TL;DR
- NVLink接続なGPUサーバがあったのでNCCL試してみたよ
- NVLink対応のNCCL2だと集合通信が速い!!(GitHub版のNCCL1.3.5では性能でないよ!!)
- TensorFlowとかNCCL2に対応してないみたいなんだけど...
- みんなどうしてるの?
- NCCL1.3.5向けのコードをNCCL2で使えるようにしてみた
ことのはじまり
NCCLは,NVIDIAが提供しているマルチGPU向けの集合通信用のライブラリです.
NCCLについての正確で詳しい説明は,NVIDIA Collective Communications Library(NCCL)やFast Multi-GPU colllectives NCCLをみてもらうとして,
簡単にいうと,マルチGPUで,Reduceなど手軽に高速に処理できる素敵ライブラリ,です.
NCCL 1.3.5が,オープンソースとしてGitHubで公開されていますhttps://github.com/NVIDIA/nccl .
今回,二つのGPUを搭載したサーバを使える機会に恵まれたので試してみました.GPUがNVLinkで接続されている素敵なハードウェア構成です.
NVLinkについてはこちら.PCIeより5〜12倍高速なるというふれこみの,期待大の通信路です.
NCCL1.3.5の落し穴とNCCL2
...と,ここで衝撃のIssueがGitHubに.
what is the latest release version of NCCL?
- GitHubにあるオープンソース版のNCCLはNVLink向けにはなってない
- NVLinkをサポートしたNCCL 1.6はDGX-1カスタマー向けにリリースされている
とのこと.
ただし,NVLink使うのは諦めなさい...ということではなく,DGX-1を購入していないユーザでもNCCL2ならダウンロードして使えるとのこと.
ちなみにDGX-1というのは,NVIDIAから販売されているAI研究向けにGPUがたくさんのったパワフルな計算機です https://www.nvidia.com/en-us/data-center/dgx-server/
NCCL1.3.5 vs NCCL2.
というわけで,GitHub版のNCCL1.3.5とNCCL2で,どれほどの違いがあるのかGitHubのテストベンチで調べてみました.
結果はこちら
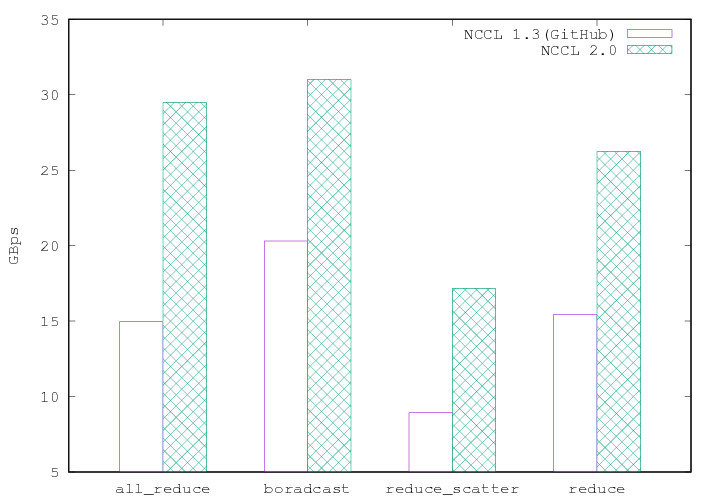
二つのGPUだけのReduceであるにも関わらず,約2倍程度の性能差があることがわかります.
これ,4GPUや8GPUの環境では,もっと性能差がでるんじゃないかなあ...
NCCL2があればOK...でもない
NCCL2があるなら,それでいいじゃん,で話が終わらないのが残念なところ.
マルチGPUサーバを何に使う?というと,今ならディープニューラルネットワークの学習に使うというのが主ですよね.
TensorFlowなど有名なフレームワークはマルチGPUにもNCCLにも対応しはじめています.
なのですが,多分それらはNCCL2では使えないんじゃないのかなあ?(まだちゃんと試せていないけど)
というのも,NCCL1.3.5とNCCL2には若干の違いがあるのです.
大きな違いの一つは,NCCL1.3.5では,
for (int i = 0; i < nDev; ++i) {
CUDACHECK(cudaSetDevice(dList[i]));
NCCLCHECK(ncclAllReduce((const void*)sendbuff[i], (void*)recvbuff[i], std::min(N, 1024 * 1024), type, op, comms[i], s[i]));
}
としてNCCLでのall-reduceができるのですが,NCCL2では,
ncclGroupStart();
for (int i = 0; i < nDev; ++i) {
NCCLCHECK(ncclAllReduce((const void*)sendbuff[i], (void*)recvbuff[i], std::min(N, 1024 * 1024), type, op, comms[i], s[i]));
}
ncclGroupEnd();
と,集合通信のAPIを呼ぶ前後で,ncclGroupStart()/ncclGroupEnd()を呼ばないといけなくなっています.
ちなみに,これらを呼ばないと処理がまったく進みません.
また,ncclAllGatherのように,引数の順番が違うAPIもあります...
だから?
たとえば,TensorFlowのNCCL関連コードnccl_manager.ccを見てみると,
ncclGroupStart()/ncclGroupEnd()を呼んでいるようには見えないのです(2017年8月22日現在).
...つまり,オープンソースとして公開されているバージョンを組み合わせてTensorFlowをマルチGPU環境で使う場合,NVLinkが宝の持ち腐れになっちゃうってこと?
まとめ
NCCLを使ってNVLinkの性能を評価してみました.NVLinkに対応したNCCL2を使うことで速度向上が見込めるようです.
一方で,たとえばTensorFlowのようなNCCLに対応したコードが入っているフレームワークでもNCCL2には対応していないような気が...
DGX-1ではない,NVLink接続なマルチGPUサーバを購入した人たちって,どうしているのかなあ?(ニュースなんかで,導入している大学や組織の名前を目にした気がするのだけど)
フレームワークなんか使わないで,ごりごりNCCL2で集合通信するマルチGPU対応のニューラルネットワーク処理エンジンを作っているのかな?