はじめに
こんにちは、コピペデータサイエンティストです。
3年ぐらい前に「ラーメンと自然言語処理」というおちゃらけLTをしたのですが、今見ると恥ずかしいぐらいショボいので、Pythonで作りなおしてみました。
長くなったので3行でまとめると
- Web上に転がっている口コミとか紹介文を
- Pythonのライブラリを用いて解析することで
- 好きなラーメン屋に似たラーメン屋を見つける手法を構築した
方法
統計的潜在意味解析という手法を用います。ざっくり言うと、文書がどんなトピックを持っているか、何に関する文書なのか、を推定してくれるものです。
以下の様なイメージで各トピックに割り振られる割合を算出できるため、以下の例ではAとBが近い、ということを計算することが可能です。
- ラーメン屋A: [0.75, 0.15, 0.10]
- ラーメン屋B: [0.60, 0.15, 0.15]
- ラーメン屋C: [0.05, 0.25, 0.70]
上記のような使い方ではありませんが、以下の適用事例や書籍が参考になるかと思います。
- SmartNewsさん: LDAを用いたニュース記事の分類
- 太宰治の文学の変化をTopic Modelで分析
- [トピックモデルによる統計的潜在意味解析] (http://www.amazon.co.jp/dp/4339027588)
主に使うもの
おおまかな流れ
かなり長くなってしまったので、
最初におおまかな全体の流れを列挙しておきます。
- 口コミ等の文書データ準備
- ゴニョゴニョして準備する(略)
- MeCabで分かち書きしておく
- 分類器の学習準備
- 1.で準備したデータから
- 単語リスト(dictionary) 作成
- TFIDFコーパス 作成
- 1.で準備したデータから
- 分類器学習: gensimでLDAモデルを学習
- 店の分類: 学習済み分類器に文書データを通してトピック分け
- 似ている店を探す
- 店ごとのトピック分け結果から類似度を計算
- 類似度が高い順に似ている店と判定する
ここから実際に作業していきます
1. 口コミデータ準備
# 収集した文書データの読み込み
from io_modules import load_data # 自作のDB読み込みライブラリ
rows = load_data(LOAD_QUERY, RAMEN_DB)
# 参考記事のstem関数で語幹を抽出
from utils import stems # 参考記事の実装ほぼそのまま
docs = [stems(row) for row in rows]
"""
docs = [
['大盛り', '感想', '方面', 'ベスト', 'ラーメン', ...
['ラーメン', '行列', '寒い', '熱々', '喜び', ...
...
]
"""
- 全体として
- 単なる前処理
- 分かち書きした大量の口コミ/紹介文(数万〜数十万件)を準備します
- 全文書に数回しか出てこないレアな単語を削除すると言った作業も行います
- 語幹の抽出: この記事を参考に
- 備考
- 分かち書きのためにラーメン用の辞書を準備しました
- なくても動くけど、あったほうがキレイな結果になったので
- 分かち書き→カウント→出現頻度の高い単語を2000個抽出
- 高い安いといった値段に関することや、店がきれい/汚いといった味に関係ないことを省きました
- 分かち書きのためにラーメン用の辞書を準備しました
2. 事前準備
ここから、実際にgensimを用いてLDAを行っていきます。
まずはgensim用の辞書やコーパスの作成を行います。
gensimのロード
from gensim import corpora, models
辞書の作成
ややこしいですがMeCabで分かち書きするのに使うユーザー辞書ではなく、gensimが文書中の出現単語と単語IDをマッピングするためのものです。
dictionary = gensim.corpora.Dictionary(docs)
dictionary.save_as_text('./data/text.dict') # 保存
# gensim.corpora.Dictionary.load_from_text('./data/text.dict') # 次回からファイルロード可
"""
単語ID 単語 出現回数
1543 あさり 731
62 あっさり 54934
952 あったかい 691
672 あつい 1282
308 ありがたい 4137
・
・
"""
コーパスの作成
最初に集めた口コミをコーパスとして整備し、分類器の学習に使用します。
corpus = [dictionary.doc2bow(doc) for doc in docs]
gensim.corpora.MmCorpus.serialize('./data/text.mm', corpus) # 保存
# corpus = gensim.corpora.MmCorpus('./data/text.mm') # 次回からはファイルロード可
"""\
doc_id word_id 出現頻度
6 150 3 # word_id=150: もやし
6 163 9 # word_id=163: しょうゆ
6 164 1
6 165 1
・
・
"""
必要かどうか議論が分かれるところですが、
今回はコーパスにTFIDF処理を行ってLDAを行います。
tfidf = gensim.models.TfidfModel(corpus)
corpus_tfidf = tfidf[corpus]
# 折角計算したのでpickleに保存
import pickle
with open('./data/corpus_tfidf.dump', mode='wb') as f:
pickle.dump(corpus_tfidf, f)
# 次回からはロードできます
# with open('./data/corpus_tfidf.dump', mode='rb') as f:
# corpus_tfidf = pickle.load(f)
3. 分類器の学習
ここまでで準備ができたので、実際にgensimでLDAを行います。
今回は50個のトピックに分類してみました。
# 文書量にもよりますが、数時間程度かかったりもします。
# '18/12/03追記: LdaMulticore で worker の数を増やせばかなり早くなるかもです
lda = gensim.models.LdaModel(corpus=corpus_tfidf, id2word=dictionary,
num_topics=50, minimum_probability=0.001,
passes=20, update_every=0, chunksize=10000)
lda.save('./data/lda.model') # 保存
# lda = gensim.models.LdaModel.load('./data/lda.model') # 次回からロード可
ここで、学習したモデルの中身を表示してみましょう。
一部に感想を表すトピック(#0, #36, #42等)が混在しているものの、概ねラーメンの味を表すトピック(#2:味噌, #49:家系 等)となっており、それなりの分類器ができているものと思われます。
for i in range(50):
print('tpc_{0}: {1}'.format(i, lda.print_topic(i)[0:80]+'...'))
==============
tpc_0: 0.019*感動 + 0.014*衝撃 + 0.013*念願 + 0.012*難点 + 0.012*美味しい + 0.011*ラーメン + 0.010*感激 +...
tpc_1: 0.035*焼豚 + 0.022*冷やし中華 + 0.018*暑い + 0.010*病み付き + 0.009*頑固 + 0.008*美味しい + 0.008*ま...
tpc_2: 0.050*味噌 + 0.029*みそ + 0.017*生姜 + 0.013*バター + 0.012*もやし + 0.011*ラード + 0.009*コーン +...
tpc_3: 0.013*香味 + 0.010*ガーリック + 0.010*芳醇 + 0.009*チャーシュー + 0.008*オイル + 0.008*濃厚 + 0.008*...
tpc_4: 0.010*醤油 + 0.009*使用 + 0.009*昆布 + 0.008*素材 + 0.007*スープ + 0.007*魚介 + 0.007*チャーシュー ...
tpc_5: 0.015*こい + 0.014*あさり + 0.012*うすい + 0.010*ラーメン + 0.010*人受け + 0.010*気持ちよい + 0.010*...
tpc_6: 0.047*えび + 0.046*エビ + 0.014*胡麻 + 0.014*海老 + 0.012*病みつき + 0.008*美味しい + 0.008*すき焼き...
tpc_7: 0.016*まずい + 0.015*期待 + 0.013*悪い + 0.012*残念 + 0.012*美味しい + 0.011*普通 + 0.011*ラーメン ...
tpc_8: 0.070*そば + 0.015*そぼろ + 0.013*つけ + 0.012*明太子 + 0.012*鶏肉 + 0.010*濃厚 + 0.010*美味しい +...
tpc_9: 0.041*柚子 + 0.024*和風 + 0.017*煮込み + 0.010*三つ葉 + 0.010*人生 + 0.009*美味しい + 0.009*魚介 +...
tpc_10: 0.040*野菜 + 0.027*ニンニク + 0.018*増し + 0.013*にんにく + 0.010*もやし + 0.010*少なめ + 0.009*キャ...
tpc_11: 0.026*手打ち + 0.023*もつ + 0.016*しょうが + 0.010*辛口 + 0.010*ラーメン + 0.009*美味しい + 0.008*感...
tpc_12: 0.031*ソバ + 0.030*蕎麦 + 0.029*中華 + 0.016*白湯 + 0.011*軍鶏 + 0.008*美味しい + 0.007*ラーメン +...
tpc_13: 0.057*ブラック + 0.023*黒い + 0.020*真っ黒 + 0.018*醤油 + 0.011*スタミナ + 0.010*牡蠣 + 0.009*見た目...
tpc_14: 0.060*タンメン + 0.048*海老 + 0.019*野菜 + 0.014*白菜 + 0.011*つみれ + 0.009*餃子 + 0.007*美味しい ...
tpc_15: 0.073*辛い + 0.015*激辛 + 0.012*味噌 + 0.011*唐辛子 + 0.011*山椒 + 0.010*辛味 + 0.010*辛味噌 + 0...
tpc_16: 0.031*青葉 + 0.029*めし + 0.019*ダブル + 0.012*魚介 + 0.010*流行 + 0.009*インスタント + 0.009*ラーメ...
tpc_17: 0.041*替え玉 + 0.017*替玉 + 0.014*とんこつ + 0.014*辛子 + 0.010*極細 + 0.010*ラーメン + 0.009*紅しょ...
tpc_18: 0.032*懐かしい + 0.023*やさしい + 0.016*意味 + 0.012*ラーメン + 0.011*優しい + 0.010*感じ + 0.010*あ...
tpc_19: 0.027*レモン + 0.016*ふつー + 0.011*ガッツ + 0.009*惜しい + 0.009*ステーキ + 0.008*濃厚 + 0.008*美味...
tpc_20: 0.088*煮干 + 0.009*そば + 0.008*香り + 0.008*ラーメン + 0.008*スープ + 0.007*チャーシュー + 0.007*醤...
tpc_21: 0.023*寿司 + 0.015*お薦め + 0.012*お気に入り + 0.010*ラーメン + 0.009*美味しい + 0.008*育ち + 0.008*...
tpc_22: 0.025*空揚げ + 0.021*おしゃれ + 0.017*オシャレ + 0.016*カフェ + 0.014*お洒落 + 0.014*雰囲気 + 0.011*...
tpc_23: 0.024*価値 + 0.022*白味噌 + 0.018*味噌 + 0.014*赤味噌 + 0.010*究極 + 0.010*美味しい + 0.009*焦げ +...
tpc_24: 0.095*チャーハン + 0.040*セット + 0.017*ミニ + 0.013*餃子 + 0.012*ラーメン + 0.011*美味しい + 0.009*...
tpc_25: 0.024*おでん + 0.015*なつかしい + 0.013*焼肉 + 0.011*フラット + 0.010*濃い口 + 0.010*ラーメン + 0.009...
tpc_26: 0.010*外れ + 0.009*ラーメン + 0.009*美味しい + 0.008*真面目 + 0.008*おいしい + 0.008*うるさい + 0.008...
tpc_27: 0.073*もち + 0.032*キムチ + 0.012*辛みそ + 0.010*おいしい + 0.010*美味しい + 0.008*チャーシュー + 0.00...
tpc_28: 0.021*すだち + 0.019*七味 + 0.018*めん + 0.015*玉ねぎ + 0.011*たまねぎ + 0.010*期待外れ + 0.010*つけ...
tpc_29: 0.079*餃子 + 0.026*ビール + 0.011*美味しい + 0.010*ラーメン + 0.009*生ビール + 0.009*しょう油 + 0.008...
tpc_30: 0.021*締め + 0.018*無性 + 0.018*胚芽 + 0.015*酒粕 + 0.010*水炊き + 0.009*カニ + 0.009*濃厚 + 0....
tpc_31: 0.051*ちゃんぽん + 0.024*学生 + 0.015*坦々 + 0.011*海鮮 + 0.009*ショック + 0.009*本物 + 0.009*美味し...
tpc_32: 0.025*臭い + 0.023*匂い + 0.016*におい + 0.010*秘伝 + 0.010*おいしい + 0.010*ラーメン + 0.010*つゆ ...
tpc_33: 0.010*醤油 + 0.009*チャーシュー + 0.008*魚介 + 0.008*旨味 + 0.007*スープ + 0.007*メンマ + 0.007*良い...
tpc_34: 0.074*カレー + 0.040*焼き飯 + 0.015*元祖 + 0.011*スパイス + 0.010*セット + 0.008*美味しい + 0.008*ラ...
tpc_35: 0.068*トマト + 0.031*チーズ + 0.015*イタリアン + 0.014*パスタ + 0.011*ホルモン + 0.011*リゾット + 0.00...
tpc_36: 0.038*同僚 + 0.014*最強 + 0.010*堅い + 0.010*ラーメン + 0.010*ダントツ + 0.009*美味しい + 0.009*話題...
tpc_37: 0.059*とんこつ + 0.026*しょうゆ + 0.025*子供 + 0.015*おいしい + 0.012*どろどろ + 0.012*ラーメン + 0.01...
tpc_38: 0.027*ごはん + 0.025*おにぎり + 0.022*ご飯 + 0.016*雑炊 + 0.014*ライス + 0.012*漬物 + 0.011*セット ...
tpc_39: 0.026*ゆず + 0.019*淡い + 0.009*熟成 + 0.009*焼き豚 + 0.008*醤油 + 0.008*チャーシュー + 0.007*スープ...
tpc_40: 0.042*うどん + 0.012*カツオ + 0.009*ええ + 0.009*天ぷら + 0.009*ラーメン + 0.008*美味しい + 0.008*感...
tpc_41: 0.023*塩辛い + 0.020*だれ + 0.012*ジャンク + 0.012*つけ + 0.009*フレンチ + 0.008*シェフ + 0.008*ラー...
tpc_42: 0.029*友達 + 0.028*おいしい + 0.015*行列 + 0.015*美味しい + 0.013*ラーメン + 0.013*あっさり + 0.012*...
tpc_43: 0.012*メンマ + 0.011*チャーシュー + 0.010*醤油 + 0.009*ネギ + 0.009*良い + 0.008*魚介 + 0.008*スープ...
tpc_44: 0.040*つけ + 0.014*濃厚 + 0.013*ぬるい + 0.013*割り + 0.013*魚介 + 0.013*魚粉 + 0.011*盛り + 0....
tpc_45: 0.019*不味い + 0.017*岩のり + 0.017*春菊 + 0.012*日本一 + 0.010*美味しい + 0.009*ラーメン + 0.008*行...
tpc_46: 0.074*ワンタン + 0.045*メン + 0.015*チャーシュー + 0.009*美味しい + 0.008*雲呑 + 0.008*醤油 + 0.007*...
tpc_47: 0.027*ふつう + 0.019*系列 + 0.017*盛蕎麦 + 0.012*漬け + 0.010*古い + 0.010*おいしい + 0.010*一生懸命...
tpc_48: 0.018*ハーフ + 0.014*サラダ + 0.014*デザート + 0.014*料理 + 0.013*居酒屋 + 0.012*豆腐 + 0.010*セット...
tpc_49: 0.068*家系 + 0.019*ほうれん草 + 0.013*海苔 + 0.010*醤油 + 0.010*チャーシュー + 0.010*濃い + 0.010*ラ...
4. 店の分類 (トピック分け)
分類器の学習ができたので、この分類器に店の口コミを通すことによって、店のトピック分け(トピックベクトル算出)を行います。
まずは、私が中高生時代から愛してやまない、"新福菜館本店@京都" の食べログピックアップ口コミを1件入力して性能を見てみましょう。ただその前に、以下の理解を容易にするために、新福菜館がどのようなラーメンを提供されているか共有しておきます。
「新福菜館 京都」
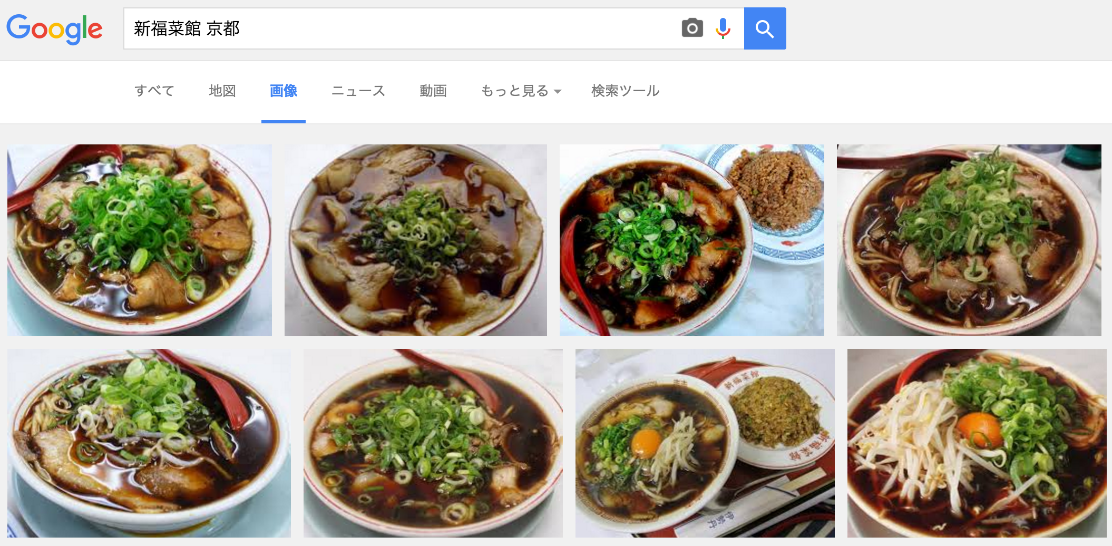
黒いですね…。黒いラーメンです。
ただ見た目と異なり、意外とあっさりしつつもコクのある美味しい醤油ラーメンです。
さて、今回構築した分類器はどのような結果を返すでしょうか?
# 引用元: http://tabelog.com/kyoto/A2601/A260101/26000791/dtlrvwlst/763925/
# ちなみに個人的には生卵入れないほうが好きです笑
>> str="京都出張の際、念願だった新福菜館の本店に立ち寄りました。 (中略) 何と言うか、スープの加減といい、麺の茹で具合といい、具の盛り方といい、チャーシューのおいしさといい、やはり本店はさらに旨い!と感じました。とにかくこれが650円とは安いです。新福菜館の「中華そば」は、チャーシューの煮汁のように真っ黒なスープ、たっぷり乗った九条ねぎが特徴。もちろん、「ヤキメシ」もたまりません。 (中略) 帰り際にふと見たお客さんの注文したもの(後でここのレビューを見て、それが「特大 新福そば」だと知りましたが)には生卵が乗っていて、生卵好きな私とし ては、「あ~、そんなこともできたのかあ!」とショックを受けました。新福菜館のスープには絶対合いそうですし、次回は絶対頼もうと思います。"
>> vec = dictionary.doc2bow(utils.stems(str))
# 分類結果表示
>> print(lda[vec])
[(0, 0.28870310712135505), (8, 0.25689765230576195), (13, 0.3333132412551591), (31, 0.081085999317724824)]
# 各トピック内容 / 影響度の高い順に
>> lda.print_topic(13) # 新福菜館の黒いラーメンの特徴を捉えられている
0.057*ブラック + 0.023*黒い + 0.020*真っ黒 + 0.018*醤油 + 0.011*スタミナ + 0.010*牡蠣 + 0.009*見た目 + 0.008*濃い + 0.008*ラーメン + 0.008*美味しい
>> lda.print_topic(0)
0.019*感動 + 0.014*衝撃 + 0.013*念願 + 0.012*難点 + 0.012*美味しい + 0.011*ラーメン + 0.010*感激 + 0.010*行列 + 0.010*おいしい + 0.008*美味い
>> lda.print_topic(8)
0.070*そば + 0.015*そぼろ + 0.013*つけ + 0.012*明太子 + 0.012*鶏肉 + 0.010*濃厚 + 0.010*美味しい + 0.008*チャーシュー + 0.008*あっさり + 0.007*ご飯
>> lda.print_topic(31)
0.051*ちゃんぽん + 0.024*学生 + 0.015*坦々 + 0.011*海鮮 + 0.009*ショック + 0.009*本物 + 0.009*美味しい + 0.008*ラーメン + 0.008*野菜 + 0.008*格別
ちゃんと黒いラーメンって出ました。
正常に動作することがわかったので、新福菜館本店に言及しているWeb上の数百件の文章を連結して分類器に入れてみましょう。
>> str = "WEB上でかき集めた文章ほげほげ"
>> sinpuku_vec = dictionary.doc2bow(utils.stems(str))
>> print(lda[sinpuku_vec])
[(0, 0.003061940579476011), (5, 0.001795672854987279), (7, 0.016165280743592875), (11, 0.0016683462844631061), (13, 0.387457274481951), (16, 0.048457912903426922), (18, 0.025816920842756448), (19, 0.0014647251485231138), (20, 0.0018013651819984121), (21, 0.001155430885775867), (24, 0.11249915373166983), (25, 0.0030405756373518885), (26, 0.0031413889216075561), (27, 0.0030955757983300515), (29, 0.0021349369911582098), (32, 0.006158571006380364), (34, 0.061260735988294568), (36, 0.0023903609848973475), (37, 0.020874795314517719), (41, 0.0018301667593946488), (42, 0.27803177713836785), (45, 0.0055461332216832828), (46, 0.0016396961473594117), (47, 0.0056507918659765869)]
>> lda.print_topic(13) # 値: 0.38
0.057*ブラック + 0.023*黒い + 0.020*真っ黒 + 0.018*醤油 + 0.011*スタミナ + 0.010*牡蠣 + 0.009*見た目 + 0.008*濃い + 0.008*ラーメン + 0.008*美味しい
>> lda.print_topic(42) # 値: 0.27
0.029*友達 + 0.028*おいしい + 0.015*行列 + 0.015*美味しい + 0.013*ラーメン + 0.013*あっさり + 0.012*すごい + 0.011*感じ + 0.011*有名 + 0.011*多い
>> lda.print_topic(24) # 値: 0.11
0.095*チャーハン + 0.040*セット + 0.017*ミニ + 0.013*餃子 + 0.012*ラーメン + 0.011*美味しい + 0.009*おいしい + 0.009*単品 + 0.008*注文 + 0.008*チャーシュー
結果が若干見づらくなってしまいましたが、多くの意見を反映した結果か第3位トピックにチャーハンが登場しました。
最初の口コミを書かれた方は頼まれなかったようですが、実は新福菜館は黒いチャーハンも有名です。このことにより(?)、集合知によるラーメン屋のトピック分けが機能することが分かりました。
5. 似ている店を探す
さて、分類器により任意のラーメン屋のトピックベクトルが算出できるようになりました。最後に、この分類器を活用して似ている店を探していきたいと思います。
理論上はどんな店に対してでも似ている店を探すことが出来ますが、前節の内容を引き継ぎ、新福菜館本店に似ている店を探そうと思います。
細かいコードは端折りますが、概ね、全国のラーメン屋のLDAトピック計算 → 新福菜館本店のLDAトピックと類似度計算、というのを以下の様に行います。
# 各種設定
MIN_SIMILARITY = 0.6 # 類似度のしきい値
RELATE_STORE_NUM = 20 # 似ている店の抽出数
# 全国のラーメン屋のLDAトピック計算
from my_algorithms import calc_vecs
(names, prefs, vecs) = calc_vecs(reviews, lda, dictionary)
# 新福菜館本店と全国のラーメン屋のLDAトピックの類似度を計算
from sklearn.metrics.pairwise import cosine_similarity
similarities = cosine_similarity(sinpuku_vec, vecs)
# 似ている店を表示する
import pandas as pd
df = pd.DataFrame({'name': names,
'pref': prefs,
'similarity': similarities})
relate_store_list = df[df.similarity > MIN_SIMILARITY] \
.sort_values(by="similarity", ascending=False) \
.head(RELATE_STORE_NUM)
print(relate_store_list)
==============
id similarity pref name
0 0.934 toyama 誠や
1 0.898 hokkaido いそのかづお
2 0.891 shiga 金久右衛門 三井アウトレットパーク滋賀竜王店
3 0.891 kyoto 新福菜館 東土川店
4 0.888 osaka 金久右衛門 道頓堀店
5 0.886 chiba 炭一ラーメン
6 0.874 osaka 金久右衛門 江坂店
7 0.873 toyama いろは 射水本店
8 0.864 osaka 金久右衛門 梅田店
9 0.861 mie 林家
10 0.847 niigata ラーメン つり吉
11 0.846 osaka 金久右衛門 本店
12 0.838 toyama めん八 御旅屋店
13 0.837 aichi きくや飯店
14 0.820 hyogo 中乃屋
15 0.814 kyoto 金久右衛門 京都西院店
16 0.807 aichi よこじ
17 0.804 kumamoto 好来ラーメン店
18 0.792 kyoto 新福菜館 久御山店
19 0.791 niigata ゴインゴイン
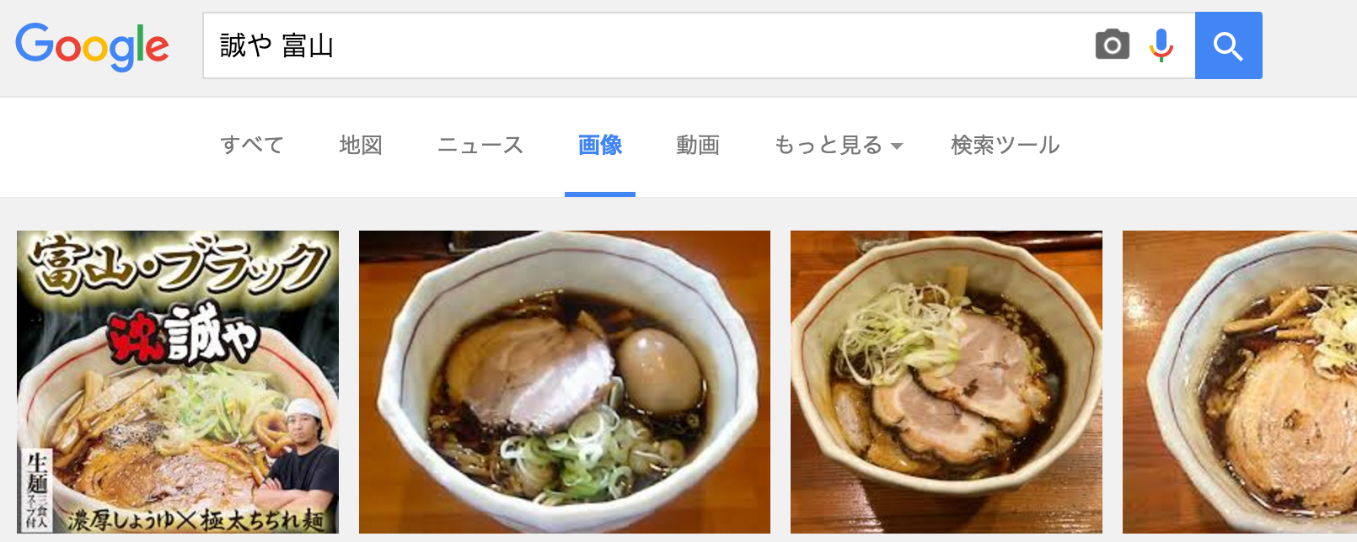
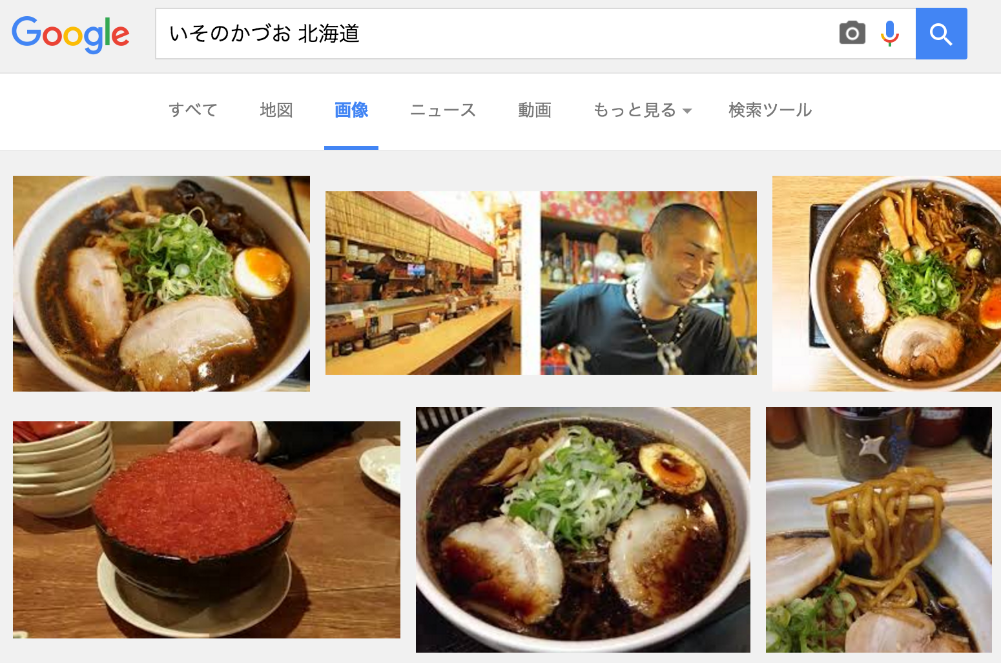
幾つかピックアップして結果を確認してみましょう。
「誠や 富山」
「いそのかづお 北海道」
「金久右衛門 三井アウトレットパーク滋賀竜王店」
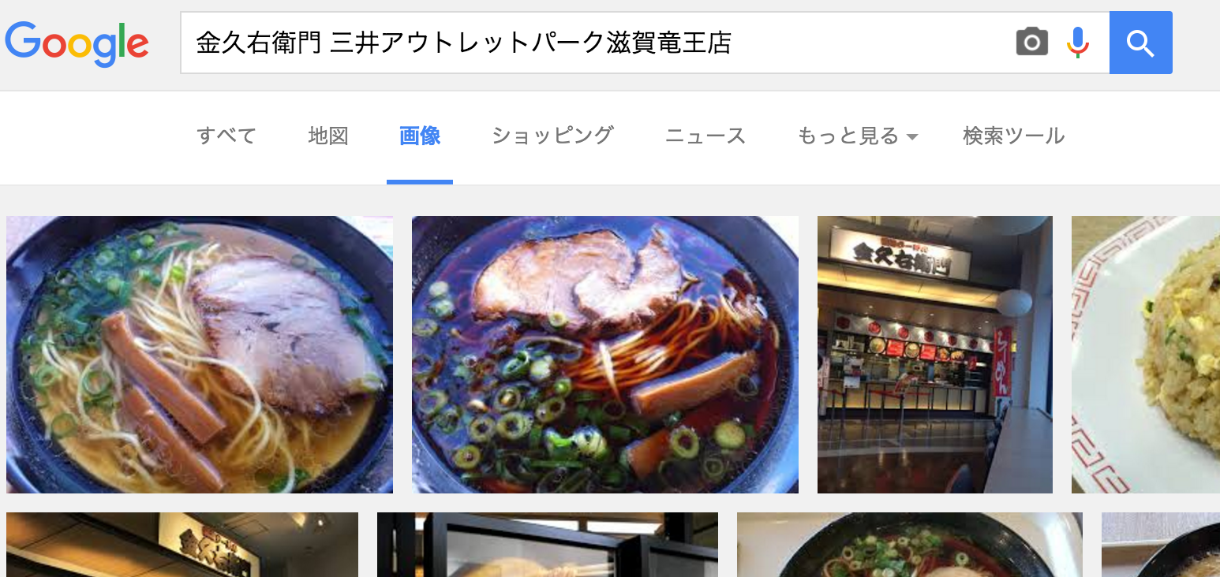
黒いですね…、見事に黒い。その他も調べてみましたが、兵庫の中乃屋さん以外は全部黒いラーメンでした。
新福菜館は支店も幾つかあり、店名を一切除去して解析しているにも関わらずきちんと結果に入ってきてくれたのも良いポイントかと思います。
黒いラーメンといえば富山ブラックが有名で幾つか登場していますが、新福菜館の味は富山ブラックとは少し違うかなと。味というよりもなんしかラーメンの黒さで似た店が選ばれてしまった感も否めません。この辺りの雑さは今後の改善ポイントとしていきたい所存です。
まとめ
今回はラーメンを題材として、ネット上に転がっている文字データから、人間が(ほぼ)介在することなく様々な知見を得る方法をご紹介いたしました。
人間が介在して作った教師ありデータをもとに分類する手法に比べると甚だ頼りない結果にも見えますが、Pythonの既存のライブラリを用いて手軽に得られる結果としてはそこそこ良い結果ではないかと思います。
勿論ラーメンだけでなく、一定量以上の文章量があれば様々なものに対応が可能です。
みなさんも良かったら色々な文書で試してみてください。