#機械学習とは
こんにちは、mucunです。
この連載では、私なりに勉強してきた「機械学習」の知識について、
なるべく綺麗にまとめて、紹介していきたいと思います。
「AI」「人工知能」「機械学習」「ディープラーニング」、、、
これらのワードが一気呵成にバズり始め、
真剣に導入を考える企業が少なくない昨今。
非常にHOTな技術領域と言えます。
##言葉の整理
先ず、言葉の整理です。
「AI」「人工知能」「機械学習」「ディープラーニング」、、、
これらは違う領域を指しています。
違いについては、下記画像引用元記事に詳しく書いてありました。
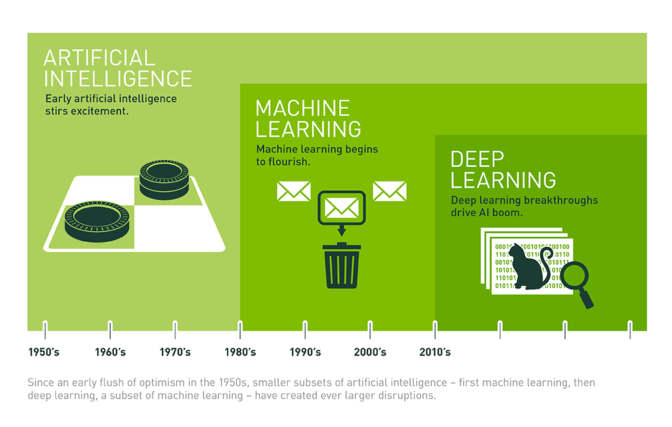
(画像引用元:【NVIDIA】人工知能、機械学習、ディープラーニングの違いとは)
分かりやすい!!
「AI・人工知能」がより抽象的な概念、広義な意味合い。
「機会学習」がそれを実現する手法の1流派。
「ディープラーニング」が、「機会学習」の内の1手法という関係です。
##機械学習の意味するところ
次に、「機械学習」の意味を掘り下げていきます。
wikiによれば、
機械学習(きかいがくしゅう、英: machine learning)とは、
人工知能における研究課題の一つで、
人間が自然に行っている学習能力と同様の機能を
コンピュータで実現しようとする技術・手法のことである。
とのこと。
また、統計解析で有名なSASによれば、
機械学習とは、データから反復的に学習し、
そこに潜むパターンを見つけ出すことです。
そして学習した結果を新たなデータにあてはめることで、
パターンにしたがって将来を予測することができます。
とのこと。
まとめると、
- 人間の学習をコンピューターで再現する手法
- データの法則性を抽出し、そこから将来予測をする手法
ということですね。
つまり、行動科学の解明であり、パターン識別であるという訳です。
##具体例から説明
例えば、男女の判断を見た目から識別してみます。
分かりやすく、以下の項目で判断することにします。
- 身長の高さ
- 髪の長さ
- 髭の濃さ
サンプルデータを以下5件とします。
| 名前 | 身長 | 髪の長さ | 髭の濃さ | 性別 |
|---|---|---|---|---|
| Aさん | 170 | 濃い | 男 | |
| Bさん | 180 | 少し | 男 | |
| Cさん | 160 | まあまあ濃い | 男 | |
| Dさん | 150 | ほんの少し | 女 | |
| Eさん | 170 | 無し | 女 |
これらの与えられたデータから、
「男性/女性」を識別する決め手を抽出するのが機械学習です。
学習の前には、データの数値化とスケール合わせをします。
データの値域は、「-1~1」か「0~1」に調整することが多いです。
値の意味合いによって、調整の仕方は考える必要があります。
特に、ZEROの意味をしっかり考慮しなくてはなりません。
(※この辺りについては、いずれ掘り下げたいと思います)
実際にやってみると、こんな感じです。
| 名前 | 身長 | 髪の長さ | 髭の濃さ | 性別 |
|---|---|---|---|---|
| Aさん | 0.70 | 0.20 | 1.00 | 1 |
| Bさん | 0.80 | 0.60 | 0.30 | 1 |
| Cさん | 0.60 | 0.40 | 0.50 | 1 |
| Dさん | 0.50 | 0.60 | 0.10 | 0 |
| Eさん | 0.70 | 0.90 | 0.00 | 0 |
このデータを使って、機械学習を行います。
具体的に行うことは、データ項目ごとに統計的な決め手度合の計算です。
その度合のことを、一般的に「重み」と言います。
例えば、
- 身長の高さ ⇒ 重み:0.5
- 髪の長さ ⇒ 重み:-0.9
- 髭の濃さ ⇒ 重み:0.7
という具合に計算します。
実際の計算方法については、次回以降で掘り下げます。
この重みをサンプルデータに対して掛けて、その総和を取ります。
| 名前 | 身長 × 0.5 | 髪の長さ × -0.9 | 髭の濃さ × 0.7 | 総和 |
|---|---|---|---|---|
| Aさん | 0.35 | -0.18 | 0.70 | 0.87 |
| Bさん | 0.40 | -0.54 | 0.21 | 0.07 |
| Cさん | 0.30 | -0.36 | 0.35 | 0.29 |
| Dさん | 0.25 | -0.54 | 0.07 | -0.22 |
| Eさん | 0.35 | -0.81 | 0.00 | -0.46 |
すると、男性がプラスの値、女性がマイナスの値が出るように、
「重み」が調整されていることが確認できます。
つまり、総和の値が ZEROより上か下かで識別ができています。
この時の境界値のことを「閾値」と呼びます。
「閾値」は、ZEROでも、ZEROでなくても構いません。
今回は、ZEROが「閾値」になるように調整がされています。
一度、「重み」が算出できれば、未知のデータでの予測ができます。
例えば、以下のような未知のデータがあったとします。
| 名前 | 身長 | 髪の長さ | 髭の濃さ | 性別 |
|---|---|---|---|---|
| Fさん | 170 | 少し | ? | |
| Gさん | 160 | ほんの少し | ? |
予測の際にも、データの数値化とスケール合わせをします。
| 名前 | 身長 | 髪の長さ | 髭の濃さ | 性別 |
|---|---|---|---|---|
| Fさん | 0.70 | 0.40 | 0.30 | ? |
| Gさん | 0.60 | 0.90 | 0.10 | ? |
そして、「重み」を掛け合わせます。
| 名前 | 身長 × 0.5 | 髪の長さ × -0.9 | 髭の濃さ × 0.7 | 総和 |
|---|---|---|---|---|
| Fさん | 0.35 | -0.36 | 0.21 | 0.10 |
| Gさん | 0.30 | -0.81 | 0.07 | -0.44 |
よって、予測は以下となります。
| 名前 | 性別予測 |
|---|---|
| Fさん | 男性 |
| Gさん | 女性 |
以上、機械学習のイメージを掴んでもらうために、
具体例でもっての説明でした。
##要するに、、、
まとめると、
- 識別のための「重み」を算出するのが「機会学習」
- 「重み」を算出すれば、未知のデータで予測ができる
です。
今回の記事はここまでとなります。
読んで下さった方、ありがとうございました。<(_ _)>