kerasとsparkで分散するフレームワークElephasについて。
hadoop、sparkについての神資料
https://www.slideshare.net/hamaken/hadoop-spark-ibm-datapalooza-tokyo-2016
以下本文。
https://github.com/maxpumperla/elephas#usage-of-data-parallel-models
ElephasはKerasの拡張版で、Sparkを使って分散した深い学習モデルを大規模に実行することができます。 Elephasは現在、次のような多くのアプリケーションをサポートしています。
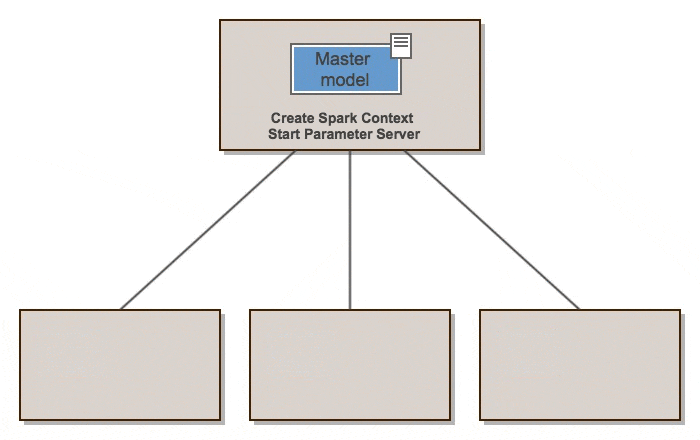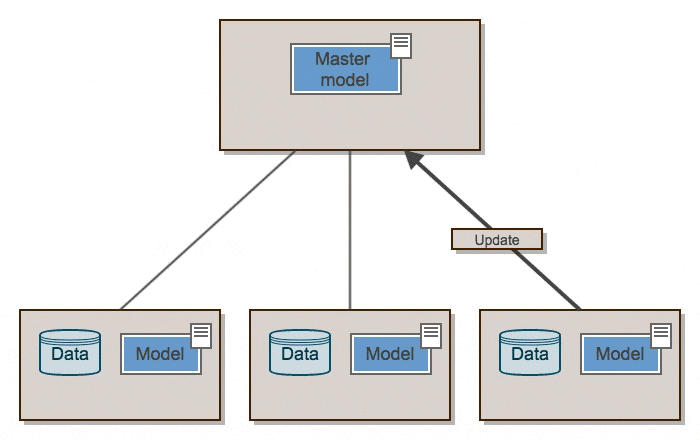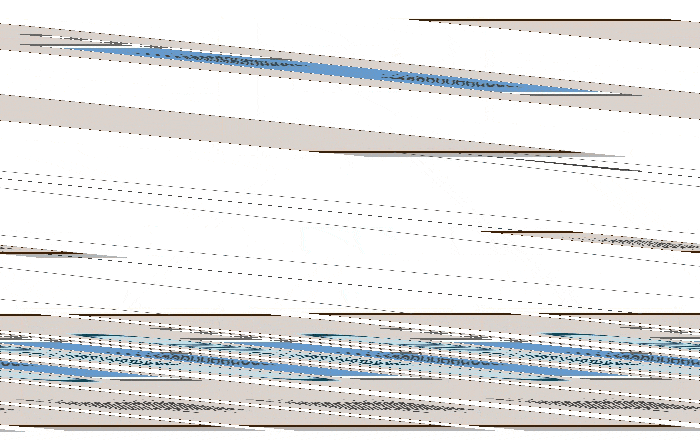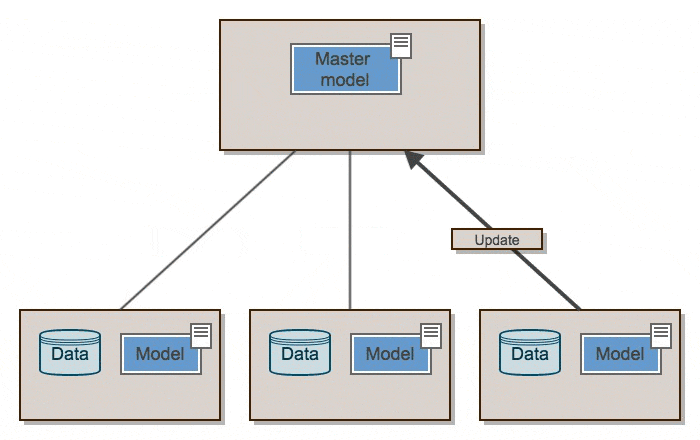
概略的に、elephasは次のように動作します。
コンテンツの一覧:
Elephas:Keras&Sparkを用いた分散型ディープラーニング
前書き
入門
インストール
基本的な例
Spark MLの例
データ並列モデルの使用
モデル更新(オプティマイザ)
更新頻度
更新モード
読み取りと書き込みロックによる非同期更新(mode = 'asynchronous')
ロックのない非同期更新(mode = 'hogwild')
同期更新(モード= '同期')
並列度(ワーカー数)
分散ハイパーパラメータの最適化
アンサンブルモデルの分散トレーニング
討論
将来の仕事と貢献
文献
前書き
ElephasはKerasのSparkへの深い学習をもたらします。 EleasはKerasのシンプルさと使いやすさを維持し、大量のデータセットで実行できる分散モデルの迅速なプロトタイプ作成を可能にします。入門的な例については、次のiPythonノートブックを参照してください。
ἐλέφαςはギリシャ語の象牙で、κέρας(ホーンを意味する)への付随するプロジェクトです。これが悪い夢のように気まずいことだと思われる場合は、実際にKerasのドキュメントにあることを確認する必要があります。エレファはまた、象の黄色い象のように象を意味します。
Elephasは、SparkのRDDとデータフレームを使用して、Kerasの上にデータ並列アルゴリズムのクラスを実装しています。 Kerasモデルはドライバーで初期化され、シリアル化されてワーカーに送信され、データとブロードキャストされたモデルパラメーターとともに送られます。スパーク作業員はモデルをデシリアライズし、データのまとまりを訓練し、グラジエントをドライバーに送り返します。ドライバーの「マスター」モデルは、オプティマイザーによって更新されます。オプティマイザーは、グラディエントを同期または非同期に取り込みます。
入門
インストール
PyPIからelephasをインストールする
pip install elephas
使用しているOSによっては、まずいくつかの前提条件モジュール(LAPACK、BLAS、Fortranコンパイラ)をインストールする必要があります。
たとえば、Ubuntu Linuxの場合:
sudo apt-get install liblapack-dev libblas-dev gfortran
Sparkをローカルにインストールする簡単な方法は、Macでhomebrewを使うことです
brew install spark
またはLinuxのlinuxbrewです。
brew install apache-spark
SparkのBREWバージョンは、時代遅れの可能性があります。 ソースからビルドするには、Sparkのダウンロードセクションの指示に従うか、次のコマンドを使用します。
wget http://apache.mirrors.tds.net/spark/spark-1.5.2/spark-1.5.2-bin-hadoop2.6.tgz -P〜
sudo tar zxvf〜/ spark- * -C / usr / local
sudo mv / usr / local / spark- * / usr / local / spark
その後、これらのパス変数をシェルプロファイル(〜/ .zshrcなど)に入れてください。
export SPARK_HOME = / usr / local / spark
export PATH = $ PATH:$ SPARK_HOME / bin
ドッカーを使用する
こちらの手順(https://www.docker.com/)に従って、Dockerをインストールして実行してください。
ビルド
多くのパッケージをダウンロードしてインストールする必要があるため、ビルドには初めての実行にかなりの時間がかかります。 Dockerfileと同じディレクトリに以下のコマンドを実行します
docker run -d -p 8899:8888 pyspark/elephas
実行
次のコマンドは、認証が設定されていない状態で、ノートブックサーバーがポート8899(ローカルJupyterノートでは8888を使用しているため)でHTTP接続を待機しているコンテナを開始します。
docker run -d -p 8899:8888 pyspark / elephas
設定
メモリDockerファイルでは、次の行を調整してメモリ設定を構成できます。
ENV SPARK_OPTS --driver-java-options=-Xms1024M --driver-java-options=-Xmx4096M --driver-java-options=-Dlog4j.logLevel=info
その他のその他の設定や設定については、こちらをご覧くださいhttps://github.com/kmader/docker-stacks/tree/master/keras-spark-notebook
基本的な例
ElephasとSparkの両方をインストールした後、モデルの訓練は次のように概略的に行われます。
ローカルなPysparkコンテキストを作成する
from pyspark import SparkContext, SparkConf
conf = SparkConf().setAppName('Elephas_App').setMaster('local[8]')
sc = SparkContext(conf=conf)
Kerasモデルの定義とコンパイル
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation
from keras.optimizers import SGD
model = Sequential()
model.add(Dense(128, input_dim=784))
model.add(Activation('relu'))
model.add(Dropout(0.2))
model.add(Dense(128))
model.add(Activation('relu'))
model.add(Dropout(0.2))
model.add(Dense(10))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy', optimizer=SGD())
numpyの配列からのRDDを作成します。
from elephas.utils.rdd_utils import to_simple_rdd
rdd = to_simple_rdd(sc, X_train, Y_train)
SparkModelは、SparkコンテキストとKerasモデルを渡すことによって定義されます。さらに、エレファスモデルの更新に使用されるオプティマイザ、更新頻度、並列化モード、および並列度、すなわちワーカーの数を選択する。
from elephas.spark_model import SparkModel
from elephas import optimizers as elephas_optimizers
adagrad = elephas_optimizers.Adagrad()
spark_model = SparkModel(sc,model, optimizer=adagrad, frequency='epoch', mode='asynchronous', num_workers=2)
spark_model.train(rdd, nb_epoch=20, batch_size=32, verbose=0, validation_split=0.1, num_workers=8)
spark-submitを使用してスクリプトを実行する
spark-submit --driver-memory 1G ./your_script.py
ネットワーク内のパラメータセットが非常に大きく、ドライバ上でそれらを収集することは、多くのリソースを消費するため、ドライバメモリをさらに増やすことがさらに必要になる可能性があります。 いくつかの実際の例についてはexamplesフォルダを参照してください。
Spark MLlibの例
最後の例をフォローアップして、numpy配列のペアからの監督訓練のためのLabeledPointsのRDDを作成するには、
from elephas.utils.rdd_utils import to_labeled_point
lp_rdd = to_labeled_point(sc, X_train, Y_train, categorical=True)
特定のLabeledPoint-RDDをトレーニングすることは、すでに見たようなものです
from elephas.spark_model import SparkMLlibModel
adadelta = elephas_optimizers.Adadelta()
spark_model = SparkMLlibModel(sc,model, optimizer=adadelta, frequency='batch', mode='hogwild', num_workers=2)
spark_model.train(lp_rdd, nb_epoch=20, batch_size=32, verbose=0, validation_split=0.1, categorical=True, nb_classes=nb_classes)
Spark MLの例
データフレーム上でSparkMLを使用してモデルをトレーニングするには、次の構文を使用します。
df = to_data_frame(sc, X_train, Y_train, categorical=True)
test_df = to_data_frame(sc, X_test, Y_test, categorical=True)
adadelta = elephas_optimizers.Adadelta()
estimator = ElephasEstimator(sc,model,
nb_epoch=nb_epoch, batch_size=batch_size, optimizer=adadelta, frequency='batch', mode='asynchronous', num_workers=2,
verbose=0, validation_split=0.1, categorical=True, nb_classes=nb_classes)
fitted_model = estimator.fit(df)
estimatorをフィッティングするとSparkMLトランスフォーマーが生成され、変換メソッドを呼び出して予測やその他の評価に使用できます。
prediction = fitted_model.transform(test_df)
pnl = prediction.select("label", "prediction")
pnl.show(100)
prediction_and_label= pnl.map(lambda row: (row.label, row.prediction))
metrics = MulticlassMetrics(prediction_and_label)
print(metrics.precision())
print(metrics.recall())
データ並列モデルの使用 上記の最初の例では、elephasモデルがこのようにインスタンス化されていることを確認しました。
spark_model = SparkModel(sc,model, optimizer=adagrad, frequency='epoch', mode='asynchronous', num_workers=2)
したがって、標準的なSparkコンテキストとKerasモデルを除いて、Elephasモデルには4つのパラメータがあり、次にそれぞれについて説明します。 モデル更新(オプティマイザ) オプティマイザ:elephasのオプティマイザモジュールは、ケラスの同じモジュールの適応です。つまり、オプティマイザの次のリストをユーザに提供します。
SGD
RMSprop
Adagrad
Adadelta
Adam
構築されると、これらのそれぞれをモデルのオプティマイザパラメータに渡すことができます。 kerasの更新はtheanoの助けを借りて計算されるので、kerasオプティマイザのデータ構造のほとんどはtheanoに由来します。 エレファでは、それぞれのワーカーによって既にグラディエントが計算されているので、内部的には数が少ない配列で完全に作業するのが理にかなっています。
elephasモデルを設定するには、elephasと基底のkerasモデルの2つのオプティマイザを指定する必要があります。 個々の労働者はkerasオプティマイザに従って更新を行い、ドライバの「マスタ」モデルはelephasオプティマイザを使用してそれらを集約します。 まず、SGDを搭載したケラスモデルとAdagradまたはAdadeltaを搭載したelephasモデルをお勧めします。
更新頻度
頻度:ユーザーは、頻度パラメータを制御することによって、更新頻度を決定できます。 すべてのバッチを更新するには、「バッチ」を選択し、各エポック後にのみ更新するには、「エポック」を選択します。
更新モード
mode:現在、elephasで利用可能な3つの異なるモードがあり、それぞれが採用された異なるヒューリスティックまたは並列化方式に対応し、モードパラメータによって制御されます。デフォルトのプロパティは '非同期'です。
読み取りと書き込みロックによる非同期更新(mode = 'asynchronous')
このモードは、[1]の豪雨として記述されたアルゴリズムを実装しています。つまり、各ワーカーは、準備ができたらいつでも更新を送信できます。マスタモデルは、更新を失わないようにします。つまり、パラメータを読み書きしている間にマスタパラメータをロックすることによって、複数の更新が同じ時間に適用されます。このアイデアは、GoogleのDistBeliefフレームワークで使用されています。
ロックのない非同期更新(mode = 'hogwild')
基本的には上記と同じですが、ロックを必要としません。このヒューリスティックは、たとえここで更新が失われても、まだ十分にうまくいくと仮定しています。 SGDの非分散設定でのロックフリーパラメータの更新は、「Hogwild!」という名前で行われます。 [2]、それは 'Dogwild!'と呼ばれる分散拡張です。 [3]。
同期更新(mode='synchronous')
このモードでは、各ワーカーは同時にパラメータ更新の新しいバッチを送信し、その後マスタで処理されます。したがって、このアルゴリズムはバッチ同期並列または単にBSPと呼ばれることがあります。
並列度(ワーカー数)
num_workers:最後に、私たちのトレーニングデータを並列化する度合いは、num_workersパラメータによって制御されます。
分散ハイパーパラメータの最適化
elephasを使ったハイパーパラメータの最適化は、hyperoptとkerasの便利なラッパーであるhyperasに基づいています。少なくともバージョン0.1.2のhyperasがインストールされていることを確認してください。各Sparkワーカは多数の試行を実行し、結果が収集され、最良のモデルが返されます。 hyperoptの分散モード(MongoDBを使用)は、書込み時に構成が難しく、エラーが発生しやすいため、並列化を自分で実装することを選択しました。現在では、利用可能な最適化アルゴリズムはランダム検索のみです。
この例の最初の部分は、多かれ少なかれ直接hyperasのドキュメントから取られています。データとモデルを関数として定義し、ハイパーパラメータの範囲は中括弧で定義します。この仕組みの詳細については、hyperasのドキュメントを参照してください。
from __future__ import print_function
from hyperopt import Trials, STATUS_OK, tpe
from hyperas.distributions import choice, uniform
def data():
'''
Data providing function:
Make sure to have every relevant import statement included here and return data as
used in model function below. This function is separated from model() so that hyperopt
won't reload data for each evaluation run.
'''
from keras.datasets import mnist
from keras.utils import np_utils
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train = X_train.reshape(60000, 784)
X_test = X_test.reshape(10000, 784)
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255
nb_classes = 10
Y_train = np_utils.to_categorical(y_train, nb_classes)
Y_test = np_utils.to_categorical(y_test, nb_classes)
return X_train, Y_train, X_test, Y_test
def model(X_train, Y_train, X_test, Y_test):
'''
Model providing function:
Create Keras model with double curly brackets dropped-in as needed.
Return value has to be a valid python dictionary with two customary keys:
- loss: Specify a numeric evaluation metric to be minimized
- status: Just use STATUS_OK and see hyperopt documentation if not feasible
The last one is optional, though recommended, namely:
- model: specify the model just created so that we can later use it again.
'''
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation
from keras.optimizers import RMSprop
model = Sequential()
model.add(Dense(512, input_shape=(784,)))
model.add(Activation('relu'))
model.add(Dropout({{uniform(0, 1)}}))
model.add(Dense({{choice([256, 512, 1024])}}))
model.add(Activation('relu'))
model.add(Dropout({{uniform(0, 1)}}))
model.add(Dense(10))
model.add(Activation('softmax'))
rms = RMSprop()
model.compile(loss='categorical_crossentropy', optimizer=rms)
model.fit(X_train, Y_train,
batch_size={{choice([64, 128])}},
nb_epoch=1,
show_accuracy=True,
verbose=2,
validation_data=(X_test, Y_test))
score, acc = model.evaluate(X_test, Y_test, show_accuracy=True, verbose=0)
print('Test accuracy:', acc)
return {'loss': -acc, 'status': STATUS_OK, 'model': model.to_yaml(), 'weights': pickle.dumps(model.get_weights())}
基本設定が定義されると、最小化の実行はコードのほんの数行で実行されます:
from hyperas import optim
from elephas.hyperparam import HyperParamModel
from pyspark import SparkContext, SparkConf
# Create Spark context
conf = SparkConf().setAppName('Elephas_Hyperparameter_Optimization').setMaster('local[8]')
sc = SparkContext(conf=conf)
# Define hyper-parameter model and run optimization
hyperparam_model = HyperParamModel(sc)
hyperparam_model.minimize(model=model, data=data, max_evals=5)
アンサンブルモデルの分散トレーニング
最後のセクションでは、大規模な検索スペースでのハイパーパラメータ最適化を実行し、上位n個の実行モデルに結果として得られる投票分類子を定義することによって、エレファとアンサンブルモデルを訓練することができます。 上記のように定義されたデータとモデルによって、これは実行中の単純なものです
result = hyperparam_model.best_ensemble(nb_ensemble_models=10, model=model, data=data, max_evals=5)
この例では、各Spark作業者の最大5回の実行の最適化に基づいて、10モデルのアンサンブルが構築されています。
討論
早期並列化はすべての悪の根源ではないかもしれませんが、そうすることが常に最善の考えであるとは限りません。より多くのワーカーが従業員一人当たりのデータを少なくし、モデルの並列化は実際の学習の言い訳ではないことに留意してください。したがって、データをメモリに完全に収めることができ、モデルの速度を訓練することに満足しているのであれば、ケラスを使用するだけで十分です。
このルールの例外の1つは、既にSparkエコシステム内で作業しているもので、そこにあるものを活用したいということです。上記のSparkMLの例では、Sparkの評価モジュールを使用する方法を示しています。おそらく、象モデルの結果をさらに処理したいと思うかもしれません。この場合、num_workers = 1に設定することで、elephasを単純なラッパーとして使用することをお勧めします。
現在elephasは、2つの理由からデータ並列アルゴリズムに制限されていることに注意してください。まず、Sparkは単にデータの配布を非常に簡単にします。第二に、SparkもTheanoも、実際のモデルを部分的に分割することを特に容易にしないので、モデル並列性を実現することは事実上不可能です。
すべてのことを言っておけば、Elephasを簡単にセットアップし、データ並列ディープ学習アルゴリズムのための遊び場として利用することを学ぶことを願っています。
将来の仕事と貢献
エレファスに対する建設的なフィードバックとプルリクエストは大歓迎です。 将来の開発のために覚えていることがいくつかあります
トレーニングの速度と精度のベンチマーク。
imagenetのような大きなデータセットを持つEC2インスタンスに関する現実のテスト。
文献
[1] J. Dean, G.S. Corrado, R. Monga, K. Chen, M. Devin, QV. Le, MZ. Mao, M’A. Ranzato, A. Senior, P. Tucker, K. Yang, and AY. Ng. Large Scale Distributed Deep Networks.
http://research.google.com/archive/large_deep_networks_nips2012.html
[2] F. Niu, B. Recht, C. Re, S.J. Wright HOGWILD!: A Lock-Free Approach to Parallelizing Stochastic Gradient Descent
http://arxiv.org/abs/1106.5730
[3] C. Noel, S. Osindero. Dogwild! — Distributed Hogwild for CPU & GPU
Contact GitHub API Training Shop Blog About
©
http://stanford.edu/~rezab/nips2014workshop/submits/dogwild.pdf