Haskell で Web スクレイピングしてみたらすごく楽しかったのでご紹介します.
Scalpel
Scalpel は Haskell のスクレイピングライブラリです.
著名なパーサコンビネータである parsec に影響を受けており, 宣言的・モナディックにスクレイピングスクリプトを書くことができます.
本記事では, Scalpel でのスクレイピングの実装例を紹介しながら, モナディックな記述の裏側, Alternative, MonadPlus 型クラスを利用した解析器の仕組み を説明したいと思います.
スクレイピングしてみる (基本編)
弊社の Qiita AdventCalendar の投稿一覧をスクレイピングしてみましょう.
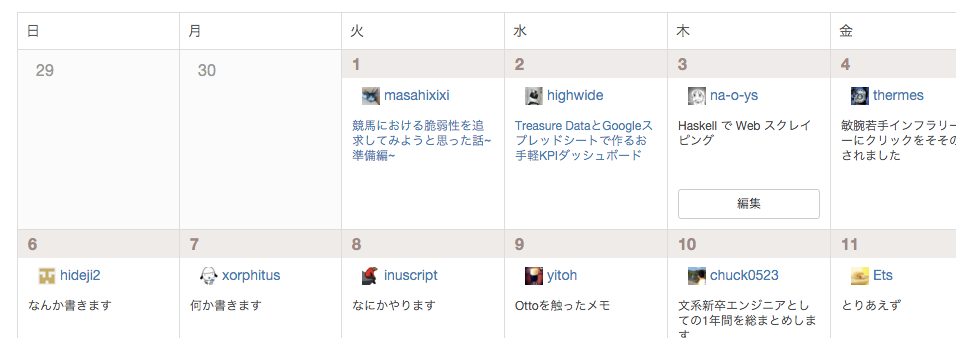
スクレイピング結果例
こんな感じの結果を得ようと思います.
Just [
masahixixi: 競馬における脆弱性を追求してみようと思った話~準備編~ (http://qiita.com/masahixixi/items/e6d5eaa3bd6efbf926aa),
highwide: Treasure DataとGoogleスプレッドシートで作るお手軽KPIダッシュボード (http://qiita.com/highwide/items/9a75428e8e8bda0325db),
na-o-ys: Haskell で Web スクレイピング,
...
]
DOM 構造
カレンダーのアイテムは投稿済み/未投稿によって二通りの構造をしています.
投稿済みアイテム
<div class="adventCalendarItem">
<div class="adventCalendarItem_author">
{author}
</div>
<div class="adventCalendarItem_entry">
<a href="{url}">
{title}
</a>
</div>
</div>
未投稿アイテム
<div class="adventCalendarItem">
<div class="adventCalendarItem_author">
{author}
</div>
<div class="adventCalendarItem_comment">
{comment}
</div>
</div>
投稿済みアイテムからは (author, url, title) を, 未投稿アイテムからは (author, comment) を取得したいと思います.
スクレイパーの実装
まずはカレンダーのアイテムを表す型 Item を定義します.
type Author = String
type Title = String
type URL = String
type Comment = String
data Item
= SubmittedItem Author Title URL
| UnsubmittedItem Author Comment
DOM 構造に準じて, Item を (Author, Title, URL) を持つ SubmittedItem, または (Author, Comment) を持つ UnsubmittedItem で定義します.
続いて, スクレイパー部分を実装します.
items :: Scraper String [Item]
items = chroots ("div" @: [hasClass "adventCalendarItem"]) item
item :: Scraper String Item
item = submittedItem <|> unsubmittedItem
submittedItem :: Scraper String Item
submittedItem = do
author <- text $ "div" @: [hasClass "adventCalendarItem_author"]
title <- text $ "div" @: [hasClass "adventCalendarItem_entry"] // "a"
url <- attr "href" $ "div" @: [hasClass "adventCalendarItem_entry"] // "a"
return $ SubmittedItem author title url
unsubmittedItem :: Scraper String Item
unsubmittedItem = do
author <- text $ "div" @: [hasClass "adventCalendarItem_author"]
comment <- text $ "div" @: [hasClass "adventCalendarItem_comment"]
return $ UnsubmittedItem author comment
使っている関数の簡単な説明です.
- chroots
- 選択したタグをルートとした DOM ツリーを子スクレイパーに渡す
- <|>
- 2 つのスクレイパーを結合する
- texts, attr
- 選択したタグのインナーテキスト / 属性を取り出す
items は chroots 関数によって「"adventCalendarItem" クラスを持つ DIV タグ」を全て検索し, それをルートとした DOM ツリーを子スクレイパー item に渡します.
型 Scraper String [Item] は 「String をスクレイピングして Item のリストを生成しますよ」 という意味です.
item では, 二つのスクレイパー submittedItem と unsubmittedItem を演算子 <|> で結合しています.
演算子 A <|> B によって, 「まず A でスクレイピングし, 失敗したら B でスクレイピングする」 という機能を実現しています.
submittedItem, unsubmittedItem では, タグのインナーテキストを取り出す text 関数 と, タグの属性を取り出す attr 関数 を使って, ほしい情報を取り出しています.
Scraper str は Monad のインスタンスなので, 上記のように do 構文でつなぐことができます.
動くコードの全体像はこちらです.
https://gist.github.com/na-o-ys/b491ca3939acefb51a39#file-calendar-hs
スクレイピングしてみる (発展編)
続いて, AtCoder の提出履歴をスクレイピングしてみましょう. 先ほどの例よりも複雑な処理が必要となります.

スクレイピング結果例
AcSubmission {
createdTime = "2015/11/25 15:38:16 +0000",
title = "D - 語呂合わせ",
user = "na_o_ys ",
language = "C++14 (Clang++ 3.4)",
score = "100",
sourceLength = "1400 Byte",
status = "AC",
execTime = "35 ms",
memoryUsage = "932 KB"
},
...,
FailedSubmission {
createdTime = "2015/11/25 14:36:25 +0000",
title = "C - 数列ゲーム",
user = "na_o_ys ",
language = "C++14 (Clang++ 3.4)",
score = "0",
sourceLength = "1019 Byte",
status = "WA"
},
...
DOM 構造
カレンダーの例と同じく, Accepted / Failed で二種類の DOM 構造があります.
Accepted に存在する実行時間, メモリ使用量の TD タグが Failed には存在しません.
Accepted の場合
<tr>
<td> {投稿日時} </td>
<td> {問題名} </td>
<td> {ユーザ名} </td>
...
<td> {状態} </td>
<td> {実行時間} </td>
<td> {メモリ使用量} </td>
</tr>
Failed の場合
<tr>
<td> {投稿日時} </td>
<td> {問題名} </td>
<td> {ユーザ名} </td>
...
<td> {状態} </td>
スクレイパーの実装
DOM 構造に準じて型 Submission を定義します. (簡単のために AcSubmission は user, execTime (実行時間) を, FailedSubmission は user のみを持つものとします.)
data Submission
= AcSubmission {
user :: String,
execTime :: String
}
| FailedSubmission {
user :: String
}
続いて, スクレイパー submissions, submission を定義します.
submissions :: Scraper String [Submission]
submissions = chroots "tr" submission
submission :: Scraper String Submission
submission = acSubmission <|> failedSubmission
acSubmission, failedSubmission はどのように実装すれば良いでしょうか. DOM 構造を見ると分かる通り, Accepted/Failed には TD タグの個数以外に違いがありません.
Scalpel ライブラリでは attribute の有無について条件付けを行うことはできますが, 選択結果の個数やインナーテキストの内容で条件付けを行う機能は用意されていません.
自作してみましょう!
先立って型クラス Alternative, MonadPlus を理解することで, スクレイピングの成功/失敗を自由に制御できるようになります.
Alternative / MonadPlus
データ型定義 にある通り, Scraper は型クラス Alternative, MonadPlus のインスタンスです. これらの型クラスが スクレイピングの成功/失敗 や <|> によるスクレイパーの結合 を表現する上で本質的な役割を担っています.
Alternative
Alternative 型クラスでは関数 empty, <|> が提供されます.
class Applicative f => Alternative f where
empty :: f a
(<|>) :: f a -> f a -> f a
これらは以下の制約 (laws) を満たすことが要求されます.
empty <|> x = x
x <|> empty = x
このように, 演算子 <|> は引数のうち一方が empty であれば他方を返します.
型 Scraper においては, empty をスクレイピングの失敗とみなす ことで, 演算子 A <|> B によるスクレイパーの結合「まず A でスクレイピングし, 失敗したら B でスクレイピングする」を表現しています.
参考: 9.4 Other monoidal classes: Alternative, MonadPlus, ArrowPlus | Typeclassopedia
MonadPlus
"スクレイピングの失敗" の正体が型クラス Alternative で提供される empty であることが分かりました.
実は empty は, Scraper モナドの bind チェイン (という言い方が正しいのか分からないですが) 内で引き継がれるという性質を持っています.
Scraper が属するもう一方の型クラス, MonadPlus の定義を追うことでその理解が容易になります.
MonadPlus 型クラスでは関数 mzero, mplus が提供されます. 今重要なのは mzero です.
class Monad m => MonadPlus m where
mzero :: m a
mplus :: m a -> m a -> m a
mzero は次の制約を満たすことが要求されます.
mzero >>= f = mzero
v >> mzero = mzero
<|> の場合とは逆に, bind の左右どちらか一方でも mzero であれば, 結果は mzero になります.
型 Scraper のインスタンス宣言では, mzero = empty と定義されています.
つまりスクレイパーの実装においては, do 構文中の ある一箇所で empty が返っていれば, その他の演算内容に関わらず empty が返る ということが分かります.
再び実装
リストの要素数をチェックして, 一致していなければ失敗させる関数 nItems を定義してみます.
要素数が合っていれば引数の Scraper をそのまま返し, 違っていれば empty を返します.
nItems :: Int -> Scraper s [a] -> Scraper s [a]
nItems n scraper = do
items <- scraper
if length items == n
then return items
else empty
関数 mfilter を使うと nItems をよりシンプルに定義できます.
nItems :: Int -> Scraper s [a] -> Scraper s [a]
nItems n = mfilter ((==n) . length)
この関数 nItems を使って, スクレイパー acSubmission, failedSubmission を次のように定義できます.
acSubmission :: Scraper String Submission
acSubmission = do
cols <- nItems 10 . texts $ "td"
return AcSubmission { user = cols !! 2, execTime = cols !! 7 }
failedSubmission :: Scraper String Submission
failedSubmission = do
cols <- nItems 8 . texts $ "td"
return FailedSubmission { user = cols !! 2 }
acSubmission, failedSubmission は TD タグがそれぞれぴったり 10 個 / 8 個でなければ nItems が empty を返すため, スクレイピングに失敗します.
解説したコードの全体像: https://gist.github.com/na-o-ys/b491ca3939acefb51a39#file-atcoder-hs
まとめ
Haskell / Scalpel を使うことで, 宣言的でシンプル・モナディックなスクレイピングスクリプトを実装できることが分かったと思います.
僕は不勉強ですが, Alternative や MonadPlus を使って解析器の結合, 成功/失敗を表現するテクニックは, Haskell の代表的なパーサコンビネータである parsec でも駆使されているようです.
みなさんも Web スクレイピングに Haskell を取り入れてみては如何ですか?