ざっくりいうと
物体検出アルゴリズムを写真やビデオの編集アプリに入れる話
重要なオブジェクトを検出するのに使用
クラウドソーシングでデータセット作成もしたが、能力が少し足りない問題もあったそうな
ボケ処理を背景に入れることで背景の誤認識を下げる
オリジナルのビデオコードに基づいてbokehスレッドを実装
実装は見つからない。残念。
用語
blur or Blurring
...ブラー。モーションブラーで被写体ボケ。
Focusing
...フォーカス
Bokeh
...ボケ処理。レンズの焦点の範囲外に生みだされるボヤけた領域を利用する表現手法。
左がブラー。ピンボケ

ボケ処理

reports2016
抜粋
このプロジェクトでは、CNNを使用して、写真やビデオの編集アプリケーションでシーン内の重要なオブジェクトを識別します。 この問題には、RCNNとYOLOという2つのアプローチがあります。 fasterR-CNNは、シーン内のオブジェクトをより正確に識別し、それらの領域をラベル付きオブジェクトカテゴリに分類するために使用される。 YOLOは、リアルタイムで処理する必要のあるビデオを識別し、分類するために使用され、速度のために不正確さをトレードオフします。 次に、これらのラベルを使用して、画像のオブジェクトの重要度の重み付けを決定して、最も重要なオブジェクトまたはオブジェクトを分離することにより、これらのオブジェクトを定常化させる画像処理技術を適用する。 fasterR-CNNおよびYOLOは、VOC 2007データセットでトレーニングされています。
1.はじめに
画像中の複数のアイテムを特定することはまだ困難である。しかしながら、ここ数年、畳み込みニューラルネットワーク(CNN)を用いた物体検出のための重要な研究がなされている。本論文では、シーンの中で最も重要なオブジェクトを写真やビデオ編集で可能なアプリケーションとして識別できる検出器を作成することを目的としています。検出器への入力は、未処理の写真か動画です。アプリケーションに応じて、fastR-CNNまたはYOLOのいずれかを使用して、各画像のオブジェクトを検出して分類し、各オブジェクトの重要度をランク付けし、画像処理フィルタを適用して最も重要なオブジェクトを目立たせます。検出器の出力は、処理された写真またはビデオです。
このような検出器の有用性の例として:
スポーツイベントのビデオがある場合、検出器は移動するアスリートを見つけることができるため、ビデオ処理技術を適用して背景の変化する風景からの注意散漫を減らすことができます。
もう一つの例は、有名な目印の前に関心のある対象者が写真を持っているが、背景にあまりにも多くの観光客がいる場合、その人物と目印が写真の最も重要な対象であると判断できないので ボカシなどの撮影技術を適用して背景ノイズを低減します。
カメラは、焦点合わせのために1つの深度しか有することができないので、特に複数のオブジェクトにフォーカスする場合のボケ処理は、非常に困難です。
したがって、重要なオブジェクトの境界ボックスを特定できても、理論上、複数のオブジェクトをボケ効果で焦点を合わせたり、ぼかしたりすることはできません。
その目的を達成するには、いくつかの課題に取り組まなければなりません。広範囲のオブジェクトクラスを正確に配置および分類することが可能なモデル。
第2の課題は、ビデオをリアルタイムで処理できるディテクタを作成することです。私たちは、次の論文でこれらの課題に取り組んでいることを示しています。

図1:ボケ処理(Bokeh)(2)とブラー(Blurring)(3)の例
2.関連ワーク
検出器がさまざまな異なる画像またはビデオアプリケーションで動作するように、YOLOとFaster R-CNNという2つの異なる検出アルゴリズムを検討します。 YOLOは画像をグリッドに分割し、各グリッドセル内で、境界ボックスとその信頼スコアならびに各セルの条件付きクラス確率予測を予測する。 1つのバウンディングボックス内に多くの小さなオブジェクトがある場合、YOLOはエラーを被ります。[1] .FAST R-CNNは、リージョンプロポーザルネットワーク(Region Proposal Network、RPN)の追加により、R-CNNの以前の世代よりも優れています。領域とそのそれぞれの得点を同じタイミングに特定することにより、領域提案時間のボトルネックを軽減する。検出はRPNと共にFast R-CNNを使用して行われます。 VGG-16モデルでは、FASTER R-CNNはフレームレートが5fpsであり、PASCAL VOC 2007,2002、およびCOCOデータセットで最先端のオブジェクト検出精度を達成しており、画像あたりわずか300件の提案があります。 4] .2つのアルゴリズムは速度と精度のトレードオフを持つため、各アルゴリズムには適した特定のアプリケーションがあります。 YOLOは、PASCALVOC 2007データセットで45 FPSで63.4の平均精度(map)を持つ画像を処理できます。これは、リアルタイムのビデオ処理アプリケーションに適用するのに十分速いです。一方、より速いRCNNは、73.2mAPの高い精度を達成するが、わずか7FPSである[1]。画像内の物体の重要度をランク付けする以前の研究を検討した。 1つの論文はMechanical Turk(クラウドワークスのアマゾンバージョン)を使用して画像のオブジェクトの相対的な重要性をアノテーションラベリングした[5]。他の論文ではテキストラベル付きイメージを使用しました.1つの論文はUIUC Pascal Sentenceデータセット(UIUC)を使用していましたが、それぞれのイメージの文章の説明[6]、Mechanical Turkを使用してイメージラベルにテキストラベルを追加しました。これらのアプローチは有望でしたが、Mechanical Turkはこのプロジェクトの能力と資金を超えていましたが、オブジェクトの相対的重要性を判断するには、テキスト記述をイメージ・オブジェクトに関連付ける追加のNLP技法が必要です。
3.メソッド
この問題にアプローチするために、以下の4つの主要なステップに分けました。
1.オブジェクトの検出:このステップでは、畳み込み
画像内の関心対象を検出するニューラルネットワーク。我々は2つの異なるモデルを適用する:
YOLO、およびより高速のR-CNNを提供します。
2.有意性ランキング:
前のステップでは、各オブジェクトに重要度を割り当てる順位付けスキームを開発しました。これは、私たちが焦点を当てたいオブジェクトの数を選択する柔軟性を与えます。
3.フォーカシングとぼかし:このステップでは、画像処理
最も重要なオブジェクトに集中し、ビネット、ブラー、またはボケのいずれかを使用して残りのイメージをぼかし、識別されたオブジェクトの境界ボックスを使用します。
4.ビデオレンダリングの最適化:
最後のステップは、プログラムがビデオフレームを処理できるようにすることです。レンダリングプロセスでバウンディングボックスサイズが大きく変動するのを避けるため、完成したプログラムがYOLOで達成した合理的なフレームレートを提供するのに十分な効率を持つようにする必要がありました。
オブジェクト検出が重要であり、アプリケーションの第一歩であることから、我々は提案された2つの
アルゴリズム:YOLOとfasterR-CNN。
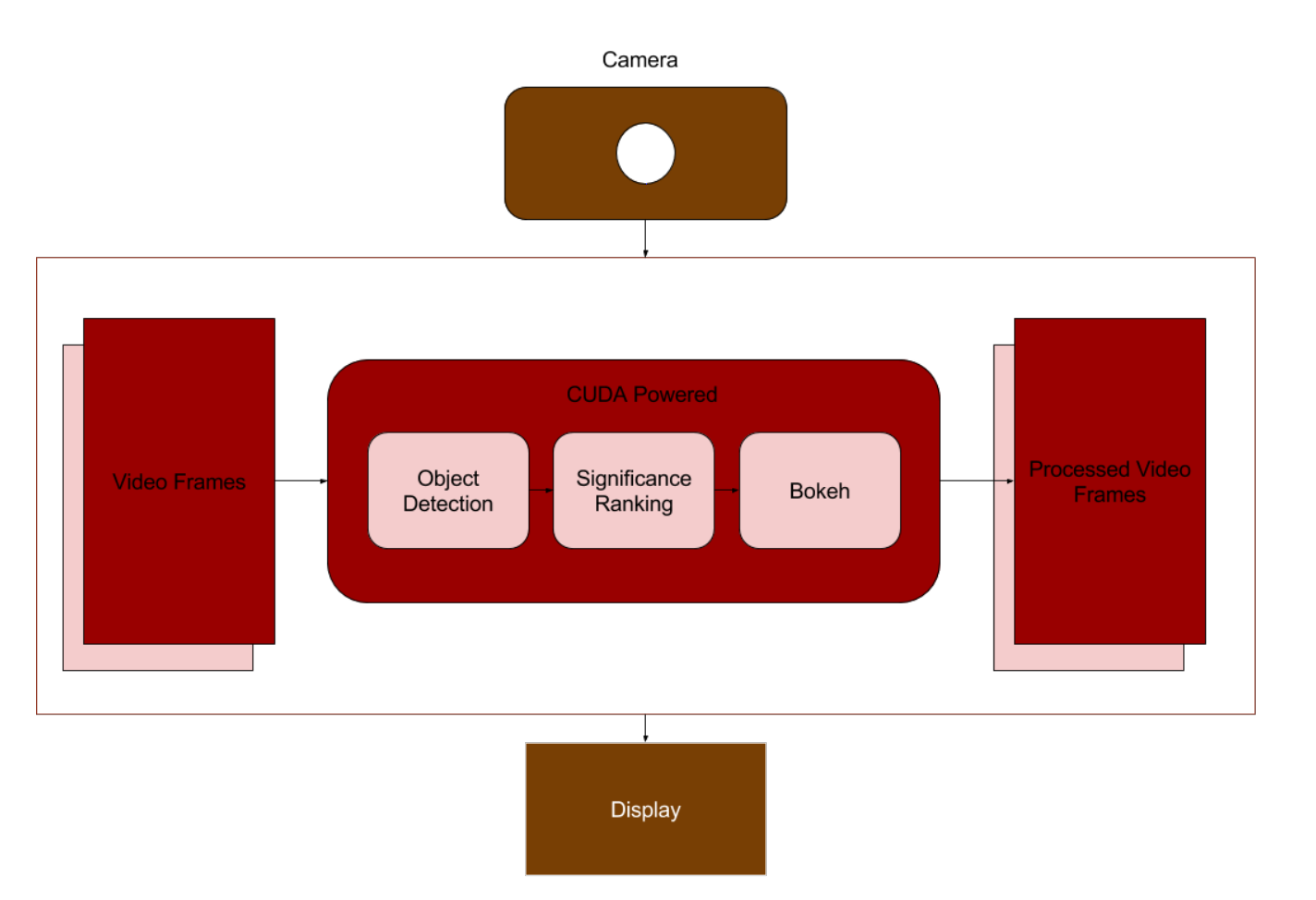
図2:システム図
〜モデルの説明は元論文もあるので略〜
3.1.2実装
YOLOは、CとCUDAで書かれたオープンソースのニューラルネットワークフレームワークであるDarknetで実装されています。 YOLOのこの実装は、リアルタイムでビデオストリーミングを処理するGPUコンピューティングパワーを利用します。 Darknetplatformには、アクティブ化レイヤー、平均プールレイヤー、畳み込みレイヤー、クロップレイヤー、およびデコンボリューションレイヤーの大部分のCUDAカーネル実装が含まれています。ビデオスクリーニングサブルーチンもCUDAkernelに実装されています。プログラムは、実行時にfetchthreadとスレッドを検出する2つのスレッドを起動します。各スレッドは並列に実行され、各画像の後に収束します。これは入力フレームを事実上二重にバッファリングする。処理を高速化するために、Darknetは画像操作を行う独自の画像クラスを持っています。 OpenCVは画像を取得、表示、保存するためのユーザーインターフェースラッパーとして使用されています。私たちの実装では、Darknetplatformを独自の処理CUDAカーネルを作成することによって活用しました。 CUDAカーネルは、オリジナルのビデオクリームデモコードに基づいて実装されています。フェッチスレッド、検出スレッド、bokehスレッドの2つのスレッドを起動してダブルフレームバッファリングを使用しました。この実装は、およそ20フレームで達成されました。
3.4。 画像処理
我々は、画像またはビデオ上で使用される3つの異なる画像処理技術を実装した。fasterR-CNNまたはYOLOのいずれかによって検出された境界ボックスを使用して、画像の背景にビネット、ぼかし、またはボケを導入しました。ビネットは暗いマスクを使用して実装され、ぼかしはアガウスのフィルタとして実装されました。ボケ効果をシミュレートするために、アガウスフィルタを適用した後、ランダムにピクセルを選択して円に拡大し、その後に別のガウスレイヤーを追加しました。フィルタリングされたオブジェクトと背景との間のエッジを柔らかくするために、ガウスフィルタを使用しました。
画像にフィルタを適用する1つの経緯は、複数の検出されたオブジェクトを扱うためです。
処理してはならないオブジェクト領域を追跡することによって、フィルタの重なりを防ぎます。
フィルタを適用することの主な難点は、オブジェクトをその背景と区別することです。色やエッジでセグメント化するなど、複数のアプローチを試みましたが、良い結果が得られず、オブジェクトの重なりを扱うのは困難でした。私たちは、すべてのオブジェクトクラスにわたって一般化されているバウンディングボックスの寸法を使用して、単純な楕円形になりました。

図6:ボケ生成プロセス
参考
http://cs231n.stanford.edu/reports2016/259_Report.pdf
http://cs229.stanford.edu/proj2016/report/BuhlerLambertVilim-CS229FinalProjectReport.pdf