コードはこちら: 全てのコードはGithub上のIpython Notebookでも公開しています。
この投稿では、1から3階層のシンプルなニューラルネットワークを構築します。出てくる全ての数学の解説はしませんが、可能な限り必要な部分は、わかりやすく説明したいと思います。数学の詳細が気になる方は、英語が多いですが参考になるリンクを下記で記載します。
※この投稿の読者は最低限、微分と機械学習の基礎(クラシフィケーションや正則化など)を知っていると仮定します。更にGradient Descent(勾配降下法)のような最適化技術を知っていれば、なお良しです。ただ上記を知らなくても、ニューラルネットワークに興味のある方なら楽しめる内容だと思います。
それではまず、なぜライブラリーを使わずに一からニューラルネットワークを構築する必要があるのでしょうか?後の投稿でPyBrainやTensorflowのようなニューラルネットワーク・ライブラリーを使う予定ですが、その理由としては、1度でも一からニューラルネットワークを構築するという経験はすごく価値があるからです。どのようにしてニューラルネットワークは動くのか・構築されているのかを知ることによって、いざモデルをデザインするぞ!という時に役立ちます。
1つ注意点として、この投稿では理解しやすさに重きをおいているため、下記のコードは効率的に書かれていません。効率的なコードの書き方は後の投稿で解説します。その時は、Theanoを使います。
データを生成する
さて、まずはデータを生成します。ラッキーな事にScikit-learnは使えるデータセットの生成キットがあるので、わざわざ自分たちでコードを書く必要がありません。今回は、make_moons機能を使って月型のデータを作ってみましょう。
# データを生成してプロットする
np.random.seed(0)
X, y = sklearn.datasets.make_moons(200, noise=0.20)
plt.scatter(X[:,0], X[:,1], s=40, c=y, cmap=plt.cm.Spectral)
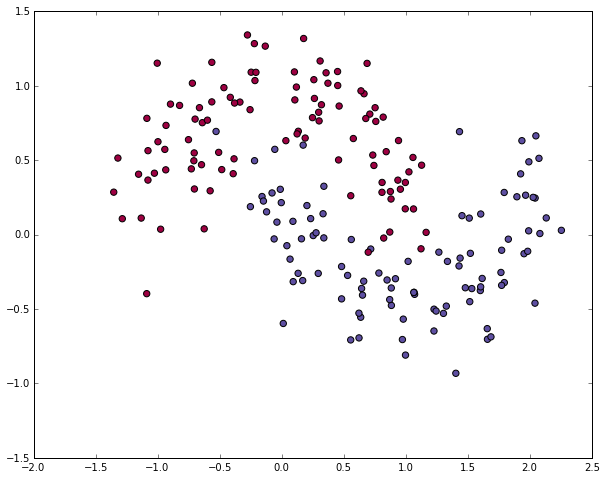
生成したデータのクラスは、二通りあります (グラフ上の赤と青の点)。例えば、青い点を男性、赤い点を女性の患者データサンプルとして、XとY軸を特定の測定数値と考えてみてください。
私達の目標は分類モデルを機械学習させて、サンプルポイント毎に正しいクラスを予測して与えることです。注意しないといけないのは、このデータは直線では分類が不可能であるという点です。そのため、ロジスティック回帰のようなLinear Classifiers (線形分類器)では、多項式などNon-linear features (非線形特性)を自分で作るなどしない限り、良いモデルを作ることはできません。ただし、今回のデータに関しては、多項式特性を率いれば良いモデルを作ることは可能です。
ニューラルネットワークを率いれば、この問題を解決できます。なぜならFeature Engineering (特性エンジニアリング)をする必要がないからです。ニューラルネットワークの隠れ層が特性を探しだしてくれます。
ロジスティック回帰
ニューラルネットワークの説明をする前にまず、ロジスティック回帰モデルを学習させてみましょう。インプットデータはX/Y軸上のポイントでアウトプットデータはそのクラス (0または1)です。ここでは下記のニューラルネットワークの解説の下準備なのでschikit-learnを使ってロジスティック回帰モデルを構築してみましょう。
# ロジスティック回帰モデルを学習させる
clf = sklearn.linear_model.LogisticRegressionCV()
clf.fit(X, y)
# 決定境界をプロットする
plot_decision_boundary(lambda x: clf.predict(x))
plt.title("Logistic Regression")
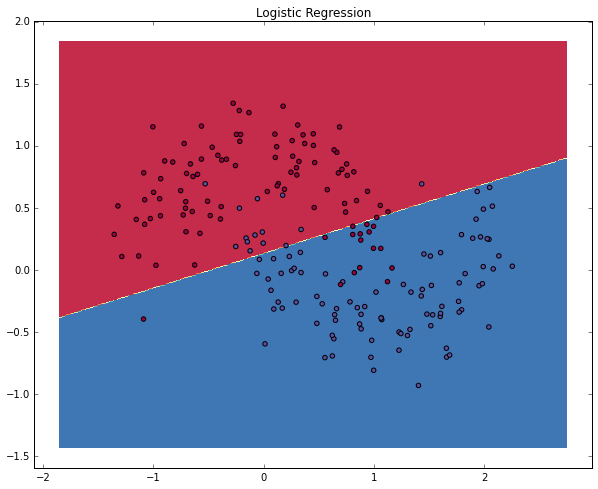
直上のグラフではロジスティック回帰モデルを学習させてDecision Boundary (決定境界)を境にクラスの分類をしています。この境界線は直線を率いて可能な限りクラス分けをしていますが、データの「月型」を認識することはできていません。
ニューラルネットワークを学習させる
それでは、3層のニューラルネットワーク (1インプット層、1隠れ層、1アウトプット層)を構築してみましょう。インプット層のノード (下記図の円)の数はデータの次元数です (今回は2)。そしてアウトプット層のノードの数はクラスの数で、今回はこちらも2つ (ちなみに2つのクラスなので1か0の1つをアウトプット・ノードにすることも可能ですが、後で複数のクラスを扱うのを考慮して今回は2つのノードを使います)。ネットワークのインプットはポイント(X、Y)で、アウトプットはクラス0 (女性)、クラス1 (男性)のどちらかになる確率です。下記の図を参照してみてください。
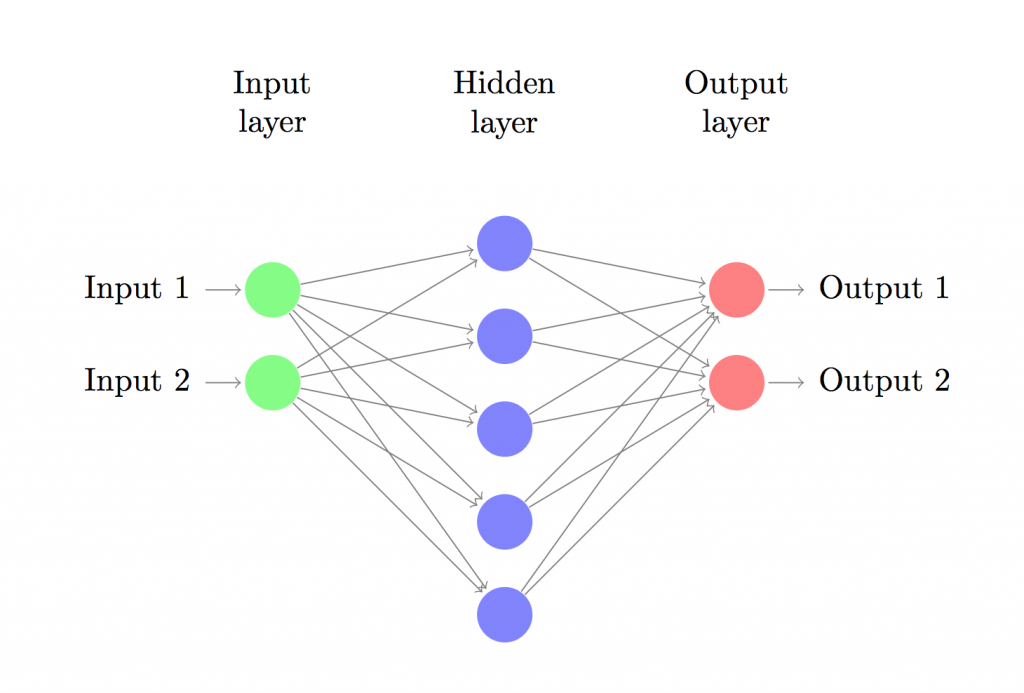
次に、隠れ層の次元 (ノードの数)を決めます。隠れ層ノードの数が増えれば増えるほど複雑なモデル構築が可能です。一方で、ノードの数が増えるほど、パラメーターの学習と予測にコンピューティングパワーが必要になります。また、パラメーターの数が増えるほどオーバーフィットのリスクが増してしまうため注意する必要があります。
隠れ層の数はどうやって選べば良いでしょうか。一般的なガイドラインはあるものの、選び方はケースバイケースで、サイエンスというよりもアートに近いと考えてください。下記では、いくつか違う隠れ層のノード数を試してみて、どのようにアウトプットに影響をあたえるのかを見てみます。
もう一つ決めないといけないのが、隠れ層のアクティベーション関数です。これはインプットデータを変形 (transform)させてアウトプットするための関数です。非線形アクティベーション関数を率いることで非線形データを学習させることができます。アクティベーション関数の一般的な例として、Tanh、シグモイド関数、そしてReLUsがあります。今回は様々なケースで比較的よい成果を出せるtanhを使ってみます。この関数の便利な特性として元の値を率いて微分した値を計算できる点です。例えば、$tanhx$の微分値は、$1 - tanh^2x$です。そのため、$tanhx$を一度計算すると後で再利用が可能です。
今回は、アウトプットに確率を与えたいので、アウトプット層のアクティベーション関数にSoftmax関数を使います。この関数を率いることで非確率な数値から確率に変換できます。ロジスティック回帰モデルに詳しい方は、Softmax関数を複数クラスの汎化版として考えてみてください。
ニューラルネットワークの予測のしくみ
今回のニューラルネットワークはforward propagationという一種の行列乗算と上記で定義したアクティベーション関数の応用を使います。インプットxが2次元の場合、予測値 $\hat{y}$(こちらも2次元)は下記のように計算します。
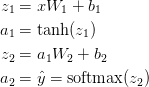
$z_i$はインプット層i、$a_i$はアクティベーション関数で変換後のアウトプット層iです。$W_1$ ,$b_1$, $W_2$, $b_2$はネットワークのパラメターで、学習用データから学ぶ必要があります。ネットワーク層間の行列変換と考えてよいでしょう。上記の行列乗算を見てみると行列の次元数が見て取れます。例えば隠れ層500ノードを使うと、$W_1 \in \mathbb{R}^{2 \times 500}$, $b_1 \in \mathbb{R}^{500}$, $W_2 \in \mathbb{R}^{2 \times 500}$, $b_2 \in \mathbb{R}^{2}$となります。そのため、隠れ層のサイズを増やすとパラメーターも増える理由がわかりますね。
パラメーターを学習させる
パラメーターを学習させるということは、学習用データ上のエラー値を最小化するパラメーター ($W_1$ ,$b_1$, $W_2$, $b_2$)を探す、ということです。さてエラー値はどうやって定義するのでしょう?エラー値を測る関数をLoss関数と言います。Softmaxの場合、一般的に使われるLoss関数交差エントロピー最小化 (negative log likelihoodとも呼ばれています)を率います。もし、N学習用データがありCクラスがある時の正解値yに対して予測値$\hat{y}$のLoss関数は下記のように書くことができます。
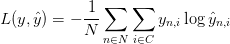
この方式は複雑なように見えますが、その役割は、学習用データを足し合わせ間違えてクラスを予測した時に、その値をLossに足す、というシンプルなものです。そのため予測値$\hat{y}$と正解値yの2つの確率分布が遠く離れていればいるほど、Lossは大きくなります。そのため、Lossを最小化するパラメーターを探すということは、学習用データの尤度を最大化させることと同じことです。
Loss最小値を計算するには、Gradient Descent (勾配降下)を使います。今回はシンプルなバッチ勾配降下 (学習率は定数)を率いますが、確率的勾配降下やミニバッチ勾配降下がより実用的でしょう。また学習率も徐々に小さくしていく方がより実践的です。
インプットとして、勾配降下のパラメーター($\frac{\partial{L}}{\partial{W_1}}$,$ \frac{\partial{L}}{\partial{b_1}}$,$ \frac{\partial{L}}{\partial{W_2}}$, $\frac{\partial{L}}{\partial{b_2}}$)に対してLoss関数の傾斜 (ベクトルの微分値)を計算する必要があります。この傾斜を計算するためにback-propagationアルゴリズムを使います。このアルゴリズムは、アウトプットから傾斜を効率的に計算する方法です。この数学的解説に興味のある人はこちらとこちらの解説を読んでみてください (英語)。
back-propagationを使うと下記が成り立ちます。
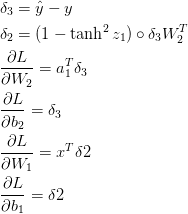
実際にコードを書いてみる
これまでの学問的な知識はおしまいにして、実際にコードを書いてみましょう!まずは勾配降下のための変数とパラメーターを設定してみましょう。
num_examples = len(X) # 学習用データサイズ
nn_input_dim = 2 # インプット層の次元数
nn_output_dim = 2 # アウトプット層の次元数
# Gradient descent parameters (数値は一般的に使われる値を採用)
epsilon = 0.01 # gradient descentの学習率
reg_lambda = 0.01 # regularizationの強さ
上記で定義したLoss関数を書いてみます。これを率いてモデルの性能をチェックできます。
# 全Lossを計算するためのHelper function
def calculate_loss(model):
W1, b1, W2, b2 = model['W1'], model['b1'], model['W2'], model['b2']
# 予測を算出するためのForward propagation
z1 = X.dot(W1) + b1
a1 = np.tanh(z1)
z2 = a1.dot(W2) + b2
exp_scores = np.exp(z2)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
# Lossを計算
corect_logprobs = -np.log(probs[range(num_examples), y])
data_loss = np.sum(corect_logprobs)
# Lossにregulatization termを与える (optional)
data_loss += reg_lambda/2 * (np.sum(np.square(W1)) + np.sum(np.square(W2)))
return 1./num_examples * data_loss
アウトプット層を算出するためのHelper関数を書きます。上記で解説したforward propagationを率いて、一番高い確率を返します。
# Helper function to predict an output (0 or 1)
def predict(model, x):
W1, b1, W2, b2 = model['W1'], model['b1'], model['W2'], model['b2']
# Forward propagation
z1 = x.dot(W1) + b1
a1 = np.tanh(z1)
z2 = a1.dot(W2) + b2
exp_scores = np.exp(z2)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
return np.argmax(probs, axis=1)
最後に、ニューラルネットワークを生成するコードを書きます。上記で解説したbackpropagationの微分値を使ってバッチ勾配降下を書きます。
# This function learns parameters for the neural network and returns the model.
# - nn_hdim: Number of nodes in the hidden layer
# - num_passes: Number of passes through the training data for gradient descent
# - print_loss: If True, print the loss every 1000 iterations
def build_model(nn_hdim, num_passes=20000, print_loss=False):
# Initialize the parameters to random values. We need to learn these.
np.random.seed(0)
W1 = np.random.randn(nn_input_dim, nn_hdim) / np.sqrt(nn_input_dim)
b1 = np.zeros((1, nn_hdim))
W2 = np.random.randn(nn_hdim, nn_output_dim) / np.sqrt(nn_hdim)
b2 = np.zeros((1, nn_output_dim))
# This is what we return at the end
model = {}
# Gradient descent. For each batch...
for i in xrange(0, num_passes):
# Forward propagation
z1 = X.dot(W1) + b1
a1 = np.tanh(z1)
z2 = a1.dot(W2) + b2
exp_scores = np.exp(z2)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
# Backpropagation
delta3 = probs
delta3[range(num_examples), y] -= 1
dW2 = (a1.T).dot(delta3)
db2 = np.sum(delta3, axis=0, keepdims=True)
delta2 = delta3.dot(W2.T) * (1 - np.power(a1, 2))
dW1 = np.dot(X.T, delta2)
db1 = np.sum(delta2, axis=0)
# Add regularization terms (b1 and b2 don't have regularization terms)
dW2 += reg_lambda * W2
dW1 += reg_lambda * W1
# Gradient descent parameter update
W1 += -epsilon * dW1
b1 += -epsilon * db1
W2 += -epsilon * dW2
b2 += -epsilon * db2
# Assign new parameters to the model
model = { 'W1': W1, 'b1': b1, 'W2': W2, 'b2': b2}
# Optionally print the loss.
# This is expensive because it uses the whole dataset, so we don't want to do it too often.
if print_loss and i % 1000 == 0:
print "Loss after iteration %i: %f" %(i, calculate_loss(model))
return model
隠れ層が3つのニューラルネットワーク
それでは、隠れ層が3つの場合のネットワークを生成します。
# 3次元の隠れ層を持つモデルを構築
model = build_model(3, print_loss=True)
# 決定境界をプロットする
plot_decision_boundary(lambda x: predict(model, x))
plt.title("Decision Boundary for hidden layer size 3")
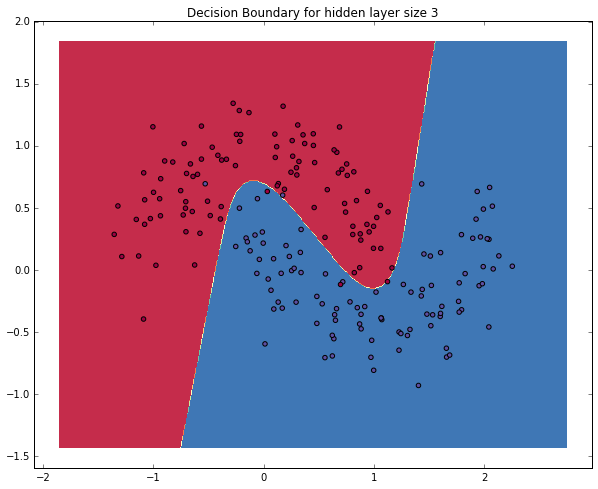
うまく月形を認識しました!ニューラルネットワークによってクラスを程よく分けることができていますね。
隠れ層の適合サイズをチェック
上記では隠れ層3つを選びました。下記では隠れ層の数を変えながら比較してみましょう。
plt.figure(figsize=(16, 32))
hidden_layer_dimensions = [1, 2, 3, 4, 5, 20, 50]
for i, nn_hdim in enumerate(hidden_layer_dimensions):
plt.subplot(5, 2, i+1)
plt.title('Hidden Layer size %d' % nn_hdim)
model = build_model(nn_hdim)
plot_decision_boundary(lambda x: predict(model, x))
plt.show()

上記の図を見てみると、低次元の隠れ層の場合 (3,4あたり)データのパターンをうまくつかめています。一方で、高次元だとオーバーフィットの恐れがあるようです。そうなってしまえば、データの真の形を捉えるのではなくデータの丸暗記をしているようなものです。もしテストデータを率いてモデルをチェックする場合、低次元の隠れ層だとより正確に予測できるはずです。オーバーフィットを強めに正則化するよりも、ちょうど良いサイズの隠れ層を選んだ方がより(コンピューター的に)「経済的」でしょう。
さて、今回は一からライブラリーを使わずにネットワークを作ってみました。次はニューラルネットワーク・ライブラリーを使って更に深くディープラーニングを解説してみます。
*wildMLブログを書いているDenny Britzと共に執筆