正規表現の "先読み" / "後読み" を、分かりにくいと感じるすべての人にお送りします。
--- 追記:2017/06/04
コメントにて、ご指摘を頂いております。![]()
当記事の解釈には誤りがあります。コメントのご指摘内容をご覧いただければ幸いです。
当記事の主旨としては、"先読み・後読み" よりも "ルックアヘッド" の方が、意味を捉えやすいのでは?というものでしたが.. そもそも私の、「lookahead」の解釈(とくに、look の主語はどれなのかという部分だと思います)に、勘違いがありました。
ですので、いまのところ当記事の主題は、「"先読み" でも、"ルックアヘッド” でも、どちらでもよいけど、しっかりと厳密に理解しよう!(反省)」となります。
コメント本当にありがとうございました! ![]()
---
結論を先に書きます
(?=a) のような正規表現は、一般的に「先読み」と呼ばれています。
ですが、それはやめて、英語圏で言われている通りに
- lookahead (ルックアヘッド)
と呼ぶようにすると、より理解がしやすくなると思います。
同様に、 「後読み」と呼ばれている (?<=a) は、
- lookbehind (ルックビハインド)
と呼ぶと良いと思っています。
意味がわかりやすいから
- look ahead (ルックアヘッド)は、... 前を見ろ
- look behind (ルックビハインド)は、... 後ろを見ろ
です。
(もし、この段階で、 look = 見る、 ahead = 前、 behind = 後ろ ということが全く分からない!という場合は、当主張には全く同意できないかもしれません。)
たとえば、
/b(?=a)/
これは、"ルックアヘッド" 「前を見ろ」です。ですので、**「 a の前の b を見ろ」**です。
一方、
/(?<=a)b/
これは、"ルックビハインド" 「後ろを見ろ」です。ですので、**「 a の後ろの b を見ろ」**です。
そのままで、簡単な話ですよね?
先に読むってなに?意味が分かりにくい。
初めて、"先読み" / "後読み" に出会ったときのことを思い返してみました。僕の場合は、b(?=a) という記号の並びより先に、先読み / 後読み という言葉に出会いました。
/b(?=a)/
これを 先読み と云う。「 b の前に (?=a) を読む 」 という印象 を受けました。これは、百歩譲って納得がいきそうです。まずは a を探して、そして、その前に b が居るかを確認するようなフローを感じます。(この流れは後に 嘘 だと気づきます。)
では、こちらはどうでしょうか?
/(?<=a)b/
これを 後読み と云う。つまり.... 先に b を読んで、その後に (?<=a) を読む? えっと...うん。どういうことでしょうか?ちょっと、先読みと後よみがごちゃごちゃしてきてよくわかりません。たとえば /b(?=a)c/ これは、 a が先読みって、どういうことでしょうか?
... ![]()
となったのを覚えています。
さらに、否定的先読み、否定的後読み、ないしは、否定的戻り読み、肯定的先読みなどなど、これは、僕らに理解をさせないようにどこかの神さまが悪戯してるとしか思えません。
タイミングの問題じゃない
そうなんです。先読み、後読みと言われると、なんだか「先に読んだり、後に読んだり」タイミングが違うように感じます。「前を見ろ」、「後ろを見ろ」であれば、 「位置だけを示している」 ということが明々白々です。
これは、よく紹介されるように、アンカーの仲間と考えるべきなのです。
^ や $ と同じ仲間です。
「一番前」、「一番後ろ」と同じノリで、「 a の前」、「 a の後ろ」。ただそれだけのことです。
じっさいにタイミングを見てみると
/(?<=A)B/
を考えてみます。KABCD という文字列はマッチしますが、どのような順番で評価されるのか見てみます。
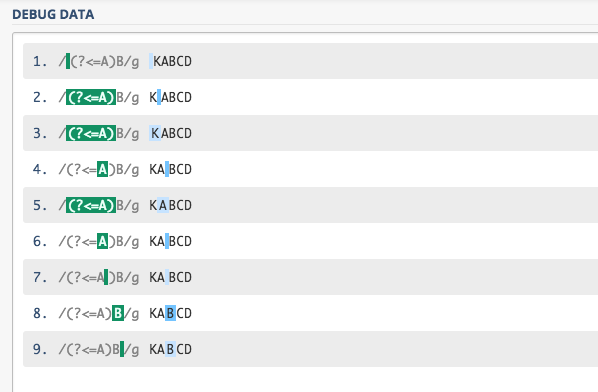
B を読んだ後に A を探すわけではありません。単純に、(?<=A) を探して、その後ろに B が居るかを確認 (ルックビハインド) しているんです。
イージーなのです。
ルックアヘッド も同じです。
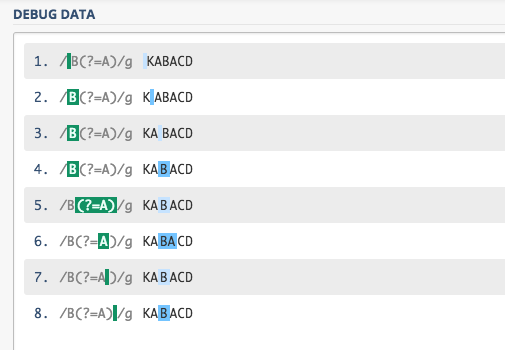
別に (?=A) を先に読んでるわけじゃないです。A の前に B が在るか を確認するのです。タイミングとしては、普通に B を評価して、その後ろに A が居るのかを確認しているのです。
タイミングは重要です
なぜならパフォーマンスに直結するからです。
当コラムでは、詳しく語ることはできませんが、流れを理解するとこ、または、感じることは重要だと思います。
そして、流れを感じると、否定系 (?!a) などの応用もすんなり理解できてしまうと思います。
ref. 正規表現のパフォーマンスの話...
事例を考えてみます
「渋谷様は 6:00 に渋谷駅に集合してください。」と言われていたことを思い出した渋谷さんは、急いで渋谷に向かった。
この文では、「渋谷」という名前の人物が出てきます。が、本当は、「田中」という名前だっとします。
- 渋谷さん
- 渋谷様
を 田中さん、田中様に置換したいです。つまり、(さん|様) の前の「渋谷」だけ を、「田中」に変更すればよいのです。ルックアヘッド。
pry > str = "「渋谷様は 6:00 に渋谷駅に集合してください。」と言われていたことを思い出した渋谷さんは、急いで渋谷に向かった。"
pry > str.gsub(/渋谷(?=さん|様)/, '田中')
=> "「田中様は 6:00 に渋谷駅に集合してください。」と言われていたことを思い出した田中さんは、急いで渋谷に向かった。"
なんだか、ルックアヘッド、ルックビハインドが簡単につかえるような気がしてきました。![]()
(事例を考えるのは、難しいです。拙い文ですみません。..)
最後に ネガティブ ルック~ を紹介します。
読み方は、まあ、なんでもいいと思います。
- (?!a) ... ネガティブ ルックアヘッド
- (?<!a) ... ネガティブ ルックビハインド
でもいいし、否定的ルックアップとかでもいいですね。本当になんでもいいです。
/b(?!a)/
a 以外の前に b が居るか? ってことを確認します。流れ的には、b を探して、その後ろが a かどうかを確認します。
なので、よくある、「先頭が hoge 以外」という条件は、流れ的には、まず、先頭を捕まえて、その後ろに hoge 以外がきてるか? ってことになります。
/^(?!hoge)/
ということです。 ![]()
僕は、これで「どこにも hoge を含まない」という条件が、以下のようになるもの、理解できるようになりました。
/^(?!.*hoge)/
まとめ
| 記号 | 読み方 |
|---|---|
| (?=a) | ルックアヘッド ( lookahed ) |
| (?<=a) | ルックビハインド ( lookbehind ) |
| (?!a) | 否定のルックアヘッド |
| (?<!a) | 否定のルックビハインド |
ルックアヘッド、ルックビハインドと呼べば、名が体を表しているように感じます。![]()
先読み、後読みという呼称は禁止にしませんか。(笑)
以上、ありがとうございました。![]()