ニューラルネットのハイパーパラメータの最適化には
現状グリッドサーチよりランダムの方が精度が高いと言われている。
理由はどのパラメータが精度向上に影響しているかわからない為、
ランダムで探索し影響の高いところを集中的にチューニングしたほうが効果的だから。
それ以上こって作りたい場合は下記の方法を認識している。
1、ランダム
2、進化計算でハイパーパラメータを最適化
3、ベイズ最適化でハイパーパラメータを最適化
ベイズ最適化はこっち
https://github.com/RuiShu/Neural-Net-Bayesian-Optimization
今回は2の進化計算での最適化をメインで理解するために調べた。
ほぼこちらのページの内容です。
http://eplex.cs.ucf.edu/hyperNEATpage/
関係ないかもだけど分子プログラムも。
こっからググればでてくる。
http://repository.dl.itc.u-tokyo.ac.jp/dspace/bitstream/2261/60802/3/A31939_review.pdf
このページは、NEATメソッドの拡張であるHyperNEAT NeuroEvolutionの使用と実装に関する情報を求める方のためのページです。
ここでの情報は、HyperNEATに関する一般的な質問に対処し、方法を適用または拡張したいと思う人に知識を提供することを目的としています。

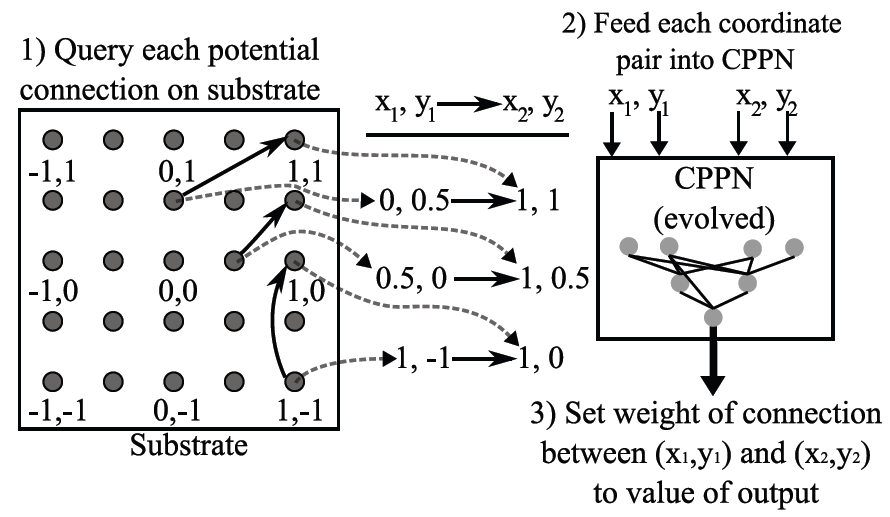
はじめに/ HyperNEATとは?
HyperNEATのことを聞いていないなら、それは進化的アルゴリズムでニューラルネットワークを進化させるNeuroEvolutionの方法です。 これは、NeuroEvolution of Topologies(NEAT)と呼ばれる以前の進化的アルゴリズムから拡張されています。
これには独自のNEATユーザーページもあります。
http://eplex.cs.ucf.edu/hyperNEATpage/
HyperNEATの出版物(上のリンク)は、この方法とその基礎となる表現理論の完全な紹介を提供します。
このセクションでは、その背後にある一般的な考え方について簡単に説明します。
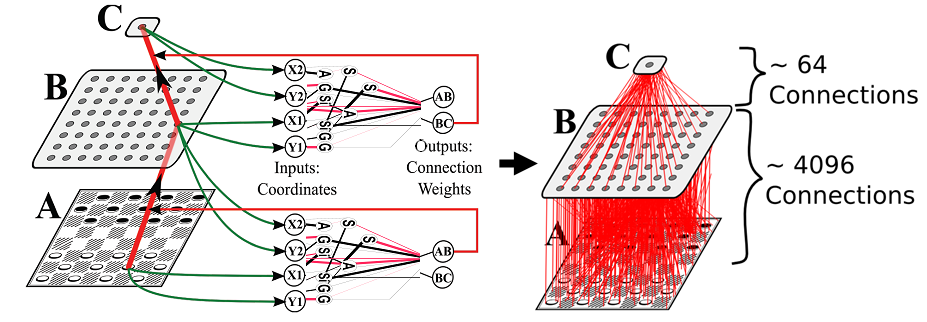
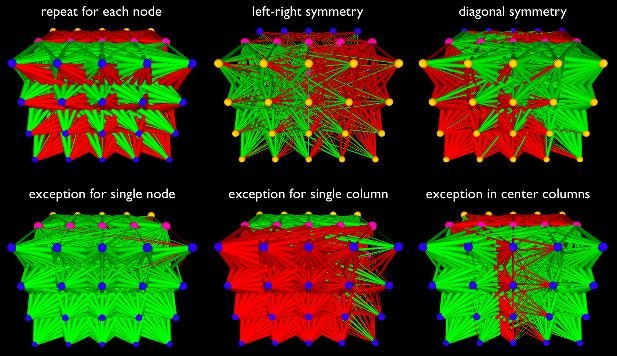
要するに、HyperNEATは、人工ニューラルネットワークの良好な表現が、その接続パターンをコンパクトに記述できるはずであると仮定した表現理論に基づいている。 この種の記述はエンコーディングと呼ばれます。 構成パターン生成ネットワークと呼ばれるHyperNEATのエンコーディングは、対称性、繰り返し性、および反復性などの規則性を持つパターンを表現するように設計されています。
したがって、HyperNEATはこれらの特性を持つニューラルネットワークを進化させることができます。
この能力の主な意味は、HyperNEATが、脳内の神経接続パターン(いくつかの不規則性に加えて多くの規則性を伴って繰り返している)に似ており、一般に以前のアプローチよりもはるかに大きい非常に大きなニューラルネットワークを効率的に進化させることができる学習が生み出すことができる。
HyperNEATの他のユニークで重要な面は、実際に問題のドメイン(領域?)のジオメトリ(形状?)が見えるということです。
(※ジオメトリ=座標を持った線.円.寸法などグラフィカルなオブジェクト。形状など)
考慮すべきことは奇妙ですが、ほとんどのニューラルネットアルゴリズム(およびほとんどの学習アルゴリズム)は、ドメインジオメトリに対して完全に盲目的です。
例えば、チェッカーというボードゲームで位置がニューラルネットワークに入力された場合、どのピースがどのピースに隣接しているかは分からない。
ボードジオメトリを理解することができたら、それを理解する必要があります。
対照的に、人間がチェッカー(ボードゲーム)をプレイするとき、ボードのジオメトリをすぐに知ることができます。
何百というゲームプレイの例から推論する必要はありません。 HyperNEATには同じ機能があります。
実際には入力(および出力)のジオメトリを確認し、そのジオメトリを活用して学習を大幅に強化することができます。
より技術的に言えば、HyperNEATは、そのジオメトリの関数としてニューラルネットワークの接続性を計算します。
HyperNEATがジオメトリを利用することができることの1つは、ニューラルネットワーク学習にまったく新しい種類の影響を与えることです。
ユーザーはドメインのジオメトリをHyperNEATに記述できるようになりました。
つまり、創造的な空間があります。
ドメインが異なるジオメトリで最もよく記述できると考える人は、HyperNEATでテストできます。
このように、HyperNEATは、ニューラルネットワークのための新しい種類の研究方向を開く。
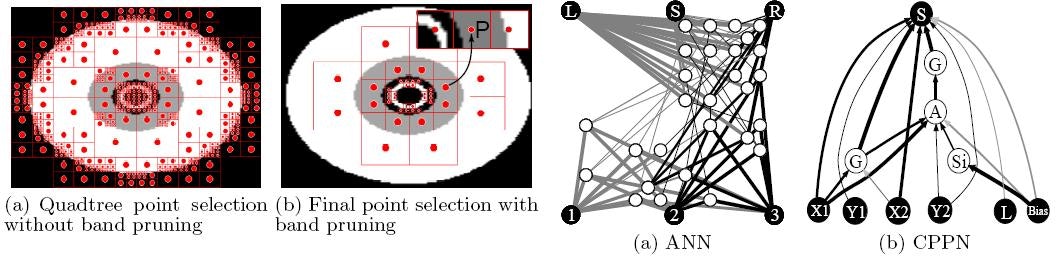
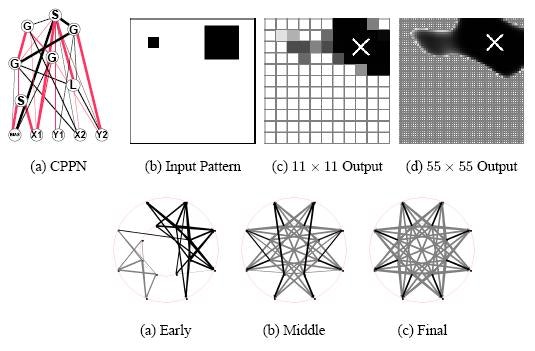
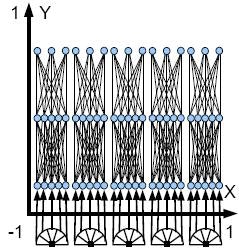
この幾何学的レイアウトは基板と呼ばれ、 上の図に描かれています。
したがって、HyperNEATが何をしているかを表現する1つの方法は、特定の基板ジオメトリを持つニューラルネットワークの接続パターンを進化させることです。
ソフトウェアパッケージ
完全なパッケージの選択については、 HyperNEATソフトウェアカタログを参照してください。
http://eplex.cs.ucf.edu/neat_software/#HyperNEAT
HyperSharpNEATにはマルチエージェントの捕食者実験が、 HyperNEAT C ++には視覚的識別タスク(「ボックス」タスク)とチェッカー(ボードゲーム)実験が含まれています。 Colin GreenのHyperNEATバージョンにはボックスドメインも含まれていますが、Jason Gauciとは異なり、C#で書かれています。 Phillip VerbancsicsのバージョンにはKeepawayが含まれ、Bird's Eye View(BEV)基板が実装されています。 Oliver ColemanのJavaパッケージは、完全な視野に焦点を当てた実験を提供します。 新しい実験を計画している場合は、同様の実験のコードを見てみると役に立ちます。
NEAT
HyperNEATはNEATメソッドを拡張します。 (NEATはHyperNEATでネットワークを生成するCPPNを発展させています。)
NEATでは多くの情報が入手でき、多くの実装がサポートされています。
NEATは、拡張トポロジーのNeuroEvolutionの略です。
これは進化的アルゴリズムを用いてニューラルネットワークを進化させる方法である。
NEATは、小型でシンプルなネットワークで進化を開始し、世代にわたってますます複雑になるようにすることが最も効果的であるという考えを実現しています。
そうすることで、自然界の生物が最初の細胞から複雑さが増したように、NEATのニューラルネットワークも同様に増加しました。
継続的な詳細化のこのプロセスは、非常に高度で複雑なニューラルネットワークを見つけることを可能にする。
NEATおよびNEATソフトウェアの詳細については、 NEATユーザーページを参照してください。
http://eplex.cs.ucf.edu/hyperNEATpage/
HyperNEAT方法論のFAQ
このスペースは、HyperNEATメソッドロジーに関するよくある質問とHyperNEATの背後にある理論のために用意されています。
HyperNEATと呼ばれるのはなぜですか?
「HyperNEAT」の「Hyper」は、「Hypercube」(超立方体)という単語に由来します。
一口であるアプローチの完全な名前は、「Hypercubeに基づいた拡張型トポロジーのNeuroEvolution」です。
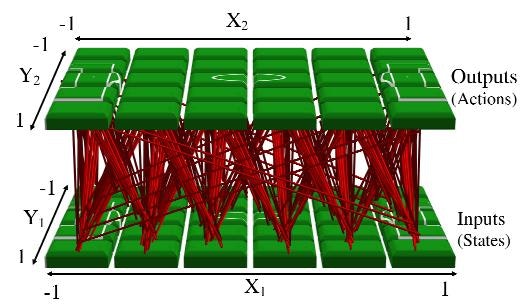
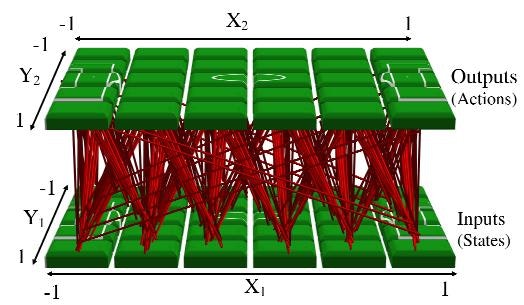
接続パターンを記述するCPPNが少なくとも4次元(すなわち、x1、y1、x2、およびy2をとることから)であるため、「Hypercube」という語がこのアプローチを記述する理由があります。
場合によっては、符号化された接続パターンが3次元である場合など、4次元以上のものであってもよい。
その場合、CPPNは6次元である(すなわち、入力x1、y1、z1、x2、y2、およびz2から)。
これらの多次元空間は、通常、-1で始まり各次元で終わる超立方体の境界内でサンプリングされる。
超立方体内の各点は接続重みを表す。 したがって、HyperNEATは実際にはハイパーキューブの内部にパターンを描いています。
そのパターンは、ニューラルネットワークの接続パターンとして解釈されます。
NEATの名前の残りの部分は、HyperNEATでは、ニューラルネットワーク基板の重みを順番に符号化するCPPNのトポロジーと重み(および活性化関数)を展開するNeuroEvolution of Topologiesメソッドから来ています。
HyperNEATにはどのような問題に利点がありますか?
HyperNEATは必ずしもすべての問題に最適な選択肢ではありません。
HyperNEATは、ほとんどの問題で少なくともNEATなどの他の神経進化方法を実行する必要がありますが、重要な利点が得られない場合は、基板を使用する努力が必ずしも必要なわけではありません。
したがって、HyperNEATがいつ最大の利点を提供するかを知ることは有用です。 潜在的な利点を期待できるいくつかのタイプの問題があります。
1、多数の入力に関する問題 。
HyperNEATのCPPNは間接的なエンコーディングであるため、HyperNEATの問題の難しさの主な原因はネットワークのサイズ(他のほとんどの学習方法とは異なります)ではありません。
つまり大規模または大規模な入力配列を入力することは、学習アルゴリズムにとっては不可能ではありません(CPUが実際に巨大なネットワークを通過するには、それがどれほど大きいかによって異なります)。
大規模な入力配列の問題の例としては、視覚的な領域(目の多くの入力)やボードゲーム(ボード上の多くの四角形など)があります。
2、多数の出力に関する問題 。
HyperNEATは、一般的な強化学習アルゴリズムとは異なり、多くのインプットを持っているのと同じくらい多くのアウトプットを持つように快適です。
伝統的なニューラルネットワークには、通常、数十、数百、またはそれ以上の出力は含まれていませんが、これは禁止されている可能性が高いためです。
原則として多くのアウトプットを持つことで、問題解決の創造的アプローチが可能になります。
例えば基板は、移動したい場所を描画する2次元マップ全体を出力することができる。
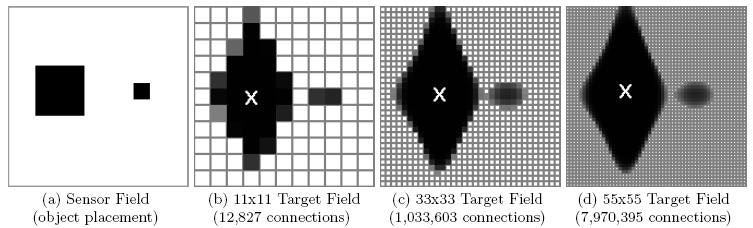
3、可変解像度の問題 。
いくつかの問題については、正確に入力がいくつあるべきか明確ではないかもしれません。 例えば、視野の最適解像度は先験的には分かっていないかもしれない。 同様に、出力のための最良の解像度も知られていない可能性があります。 例えば、マルチセグメントアームのセグメントおよび関節筋肉の最適な数は分かっていないかもしれない(それぞれが出力を必要とする)。 HyperNEATは、その性能が与えられた解像度にほとんど依存しないため、そのようなドメインにとって魅力的な選択肢です。 したがって、最初に解決策を得ることを心配する必要はなく、最小化することさえも心配する必要はありません。 後でもっと解像度を上げたい場合は、高い解像度で実験をやり直すだけで、高い確信度が得られます。 また興味深いことに、訓練後に、さらに訓練することなく基板の解像度を単純に拡大し、基板上でCPPNを再クエリすることができます。 場合によっては、その解像度で訓練されていないにもかかわらず、ソリューションは依然としてより高い解像度で動作します。 そうでない場合でも、さらに高解像度で学習することができ、低解像度で学習したものをブートストラップすることができます。
4、入力および/または出力間の幾何学的関係に関する問題 。
HyperNEATには、入力ニューロン、出力ニューロン、および隠れニューロンの座標が表示されます。 つまり、問題解決の際に相対的なジオメトリを先取りすることができます。
例えば、チェッカー(ボードゲーム)では、どの正方形がどの正方形に隣接し、どの方向にあるのかを実際に見ています。 そのような知識はチェッカー(ボードゲーム)のようなゲームにとって基本的なものです。つまり、基板の幾何学的形状は、例えば幾何学的知識が全くない伝統的なニューラルネットワークに比べて大きな利点になります最終的なパフォーマンスを阻害する多くの例を通じて)。
しかし、ジオメトリはボードゲームで重要なだけではありません。 どのピクセルが画像の中で次のものであるか。 どのジョイントがボディの中でどの物質の問題であるか(出力のジオメトリに反映される) また、入力と出力の間の幾何学的な相関も同様に役立ちます。 左側のセンサーが左側にあり、左側のエフェクターが左側にある(そして右側が左側を反映している)場合、HyperNEATはジオメトリの対称性を活用し、左を右に、左を右に相関させることができます。 基質を介してHyperNEATに幾何学的知識を伝える能力は、学習領域の創造的表現を探索する新たな機会を創出する。
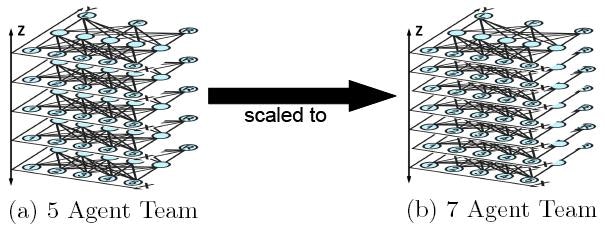
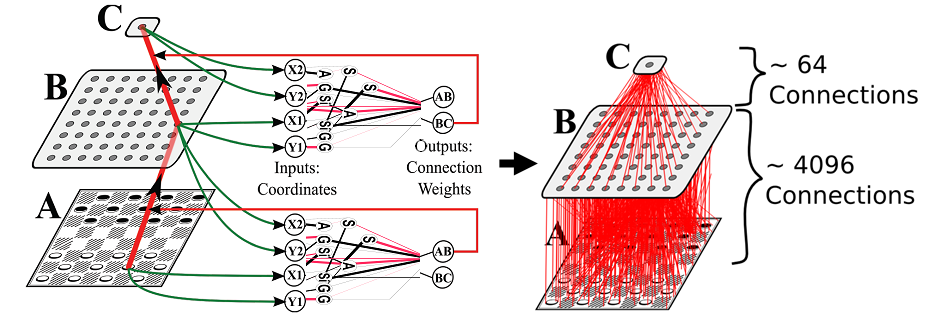
5、マルチエージェント学習の問題 。
マルチエージェントHyperNEATと呼ばれるHyperNEATの拡張により、間接エンコーディングとジオメトリをマルチエージェント学習ドメインに適用することができます。 HyperNEATがこのようなタイプの問題に適している理由は、チームのプレーヤーの標準的な幾何学的位置がその仕事に相関する暗黙的なジオメトリ(これをポリシージオメトリと呼ぶ)を持つことが多いからです。 たとえば、サッカー(フットボール)チームでは、ディフェンダーがフィールドの背面に配置され、ストライカーが前面に配置されます。 この種の相関はスポーツチームでは一般的であり、他のタイプのチームでも活用できます。 チームのジオメトリ全体でのジョブの分散を考えると、チームのポジション全体で幾何学的なパターン(各ジョブは異なる色であると想像してください)を描くのとは異なります。 それがCPPNの成果です。 だから、マルチエージェントの問題は、(マルチエージェント)HyperNEATの興味深い研究分野です。
6、神経可塑性 。
適応型HyperNEATを用いた最近の研究では、CPPNが周囲のニューロンの活性化レベルに応じて結合重量がどのように変化するかをコードすることができることが示されている。 興味深いことに、接続重みを色として変更するルールについて考えると、ネットワークのジオメトリ全体でこのようなルールのセットをエンコードすることは、その接続全体にカラーパターンをペイントするようなものです。 もう一度、それはCPPNがうまくいくタイプのものです。 したがって、CPPNは、生物学におけるプラスチック脳を連想させるネットワーク全体にわたる可塑性規則の幾何学を符号化することができる。
隠れたノードを持つ基板をエンコードするためにCPPNを設定する正しい方法は何ですか?
まず、正しい方法はありません。 代わりに、いくつかの主な可能性があります。
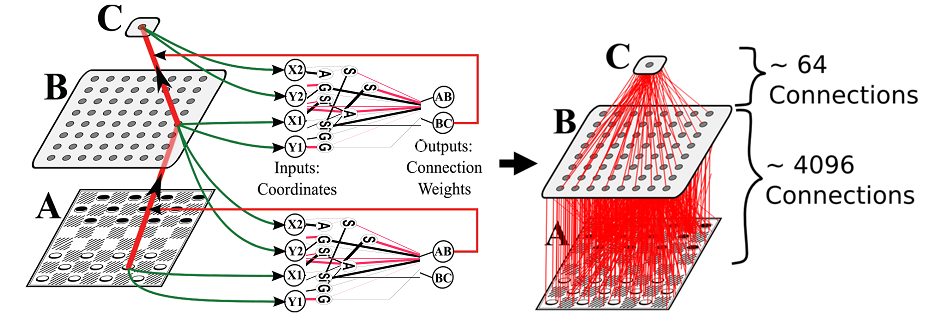
第1の可能性は、単純に隠れたノードを基板上に置き、それらにCPPNで接続する接続を照会することである。 例えば、基板が2次元である場合、入力はy = -1(基板の底面)にあり、出力はy = 1(基板の上部)にあり得る。 隠れノードは、y = -1とy = 1の間のどこにでも置くことができます。 たとえば、y = 0に隠れノードの行が存在する可能性があります。 次に、y = 0のノードまたは2つのノードからの接続は、隠れノードとの間で接続されます。 基板が3次元(各ノードがx、y、z座標に存在することを意味する)である場合、z次元を用いて隠れノードを表すことができる。 そのようにして、z = -1は入力、z = 1の出力、おそらくz = 0の隠れたノードになります。 この3-Dセットアップでは、z = 0は1行ではなく平面です(y = 0が2-Dの場合)。 もちろん、非表示のノードはどこにでも配置でき、単一のレイヤーを形成する必要はありません。 例えば、あるものはz = 0にあり、あるものはz = 0.5にあり得る。 プレースメントはユーザー次第です。
CPPNが隠れノードとの接続を符号化する第2の可能性は、異なる出力を有するネットの異なる層を表現することである。 この論文のチェッカー(ボードゲーム)基板はこのように機能します。 その考え方は、第1の出力が入力層から隠れ層への接続に対して読み出され、第2の出力が隠れ層から出力層への接続のために読み取られるということである。 このようにして、別個のCPPN出力ノードが各層に対応する。 もちろん、この方法であっても、各層内のノードをどのように表現するかについての決定はまだ行われなければならない。 例えば、それらは、1-D、2-D、3-D、またはさらに高次の次元で表現することができる。 このホワイトペーパーでは、これらのオプションを比較して、次元の選択が大きな違いを生むことがわかりました。 このペーパーは、特にマルチモーダルの問題に対して、複数の出力を使用する利点の新しい証拠を提供します。
隠れたノードを持つ基材を照会するこれらの2つの方法は、異なる示唆を持っています。 異なるCPPN出力が異なる隠れ重み(上記の第2の可能性)を表す場合、第1の層の重みの幾何学的パターンは第2の層のパターンと高度に関連する可能性が低い。なぜなら、異なるCPPN出力は、それらのパターンは半独立している。 一方、すべての接続に単一のCPPN出力から重みが割り当てられると、すべての重みおよびレイヤにわたって大域パターンが観測される可能性が高くなります。 もちろん、これらはバイアスだけであり、保証はありません。 また、レイヤー間の幾何学的相関が望ましいかどうかはドメインに依存するため、一方の選択肢が他方の選択肢より明らかに優れているわけではありません。
また、HyperNEATの新機能である進化的基板HyperNEAT (ES-HyperNEAT)は、HyperNEATが隠れノード自体の配置と密度を進化させることを可能にします。次の質問で説明します。
HyperNEATが基板上の隠れたニューロンの配置と密度を独自に決定する方法はありますか?
はい、この課題は活発な研究分野です。 HyperNEATが、伝統的なCPPNを超えた追加表現なしで隠れニューロンの配置と密度を決定する方法が確かにあることが判明しました。 このアプローチは、 進化的基質HyperNEATと呼ばれています。
主なアイデアは、ES-HyperNEATが、CPPNによって描かれたハイパーキューブのパターンを検索して、高い情報の領域を見つけ出し、そこから接続を選択することです。
これらの接続が接続するノードも当然選択されます。 従って、密度は情報に従うべきであるという哲学です:CPPNでコード化されたパターンにもっと多くの情報がある場合、それをキャプチャするために基板内でより高い密度が必要です。 このアプローチに従うことによって、ユーザが隠れたノードの配置または密度について何かを決定する必要はない。
詳細については、 ニューロンの配置、密度、接続性を進化させるための拡張ハイパーキューブベースのエンコーディングを参照してください。
http://eplex.cs.ucf.edu/papers/risi_alife12.pdf]
ニューラルネット基板バイアスを得る最良の方法は何ですか?
まず、どのようなタイプのニューラルネットワークかと同様に、バイアスが重要になります。
あなたの実験がうまくいかない場合は、バイアスを含まないためかもしれません。
もちろん、 CPPNが偏りを持っているという理由だけで基板に1つのバイアスがあるという意味ではなく、基板が実際のニューラルネットワークであるため、バイアスをかけて通常のニューラルネットワークのようには機能しません、それは一つ。
基板にバイアスを与えるには2つの方法があります。
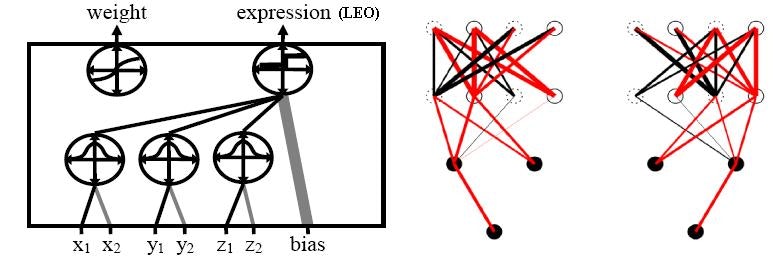
第1の選択肢:バイアスとして機能するノードを基板上に置くことができます。これは一定の入力(通常は1.0または0.5)を取ることを意味します。 CPPNは、他のノードと同様に、残りのネットワークにバイアスを接続します。 HyperNEATの外では、この考え方は簡単です。 たとえば、NEATでは、バイアスを追加することはもう1つの入力を含むだけ簡単です。 しかし、HyperNEATでは、偏りに座標を与えなければならないため、それほど簡単ではなく、しばしば神経の形態がどこにあるのかは明らかではありません。 したがって、この伝統的な方法でバイアスを加えることは、HyperNEATでは自然ではないかもしれません。 同様に、実際の脳には「偏り」があるほど、おそらく脳内の任意の場所に座っているのは単一のノードではありません。 したがって、HyperNEATでは、2番目の選択肢が望ましい場合があります。
第2のオプション:空間内の特定の場所のバイアスを出力する新しい出力をCPPNに追加することができます。 この新しい出力は、重量を決定する通常の出力に加えていることに注意することが重要です。 したがって、CPPNは1つの出力から重みを決定し、別の出力からバイアスを決定します。 基板内のノードは場所に存在することを想起してください。 したがって、CPPNは、バイアスを返すために各ロケーションについて照会することができる。 この偏りは、ノードの全アクティブ化に加えられる定数です。 したがって、バイアスノードからの入力ウェイトに定数項(たとえば1.0)が乗算されるのは実際には似ています。 しかし、この場合、実際のバイアスノードはなく、バイアスウェイトは他のウェイトとは別に計算されます。
第2の選択肢で気付くかもしれない1つの問題は、それが過度に指定されていることです。 CPPNは接続の重みを決定するために使用されるため、バイアスなどのノード中心値を照会するのに必要な座標よりも多くの座標があります。 たとえば、4次元では、(x1、y1、x2、y2)に接続が存在しますが、ノードは(x、y)にのみ存在します。 したがって、質問は、2つだけ必要な場所の値に対して4つの入力をCPPNに求める方法です。 解決策は、条約を確立することです。 例えば、慣例により、バイアスは全て(x1、y1,0,0)に対してのみ照会されると言うことができる。 幾何学的には、点(x1、y1,0,0)の集合は4の2-D断面である(x1、y1) -D hypercube。 だから、私たちはすべての偏見がその横断面にあると言っています。 それは他の方法でもできるが、この特別な大会はこれまで過去に働いていた。
CPPNのバイアス出力ノードは重量出力とは異なることを想起されたい。 したがって、重量出力は、基板内のすべての(x1、y1、x2、y2)座標について引き続き照会される。 しかし、バイアス出力は、x2 = 0かつy2 = 0のときのみ照会されます。 これにより、基板のバイアス値のパターンが得られます。
HyperNEATのCPPN出力の範囲が切り詰められ、異なる範囲に正規化されるのはなぜですか?
HyperNEATでは、従来のように、重みの大きさ(CPPNによる出力)がある閾値を下回る接続を表現しません。 例えば、閾値は0.2であり、これは接続が[-0.2..0.2]の間の重みで表されないことを意味する。 この大きさを超える(したがって表現される)接続の場合、その重みは範囲にスケーリングされます。 たとえば、合理的な範囲は[-3.3.3]です。 問題は、この切断とスケーリングが行われる理由です。
一般的な考え方は、CPPNがいくつかの接続が表現されないことを示唆することを可能にし、それによって任意のトポロジーを可能にすることである。 この目的のために、接続が表現されない閾値の大きさ(例えば、0.2)が選択される。 しかし、CPPNは-1と1の間の数値しか出力しないため、出力範囲[0.2.1.1]と[-0.2 .. -1]は表示されたままになります。したがって、範囲を[-3.3 ]。 つまり、0.2または-0.2の値は0にマップされ、1の値は3(および-1から-3)にマップされます。 3番の理由は、経験的経験に基づいている。 それは良い最高の体重になります。 1つの理由は、シグモイド関数の特定の形状であり、特定の点がその最大値または最小値に非常に近くなり、したがってもはや敏感でなくなった後である。 重量範囲は、S字状の感度範囲で良好に較正するように選択される。
人工ニューラルネットワークの間接符号化に関する理論的な研究はありますか?
確かに、Juergen Schmidhuberは、ニューラルネットワークにおける重みの圧縮符号化がそうしなければそうした圧縮なしでは困難すぎる特定のタイプの問題を解決することを可能にすることを示した(経験的結果もまた理論的分析を支持している)。
J. Schmidhuber。 Kolmogorovの複雑さが低く、汎化能力が高いニューラルネットを発見する 。 ニューラルネットワーク、10(5):857-873,1997
間接的なエンコーディングに関する一般的な作業の詳細については、どこで知ることができますか?
この分野の調査は以下の通りです。
Kenneth O. StanleyとRisto Miikkulainen。 人工胚発生のための分類学 。 人工生命9(2):93-130,2003
EPlexのHyperNEAT出版物
HyperNEATは、もともとセントラルフロリダ大学の進化的複雑性研究グループ(EPlex)で発明されました。
次の2つの論文は良い紹介です:
(1) 人工ニューラルネットワークの地形的規則性の自律的進化は、HyperNEATがどのように基板の地形の規則性を発見し、それらがなぜ有用であるかを探究する。
http://eplex.cs.ucf.edu/publications/2010/gauci-nc10
(2) 進化する大規模ニューラルネットワークのためのハイパーキューブに基づく符号化は、2つの簡単な例を用いて主なアイデアを示し、それらを詳細に分析する。
http://eplex.cs.ucf.edu/publications/2009/stanley-alife09
EPlexのHyperNEAT関連のすべての出版物は以下のとおりです。
より複雑なレギュラーニューラルネットワークを進化させるES-HyperNEATの強化
セバスチャン・リシ、ケネス・O・スタンリー
In: 遺伝的および進化的計算会議の議事録(GECCO-2011) 。 ニューヨーク、ニューヨーク:ACM、2011(8ページ)
http://eplex.cs.ucf.edu/publications/2011/risi-gecco11
HyperNEATのモジュール性を奨励するための接続を制限する
Phillip VerbancsicsとKenneth O. Stanley
In: 遺伝的および進化的計算会議の議事録(GECCO-2011) 。 ニューヨーク、ニューヨーク:ACM、2011(8ページ)
http://eplex.cs.ucf.edu/hyperNEATpage/
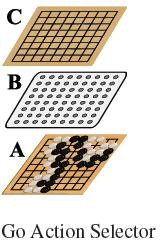
スケーラブルなGoのためのニューラルネットワークの間接符号化
Jason GauciとKenneth O. Stanley
In: Parallel Problem Solving of Nature(PPSN-2010)の第11回国際会議の議事録 。 ニューヨーク、NY:Springer、2010(10ページ)
http://eplex.cs.ucf.edu/publications/2010/gauci-ppsn10
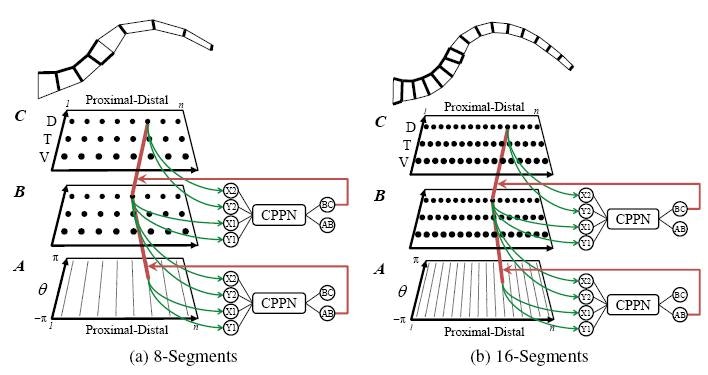
可変セグメントを持つタコのアームのための単一スケーラブルコントローラの進化
ブライアン・G・ウーリーとケネス・O.スタンリー
In: Parallel Problem Solving of Nature(PPSN-2010)の第11回国際会議の議事録 。 ニューヨーク、NY:Springer、2010(10ページ)
http://eplex.cs.ucf.edu/publications/2010/woolley-ppsn10
タスク転送の進化する静的表現
Phillip VerbancsicsとKenneth O. Stanley
In: Journal of Machine Learning Research 11:1737-1769ページ。 Brookline、MA:Microtome Publishing、2010(33ページ)
http://eplex.cs.ucf.edu/publications/2010/verbancsics-jmlr10
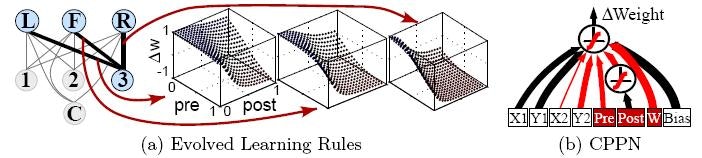
局所的規則のパターンとしての神経可塑性の間接的符号化
セバスチャン・リシ、ケネス・O・スタンリー
In: 適応行動のシミュレーションに関する第11回国際会議(SAB 2010)の講演会 。 ニューヨーク、NY:Springer、2010(11ページ)
http://eplex.cs.ucf.edu/publications/2010/risi-sab10
HyperNEAT基質におけるニューロンの配置と密度の進化
Sebastian Risi、Joel Lehman、Kenneth O. Stanley
In: 遺伝的および進化的計算会議の議事録(GECCO 2010) 。 ニューヨーク、ニューヨーク:ACM、2010(8ページ)
http://eplex.cs.ucf.edu/publications/2010/risi-gecco10
間接エンコーディングによる学習の伝達
Phillip VerbancsicsとKenneth O. Stanley
In: 遺伝的および進化的計算会議の議事録(GECCO 2010) 。 ニューヨーク、ニューヨーク:ACM、2010(8ページ)
http://eplex.cs.ucf.edu/publications/2010/verbancsics-gecco10
人工ニューラルネットワークにおける地形的規則性の自律的進化
Jason GauciとKenneth O. Stanley
出現する: 神経計算ジャーナル。 ケンブリッジ、マサチューセッツ州:MIT Press、2010(原稿38ページ)
http://eplex.cs.ucf.edu/publications/2010/gauci-nc10
スケーラブルなマルチエージェント学習のための進化するポリシージオメトリ
David BDAmbrosio、Joel Lehman、Sebastian Risi、Kenneth O. Stanley
出現するには : 第9回自律エージェントとマルチエージェントシステムに関する国際会議(AAMAS-2010)の議事録。 2010年(8ページ)
http://eplex.cs.ucf.edu/publications/2010/dambrosio-aamas10
進化する大規模ニューラルネットワークのためのハイパーキューブに基づく符号化
ケネス・O・スタンレー、デイビッド・B・ダンブロシオ、ジェイソン・ゴーシ
In: Artificial Lifeジャーナル。 ケンブリッジ、MA:MIT Press、2009(原稿39ページ)
http://eplex.cs.ucf.edu/publications/2009/stanley-alife09
マルチエージェント学習の生成エンコーディング
David B. D'AmbrosioとKenneth O. Stanley
注:このペーパーには、http://eplex.cs.ucf.edu/multiagenthyperneatのビデオセットが添付されています。
In: 遺伝的および進化的計算会議の議事録(GECCO 2008) 。 ニューヨーク、ニューヨーク:ACM、2008(8ページ)
http://eplex.cs.ucf.edu/publications/2008/dambrosio-gecco08
機械学習における幾何学的規則の重要な役割に関する事例研究
Jason GauciとKenneth O. Stanley
注:この文書にはHyperNEATソフトウェアのバージョン2.0が添付されています。
人工知能に関する第22回AAAI会議の議事録(AAAI-2008)。 Menlo Park、CA:AAAI Press、2008(6 pages)
http://eplex.cs.ucf.edu/publications/2008/gauci-aaai08
幾何学的規則の発見による大規模ニューラルネットワークの生成
Jason J. GauciとKenneth O. Stanley
In: 遺伝的および進化的計算会議の議事録(GECCO 2007) 。 ニューヨーク、ニューヨーク:ACM、2007(8ページ)
http://eplex.cs.ucf.edu/publications/2007/gauci-gecco07
ニューラルネットワークセンサと出力ジオメトリを利用するための新規生成符号化
David B. D'AmbrosioとKenneth O. Stanley
In: 遺伝的および進化的計算会議の議事録(GECCO 2007) 。 ニューヨーク、ニューヨーク:ACM、2007(8ページ)
http://eplex.cs.ucf.edu/publications/2007/dambrosio-gecco07
構成パターン生成ネットワーク:開発の新規抽象化
ケネス・O・スタンリー
遺伝的プログラミングと進化的機械特集:Developmental Systems 8(2):131-162 。 New York、NY:Springer、2007(36ページ)
Springerの出版物形式の記事へのリンク(Springerの購読が必要): http:www.springerlink.com/content/804411v3703ph210
http://eplex.cs.ucf.edu/publications/2007/stanley-gpem07

開発なしの規則性の活用
ケネス・O・スタンリー
In: 発達的システムに関するAAAI秋シンポジウムの議事録 。 Menlo Park、CA:AAAI Press、2006(8ページ)
http://eplex.cs.ucf.edu/publications/2006/stanley-aaaifs06
人工表現型と自然の生物学的パターンの比較
ケネス・O・スタンリー
遺伝的および進化的計算会議(GECCO)ワークショッププログラムの議事録 。 New York、NY:ACM Press、2006(2ページ)
http://eplex.cs.ucf.edu/publications/2006/stanley-gecco06
外部EPlexからのHyperNEAT出版物およびプロジェクト
HyperNEATとCPPNに関する重要な研究は、世界中の多くの研究グループで進行中です。
コーネル大学のコーネル計算合成研究所
Jonathan D. HillerおよびHod Lipson、進化するアモルファスロボット、 第12回人工生命国際会議(Alife XII) 、2010年。( pdf )
Clune J、Lipson H、発達生物学に触発されたジェネリックエンコーディングを用いて進化する3次元オブジェクト、2011年、 人工生命に関する欧州会議(p144-148、2011 )。( pdf )
Yosinski J、Clune J、Hidalgo D、Nguyen S、Cristobal Zagal J、Lipson H、ハードウェアにおける進化型ロボット歩行:HyperNEATジェネティックエンコーディング対パラメータ最適化、欧州人工生命会議講演予稿集890-897、2011ページ。( pdf )
HyperNEATジェネリックエンコーディングを使用した物理ロボットの進化:進化コンピューティングのアプリケーションにおけるシミュレーションのメリット 、Springer、2013( pdf )( ビデオ )
( )
Vrije Universiteit(VU)アムステルダムの計算機インテリジェンス(CI)グループ
Evert Haasdijk、Andrei A. Rusu、AE Eiben、モジュラロボットにおける運動制御のためのHyperNEAT 、第9回進化型システム国際会議(ICES 2010) 、2010年。( pdf )
バーモント大学の形態学、進化および認知研究室
Auerbach、JE、Bongard、JC、3次元構造を成長させる進化するCPPN、2010年の遺伝的進化計算会議(GECCO)の議事録 ( pdf )
第12回生命システムの合成とシミュレーションに関する国際会議(ALife XII) 、2010年。( pdf )、アウエルバッハ、JE、ボンゴール、JC、形態学と制御の共進化におけるダイナミックな解像度
ニューサウスウェールズ大学工学部コンピュータサイエンス学科
Oliver Johan Coleman、視覚処理のための進化するニューラルネットワーク、 学士号(コンピュータサイエンス学士) 、2010年。( pdf )
プラハのチェコ工科大学の計算知能グループ
Drchal、J.およびKapra。、O.およびKoutnik、J.およびSnorek、M .: HyperNEAT Mobile Agent Controllerにおける複数の入力の結合。 第19回人工ニューラルネットワーク国際会議 (ICANN 2009)、p。 775-783、Springer、Berlin、2009. ISSN 0302-9743。 ( pdf )
Buk Z.、KoutníkJ.、ŠnorekM.、遺伝的プログラミングに代わるHyperNEATのNEAT 、ICANNGA 2009 ( pdf ) に掲載
DrCal J.、KoutníkJ.、ŠnorekM.、HyperNEAT制御ロボット は、CEC 2009に登場する シミュレートされた環境で道路を運転することを学ぶ ( pdf )
この作品には、 プロジェクトページと学習された運転行動の関連ビデオもあります。
ミシガン州立大学のデジタル進化研究室
Clune J、Stanley KO、Pennock RT、Ofria C.
規則性の連続体における間接符号化の性能について
IEEE Transactions on Evolutionary Computation、2011(出現する)( pdf )
Clune J、Beckmann BE、McKinley PK、Ofria C.
HyperNEATがモジュラーニューラルネットワークを生成するかどうかを調べる。
遺伝的進化計算会議(GECCO)の議事録、2010年。( pdf )
David B. Knoester、Heather J. Goldsby、Philip K. McKinley
モバイルアドホックネットワークの神経進化。
遺伝的進化計算会議(GECCO)の議事録、2010年。( pdf )
Clune J、Beckmann BE、Pennock RT、Ofria C.
HybrID:進化的計算のための間接および直接エンコーディングのハイブリダイゼーション。
欧州人工生命会議(ECAL)、2009年、ブダペスト、ハンガリー。 ( pdf )
Clune J、Pennock RT、Ofria C.
問題の異なる幾何学的表現に対するHyperNEATの感度。
遺伝的および進化的計算会議(GECCO)の議事録、2009年、カナダ、モントリオール。 ( pdf )
Clune J、Beckmann BE、Ofria C、Pennock RTである。
HyperNEAT生成コードでコーディネートされた歩行を進化させる。
進化的ロボットに関するIEEE議会議事録、2009年。ノルウェーのトロンハイム。 ( pdf )
Clune J、Ofria C、Pennock RTである。
ジェネリックエンコーディングは問題の規則性がどのように低下するのか
自然からのパラレル問題解決に関する第10回国際会議の議事。 pp 358-367。 ドルトムント、ドイツ。 ( pdf )
ポズナン工科 大学の計算科学科
このチームによって進化したHyperNEATニューラルネットNeuroHunterは、GECCO'2008平衡ダイエットコンテストで優勝しました。
テキサス大学オースティン校ニューラルネットワーク研究グループ
Erkin BahceciとRisto Miikkulainen 、 コンピュータインテリジェンスとゲームに関するIEEEシンポジウム(CIG)討論会 、2008年のゲームにおける進化型パターンヒューリスティックの移転 ( pdf )