注意点
ゴリ押しです.たぶん,より良い方法があると思います.
min_after_dequeueが小さいとき,tf.train.shuffle_batchは偏る.
min_after_dequeueがファイルサイズより小さいとき,tf.shuffle_batchは偏ります.なぜなら,shuffle_batchはenqueueされた画像に対してのみshuffleをかけるからです.
例えば,mnistの画像7万枚 (各ラベル7000枚) をラベルの小さい順に並び替え,ラベルと一緒にtfrecordに記録したとします.
このとき,tf.train.shuffle_batchのmin_after_dequeueを10000に設定し,5万個のラベル取り出したとすると,ラベルの分布は,
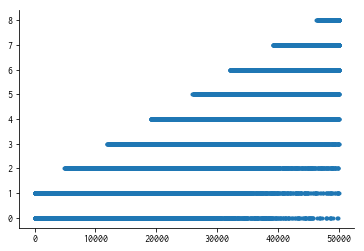
のようになります.横軸は取り出した順番,縦軸は得られたラベルです.
最初のほう (4000枚取り出すまで = 14001枚目の「2」のレコードがeuqueueされるまで) は,「0」か「1」のレコードしかキューに入っていないので,0か1しか出てきません.
また,「9」のラベルは63001枚目以降にしか含まれていないため,5万枚のラベルを取り出した時点では一度も出現していません.
より直接的に,tfrecordにレコード番号をつけ,そのレコード番号を縦軸にとってみると,

のようになります.バッチ前半は番号の小さいレコードのみが返され,バッチ後半は主に番号の大きいレコードが返されます.ただしバッチ後半は,シャッフルで運良く (?) dequeueを逃れた番号の若いレコードがいくらか残っています.
複数のtfrecordを使った場合など,より詳しい話は,こちらの「【Tensorflow】TFRecordファイルでshuffle_batchしたときの偏り調査」に書かれています.
回避策
回避策はいくらかあると思います.
- 非同期読み込みを諦める.
- ちょっとした学習ならこれで解決.
- tfrecordを分割する.
- おそらく,最も基本的な回避策かと思われます.例えば,1000レコードのtfrecordファイルを70個作れば,ばらつきを抑制することができます.
- というより,
min_after_dequeueよりも大きなサイズのファイルは,そもそも作るべきでは無いです. - とはいえこの方法,偏りが完全になくなるわけではないです (1ファイルにまとめられた1000レコードは,まとまって吐き出されやすい).
-
min_after_dequeueをファイルのレコード数以上にし,ファイルの中身を全部メモリに載せる.- 力こそパワー.
-
ファイルのpathだけのtfrecordを作成し,
min_after_dequeueをそのファイルのレコード数以上にする.- 70000枚の画像をメモリに載せるのは無理でも,画像へのパスを保持することは難しくないはずです.
- つまり,2つのバッチを作成します.
- 画像のパスを大量に保持するバッチ
- ある程度の画像を読み込んで保持するバッチ
非同期処理,かつ,十分良いランダマイズ,を同時に達成するには最後の方法しか無いと思います (が,他にあったらぜひ教えて欲しいです).そこで,これについて自分がやった対策を,MNISTデータセットを例にして書いていきます.
以下では,2通りの実装方法を並行して書いていきます.
- 画像をtfrecordに詰めた場合の例 (= 普通のtfrecordの使い方)
- パスをtfrecordに詰めた場合の例 (= 今回やりたいtfrecordの使い方.画像はすべてローデータのままpathに保存しておく)
1の実装は「共通の操作」と「画像のtfrecordの場合」をコピペすれば動きます.2の実装は「共通の操作」と「パスのtfrecordの場合」をコピペすれば動きます.
tfrecordの作成
普通の方法 (画像をtfrecordに保存する) と,今回やりたい方法 (画像の代わりにパスtfrecordに保存する) を試すために,それぞれの方法でMNISTデータのtfrecordを作成します.
共通の操作
import os
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
MNIST_DIR = './MNIST-data'
TFRECORD_DIR = './tfrecords'
IMAGE_DIR = './images'
def make_mnist_data():
mnist_data = input_data.read_data_sets(MNIST_DIR, validation_size=0)
# 学習データもテストデータも全部まとめる
labels = np.r_[mnist_data[0].labels, mnist_data[2].labels]
images = np.r_[mnist_data[0].images, mnist_data[2].images]
# 画像は画像の形に修正しておく.
images = (images * 255).astype(np.uint8).reshape((-1, 28, 28))
# 画像を0から順番に並び替える.
order = np.argsort(labels)
labels = labels[order] # np.repeat(np.arange(0, 10), 7000) と同じ
images = images[order] # 昇順に並び替えられた手書き画像
indices = np.arange(len(labels), dtype=int) # 0~69999のインデックス
return indices, labels, images
def int64_feature(value):
return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))
def bytes_feature(value):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
画像のtfrecordの場合
普通,tfrecordはこんな感じで作ります (indexは不要ですが一応).
def image_to_tfexample(index, label, image):
image_string = image.tostring()
return tf.train.Example(features=tf.train.Features(feature={
'index': int64_feature(index),
'label': int64_feature(label),
'image_string': bytes_feature(image_string)
}))
indices, labels, images = make_mnist_data()
tfrecord_path = os.path.join(TFRECORD_DIR, 'mnist_image.tfrecord')
with tf.python_io.TFRecordWriter(tfrecord_path) as writer:
for index, label, image in zip(indices, labels, images):
example = image_to_tfexample(index, label, image)
writer.write(example.SerializeToString())
パスのtfrecordの場合
tfrecord作成とは別に,IMAGE_DIRにpng画像を保存しておきます.
def path_to_tfexample(index, label, path):
path_string = path.encode('utf-8')
return tf.train.Example(features=tf.train.Features(feature={
'index': int64_feature(index),
'label': int64_feature(label),
'path_string': bytes_feature(path_string)
}))
indices, labels, images = make_mnist_data()
paths = [os.path.join(IMAGE_DIR, f'{i}.png') for i in indices]
tfrecord_path = os.path.join(TFRECORD_DIR, 'mnist_path.tfrecord')
with tf.python_io.TFRecordWriter(tfrecord_path) as writer:
for index, label, path in zip(indices, labels, paths):
example = path_to_tfexample(index, label, path)
writer.write(example.SerializeToString())
# MNIST画像は,tfrecordとは別に保存しておく
for path, image in zip(paths, images):
Image.fromarray(image).save(path)
tfrecordの読み込み
画像のtfrecordの場合
以下の例では,min_after_dequeueを1万枚に設定しています (よくある入力画像サイズは224x224x3以上だったりするので,メモリによってはこのようにせいぜい数万枚が限界かと思います).
このmin_after_dequeueのサイズだと,冒頭の図のような分布の偏りが生じます (というより,そもそもこのinput_pipelineからデータを取得して作図しました).
BATCH_SIZE = 20
def read_tfrecord(filename_queue):
reader = tf.TFRecordReader()
key, record_string = reader.read(filename_queue)
example = tf.parse_single_example(record_string, features={
'index': tf.FixedLenFeature([], tf.int64),
'label': tf.FixedLenFeature([], tf.int64),
'image_string': tf.FixedLenFeature([], tf.string)
})
index = tf.cast(example['index'], tf.int32)
label = tf.cast(example['label'], tf.int32)
image = tf.decode_raw(example['image_string'], tf.uint8)
image = tf.reshape(image, [28, 28, 1])
image.set_shape([28, 28, 1])
return index, label, image
def input_pipeline(filenames):
filename_queue = tf.train.string_input_producer(filenames)
index, label, image = read_tfrecord(filename_queue)
index_batch, label_batch, image_batch = tf.train.shuffle_batch(
[index, label, image],
batch_size=BATCH_SIZE,
min_after_dequeue=10000,
capacity=10000 + 3 * BATCH_SIZE,
num_threads=1,
)
return index_batch, label_batch, image_batch
tfrecord_path = os.path.join(TFRECORD_DIR, 'mnist_image.tfrecord')
index_batch, label_batch, image_batch = input_pipeline([tfrecord_path, ])
パスのtfrecordの場合
以下の例では,1つ目のmin_after_dequeueを7万枚に設定しています.パスはただの文字列ですし問題なくメモリに乗ると思います.このmin_after_dequeueのサイズであれば,冒頭の図のような分布の偏りは生じないです.
一方,画像を保持するバッチのcapacityは約10000枚です.これは画像tfrecord版に合わせているだけで,シャッフルをする必要がないので実際にはもっともっと少なくても良いです (デフォルトのcapacityは32).
なお,出力の形が[BATCH_SIZE, ]や[BATCH_SIZE, 28, 28, 1]になるようにちょくちょくreshapeをはさんでいます.
バッチを二段構えにしている理由は単純で,画像のtfrecordと全く同じようにすると,非同期処理はパスの読み込みで止まってしますからです.処理に時間がかかるのは画像読み込み〜前処理なので,ここが裏で動いてくれないと旨味がほとんど全くありません.
BATCH_SIZE = 20
def read_tfrecord(filename_queue):
reader = tf.TFRecordReader()
key, record_string = reader.read(filename_queue)
example = tf.parse_single_example(record_string, features={
'index': tf.FixedLenFeature([], tf.int64),
'label': tf.FixedLenFeature([], tf.int64),
'path_string': tf.FixedLenFeature([], tf.string)
})
index = tf.cast(example['index'], tf.int32)
label = tf.cast(example['label'], tf.int32)
path = example['path_string']
return index, label, path
def image_from_path(path):
png_bytes = tf.read_file(path)
image = tf.image.decode_png(png_bytes, channels=1)
image.set_shape([28, 28, 1])
return image
def input_pipeline(filenames):
filename_queue = tf.train.string_input_producer(filenames)
index, label, path = read_tfrecord(filename_queue)
index_batch, label_batch, path_batch = tf.train.shuffle_batch(
[index, label, path],
batch_size=1,
min_after_dequeue=70000,
capacity=70000 + 3 * 1,
num_threads=1
)
index_batch_flatten = tf.reshape(index_batch, [-1])
label_batch_flatten = tf.reshape(label_batch, [-1])
path_batch_flatten = tf.reshape(path_batch, [-1])
image_batch_flatten = tf.map_fn(image_from_path, path_batch_flatten, dtype=tf.uint8)
index_batch, label_batch, image_batch = tf.train.batch(
[index_batch_flatten, label_batch_flatten, image_batch_flatten],
batch_size=BATCH_SIZE,
capacity=10000 + 3 * BATCH_SIZE,
num_threads=1,
)
index_batch = tf.reshape(index_batch, [-1])
label_batch = tf.reshape(label_batch, [-1])
image_batch = tf.reshape(image_batch, [-1, 28, 28, 1])
return index_batch, label_batch, image_batch
tfrecord_path = os.path.join(TFRECORD_DIR, 'mnist_path.tfrecord')
index_batch, label_batch, image_batch = input_pipeline([tfrecord_path, ])
出力の確認
それぞれの方法で作ったindex_batch, label_batch, image_batchの出力を確認していきます.
init_op = tf.local_variables_initializer()
results = {'index': [], 'label': []}
with tf.Session() as sess:
sess.run(init_op)
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
for i in range(2500): # batch sizeが20なので,5万枚ぶん
result = sess.run([index_batch, label_batch])
results['index'].append(result[0])
results['label'].append(result[1])
coord.request_stop()
coord.join(threads)
fig = plt.figure(figsize=(10, 5))
for i, key in enumerate(('index', 'label')):
ax = fig.add_subplot(1, 2, i + 1)
y = np.array(results[key]).flatten()
x = np.arange(len(y))
ax.plot(x, y, '.')
fig.show()
結果 (画像のtfrecordの場合)
書き忘れたんですが,横軸がそのバッチを取り出した順番で,縦軸がバッチのレコード番号 (左) または正答ラベル (右) です.

結果 (パスのtfrecordの場合)
いい感じに混ざってる.

結論
パスだけをtfrecordに保存することで,メモリを節約したまま,十分シャッフルされた画像のバッチを非同期処理で作ることが出来ました.なお,数千万単位のデータに対しても,ファイルを分割することで同様の対策が取れるのではないかと思います (直接tfrecordに画像を入れるよりは混ざるはず).