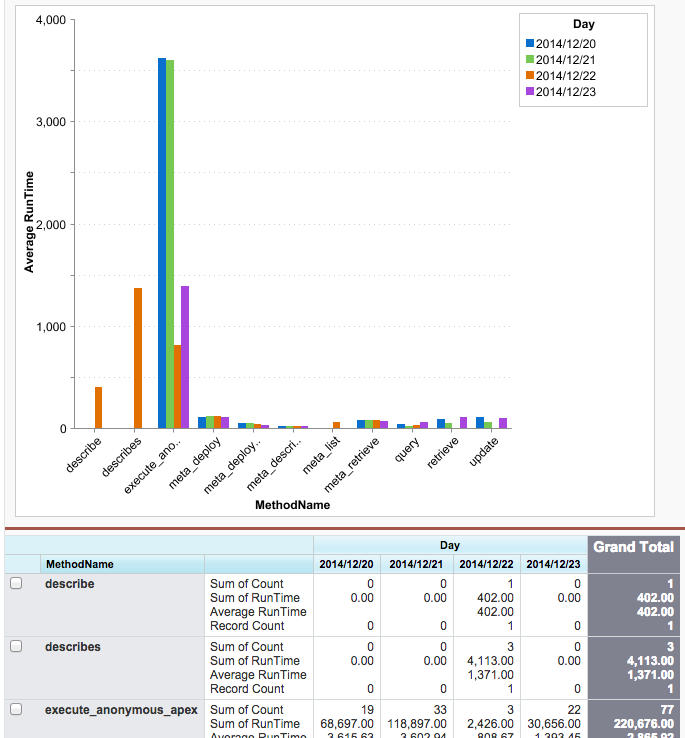
もう少し凝ったやつで、APIタイプ・日付別平均レスポンス時間。メタAPI意外に速い。
Treasure Dataに投げるHiveクエリ。
String query = 'SELECT TD_TIME_FORMAT(time, "yyyy-MM-dd\'Z\'", "UTC") AS Day__c, ' +
'method_name AS MethodName__c, ' +
'count(1) AS Count__c, ' +
'avg(cast(run_time AS bigint)) AS RunTime__c ' +
'FROM sfdc_event_log_files ' +
'WHERE event_type = "API" AND ' +
'TD_TIME_RANGE(time,TD_TIME_ADD(TD_SCHEDULED_TIME(), "-7d" ), TD_SCHEDULED_TIME()) ' +
'GROUP BY TD_TIME_FORMAT(time, "yyyy-MM-dd\'Z\'", "UTC"), method_name';
最初のアクセスログの例では、いくら毎日洗い替えするデータとはいえ、実際には1週間分のアクセスログ全体を連携するとSalesforce.com組織のデータストレージが足りません。適宜URLでフィルタするか、Treasure Data側で分析し終えてから5分おきに結果をSalesforce.comに書き出し、のほうが向いているかもしれません。データ連携する場合、ビッグデータの分析をどこで止めておくか、なかなか悩ましいところです。
また、ダウンロード可能なEvent Log Filesはどんどん消えていくので、定期的に取り込んでいかないといけません。この辺、「Treasure Dataの提供する価値」で書いた1のデータ取り込み機能拡張として作るつもりだったんですが、残念ながら別途開発中のデータ取り込みインフラが間に合いませんでした。またいずれ。