大したことではないですが,pandas.DataFrameをcsvで保存してRのreadr::tbl_dfで読もうとしたらハマったので回避策をメモ.
小中規模のデータフレームを扱う場合,Pythonではpandas,Rではdata.frame系を使うことが一般的だと思います.
また,Python <=> R間でのデータフレームの受け渡しは,SQLを仲介する場合もあるでしょうが,楽にやるならcsvがベターだと思います.
csvによる受け渡しの問題点
ところがboolを含むpandas.DataFrameをそのままcsvに吐くとread_csvでlogicalとして読めないっぽいです.こんな感じ↓
from datetime import datetime
import pandas as pd
df = pd.DataFrame({
'A': ('a1', 'a2', 'a3'),
'B': (True, False, True),
'C': (0, 1, 2),
'D': [datetime.now()] * 3
})
df.to_csv('sample.csv', index=False, encoding='utf-8')
library(readr)
read_csv('sample.csv', col_types = 'cliT', locale = locale(encoding = 'UTF-8'))
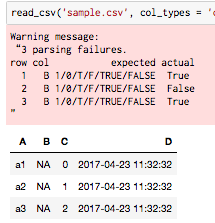
エラーを見ると,T・FやTRUE・FALSE,0・1しかlogicalとして受け付けてくれないっぽいです.
回避策
# df.to_csv('sample.csv', index=False, encoding='utf-8')
(df * 1).to_csv('sample.csv', index=False, encoding='utf-8')
とすれば良いです.True/Falseを1/0にしてくれます.
文字列に対する*は,「"hoge" * 2」を「"hogehoge"」とするような処理ですから,今回のように「* 1」しても何も変わりません.
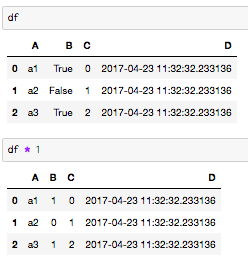
01であれば,read_csvで読み込めます.
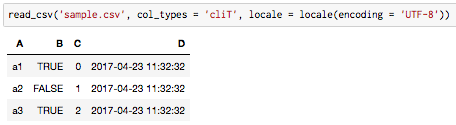
失敗例
ちなみに以下のような方法は失敗します.
df.astype(int) # str等がある場合失敗する
df.replace({True: 1, False: 0}) # 何も起こらない
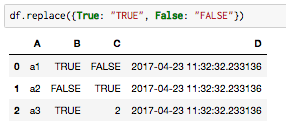
df.replace({True: "TRUE", False: "FALSE"}) # 1/0が全部文字列に (下図)
(他に良い方法があれば教えてください)