PHP言語レベルでのエスケープシーケンス
マニュアル も併せてお読みください。
シングルクオート内で処理されるシーケンス
| 記述 | 実際の表示 | 意味 | 備考 |
|---|---|---|---|
\\ |
\ | バックスラッシュ | 【※1】 直後にシングルクオートがない場合は省略可能 |
\' |
' | シングルクオート |
echo '[a]\[b]'; # => [a]\[b]
echo '[a]\\[b]'; # => [a]\[b]
echo '[a]\\\[b]'; # => [a]\\[b]
echo '[a]\\\\[b]'; # => [a]\\[b]
echo '\\'; # => \
echo '\'; # パースエラー
慣れないうちは省略せずに全てエスケープすることをおすすめします。ちなみにこれはPHPに限っての挙動であり、 C や Java ではこのような挙動にはならず、 必ずエスケープしなければなりません 。
ダブルクオート内で処理されるシーケンス
一部マニュアルに記載がないものもあります。
| 記述 | 実際の表示 | 意味 | 備考 |
|---|---|---|---|
\\ |
\ | バックスラッシュ | 【※1】 直後に他のエスケープ可能な文字がない場合は省略可能 |
\" |
" | ダブルクオート | |
\$ |
$ | ドル記号 | 【※2】 直後に変数名に使える文字がなければ省略可能 |
\0 |
NULL文字 | (実際は下で紹介している8進数表記のものに属する) | |
\n |
ラインフィード | ||
\r |
キャリッジリターン | ||
\t |
水平タブ | ||
\v |
垂直タブ | PHP5.2.5以降のみ | |
\e |
エスケープ | PHP5.4.0以降のみ | |
\123 |
S | 8進数表記でのアスキーコード指定 | 正規表現は \[0-7]{1,3}
|
\x53 |
S | 16進数表記でのアスキーコード指定 | 正規表現は \x[0-9A-Fa-f]{1,2}
|
{$var} |
$var の値 | 変数展開 | |
$var |
$var の値 | 変数展開 | |
{$var[0]} |
$var[0] の値 | 変数展開 | |
$var[0] |
$var[0] の値 | 変数展開 | |
{$var['hoge']} |
$var['hoge'] の値 | 変数展開 | ↓ との違いに注意 |
$var[hoge] |
$var['hoge'] の値 | 変数展開 | ↑ との違いに注意 |
【※2】
ここでの「変数名に使える文字」とは、 ${"hoge\r\nhoge"} などせずとも、直接PHPコードとして書けるものを指します。正規表現 [a-zA-Z_\x7f-\xff][a-zA-Z0-9_\x7f-\xff]* にマッチする文字列です。
ヒアドキュメント内で処理されるシーケンス
| 記述 | 実際の表示 | 意味 | 備考 |
|---|---|---|---|
\$ |
$ | ドル記号 | 【※2】 直後に変数名に使える文字がなければ省略可能 |
{$var} |
$var の値 | 変数展開 | |
$var |
$var の値 | 変数展開 | |
{$var[0]} |
$var[0] の値 | 変数展開 | |
$var[0] |
$var[0] の値 | 変数展開 | |
{$var['hoge']} |
$var['hoge'] の値 | 変数展開 | ↓ との違いに注意 |
$var[hoge] |
$var['hoge'] の値 | 変数展開 | ↑ との違いに注意 |
Nowdoc内で処理されるシーケンス
無し
正規表現エンジンレベルでのエスケープシーケンス
大部分は マニュアル 通りなので私からの説明は割愛しますが、 \ddd の項目にかなりややこしいケースがあるので、ここだけ説明を入れておきます。
処理の順序
-
2桁以下 のとき、まず10進数として扱い、その番目のキャプチャサブパターンが存在するときはそれを意味する。
1~99 であって、0は該当しない。 - 2桁以下で1に該当しなかったとき、3桁に満たない分だけ頭から0埋めされる。
- 0~7 の数字が続く分だけ、8進数コードとして処理する。それ以降はその文字自身を表す。

これホントにどうかと思うけど、上で述べたことには忠実に従ってるので…
エスケープ方法に関する注意
エスケープは2段構え
PHP言語レベルでのエスケープ と 正規表現エンジンレベルでのエスケープ の2段構えとなっていることに十分に留意してください。
例1: バックスラッシュのエスケープ
1. PHPコードレベルで文字列が読み取られる
第1引数は文字列 /\\/ として扱われます。
2. 正規表現エンジンレベルで文字列が読み取られる
パターンは文字 \ にマッチするものとなります。
preg_match('/\\\\/', $text);
preg_match('/\\\/', $text);
preg_match("/\\\\/", $text);
preg_match("/\\\/", $text);
例2: NULL文字のエスケープ
1. PHPコードレベルで文字列が読み取られる
第1引数は文字列 /\000/ または /\00/ または /\0/ として扱われます。
2. 正規表現エンジンレベルで文字列が読み取られる
パターンは NULL文字 にマッチするものとなります。
preg_match('/\\000/', $text);
preg_match('/\\00/', $text);
preg_match('/\\0/', $text);
preg_match('/\000/', $text);
preg_match('/\00/', $text);
preg_match('/\0/', $text);
preg_match("/\\000/", $text);
preg_match("/\\00/", $text);
preg_match("/\\0/", $text);
PCRE正規表現関数は、パターンに関してはバイナリセーフでないので、NULL文字をそのまま渡すことが出来ません。
【2022.12.15 追記】 PHP 8.2 からバイナリセーフになりました。
|
PCRE (preg_match) |
鬼車 (mb_ereg) |
POSIX (ereg) |
|
|---|---|---|---|
| パターンはバイナリセーフか | × PHP 8.2 以降では ○ |
○ | × |
| 検索対象文字列はバイナリセーフか | ○ | ○ | × |
正規表現エンジンに対して無駄なエスケープは行わない
エスケープ不要な文字に関してエスケープをすることは可能な限り控えましょう。
PHP言語レベルでの「省略可能」については、
「本来エスケープしなければならないものをエスケープしなくても動く」
というニュアンスでしたが、こちらは逆に
「本来エスケープしてはいけないものをエスケープしても動く」
という解釈になると思います。
特に 文字クラス に関して冗長なエスケープをする人が数多く見られるので、エスケープが必要なものを列挙しておきます。
]\:-
^(※先頭にくる場合のみ) -
/(デリミタに使った文字)
以上です。 [ や - の エスケープいらないの? って思う人も多いかもしれませんが、本当にこれだけです。先頭以外の ^ はエスケープ不要です。 - にマッチさせたい場合は、エスケープするのではなく、文字クラスの 先頭 か 末尾 に入れるのが正解です。
【重要な追記】
鬼車 (mb_ereg) の場合は [ のエスケープが必要です。
正規表現関数の選択に関する注意
正規表現関数を使わずに実現できるかどうかを最初に検討する
無意味に処理速度の遅い正規表現関数を使うのはやめましょう。
例1: 文字列の検索
正規表現の機能を利用していない単純な検索処理があります。
if (preg_match('/abc/', $str)) {
echo '"abc" found.';
}
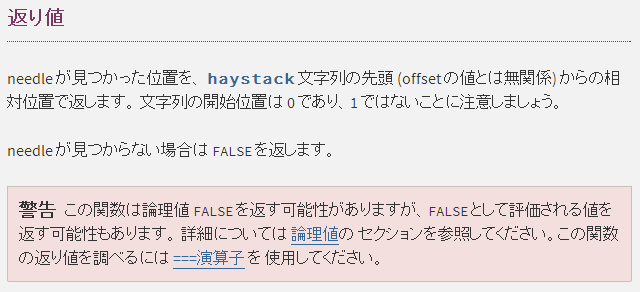
この処理は strpos 関数で実現できます。
if (strpos($str, 'abc') !== false) {
echo '"abc" found.';
}
比較演算子に != ではなく !== を用いていることに注意してください。ドキュメント上に警告があります。
例2: 文字列の削除
改行コードをすべて削除する処理があります。
$str = preg_replace("/[\r\n]/", '', $str);
この処理は str_replace 関数で実現できます。 strtr 関数でも実現できますが、処理速度は前者の方が高速です。
$str = str_replace(array("\r", "\n"), '', $str);
$str = strtr($str, array_fill_keys(array("\r", "\n"), ''));
例3: 文字列の置換
改行コードをすべてに \r\n に統一する処理があります。
$str = preg_replace("/\r\n|\r|\n/", "\r\n", $str);
この処理は strtr 関数で実現できます。
$str = strtr($str, array_fill_keys(array("\r\n", "\r", "\n"), "\r\n"));
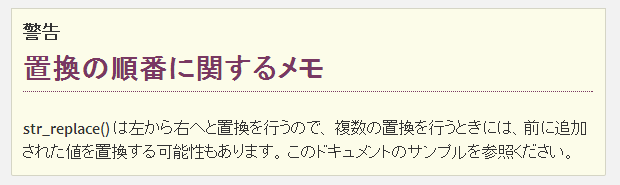
str_replace 関数では実現できません。その理由はドキュメントにも強調的に書かれています。
例4: マルチバイト文字列の置換
str_replace 関数はマルチバイト文字列の検知に対応していませんが、 UTF-8 を採用している場合は問題なく使用することが出来ます。
$str = str_replace("あいうえお", "かきくけこ", $str);
その理由は 「マルチバイト非対応関数で文字化け発生 str_replace() と mb_ereg_replace」 で解説されています。 ASCII の上位互換コードと言われる UTF-8 ならではの特性です。
split 関数はPOSIX正規表現関数である
どこにも ereg の文字が見当たらないので 「文字列を指定した文字列で分割する関数」 だと思い込む初心者さんが非常に多いのですが、これはPOSIX正規表現関数に該当します。本当に求められているのはこの関数ではなく explode 関数です。
POSIX正規表現関数は全て非推奨関数である
POSIX正規表現関数は公式マニュアル上で 非推奨 であると警告されています。検索対象の文字列がバイナリセーフで無いという致命的な欠陥を抱えていることもあり、セキュリティ的に危険なのでこの関数は絶対に使わないでください。
UTF-8 ならばPCRE正規表現関数を使う
PCRE正規表現関数を使うか鬼車正規表現関数を使うか迷うところですが、前者で比較的利用機会の多い preg_match_all 関数に相当する mb_ereg_all のような関数が後者では実装されていません。UTF-8 であればどちらでもOKなので、特に理由がなければ前者を選択しておいた方が無難でしょう。
PCRE正規表現関数の修飾子やメタ文字に関する注意
u 修飾子を使用する目的
PCRE正規表現関数でマッチングの単位を 1バイト から UTF-8 1文字 に変更したい場合、 u 修飾子を利用しますが、必ずしもマルチバイト文字列を含むパターンを扱う際に必要だとは限りません。
不要な場合
preg_match('/あ|い/u', $str);
-
u修飾子がある
→ 文字列あまたはいにマッチ -
u修飾子がない
→ バイト列E38182またはE38184にマッチ
必要な場合
preg_match('/[あい]/u', $str);
-
u修飾子がある
→ 文字あいのいずれかにマッチ -
u修飾子がない
→ バイトE38182E38184のいずれかにマッチ
u 修飾子の副作用的効果
-
preg_match 関数または preg_match_all 関数で 不正なUTF-8シーケンス を検知したとき、返り値は
FALSEになります。この性質を利用してエンコーディングバリデーションを行うことも出来ます。詳しくは 「UTF-8を想定して、不正なバイト列が含まれていないかを1行でチェックする」 で解説しています。 -
preg_replace 関数または preg_replace_callback 関数で 不正なUTF-8シーケンス を検知したとき、返り値は
NULLになります。 -
preg_match 関数または preg_match_all 関数で
PREG_OFFSET_CAPTUREフラグを指定したとき、オフセットの単位が バイト から 文字 に変化します。
^ と \A 、 $ と \Z と \z の違いを知る
^ |
\A |
|
|---|---|---|
| 通常時 | 先頭にマッチ | 先頭にマッチ |
| マルチラインモード(m修飾子) | 先頭または 改行の直後 にマッチ | 先頭にマッチ |
$ |
\Z |
\z |
|
|---|---|---|---|
| 通常時 | 末尾または 末尾の改行の直前 にマッチ | 末尾または 末尾の改行の直前 にマッチ | 末尾にマッチ |
| マルチラインモード(m修飾子) | 末尾または 改行の直前 にマッチ | 末尾または 末尾の改行の直前 にマッチ | 末尾にマッチ |
シビアな正規表現では $ や \Z は使うべきでないと思います。プログラミング言語によってこのあたりは若干変わってきますが、PHPではこのような実装となっています。
可能な限り最長マッチは独占的にする
繰り返しパターンに関して、 最短マッチ , 最長マッチ はご存じの人が多いと思いますが、 独占的最長マッチ の存在も忘れないでください。
| 最短マッチ | 最長マッチ | 独占的最長マッチ |
|---|---|---|
| ?? | ? | ?+ |
| *? | * | *+ |
| +? | + | ++ |
| {3, 8}? | {3,8} | {3,8}+ |
| {5,}? | {5,} | {5,}+ |
【例】
ABCDE123EFG45
のような文字列の末尾の数字のみを削除して
ABCDE123EFG
のようにしたい
$str = 'ABCDE123EFG45';
$str = preg_replace('/\\d+\\z/', '', $str);
-
1にマッチし、次の文字を調べる。 -
12にマッチし、次の文字を調べる。 -
123にマッチし、ここで\d+のマッチはいったん終了する。 -
123のときこの場所は\zにはマッチしないので、バックトラックを行う。 -
12のときこの場所は\zにはマッチしないので、バックトラックを行う。 -
1のときこの場所は\zにはマッチしない。よってここはマッチ失敗とする。 -
4にマッチし、次の文字を調べる。 -
45にマッチし、ここで\d+のマッチはいったん終了する。 -
45のときこの場所は\zにはマッチする。よってここはマッチ成功とする。
このように最長マッチだと無駄にバックトラックが行われてパフォーマンスが低下してしまいますが、代わりに 独占的最長マッチ を用いると・・・
$str = 'ABCDE123EFG45';
$str = preg_replace('/\\d++\\z/', '', $str);
-
1にマッチし、次の文字を調べる。 -
12にマッチし、次の文字を調べる。 -
123にマッチし、ここで\d+のマッチは終了する。 - この場所は
\zにはマッチしない。よってここはマッチ失敗とする。 -
4にマッチし、次の文字を調べる。 -
45にマッチし、ここで\d+のマッチは終了する。 - この場所は
\zにはマッチする。よってここはマッチ成功とする。
このように無駄なバックトラックを防ぐことが出来ます。