再帰型ニューラルネットワーク(RNN)は自然言語処理の分野で高い成果をあげ、現在最も注目されているアルゴリズムの一つです。しかしながら、その人気が先走りして実際にRNNがどのように動くのか、構築するのかを解説する書籍は限られているように思います。この投稿はその部分にフォーカスを当てて友人のDenny(WildMLブログの著者)と一緒に書きました。
さてRNNベースの言語モデルを解説したいと思います。言語モデルの用途は2つあります。1つ目は文章が実際にどのくらいの確率で現れるのかのスコアリングをすること。このスコアは文法的に、セマンティクス的に正しいかどうかの判断基準となります。このようなモデルは例えば機械翻訳などに使われています。次に2つ目ですが、言語モデルは新たなテキストを生成することができる点 (ちなみに個人的にこちらの方がよりCoolな用途だと思っています)。また、英語ですがAndrej Karpathyのブログでは単語レベルのRNN言語モデルを解説・開発していますので時間のある方はぜひ一度読んでみてください。
読者はニューラルネットワークについて初歩的な事はおさえていると仮定します。もしそうでない場合、ライブラリーを使わずにPythonでニューラルネットワークを構築してみよう、を読んでみてください。こちらの投稿では非再帰型のネットワークモデルの解説・構築をしています。
RNN (Recurrent Neural Network)とは?
RNNの利点は文章など連続的な情報を利用できる点です。従来のニューラルネットワークの考え方はそうではなく、インプットデータ(またアウトプットデータも)は互いに独立の状態にある、と仮定します。しかしこの仮定は多くの場合、適切ではありません。例えば次の言葉を予測したい場合、その前の言葉が何だったのかを知っておくべきですよね?RNNのRはReccurent(再帰)という意味で、直前の計算に左右されずに、連続的な要素ごとに同じ作業を行わせることができます。言い方を変えると、RNNは以前に計算された情報を覚えるための記憶力を持っています。理論的にはRNNはとても長い文章の情報を利用することが可能です。ただ実際に実装してみると2,3ステップくらい前の情報しか覚えられません(以下で更にこの件を掘り下げます)。さて、一般的なRNNを下記図表で見てみましょう。
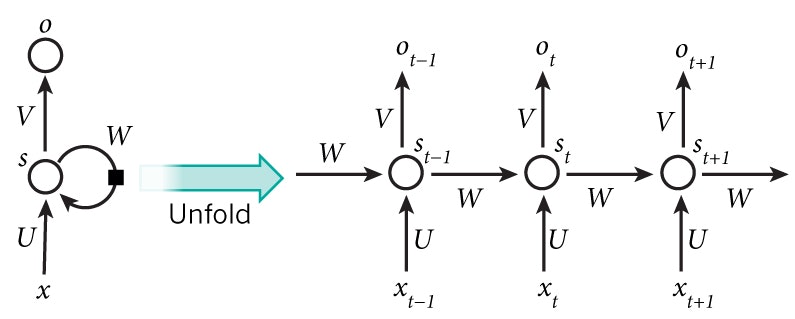
A recurrent neural network and the unfolding in time of the computation involved in its forward computation. Source: Nature
上記の図表はRNNの内部を展開しています。展開する、という意味は単に順序付けされたネットワークを書く、ということです。例えば、5ワードからなる文章があるとすれば、展開されたネットワークは1層1ワードで5層のニューラルネットワークになります。RNNを計算する際の公式は下記のようになります。
$x_t$は$t$ステップ時のインプットです。例えば、$x_1$は次の言葉に紐付いたベクトルです。
$s_t$は$t$ステップ時の隠れ要素です。これがネットワークのMemory(記憶力)となります。$s_t$は直前の隠れ要素をベースに計算されます。そしてこのステップでのインプットが$s_t = f (U x_x + W s_{t-1})$となります。$f$関数はtanhやReLUなどの非線形型が一般的です。最初の隠れ要素を計算するのに必要な$s_{-1}$は普通0から始めます。
$o_t$は$t$ステップ時のアウトプットです。例えば、次の言葉を予測したい場合、$o_t$は予測確率のベクトルになります ($o_t = softmax(V s_t)$)。
RNNができること
RNNは自然言語処理分野で、すでに色々な成功事例があります。RNNが少しわかってきたところで、最も使われているRNNの一つであるLSTMを紹介します。LSTMはRNNよりも距離のあるステップの関係性を学習するのに優れています。ただLSTMも基本的には今回構築するRNNと同じアルゴリズム構造なので心配しないでください。違いは隠れ要素を計算する方法が違うだけです。LSTMについては今後カバーする予定ですので、興味のある方はメルマガ登録してみてください。
言語モデルと文章生成
言語モデルは、連続した言葉の中で、直前の言葉を利用して次の言葉の出現確率を予測することができます。どのくらいの頻度で文章が現れるのかを測ることができるため、機械翻訳に活用されています。次の言葉を予測できることのもう一つ良いことは、アウトプットの確率からサンプリングすることで新しい文章を生成できるGenerativeモデルを得られる点です。そのため、学習用データ次第で様々なものを生成することができます。言語モデルでは、インプットデータは連続的な言葉の列です。そして、アウトプットは予測された言葉の列になります。ネットワークを学習させる時、$t$ステップのアウトプットを次の言葉にしたいため、$o_t = x_{t+1} $とします。
英語になりますが、言語モデルとテキスト生成に関する論文で参考になるものを下記に記載します。
- Recurrent neural network based language model
- Extensions of Recurrent neural network based language model
- Generating Text with Recurrent Neural Networks
機械翻訳
機械翻訳は、ソース言語(例えば日本語)の文章をインプットとする点で、言語モデルと似ています。そしてアウトプットは例えば英語の文章です。言語モデルとの違いは、アウトプットデータは完全なインプットデータを読み込んだ後に処理を開始するという点です。そのため、翻訳された文章の最初の言葉は完全なインプット文章の情報が必要になります。
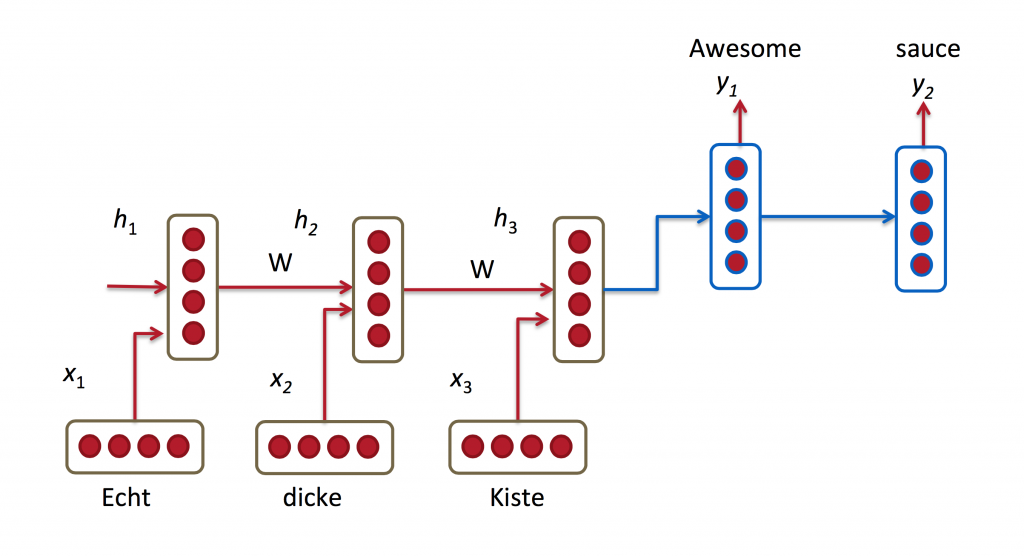
RNN for Machine Translation. Image Source: http://cs224d.stanford.edu/lectures/CS224d-Lecture8.pdf
英語になりますが、機械翻訳に関する論文で参考になるものを下記に記載します。
- A Recursive Recurrent Neural Network for Statistical Machine Translation
- Sequence to Sequence Learning with Neural Networks
- Joint Language and Translation Modeling with Recurrent Neural Networks
スピーチ認識
音波からの連続的な音響信号をインプットとして、連続的な音声セグメントを確率付けして予測します。
英語になりますが、スピーチ認識に関する論文で参考になるものを下記に記載します。
画像の概要生成
Convolutional Neural NetworksとRNNを使って、ラベルがついていない画像の概要生成ができます。下記の画像からわかるようにかなり高い確率で概要生成することが可能です。
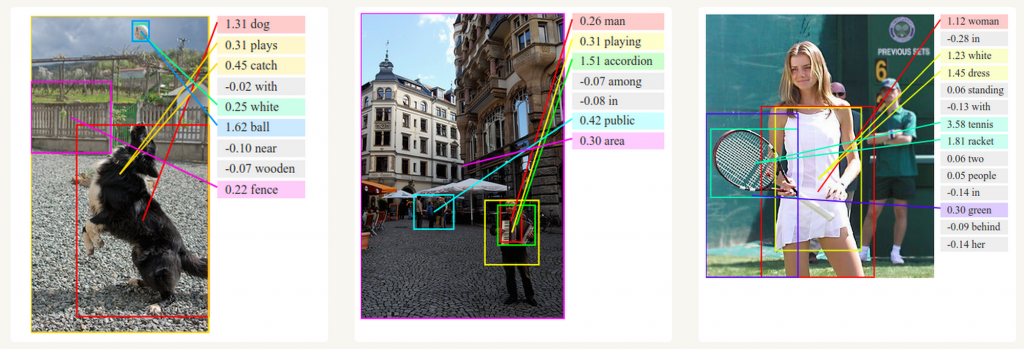
Deep Visual-Semantic Alignments for Generating Image Descriptions. Source: http://cs.stanford.edu/people/karpathy/deepimagesent/
RNNを学習させる
RNNの学習は従来のニューラルネットワークを学習させるのと似ていますが、RNNの場合、backpropagationアルゴリズムを少し変えて使います。RNNのパラメーターはネットワーク上の全ステップで使われているため、ステップ毎の勾配は現在のステップの計算以外にも前のステップの計算も使います。例えば、$t = 4$の勾配を計算するために、3ステップ後ろに戻って勾配を足し合わせる必要があります。これをBackpropagation Through Time (BPTT)と呼びます。もし意味がわからなくなってきても心配しないでください。後の投稿で詳細を書く予定です。今のところは、BPTTを使って学習させたRNNは遠ければ遠いステップほど学習させるのが難しいと覚えておいてください。この問題を解決するためにLSTMのようなアルゴリズム (RNNの一種)が開発されています。
RNNの応用
近年の研究者の開発努力によって従来のRNNの欠点を解消できる、より洗練されたRNNモデルが登場しています。それは今後の投稿で解説したいと思いますが、この投稿では、簡単に紹介したいと思います。
Bidirectional RNN
Bidirectional RNNでは、$t$のアウトプットは直前の要素だけをベースに計算するのではなく、後の要素も計算に含めます。例えば、前の部分に出てこない言葉を予測する場合、後の言葉も含め確率を算出するべきです。そのため、Bidirectional RNNは、2つのRNNが重なりあっているもの、と考えてみてください。アウトプットは2つの隠れ要素から計算されます。
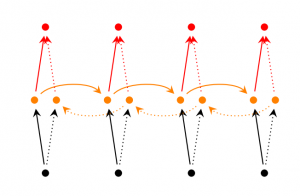
Deep (Bidirectional) RNN
Deep RNNはBidirectional RNNに似ていますが、ステップごとに複数の層を持つ、という点が異なっています。実装してみると、より高い学習能力を得られるでしょう (まだ多くの学習データが必要ではありますが)。
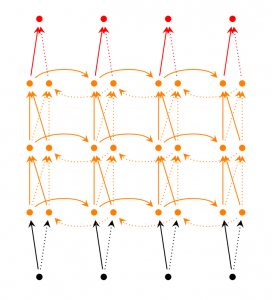
LSTMネットワーク
少し触れましたが、LSTMネットワークは最近人気が出てきたRNNの一つです。LSTMはRNNと基本的に同じ構造ですが、隠れ要素を計算するのに異なる関数を率いています。LSTMのMemoryはCellと呼ばれており、直前の要素$h_{t-1}$と現在の要素$x_t$をインプットとしたブラックボックスだと考えてください。ブラックボックス内部ではMemoryにストアするCellを選びます。そして、直前の要素、現在の要素、インプットを組み合わせます。その結果、遠く離れた言葉の関係性をうまく抽出することが可能となります。LSTMは少し理解が難しいですが、興味があれば英語ですが、こちらの解説がわかりやすいので参考にしてみてください。