環境:
Model Name: MacBook Air
Processor Name: Intel Core i7
Memory: 8 GB
Python 3.5.1
tensorflow (0.10.0rc0)
sequence-to-sequenceのニューラルネットで実現。
caffe-speech-recognitionからの置き換え。
Ultimate goal:最終目的
Linuxのスタンドアロンで音声認識できるようにする。
十分にデータはある。(100GB)
http://www.openslr.org/12
まだ計画の段階です。
train.pyを見てください。
大枠は用意したのでメソッドを実装してくれてもいいんだよ?
実行してみよう
./number_classifier_tflearn.py ./speaker_classifier_tflearn.py ./train.sh ./record.py
本家より雑に翻訳してメモ
https://github.com/pannous/tensorflow-speech-recognition
Speech recognition using google's tensorflow deep learning framework, sequence-to-sequence neural networks.
Replaces caffe-speech-recognition, see there for some background.
Extensions to current tensorflow probably needed:Sliding Window GPU implementation
Continuous seq2seq adaptation
Modular graphs/models + persistance
Incremental collaborative snapshots
Ultimate goal: Create a decent standalone speech recognition for Linux etc. Some people say we have the models but not enough training data. We disagree: There is plenty of training data (100GB here, on Gutenberg, synthetic Text to Speech snippets, Movies with transcripts, YouTube with captions etc etc) we just need a simple yet powerful model. It's only a question of time...Update: Nervana showed that it is possible for 'independents' to build models that are state of the art. Unfortunately they didn't open source the software. Sphinx starts using tensorflow LSTMs.
Collaborators wanted! We are in the process of tackling this project in seriousness. Make a pull request if you want to join the party, no matter your background.
We are still in the planning phase! See train.py for the suggested general architecture. You can contribute right away by discussing or implementing one of the (easy) train_... methods.
** Getting started ** ./number_classifier_tflearn.py ./speaker_classifier_tflearn.py ./train.sh ./record.py
ってことでmacで実行してみるといつまでたっても学習が終わらないので一旦寝る。
1日たっても終わらなかったので消した。
学習数を減らしたり色々しているうちに、そもそも放置しても動かないことがわかった。
** Getting started ** ./number_classifier_tflearn.py ./speaker_classifier_tflearn.py ./train.sh ./record.py
ってやっても そもそもtrain.shねぇし。caffeの方にはある。
speech_data.pyのmaybe_downloadとかダウンロードできねぇし。
ずっと学習が終わらなかった理由。
while data0 != '':のところでずっと回ってた。
while data0 != b'':に変更したら普通に学習終了。
すごい学習してると思ってたけどループが回ってただけでした。
学習回数を減らして音声数を減らしている為か結果があってない。
3の音声だけど8ってっ結果になってる。
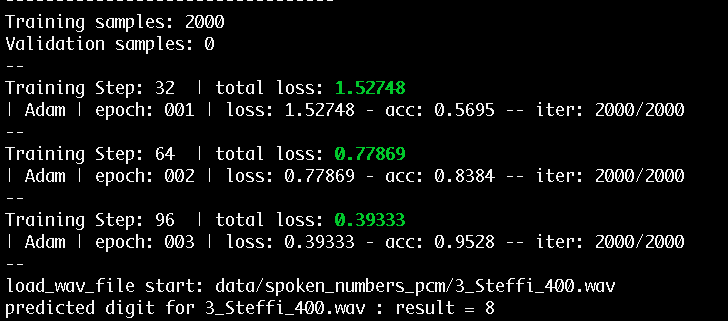
学習をするとパソコンが重くなる。。。
また今度学習回数と音声数をあげて試す予定。
gpuはcpuの20倍のパフォーマンスとのこと。
gpuパソコン作ろうか考え中
http://www.kabuku.co.jp/developers/gpu-performance-for-deep-learning