概要
友達からファイルの分散処理を頼まれたので作りました。
イメージ的にはファイルの処理要求を書き込むと複数のPodが適当にタスクを分割しファイル処理を自動でやってくれるものです。
今回はs3上に保存されているファイルをダウンロードし、Kubernetes上の計算用Podでファイル処理(今回はハッシュ値計算)を行い、その結果をRDS上のmysqlサーバーに保存します。
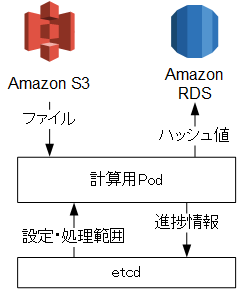
計算用PodはKubernetesを用いて複数配置し分散処理をさせたいため、etcdサーバーに設定を書き込み、各Podがタスクの内容を取得し処理するようにしました。
etcdサーバーに分割するPod数をもたせ、処理するファイル名の範囲を分割し処理します。
※ファイル名の範囲の分割をかんたんにするためファイル名は16進数を文字列化したものと仮定します。
なお、各ノードにetcdサーバーを配置(記事はこちら)していることが前提となります。
計算用Podの中身
計算用Podの中は3コンテナで構成されています。
なお、全コンテナは同じフォルダーをマウントしています。
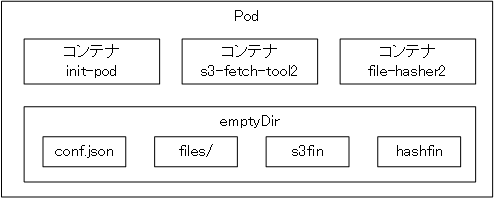
コンテナについて
- init-pod
etcdサーバーから処理内容やs3のキーなどを取得し全コンテナ共用で利用するファイルを初期化します。
また、etcdサーバーのパラメーターからs3の処理するファイル名の範囲を決定します。
本当はKubernetesのinit containersという機能を使う予定でしたがうまく動かなかったので他のコンテナの処理が終わるまでsleepします
他のコンテナの処理が終わった後etcdサーバーに終了を示すデータを書き込み新たな処理内容を取得します。 - s3-fetch-tool2
init-podが設定ファイルを生成した後s3からファイルをダウンロードします。
指定された共用フォルダーに上限10個ファイルが溜まるまでダウンロードします。
init-podで指定された範囲のファイルを全てダウンロードしたら完了を示すファイル(s3fin)を生成して他のコンテナが終了するまで待機します。 - file-hasher2
s3-fetch-tool2がダウンロードしたファイルのハッシュ値を求めRDS上のmysqlにハッシュ値を保存します。
ハッシュ値の計算アルゴリズムはetcd側で指定されたもので行います(後述)
s3-fetch-tool2が保存したファイルを全て保存したら完了を示すファイル(hashfin)を生成してinit-podの終了処理を待ちます。
ファイルについて
3コンテナが共通してマウントしているディレクトリ内では3つのファイルと1フォルダーが生成されます。
- conf.json
etcdから取得したハッシュ値のアルゴリズムやs3のパス、mysqlのホスト名やユーザー名などが格納されています。 - filesフォルダー
s3-fetch-tool2がダウンロードしたファイルを一時的に保存するフォルダーです。 - s3fin
全ファイルのダウンロードが完了したときにs3-fetch-tool2が生成します。
全処理完了後init-podコンテナがこのファイルを削除します。 - hashfin
全ファイルのハッシュ値計算が完了したときにfile-hasher2が生成します。
全処理完了後init-podコンテナがこのファイルを削除します。
etcdに保存するデータ
etcdにはs3やmysqlサーバーに接続するためのIDやパスの他、ファイルを処理する要求情報を保存します。
各Podは処理中の情報や完了情報を保存します。
ちょっと複雑ですが以下のような構成になります。(もしかしたらetcdの使い方として間違っているかもしれません。)
設定関係
- /conf/mysql_host mysqlのホスト名(例:db.rds.amazonaws.com)
- /conf/mysql_name dbの名前です
- /conf/mysql_pass mysqlのパスワード
- /conf/mysql_user mysqlのユーザー名
- /conf/s3_bucket s3のバケット名
- /conf/s3_key s3のアクセスキーID
- /conf/s3_secret s3のシークレットアクセスキー
タスクの要求
- /req/<requestID>/root
処理するs3のフォルダー名 - /req/<requestID>/job
タスクの分割数(処理をかんたんにするため後どれだけの数で分割するかとします) - /req/<requestID>/method
ハッシュ値の計算アルゴリズム(MD5, SHA1, SHA224, SHA256, SHA384, SHA512)
タスクの割当情報(自動生成)
- /wip/<requestID>/<jobID>/host
処理しているPodのホスト名 - /wip/<requestID>/<jobID>/range/start
処理対処のファイル名の範囲の開始値 - /wip/<requestID>/<jobID>/range/end
処理対処のファイル名の範囲の終了値
タスクの完了情報(自動生成)
- /done/<requestID>/<jobID>/host
処理が完了したPodのホスト名
データベースの構造
mysqlには以下のテーブル名と構造で保存します。
| カラム名 | ID | HostName | FileName | HashMethod | Hash | Date |
|---|---|---|---|---|---|---|
| 型 | int(11) auto_increment primary key |
text | varchar(256) | char(10) | text | datetime |
| 説明 | ID | 計算したPodのホスト名 | 計算したファイル名 | ハッシュ値の計算アルゴリズム | ハッシュ値 | 書き込み日時 |