# 新しいAIは自分のコードを書き直して書き直して知性を上げることができます ## 概略 企業は、機械がより少ない例から効果的に学び、さらなる例が提供されるときにその知識を洗練させる技術を開発しました。 この技術は、スマートフォンを教えることからユーザーの好みを認識することから、自律的な運転システムが障害物を迅速に特定できるようにすることまで、あらゆるものに適用できます。
より少ないデータから習得する
練習が完璧になる古い格言は、機械にも同様に適用されます。今日の人工知能デバイスの多くは、繰り返し学習に頼って学習します。 ディープラーニングアルゴリズムは、AIデバイスがデータセットから知識を収集し、学習した内容を具体的な状況に適用できるように設計されています。 たとえば、AIシステムには、空が通常青色である方法に関するデータが入力され、後で一連の画像内の空を認識することができます。
複雑な作業はこの方法を使用して行うことができますが、確かに必要なものが残ります。 例えば、ディープ・ラーニングAIをより少ない例にさらすことで、同じ結果が得られるだろうか? ボストンに拠点を置くスタートアップのGamalonはこれに答えようとする新しい技術を開発し、今週は新しいアプローチを採用した2つの製品をリリースしました。
ガマロンはベイジアンプログラム合成を採用した技術と呼んでいます。 それは18世紀の数学者トーマス・ベイズにちなんで命名された数学的な枠組みに基づいています。 ベイジアン確率は、経験を使って世界に関する予測を絞り込むために使用されます。 この形式の確率的プログラミング(特定の変数の代わりに確率を使用するコード)では、例えば、空が青く白い雲のパッチで青色になるなど、決定を下す例が少なくなります。 このプログラムは、さらなる例が提供されるにつれて知識を洗練し、そのコードを書き換えて確率を調整することもできます。
確率論的プログラミング
この新しいプログラミング手法はまだ克服するのが難しい課題ですが、機械学習アルゴリズムの開発を自動化する大きな可能性があります。 「確率論的プログラミングは、研究者や実践者にとって機械学習をはるかに容易にするでしょう」と、2015年の確率論的プログラミング手法に取り組んだNYUの研究員であるブレンダン・レイク氏は説明します。「難しい[プログラミング]部品を自動的に処理する可能性があります。
GamalonのCEOで共同創設者のBen Vigoda氏は、MIT Technology Reviewに新しい方法を使ったデモ描画アプリを公開しました。 このアプリは、昨年Googleが公開したものと似ている。それは、人がスケッチしようとしていることを予測するということだ。 しかし、Gamalonのアプリは、これまで予想されていたスケッチに依存していたGoogleのバージョンとは異なり、確率的プログラミングを利用してオブジェクトの重要な機能を特定しています。 したがって、アプリが以前に見たものとは異なる図形を描いたとしても、三角形の頂点がおそらく家のような特定の機能を認識する限り、正しい予測が行われます。
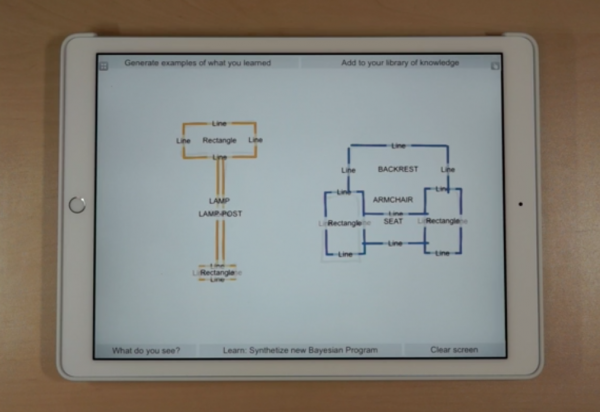
Gamalonがリリースしたこの2つの製品は、この技術が近い将来商業的に利用できることを示しています。 1つの製品であるGamalon Structureは、ベイジアンプログラム合成を使用して生テキストから概念を認識し、通常よりも効率的に処理します。 例えば、テレビの製造業者の説明を受信しただけで、ブランド、製品名、画面解像度、サイズ、および他の特徴を決定することができる。 Gamalon Matchと呼ばれる別のアプリは、店舗の在庫内の商品と価格を分類します。 どちらの場合も、システムは頭字語や略語のバリエーションを迅速に認識するように訓練することができます。
Vigodaは、他にも可能性があると考えています。 たとえば、機械学習のBeysianモデルが装備されている場合、スマートフォンやラップトップは、ユーザーの関心を決定するために大企業と個人情報を共有する必要はありません。 計算は装置内で効果的に行うことができます。 自律型自動車は、この学習方法を使用して、より迅速に環境に適応することを学ぶこともできます。 よりスマートなマシンの潜在的な影響は、実際には誇張することはできません。
このAIアルゴリズムは、われわれが実行するだけで簡単なタスクを学習する
人間が学ぶように見える方法からインスピレーションを得て、科学者は、はるかに効率的で洗練された方法で新しい知識を拾うことができるAIソフトウェアを作りました。
イチジク。 1.人々は、限られたデータから豊かな概念を学ぶことができます。 (AとB)新しい概念(赤い箱)の1つの例は、(i)新しい例の分類、(ii)新しい例の生成、(iii)オブジェクトを部分と関係に分解する色でセグメント化された部分)、および(iv)関連概念からの新しい概念の生成。
新しいAIプログラムでは、1つの例を見ただけで、手書き文字を人間が認識できるほど正確に認識することができます。ディープ・ラーニングと呼ばれる技法を採用した最も優れた既存の機械学習アルゴリズムは、AとZとの違いを知るために、手書き文字の数千の例を見る必要があります。
このソフトウェアは、ニューヨーク大学の研究者であるBrenden Lakeと、トロント大学のコンピュータサイエンスの助教授Ruslan Salakhutdinovと、MITのBrain and Cognitive Sciencesの教授であるJoshua Tenenbaumによって開発されました。プログラムの詳細とそれの背後にあるアイデアは、今日Science誌に掲載されています。
コンピュータは過去数年間で、顔を認識し、スピーチを理解し、さらには車を安全に運転することを学び、多くのことの中で、よりきれいになってきました。そして進歩の大部分は、大きな、または深い神経回路網を使用して行われています。しかし、これらのシステムには重大な欠点があります。最も単純な作業を行う方法を学ぶには、データの集まりが必要です。
この制限は、アルゴリズムが私たちのやり方で情報を処理しないという事実に大きく起因しています。深い学習はニューロンの仮想ネットワークをモデルとしていますが、そのアプローチは知覚的タスクで非常に印象的な結果を生み出していますが、脳が働く方法を模倣したものです。ディープ学習アルゴリズムは、画像内のピクセルを特定の文字と関連付ける。脳は同様の方法でいくつかの視覚刺激を処理するかもしれないが、人間はまた画像の内容を解釈するためにより高い形態の認知機能を使用する。
研究者はベイジアンプログラム学習フレームワーク(BPL)と呼ばれる手法を使用しました。本質的に、ソフトウェアは、想像上のペンのストロークを使用して、すべてのキャラクタに固有のプログラムを生成します。確率的プログラミング技法を使用して、特定のキャラクタにプログラムを適合させるか、または未知のもののための新しいプログラムを生成する。このソフトウェアは、子供が読み書き能力を獲得する方法を模倣するのではなく、むしろ、すでに知っている方法で新しいキャラクターを認識して再作成する方法を知っている大人の方法を模倣している。
「確率論的プログラミングの重要な点は、大部分の深刻な学習が進んでいるのとは違って、世界の因果過程を記述するプログラムから始めることだ」とTenenbaum氏は語る。 「われわれが習得しようとしているのは、機能の署名ではなく、機能のパターンでもありません。私たちはそれらのキャラクターを生み出すプログラムを学ぼうとしています。
Tenenbaumらは、手書きの例を見てから、人間とソフトウェアの両方が新しい文字を描くようにして、人や機械によって文字が書き込まれたかどうかをグループに尋ねるようにしてアプローチをテストしました。彼らは、裁判官の25%未満が違いを伝えることができたことを発見しました。
チームはこの技術をより実用的なアプリケーションにまで拡張できるとしています。例えば、コンピュータは、話し言葉で新しい言葉を認識して利用することをコンピュータが迅速に学ぶことができるかもしれない。または、コンピュータが特定のオブジェクトの新しいインスタンスを認識できるようにすることもできます。より一般的には、このアプローチは、人工知能における重要な新しい方向を指しています。研究者が研究からインスピレーションを得て人間の認知になるからです。
深い学びの発展に重要な役割を果たしたトロント大学の心理学科のジェフリー・ヒントン教授は、この作業はこの分野にとって重要なステップであると述べています。 「それは美しい紙であり、多くの例から学ぶ非常に印象的な例です」と彼は言います。
論文の著者の一人であるSalakhutdinov博士のアドバイザーでもあったHintonは、AI研究者は神経科学と認知科学の両方から多くの有用なことを学ぶことができると述べている。彼はまた、手書き認識のために開発されたアプローチのようなアプローチが、実際に深い学習と互換性があることを示唆している。 「両国のベストを持つことができると思う」と彼は語る。
ニューヨーク大学の認知科学者ゲーリー・マーカス(Gary Marcus)と人間の行動に影響を受けた機械学習アプローチを開発しているジオメトリックインテリジェンス(Geometric Intelligence)という会社の共同設立者は、人間の心がサイエンス紙。しかし、多くの状況でマシンが学ぶための膨大な量のデータがないため、このアプローチがAIにとって重要な目標を示していると彼は考えています。
「支配的なパラダイムの問題は、それが非常にデータに飢えているということです」とMarcus氏は言います。 "これはあなたがより速く学ぶことができる証拠です。 そして、それは人々がたくさん考えようとしているものだと思う」
Marcusは、その言語はそのようなシステムのためのキラーアプリケーションである可能性があると付け加えています。 多くの深遠な研究者が既にこの課題に取り組んでいます(「私たちを理解するための機械の教授」を参照)。しかし、マーカスは、機械を分解するために、より効率的で柔軟な方法で学習する必要があると考えています。 「AIの本当の変曲点は、マシンが実際に言語を理解できるときに来るだろう」と彼は言う。 "平凡な翻訳だけでなく、あなたが意味することを本当に理解する"
# AI Softwareは、より少ないデータから学ぶ
例えば、猫の好きなレベルの専門知識を持つ猫を認識するための深い学習アルゴリズムを訓練することはできますが、膨大な量の猫を撮影して数十から数十万の猫画像を送る必要があります 大きさ、形状、テクスチャ、照明、および向きに依存する。 人のようなビットでアルゴリズムが、猫をより少数の例から猫に変えるというアイデアを発達させることができれば、より効率的です。
Gamalonと呼ばれるボストンに本拠を置くスタートアップは、コンピュータがいくつかの状況でこれを可能にする技術を開発し、このアプローチに基づいて火曜日に2つの製品をリリースしている。
基礎となるテクニックを他の多くのタスクに適用できる場合は、大きな影響を与える可能性があります。少ないデータから学ぶ能力は、ロボットが新しい環境を非常に迅速に探索し、理解することを可能にし、データを共有することなくコンピュータがあなたの好みについて学ぶことを可能にする。
ガマロンは、ベイズプログラムの合成を呼び出して、より少ない例から学習できるアルゴリズムを構築する技術を使用しています。 18世紀の数学者Thomas Bayesにちなんで命名されたベイジアン確率は、経験に基づいて世界に関する予測を洗練するための数学的枠組みを提供します。 Gamalonのシステムは、特定のデータセットを説明する予測モデルを構築する確率的プログラミングまたは特定の変数ではなく確率を扱うコードを使用します。ほんのいくつかの例から、確率的プログラムは、例えば、猫が耳、髭、尾を持つ可能性が高いと判断することができます。さらに例を示すと、モデルの背後にあるコードが書き換えられ、確率が調整されます。これは、データからの顕著な知識を効率的に学習する方法を提供します。
確率的プログラミング技法は、しばらくの間行われてきました。 たとえば、2015年にMITとNYUのチームが確率論的手法を使用して、1つの例だけを見て、文字やオブジェクトを認識することをコンピュータに教えるようにしました(「このAIアルゴリズムはわかりやすい簡単なタスクを学習します」を参照)。 しかし、そのアプローチは主に学問的好奇心です。
2015年の研究を率いたNYUの研究員であるBrenden Lakeは、このプログラムではさまざまな考えられる説明を考慮する必要があるため、難しい計算上の課題があります。
理論によると、このアプローチは、機械学習モデルを開発する面を自動化できるため、大きな可能性を秘めています。 「確率的プログラミングは、研究者や実践者にとって機械学習をはるかに容易にするでしょう」とLake氏は言います。 「難しい[プログラミング]部品を自動的に処理する可能性がある」
より使いやすく、データに飢えた機械学習のアプローチを開発するためには、確かに大きなインセンティブがあります。 機械学習は、現在、大量の生データセットを取得し、しばしばそれを手動でラベリングすることを含む。 学習は数時間または数日間並行して行われる多くのコンピュータプロセッサを使用して、大規模なデータセンター内で行われます。 ガマロンの共同設立者兼CEOであるベン・ヴィゴーダ氏は、「実際にこれを行う余裕がある大企業はほんのわずかです。
理論的には、Gamalonのアプローチは、誰かが機械学習モデルを構築し、改良することをより容易にすることができます。ディープ・ラーニング・アルゴリズムを完璧にするには、数学的および機械学習の専門知識が必要です。 「これらのシステムを設定するには黒い芸術があります」とVigoda氏は言います。 Gamalonのアプローチでは、プログラマは重要な例を入力することによってモデルを訓練することができます。
Vigodaはこの技術を使った描画アプリでMIT Technology Reviewにデモを行った。去年リリースされたGoogleと同様のもので、人がスケッチしようとしているオブジェクトを深く知るために使用されます(「AIを理解したいですか?ダックをスケッチしてニューラルネットワークにする」を参照)。しかし、Googleのアプリはこれまで見たスケッチと同じスケッチを見る必要があるが、Gamalonのバージョンでは、確率的なプログラムを使ってオブジェクトの重要な特徴を認識している。たとえば、1つのプログラムは、正方形の上に座っている三角形が最も可能性が高いと理解しています。これは、たとえあなたのスケッチがこれまでに見たものと大きく異なっていても、それらのフィーチャがあれば、正しく推測できます。
この技術は、短期間で商業的に重要なアプリケーションを提供する可能性もあります。 同社の最初の製品は、ベイズのプログラム合成を使用してテキストの概念を認識します。
ガマロン構造と呼ばれる1つの製品は、生来のテキストから概念を通常よりも効率的に抽出することができます。 例えば、製造業者のテレビの記述を取り、記述されている製品、ブランド、製品名、解像度、サイズ、およびその他の特徴を決定することができる。 別の製品であるGamalon Matchは、店舗の在庫内で商品と価格を分類するために使用されます。 いずれの場合も、製品または機能に異なる略語または略語が使用されても、システムはそれらを認識するように迅速に訓練することができます。
Vigodaは学ぶ能力には他の実用的な利点があると信じています。 コンピュータは、実用的でない量のデータまたは時間の訓練を必要とすることなく、ユーザの興味について学ぶことができる。 ユーザーのスマートフォンやラップトップで機械学習を効率的に行うことができれば、個人データを大企業と共有する必要はありません。 ロボットや自家用車は数十万の例を見る必要なく新しい障害物を知ることができます。
# 確率論的プログラミング
プログラミング言語と機械学習コミュニティは、ここ数年の間に、確率的プログラミングの傘下にある共通の研究課題を開発しました。 概念は、抽象化や再利用のような強力なPLの概念を統計的モデリングに「エクスポート」することができるということです。これは現在非常に難しい作業です。
(講義ノートの最新版を読むことができます。ソースはGitHubにあります。間違いが見つかった場合はプルリクエストを開きます)。
1.何となぜ
1.1 確率論的プログラミングはできません
逆説的に、確率的プログラミングは、確率的に振る舞うソフトウェアを書くことではない。 例えば、あなたのプログラムが、意図した作業の一部としてrand(3)を呼び出すならば、暗号鍵生成器やOSカーネルのASLR実装、あるいは回路設計のためのシミュレーテッドアニーリングオプティマイザのように - これは すべてうまくやっていますが、それはこの話題についてではありません。
「ライティングソフトウェア」を全く考えないことが最善です。 同様に、C ++、Haskell、Pythonなどの伝統的な言語は、明らかに哲学において非常に異なっていますが、あなたの猫の写真のためのカタログ作成システムや素晴らしい代替手段 LaTeXに 特定のドメインでは、他のドメインよりも優れているかもしれませんが、すべて実行可能です。 確率的プログラミング言語(PPL)ではそうではありません。 これはPrologに似ています。確かに、プログラミング言語ですが、本格的なソフトウェアを書くための適切なツールではありません。
1.2 確率論的プログラミングは
代わりに、確率的プログラミングは統計的モデリングのためのツールです。プログラミング言語の世界から教訓を借りて、統計モデルの設計と使用の問題に適用することです。専門家は、紙で数学的表記法で統計的モデルを手作業で構築していますが、機械的推論ではサポートが難しい専門家専用のプロセスです。 PPの重要な洞察は、統計的モデリングを十分に行えばプログラミングのように感じることができるということです。私たちが飛躍し、モデリングに実際の言語を使用すると、多くの新しいツールが実現可能になります。我々は、各インスタンスごとに紙を書くことを正当化するために使用したタスクを自動化することができます。
ここでは2つ目の定義があります。確率的プログラミング言語は、プログラムの統計的な振る舞いを理解するのに役立つ、randを持つ普通のプログラミング言語であり、関連するツールの大きな塊です。
これらの定義は両方とも正確です。彼らは同じコアアイデアで異なる角度を強調します。どちらがあなたにとって理にかなっているかは、あなたがPPを使いたいものに依存します。しかし、PPLプログラムは、プログラムを実行して何らかの出力を得ることが目標である通常のソフトウェア実装とよく似ているという事実に気を取られないでください。 PPの目標は分析であり、実行ではありません。
1.3 例:用紙の推奨事項
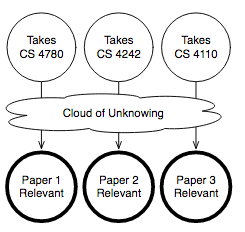
図1.紙の推奨問題ライトサークルが観察されます。重い円は私たちが望む出力です。
実例として、学生が受ける授業に基づいて研究論文を推薦するシステムを構築しているとしましょう。簡単に言えば、プログラミング言語と統計/機械学習という2つの研究テーマしかないとしましょう。すべての論文は、PL紙、統計紙、またはその両方です。そして、コーネルの3つのコース、すなわちCS 4110(プログラミング言語)、CS 4780(機械学習)、架空の選択肢「CS 4242」を確率論的プログラミングについて検討します。
機械学習がこの問題のために働くはずです。あなたのクラススケジュールによって明らかにされた領域が混在していると、読んでみたい論文について何か言わなければなりません。問題は、正確な関係が直接的に推論するのが難しいことです。明らかに4780を取ることは、統計に興味がある可能性が高いことを意味しますが、正確にどれくらい可能性が高いのでしょうか?あなたのスケジュールに合った唯一のクラスであるため、4780に登録した場合はどうなりますか?架空のCS 4242だけを取って実際のコースを取っていない人たちについて、私たちは何をやっていますか?彼らは50/50 PL / statsの人々だと思いますか?
1.3.1問題のモデリング
この問題に近づく機械学習の方法は、ランダム変数を使用して状況をモデル化することです。そのうちのいくつかは潜在的です。 重要な洞察は、図1の矢印はそれほど意味をなさないということです。実際には因果関係を表していません! それはあなたが特定の論文にもっと興味を持つようにすることではない。 確率的に両方の事象を引き起こす他の要因があります。 これらは、状況を説明するためのモデルにおける潜在的なランダム変数である。 潜在変数を自分自身に許すことで、問題について直接的に簡単に推論することができます。
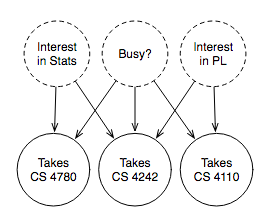
図2.関心が階級登録と紙の関連性にどのように影響するかのモデル。破線の円は潜在変数で、入力も出力もありません。
ここでは、統計やプログラミング言語に対する各人の関心のために、いくつかの潜在変数を導入したモデルを紹介します。 モデルについてより具体的に説明しますが、矢印は少なくとも意味を成しています。つまり、ある変数が何らかの形で別の変数に影響を与えることを意味します。 あなたが興味を持っているすべてのクラスを受講していないことを私たちは皆知っているので、3つ目の隠された要素が含まれています:どのくらい忙しいですか。
この図はベイジアンネットワークを示しており、各頂点がランダム変数であり、各エッジが統計的依存性であるグラフである。 それらの間にエッジを持たない変数は、統計的に独立しています。 (つまり、変数の1つについて何かが分かっていると、他の変数の結果については何もわかりません)。
モデルを完成させるために、潜在的な関心変数が紙の関連性にどのように影響するかを示すためにノードとエッジを描画します。
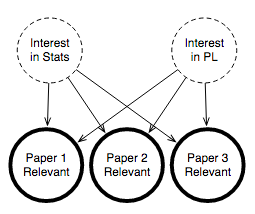
図3.モデルの残りの部分:関心が紙の関連性にどのように影響するか
アイデアは、人々の関心度やビジネスが何であるかを人々に尋ねるのではなく、私たちが観察できるものから推測しようとします。 そして、この推測された情報を使って、実際にやりたいことをすることができます:与えられた学生の紙の関連性を推測します。
1.3.2 人間のモデル
これまではモデルの依存関係の図を描いてきましたが、私たちが意味するものについて具体的に説明する必要があります。 通常の方法は次のとおりです。ランダム変数を関連付ける一連の数学を書き留めます。
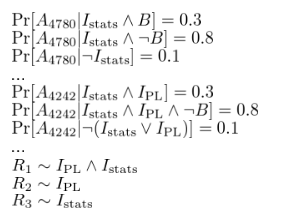
そのようなシンプルなモデルのための数学はたくさんあります!そしてそれは難しい部分でもありません。ハードと便利なビットは、我々の観測に基づいて潜在変数を推測する統計的推論です。統計的推論は機械学習の基礎研究であり、容易ではありません。伝統的に、専門家は手作業で考案した新しいモデルごとに個別の推論アルゴリズムを設計しています。
この小さな例でさえ、手作業による統計モデリングを慎重に行うべきです。アセンブリコードの作成のようなものです:プログラミングのようなものですが、抽象概念、再利用、記述変数名、コメント、デバッガ、型システムはありません。クラス登録の方程式を見てみましょう。たとえば、その繰り返しは数学的なことを書くのに疲れました。これは、昔ながらのプログラミング言語抽象化の仕事であることは明らかです。関数です。 PPLの目標は、あなたがすでに知っていて愛するプログラミング言語の古くて強力な魔法を統計の世界にもたらすことです。
2.基本的な考え方
確率的プログラミング言語の基本的な概念を紹介するために、JavaScriptに埋め込まれたPPLであるwebpplというプロジェクトを使用します。 この言語の詳細は、StanfordのNoah GoodmanとAndreasStuhlmüllerの進歩的な書籍であるProbabilistic Programming Languagesの設計と実装で読むことができます。 あなたのブラウザですぐに遊ぶことができるので、紹介として使うのはいい言葉です。
2.1。ランダムプリミティブ
言語を確率的プログラミング言語(PPL)にする最初のことは、乱数を描くためのプリミティブのセットです。 この時点で、PPLはrand呼び出しを持つ古い命令的言語のように見えます。 信じられないほど退屈なwebpplプログラムがあります:
var b = flip(0.5);
b ? "yes" : "no"
この退屈なプログラムはちょうど1つの文字列または別のものを返すために公正なコイン投げの結果を使用します。 ランダムブーリアンを生成するフリップ関数にアクセスできる通常のプログラムとまったく同じように動作します。 フリップのような関数は、時にはエレメンタリーランダムプリミティブと呼ばれ、これらのプログラムのすべてのランダム性の源です。
webpplエディタでこの小さなプログラムを実行すると、まさにあなたが期待していることがわかります:時には "yes"を出力し、時には "no"を出力します。
webpplが個々の値だけでなく、配布物全体を表現できることが分かったら、少し面白くなります。 Webppl言語には、関数によって定義された分布内のすべての確率を出力する列挙演算があります。
var roll = function () {
var die1 = randomInteger(6) + 1;
var die2 = randomInteger(6) + 1;
return die1 + die2;
}
var dist = Enumerate(roll);
print(dist);
viz.auto(dist);
可能なすべてのダイの値が2〜14とそれに関連する確率でプリントアウトされます。 そのviz.autoコールは、webpplのブラウザ内インターフェイスに、きれいなグラフを表示するよう指示します。
ロール関数を何度も何度も実行するだけで、あなたが好きな言語でEnumerateを書くことが想像できるので、これは驚くべきことです。 しかし実際、Enumerateはもう少し強力なことをしています。 分布の近似を得るのはサンプリングの実行ではありません。 正確な分布を得るために実際に関数が実行される可能性をすべて列挙しています。 これは、確率的プログラミング言語のポイントを明らかにする:PPLプログラムを分析するツールは、実際にプログラムを直接実行するのではなく、重要な部分です。
2.2 webpplのサンプルモデル
これは、ペーパーリコメンダモデルの計算をコード化するのに十分です。 関連性のある部分とクラスの登録部分をエンコードする関数を書くことができます。私たちは無作為に "生徒のプロフィール"を生成してテストすることができます。
// Class attendance model.
var attendance = function(i_pl, i_stats, busy) {
var attendance = function (interest, busy) {
if (interest) {
return busy ? flip(0.3) : flip(0.8);
} else {
return flip(0.1);
}
}
var a_4110 = attendance(i_pl, busy);
var a_4780 = attendance(i_stats, busy);
var a_4242 = attendance(i_pl && i_stats, busy);
return {cs4110: a_4110, cs4780: a_4780, cs4242: a_4242};
}
// Relevance of our three papers.
var relevance = function(i_pl, i_stats) {
var rel1 = i_pl && i_stats;
var rel2 = i_pl;
var rel3 = i_stats;
return {paper1: rel1, paper2: rel2, paper3: rel3};
}
// A combined model.
var model = function() {
// Some even random priors for our "student profile."
var i_pl = flip(0.5);
var i_stats = flip(0.5);
var busy = flip(0.5);
return [relevance(i_pl, i_stats), attendance(i_pl, i_stats, busy)];
}
var dist = Enumerate(model);
viz.auto(dist);
これを実行すると、すべての観測データの分布が表示されます。 これはあまり役に立ちませんが、面白いです。 たとえば、学生について何も知らなければ、私たちのモデルは、クラスを取らず、いずれの論文にも興味を持たない可能性が高いと言うことができます。
2.3 コンディショニング
PPLの次の重要な部分は調整構造です。 コンディショニングを使用すると、プログラム内の特定の実行に与えるべきウェイトを決定することができます。 重要なことは、計算の途中で実行の途中で実行の重みを選択することができます。 実行を完全に無関係にすることもできます。実行を効果的にサブセットにフィルタリングします。
このコンディショニング操作は、観測を符号化するのに特に有用です。 プロセスの結果について何か知っていれば、コンディショニングを使用して、観察が真でなければならない(または真実である可能性が高い)ことを伝えることができます。 考案された例について、私たちのサイコロの例に戻りましょう。 最初のダイスを見たとしましょう。それは4です。ダイスの1つが4:1であることを前提に、この情報を条件にして合計値の分布を与えることができます。
var roll = function () {
var die1 = randomInteger(6) + 1;
var die2 = randomInteger(6) + 1;
// Only keep executions where at least one die is a 4.
if (!(die1 === 4 || die2 === 4)) {
factor(-Infinity);
}
return die1 + die2;
}
当然のことながら、分布は結果8を除いてフラットであり、4つのロールを含む1つのロールのみがその合計を生み出す可能性は低い。 2と12のような結果は、サイコロが1つ上がっても起こり得ないので確率はゼロです。
一方で、どちらかのダイスを見ることはできませんが、ダイスの合計が10であると誰かから教えられたらどうでしょうか?これはダイス自身の価値について何を教えてくれるのでしょうか? ロールの結果を調整することによって、この観測値を符号化することができます。
var roll_condition = function () {
var die1 = randomInteger(6) + 1;
var die2 = randomInteger(6) + 1;
// Discard any executions that don't sum to 10.
var out = die1 + die2;
if (out !== 10) {
factor(-Infinity);
}
// Return the values on the dice.
return die1 + "+" + die2;
}
結果はおそらくあなたを驚かせることはありませんが、我々は推薦者と同じ原則を使用することができます。
2.4 実際に推薦論文
実際に勧告を出すのと同じ哲学を今使ってみましょう。 それは簡単です:関心のある人のクラス登録を条件づけするだけです。自分のクラスであるCS 4110と、架空のPPLクラス、CS 4242に参加しますが、MLではなく クラス、4780。
// A model query that describes my class attendance.
var rec = function() {
var i_pl = flip(0.5);
var i_stats = flip(0.5);
var busy = flip(0.5);
// Require my conference attendance.
var att = attendance(i_pl, i_stats, busy);
require(att.cs4242 && att.cs4110 && !att.cs4780);
return relevance(i_pl, i_stats);
}
(この例では、因子をラップする必要がある(-Infinity)を定義し、条件を満たさないプログラムの実行を完全に排除します)。このrec関数で列挙を呼び出すと、最終的には便利です。 一度に1つの用紙を見るだけではわかりやすいです。
return relevance(i_pl, i_stats).paper1;
突然、これはかなり元気です! 列挙子に私たちに関係する実行がどのようなものであるかを伝えることによって、それらの条件の下でデータが何を知っているかを教えてくれるでしょう。 私にとっては、ほとんどのプログラマーにとって、これは確率モデルを表現するためのもっと自然なツールのようなものだと思っています。 どのランダム変数がどの変数に依存するかを注意深く書き留めるのではなく、それらの依存関係を構築するためにプログラム実行の流れを使用します。
このセクションのポイント:生成モデルの作成は非常に快適で簡単です。プログラミング言語は生成アルゴリズムを書き留めるうえで最適な方法です。 私たちは、これらの単純なモデルの推論をコンパイラやツールに移すことで、仕事を簡単に成功させることに成功しました。
参考
https://futurism.com/new-ai-can-write-and-rewrite-its-own-code-to-increase-its-intelligence/
https://www.cs.cornell.edu/courses/cs4110/2016fa/lectures/lecture33.html
https://www.technologyreview.com/s/544376/this-ai-algorithm-learns-simple-tasks-as-fast-as-we-do/