sRPE:「シミュレートされた報酬予測誤差」
sAPE:「模擬他者の行動予測誤差」
領域:vmPFC:腹側前頭前野、dlPFC、背外側前頭前野; dmPFC、背前頭前頭皮質; ヘミ、半球; BA、ブロッドマン地区
vmPFCが価値ベースの意思決定において、同じことを考えているという状態を確認。
vmPFCが報酬予測誤差の表現が自己と他者の間で共有される領域であるという最初の直接的な証拠は、被験者がsRPEを用いて他の隠れ変数を学習し、vmPFCはBOLD信号を有する唯一の脳領域であり、制御タスクの被験者の報酬予測エラーとその他のタスクの被験者のsRPEの両方によって著しく調節された。
概要
社会的認知における基本的な課題は、人間が意思決定行動を予測するために他人の価値をどのように学ぶかということです。この形式の学習は、他方のプロセスをモデル化するために自己の評価プロセスを直接採用することによって、他方のシミュレーションを必要とすることが多いと考えられます。しかしながら、シミュレーション学習の認知的および神経的メカニズムは知られていない。行動、モデリング、およびfMRIを使用して、我々はシミュレーションが2つの学習信号を階層的な配置で含むことを示す。直接募集による腹側前頭前皮質仲介シミュレーションで処理されたシミュレートされた他人の報酬予測誤差は、自己とシミュレートされた他人の評価と同一です。しかし、直接募集は学習には不十分であり、体外/前外側前頭前野にコード化された擬似他者の行動予測誤差を生成する選択肢。これらの知見は、シミュレーションでは、予測を生成するために他の評価をモデル化するためのコア前部回路と、予測を改良するために行動変化を追跡するための付属回路を使用することがシミュレーションによって示される。
前書き
社会環境における基本的な人間の能力は、自分の行動や結果を予測するために、他人の精神状態や隠れた内部変数のシミュレーションです。実際、別のものをシミュレートする機能がmentalizingや心の理論(の基本的な構成要素と考えられているフェールとCamerer、2007、フリスとフリス、1999、ギャラガーとフリス、2003年 と Sanfey、2007)。しかし、社会的認知の重要性にもかかわらず、シミュレーション学習とその認知および神経メカニズムについてはほとんど知られていない。シミュレーションの一般的な仮定アカウントがモデルに自分の意思決定プロセスの直接の募集で他のプロセス(アモディオとフリス、2006、、バックナーとキャロルを 2007 および Mitchell、2009)。直接募集仮説は、他人の内部変数を含め、他者の内部変数を含め、他者の行動がどのように行動するかをモデル化してシミュレートするものであり、このシミュレートされた内部評価プロセスは、自分自身のプロセス。このように仮説はシミュレーションの簡単な説明として簡潔で魅力的ですが、実験的に調べることも難しく、したがって社会認知文学における現在の議論の中心に位置しています(Adolphs、2010、Buckner and Carroll、Keysers and Gazzola、2007、Mitchell、2009 および Saxe、2005)。
私たちは、独自の意思決定のための選択肢を評価する際の行動のシンプルで厳密な説明を提供する強化学習(RL)フレームワークを採用しました。RLはまた、価値と報酬予測誤差の2つの重要な内部変数を使用して、内部プロセスの明確なモデルを提供します。価値は、利用可能なオプションに関連する予想報酬であり、報酬予測誤差(予測報酬と実際報酬の差)からのフィードバックによって更新されます。RLフレームワークは、予測されたように挙動する様々な皮質および皮質構造における神経信号を含むかなりの経験的証拠によって支持されている(Glimcher およびRustichini、2004、Hikosaka ら、2006、Rangelら、2008 および Schultzら、1997) 。
RLのフレームワークや他のパラメトリック分析はまた、意思決定の研究に適用され、(様々な社会的文脈での学習されているベーレンスら。、2008、Bhattさんら。、2010、Coricelliとナーゲル、2009、デルガドら、2005、Hampton et al。、2008、Montague et al。、2006 and Yoshida et al。、2010)。これらの研究は、他者との社会的相互作用や他者の異なる理解によって、人間の評価と選択がどのように異なるかを調査した。彼らは通常、被験者が対話型のゲーム状況において、相手の行動や自分自身について何を考えているかを予測しなければならない場合に、高レベルの擬人化または再帰的な推論を使用することを要求する。
本研究では、第1レベル(そしてそれ以上のレベルではない)の精神化プロセスに相当する、主な仕事のための基本的な社会状況を利用した:被験者は、他の選択肢を予測しながら、その選択肢と結果を他者と観察する必要があった。したがって、我々の研究では、自分のプロセスをモデル化するのに一般的に使用される同じRLフレームワークが、他のプロセスに関連する信号と計算を定義するモデルを提供します。また、被験者が独自の価値観に基づいた決定を下す必要のある制御タスクも使用しました。これらのタスクを組み合わせることで、自らのプロセスと「擬似的な」プロセスの間の脳信号を直接比較することが可能になりました。特に、自己評価(報酬タスク)における報酬予測エラーと模擬その他の評価(主タスク) 。
さらに、主タスクの単純な構造は、RLフレームワークを使用して、直接募集によるシミュレーションのために仮定されたものを超える追加の信号および計算を識別することを比較的容易にする。強く述べているが、直接募集仮説では、他者のプロセスは、自分と同じ認知プロセスおよび神経プロセスによってシミュレートされていると仮定しているため、メインタスクでは、シミュレーション学習は他の結果の知識のみを使用することが期待されます。仮説の弱いバージョンは、認知プロセスの関与のみを仮定する。実際、多くの社会的状況において、より強い仮説が拒絶されるべきである場合には、他方の決定または選択を観察し利用することができる。したがって、我々は、
行動学習、fMRI、および計算モデリングを用いて、自己学習の場合と同じように報酬予測エラーを使用するかどうか、および同じ神経回路を採用するかどうかを尋ねるシミュレーション学習のプロセスを調べました。次に、人間が他の選択肢の変化を観察することによって得られた信号を利用して、シミュレーションの学習を改善し、他者の選択行動を予測するかどうかを調べた。
結果
他者の価値に基づく決定をシミュレートし、自分の判断を下す行動
他者をシミュレートする学習の振る舞いを測定するために、被験者は、制御タスクとその他のタスクの2つの意思決定タスクを実行した(図1A)。「その他」タスクは、他の価値ベースの決定を予測するために被験者のシミュレーション学習を調べるために設計されたものであり、制御タスクは、被験者自身の価値ベースの決定を調べるための参照タスクでした。両方の課題において、被験者は2つの刺激の間を繰り返し選択した。
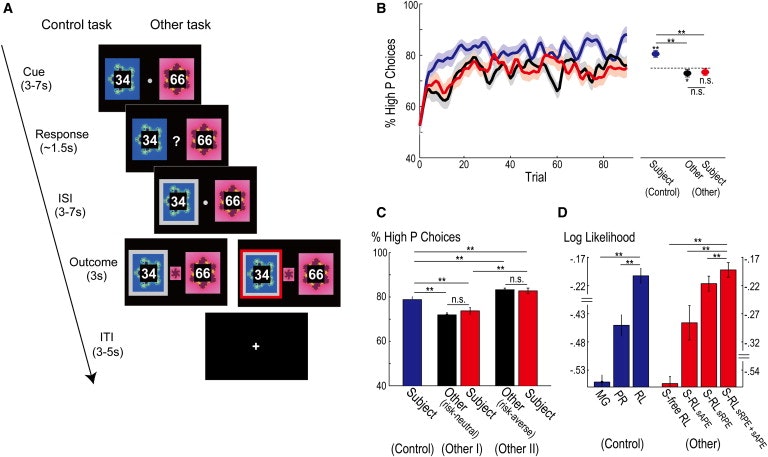
図1。
実験課題と行動結果
(A)実験課題の説明:コントロール(左)とその他(右)。両方のタスクにおいて、各試行は、CUE、応答、INTERSTIMULUS INTERVAL(ISI)、およびアウトカムの4つのフェーズで構成されています。両方のタスクの各試行において、被験者は2つのフラクタル刺激の間を選択し、被験者によって選択された刺激(応答)は、ISI中に灰色の枠で示された。コントロールタスクでは、被験者の「正しい」(報酬を与えられた)刺激が中央に現れた(アウトカム)。その他のタスクでは、他のものの報酬を与えられた刺激が中央に表示され、もう一方の選択は赤い枠で示されました。
(B)全被験者の平均(±SEM)として、試行間の曲線として、報酬確率が高い刺激を選択した平均割合(被験者n = 36) (青)とその他の(赤)タスクでの被験者の選択とその他のタスク(黒)における他の選択のために、これらの曲線は、各個人の選択肢をガウスフィルタ(1.25試行)で平滑化し、次にすべての対象について結果を平均することによって得られた。右の点線は、刺激報酬の確率(75%)を示しています。水平線より上のアスタリスクは、示された平均値(** p <0.01;両側対合t検定; ns、p> 0.05として有意ではない)各点のアスタリスクは、刺激報酬確率( * p <0.05、** p <0.01、両側t検定; ns、p> 0.05として有意ではない)との有意差を示す。ここでは、被験者と他のタスクの報酬確率が高い刺激を選択する平均割合は、刺激報酬確率に関連する報酬確率よりもわずかに低かった(被験者:p = 0.096、その他:p <0.05、両側t検定)。これは、学習がまだ進行中であった場合に平均化が早期試験を含むことを考慮すると合理的である。
(C) 同様のデータは、別の実験(エラーバー=±SEM)で全試験にわたって平均した。 他の2つのタスク条件、その他Iおよび他IIは、それぞれリスク中立およびリスク回避パラメータを使用してRLモデルによってモデル化された他の選択肢に対応する。 ** p <0.01、示されたデータ対間の有意差(両側対合t検定); n.s.、有意ではない(p> 0.05)。
(D)モデルは、コントロール(左)およびその他(右)タスクにおける行動に適合している。各バー(±SEM)は、各モデルの対数尤度を示し、被験者全体で平均化され、試行回数で正規化されます(したがって、大きさが大きいほど行動に適しています)。** p <0.01、2つの示されたモデル間のAIC値の差(AIC分布に対する片側対合t検定)。制御タスクのMGモデル、PRモデル、RLモデルは、報酬の大きさのみ、報酬の確率のみ、選択肢を生成するRLモデルの2つです。その他のタスクでは、SフリーRLはシミュレーションのないRLであり、S-RL sAPE、S-RL sRPE、およびS-RL sRPE + sAPEは、sAPEエラーのみ、sRPEのみ、およびsRPEおよびsAPEである。
制御タスクでは、各試行において1つの刺激のみが「正しい」ものであり、これは単一の報酬確率によって支配された。すなわち、確率pは試行のブロック全体にわたって固定され、両方の刺激の報酬確率はp 1- pである。被験者が正しい選択をしたとき、被験者は、選択された刺激に視覚的に割り当てられた大きさの報酬を受け取った。報酬の確率は知られていなかったので、全体の報酬収入を最大にするために試行の過程で学ばなければならなかった(Behrens et al。、2007)。両方の刺激に対する報酬の大きさは無作為であったが、各試行において視覚的に割り当てられたので、特定の報酬の大きさを特定の刺激に関連付けることを学ぶことは不可能でもなく、必要でもなかった。
その他のタスクでは、被験者は各試行の2つの刺激の間でも選択しましたが、どの刺激が最大の報酬を与えるか予測するのではなく、制御タスクを実行していた別の人(他の人)の選択を予測することでした(図1A)。被験者は、もう一方が実験の以前の参加者であると言われましたが、その選択肢は実際にはリスク中立のRLモデルから生成されました。被験者は、予測された選択肢が他の選択肢と一致したときに、試行で固定報酬を得た。したがって、他者の選択を予測するために、被験者は、被験者が試験を通して学習した報酬確率を知る必要があった。
制御タスクにおける被験者の選択は、各ウェル刺激(の値を計算するための報酬確率と大きさを合わせ基本的なRLモデルでフィッティングした式(1)における実験手順)および選択確率(生成するために図S1オンラインで利用可能A)を。報酬の大きさが各試行において明示的に示されたことを考えると、被験者は報酬確率のみを学習する必要があった。したがって、RLモデルは、報酬予測誤差が報酬確率の更新(上に集束されるように改変した式(2)ではなく、それ自体、値のこのタスクを使用する以前の研究におけるように)(ベーレンスら、2007)。RLモデルは、> 90%の精度で被験者の選択肢を正しく予測した(平均±SEM:0.9117±0。
コントロールと他のタスクにおける被験者の報酬確率の学習を比較するために、より高い報酬確率を持つ刺激が試行の過程で選択された時間の割合(全被験者に平均した)をプロットした(図 1B、左)、すべての試験で平均した(図 1B、右)。コントロールタスクの間、被験者は刺激に関連する報酬確率を学習し、リスク回避戦略を採用した。報酬確率が高い刺激が選択された回数の割合は、被験者が刺激報酬の確率を学習したことを証明する、初期試験(図 1B、左、青色曲線)中に徐々に増加した。高確率の刺激が選択されたすべての試験の平均パーセンテージ( 図1 B、右、充填された青色の円)は、その刺激(関連付けられた報酬の確率よりも有意に高かった。図1はp <0.01、B、右、破線、両側t検定)。この発見は、被験者がリスク回避行動に従事していること、すなわち、最適またはリスク中立的に行動している場合に、より頻繁に刺激を選択することを示唆している。実際、RLモデル(補足実験手順)の適合性の観点から、大部分の被験者(23/36人の被験者)は、リスク中立性またはリスクが起こりやすい行動ではなく、リスク回避行動を採用した。( 図 1B、右、破線; p <0.01、両側t検定)よりも有意に高かった。この発見は、被験者がリスク回避行動に従事していること、すなわち、最適に、またはリスク中立的に行動している場合に、より頻繁に刺激を選択することを示唆している。実際、RLモデル(補足実験手順)の適合性の観点から、大部分の被験者(23/36人の被験者)は、リスク中立性またはリスクが起こりやすい行動ではなく、リスク回避行動を採用した。( 図 1B、右、破線; p <0.01、両側t検定)よりも有意に高かった。この発見は、被験者がリスク回避行動に従事していること、すなわち、最適またはリスク中立的に行動している場合に、より頻繁に刺激を選択することを示唆している。実際、RLモデル(補足実験手順)の適合性の観点から、大部分の被験者(23/36人の被験者)は、リスク中立性またはリスクを起こしやすい行動ではなく、リスク回避行動を採用した。彼らが最適に、またはリスク中立的に行動していた場合、より頻繁に刺激を選択する必要があります。実際、RLモデル( 補足実験手順)の適合性の観点から、大部分の被験者(23/36人の被験者)は、リスク中立性またはリスクを起こしやすい行動ではなく、リスク回避行動を採用した。彼らが最適に、またはリスク中立的に行動していた場合、より頻繁に刺激を選択する必要があります。実際、RLモデル( 補足実験手順)の適合性の観点から、大部分の被験者(23/36人の被験者)は、リスク中立性またはリスクが起こりやすい行動ではなく、リスク回避行動を採用した。
その他のタスクでは、被験者は他のタスクの選択行動を追跡しました。報酬確率が高い刺激が、被験者によって選択された時間の割合(図 1B、左、赤の曲線)は、刺激が他のものによって選択された時間の割合に従うように見えた(図 1B、左、黒曲線)。この動作は、コントロールタスクのそれとは異なり、試行に対してパーセンテージが増加しましたが、コントロールタスクのレベルよりも徐々に低下し、それ以下のレベルで安定しました。実際、他の課題(図 1B、右、黒く塗りつぶされた丸印)の被験者によって報酬確率が高い刺激の平均割合は被験者によって有意に異ならなかった(p> 0.05、( 図 1B、右黒塗りの黒丸)によって選択されたものから有意に低かったが、対照タスクで被験者によって選択されたものより有意に低かった(p <0.01、両側対t検定)。他の選択肢がリスク中立のRLモデルを用いてモデル化されているとすれば、「その他」タスクの被験者の選択は、コントロールタスクのようにリスク回避行動を使用していないが、 。一緒に、これらの結果は、被験者が他の価値ベースの意思決定をシミュレートすることを学んでいたことを示唆している。リスク・ニュートラル設定のRLモデルを使用してモデル化された場合、「その他」タスクの被験者の選択は、コントロールタスクのようにリスク回避行動を使用していないが、他のタスクと同様に動作していたことを示します。一緒に、これらの結果は、被験者が他の価値ベースの意思決定をシミュレートすることを学んでいたことを示唆している。リスク・ニュートラル設定のRLモデルを使用してモデル化された場合、「その他」タスクの被験者の選択は、コントロールタスクでのようにリスク回避行動を使用していないが、他のタスクと同様に動作していたことを示します。一緒に、これらの結果は、被験者が他の価値ベースの意思決定をシミュレートすることを学んでいたことを示唆している。
しかし、代わりの解釈も可能である。例えば、他者の選択肢を予測するというタスクの指示にもかかわらず、被験者は、他の結果や選択肢を完全に無視して、自分の結果だけに焦点を当てていたかもしれません。このシナリオでは、指示されたようにOUTCOMEフェーズ(図1A)の赤いフレームを他の選択肢ではなく「正しい」状態にすることを考慮して、「制御」タスクと同じ方法で「その他」タスクを実行した可能性があります自分自身のための刺激。したがって、そのような処理は、制御タスクで使用されるRLモデルを再構成することによってモデル化することができます。これは、他の意思決定プロセスを構築することなくオプションを結果に直接関連付けるためです(Dayan and Niv 、2008 )。このモデルは行動データにはあまり適していません(次のセクションを参照)ので、却下することができます。
他の解釈は、被験者が他者の結果にのみ焦点を当て、他人の報酬を自分の報酬として処理することで、報酬予測誤差から報酬の確率を知ることができるかもしれないということである。しかし、これが真実であれば、コントロールと他のタスクの間で選択行動に違いはないはずです。しかし、コントロールタスクでの選択行動は、「その他」タスクではリスク回避とリスク中立であり、このシナリオを反論しています。それにもかかわらず、他方の報酬を自分たちのものとして処理することが、2つのタスク間のリスク行動の違いを引き起こした可能性があると主張することができる。相手の報酬を自分たちのものとして処理することは、彼ら自身の報酬のために実行したときに存在していたリスク回避傾向を何らかの形で抑えることができたが、それにより、他のタスクの間に、他のリスク中立的な振る舞いと同様の選択行動を与える。そうであれば、被験者の選択行動は、他のタスクがリスク中立的な振る舞いをしているかどうかにかかわらず、常に他のタスクにおいてリスク中立でなければならない。
我々は他のリスク回避の設定とRLモデルによってモデル化された他のタスクの別のバージョンを使用して、この予測をテストし、予測に反して、被験者の行動は、他(の追跡された、ことを見出した。図1 Cを)。私たちは追加の実験を行い、この「リスク回避」の他のタスクを第3のタスクとして追加しました。元の2つのタスクにおける被験者の行動は、元の実験の結果を再現した。しかし、第3の課題の選択肢は、リスク中立的なRLモデル(p <0.01、両側ペアt検定)によってモデル化されたものと一致しなかったが、 averse RLモデル(p> 0.05、両側対t検定)。また、術後アンケートへの回答は、他の結果( 補足的実験手順)の選択と結果の両方に注意を払っていることを確認した。これらの結果は上記の議論を反駁し、被験者が他の価値ベースの決定をシミュレートすることを学んだという概念に支持を与える。
他のタスク中の他の意思決定プロセスの挙動をシミュレートするためのモデルの学習モデルの継承
どのような情報主体が他者の行動をシミュレートするために使用されたかを決定するために、他の価値ベースの意思決定をシミュレートする様々な計算モデルを行動データに適合させた。これらの「シミュレーションベースの」RLモデルの一般的な形式は、被験者が他の意思決定プロセスをシミュレートすることによってシミュレートされた他の報酬確率を学習したことである。決定の時点で、被験者は、シミュレートされた他の値(シミュレートされた他の報酬の確率に与えられた報酬の大きさを乗じたもの)を使用して、シミュレートされた他の選択確率を生成し、これから、先に論じたように、被験者が他方の決定、すなわち他方の結果および選択について学ぶための2つの潜在的な情報源が存在する。
被験者が自分の価値ベースの意思決定プロセスのみを適用して、他の決定をシミュレートすると、他の結果を使用してシミュレーションを更新します。それらは、他方の実際の結果とシミュレートされた他方の報酬確率との間の差に従ってシミュレートされた他の報酬確率を更新する。この違いを「シミュレートされた報酬予測誤差」(sRPE; 式4)と呼んでいます。
しかし、被験者は、他方のプロセスの学習を容易にするために、他方の選択肢を使用することもできる。すなわち、被験者は、シミュレーションを更新するための実際の選択から、他の選択肢の予測における矛盾を使用することもできる。我々は、他方の選択肢とシミュレート他者の選択確率との差を「模擬他者の行動予測誤差」(sAPE; 式6)と名付けた。特に、sAPE信号をsRPEに匹敵する信号としてモデル化し、2つを結合して(すなわち、それぞれの学習速度を乗算して加算し、式3)、シミュレートされた他の報酬確率を更新する(図S1参照)。 Aは、仮定された計算プロセスの概略図である)。
シミュレーション・ベースのRLモデルは、sRPEとsAPE(Simulation-RL sRPE + sAPE)を使用したモデル、sRPE(Simulation-RL sRPE)のみを使用したモデル、 sAPEのみを使用するモデル(Simulation-RL sAPE)があります。比較の一環として、我々はまた、上記のシミュレーションのないRLモデルを検討した。
これらの計算モデルのそれぞれを行動データにフィッティングさせ、それらの適合度を比較することにより(図 1D; パラメータ推定値および各モデルの疑似R 2についての表S1)、シミュレーション-RL sRPE + sAPEモデルが提供されたデータに最も適しています。第1に、3つのSimulation-RLモデルすべてが、シミュレーションのないRLモデルよりも実際の挙動を有意に良好に適合させた(p <0.0001、被験者間のAIC値の分布に対する片側対t検定)。これは、被験者が他のタスクにおける他の意思決定プロセスを考慮し、内部的にシミュレートしたという概念を広く支持する。二番、Sim-RL sRPE + sAPEモデル(以下、S-RL sRPE + sAPEモデル)は、予測誤差のみのいずれかを用いてSimulation-RLモデルよりも挙動を著しく改善した(p <0.01、AIC分布; 図 1D)。この観察は、AIC値、いわゆるベイジアン超過確率を用いたベイジアン比較、およびすべての被験者のモデルのフィット感を一緒にして、他のタイプの統計を用いて調べた場合にも支持された(表S2)。S-RL sRPE + sAPEモデルは被験者の選択の> 90%(0.9309±0.0066)を首尾よく予測した。さらに、上記の行動結果から予想されるように、
別の分析では、sRPEとsAPEが異なる情報を提供し、両者が被験者の選択肢の予測に影響を与えることを確認しました。第一に、他の行動や選択の情報だけでなく、エラー(とその学習率)もほとんど無相関であった(補足情報)。これは、2つのエラーの別々の寄与が可能であることを示している。第2に、被験者の選択行動は、以前の試験ではsAPE(大小)とsRPE(正または負)に関して変化し、両方の組み合わせでは変化しなかったことが分かった(双方向反復測定ANOVA:p sRPE主効果については<0.001、sAPE主効果についてはp <0.001、それらの相互作用についてはp = 0.482; 図 S1B )。
次に、S-RLのsRPE + sAPEモデルをいくつかのバリエーションに比較しました。最初に、異なるレベルのリスクパラメータを含めることが上記の所見に影響を与えるかどうかを調べた。元のS-RL sRPE + sAPEモデルは、シミュレートされた他のレベルのリスクパラメータのみを含む(シミュレートされた他の選択確率を計算する)が、このモデルの他の2つの変形を考慮することが可能である。被験者のレベル(被験者の選択確率を計算する)、および被験者および擬似他のレベルにおけるリスクパラメータを含む別のものである。オリジナルのS-RL sRPE + sAPEモデルとこれらのモデルとの適合度の比較は、元のモデルの使用をサポートしました(補足情報を参照)。次に、sAPE を学習のためではなく、次の試験(補足実験手順)で被験者の選択をバイアスするために使用した最近の研究( Burke et al。、2010)で利用されている別のタイプの変異体の性能を調べた。この変種と元のS-RL sRPE + sAPEモデルとの適合度の比較は、元のモデルの優れた適合性を支持した(p <0.001、片側対合t検定)。これらの結果は、被験者が、sRPEとsAPEの両方を使用して、他の価値ベースの意思決定プロセスをシミュレートすることを学んだことを示唆している。次の試験( 補足的実験手順)での選択肢の選択。この変種と元のS-RL sRPE + sAPEモデルとの適合度の比較は、元のモデルの優れた適合性を支持した(p <0.001、片側対合t検定)。これらの結果は、被験者が、sRPEとsAPEの両方を使用して、他の価値ベースの意思決定プロセスをシミュレートすることを学んだことを示唆している。次の試験( 補足的実験手順)での選択肢の選択。この変種と元のS-RL sRPE + sAPEモデルとの適合度の比較は、元のモデルの優れた適合性を支持した(p <0.001、片側対合t検定)。これらの結果は、被験者が、sRPEとsAPEの両方を使用して、他の価値ベースの意思決定プロセスをシミュレートすることを学んだことを示唆している。
Simulated-Otherの報酬および行動予測の誤差を反映した神経信号
次に、fMRIデータを分析して、どの脳領域が他の意思決定プロセスのシミュレーションに関与しているかを調べた。S-RL sRPE + sAPEモデルが他の課題の行動に適合することに基づいて、我々は決定時の被験者の報酬確率(決定段階;材料および方法)およびsRPEアウトカム段階でsAPEを行い、全脳回帰分析にそれらを入力しました。同様に、制御タスクからのfMRIデータは、被験者の行動に対するRLモデルの適合に基づく回帰変数を用いて分析された。
sRPEと有意に相関するBOLD応答は、両側腹側前頭前野皮質においてのみ見られた(vmPFC; p <0.05、補正された; 図2A ; 表1)。これらの信号がleave-one-outクロスバリデーション手順を使用して抽出され、関心領域(ROI)選択のための独立した基準を提供し、したがって統計的妥当性を保証し(Kriegeskorte et al。、2009)、その後sRPE振幅が増加するにつれてシグナルが増加した(スピアマン相関係数:0.178、p <0.05; 図 2B)。sRPEについて予想されたように、vmPFCシグナルは、他の結果と正の相関があり、シミュレートされた他の ' ( 図 S2A )。vmPFCの活動は、しばしば価値信号および「自己」報酬予測誤差と広く相関するため(Berns et al。、2001 and O'Doherty et al。、2007)、vmPFC信号は本当にsRPEに対応し、他の変数によって誘導されなかった。vmPFC信号は、以下の潜在的交絡因子が我々の回帰分析に追加された場合でさえ、sRPEと有意に相関した(p <0.05、補正された):シミュレートされた他の報酬確率、他によって選択された刺激のシミュレートされた他の値被験者自身の報酬予測誤差と報酬確率とに基づいて決定される。vMPFC信号は、sRPEの回帰変数が最初にsAPEに直交化されてから回帰分析に含まれる場合でも有意なままであった(p <0.05、補正された)。最後に、元のsRPEを使用する代わりに、脳全体の分析において回心としての報酬の大きさ(すなわち、各試行で選択された刺激の報酬の大きさを乗じたsRPE)を用いた。vmPFCは、このエラーと有意に相関する活性を示す唯一の脳領域であった(p <0.05、補正した)。これらの結果は、vmPFC中の活性がもっぱらsRPEに関する情報を含んでいたことを示唆している。我々は、脳全体の分析において、報酬の大きさ(すなわち、各試行において他のものによって選択された刺激の報酬の大きさにsRPEを掛けたもの)を回帰者として用いた。vmPFCは、このエラーと有意に相関する活性を示す唯一の脳領域であった(p <0.05、補正した)。これらの結果は、vmPFC中の活性がもっぱらsRPEに関する情報を含んでいたことを示唆している。我々は、脳全体の分析において、報酬の大きさ(すなわち、各試行において他のものによって選択された刺激の報酬の大きさにsRPEを掛けたもの)を回帰者として用いた。vmPFCは、このエラーと有意に相関する活性を示す唯一の脳領域であった(p <0.05、補正した)。これらの結果は、vmPFC中の活性がもっぱらsRPEに関する情報を含んでいたことを示唆している。
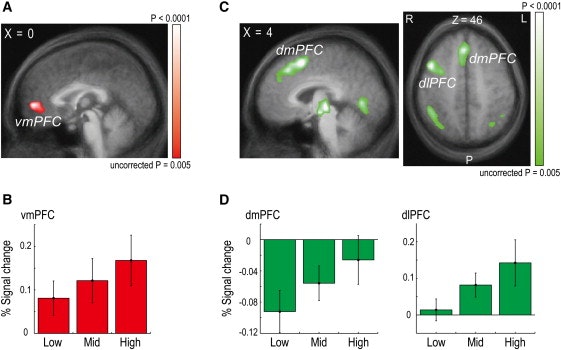
図2
シミュレートされた他者の報酬および行動の予測誤差と相関する神経活動
(A)vmPFCにおける神経活動は、結果の時点(talairach座標:x = 0、y = 53、z = 4)におけるsRPEの大きさと有意に相関した。(A)および(C)のマップは、表示のため補正されていないp <0.005で閾値設定される。
(b)sRPEが低かった試行中、vmPFCにおけるBOLD信号の平均変化率(被験者全体で、n = 36;エラーバー=±SEM;結果開始後7-9秒) 、または高い(それぞれ、33 番目、66 番目、または100 番目のパーセンタイル)。
dmPFC(x = 6、y = 14、z = 52)およびdlPFC(x = 45、y = 11、z = 43)における神経活動は、結果の時点でsAPEの大きさと有意に相関した左:サジタルビュー、右:アキシャルビュー)。
(d)sAPEが低、中、または高であった試行中、dmPFCおよびdlPFCにおけるBOLDシグナルの変化率(交差開始後7-9秒)。
表1。
他のタスク中にBOLD信号に顕著な変化を示す領域
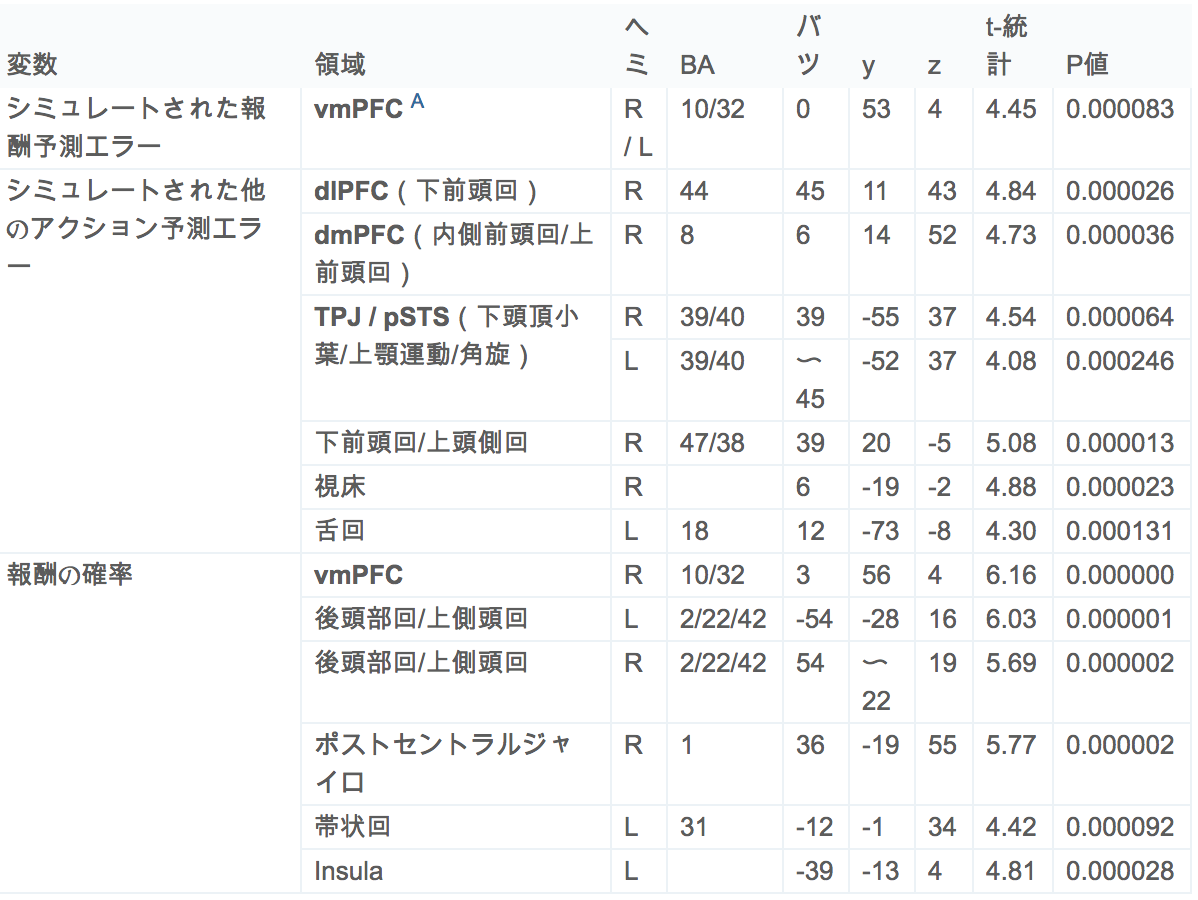
fMRIの全脳解析(p <0.05、補正)後に観察された活性化クラスター。定位座標はTalairach空間に一致し、それに応じてRegion列の解剖学的用語が与えられる。右端の欄には、各遺伝子座のピークにおける未補正のp値が示されている。本文中で議論された関心領域は太字で示されている。vmPFC:腹側前頭前野、dlPFC、背外側前頭前野; dmPFC、背前頭前頭皮質; ヘミ、半球; BA、ブロッドマン地区。
本明細書および表2で参照されるvmPFC領域は、Beckmannら(Beckmannら、2009 および Rushworthら、2011)によって参照されるクラスタ2の近傍にある。詳細に検討すると、活性化されたvmPFC領域の座位は実際にはBA10と32との間に位置し、領域14mとしても知られるクラスタ2に似ている(Mackey and Petrides、2010)。
右前頭前頭前皮質(dlPFC; p <0.05、補正後; 図 2C)およびいくつかの他の領域(p <0.05)は、右前頭前頭前野皮質におけるBOLDシグナルの変化表1)。dmPFC / dlPFC活性は、クロスバリデーション(dmPFC:0.200、p <0.05; dlPFC:0.248、p <0.05; 図 2D)の後でさえ、作用予測誤差と有意に相関し続けた。dmPFC / dlPFCシグナルは、潜在的交絡因子(被験者と被験者によって選択された刺激のシミュレートされた他の報酬確率)が回帰分析に加えられたときに有意なままであった(p <0.05、またはsAPEの回帰変数が最初にsRPEに直交化され、その後回帰分析に含まれたとき(p <0.05、補正されたとき)に、また、dmPFC / dlPFCの有意な活性化が確認された(p <0.05、補正された)が、行動レベルの行動予測誤差が値レベルの誤差の代わりに回帰変数として用いられた場合でも確認された。顕著な活性化を伴うdmPFC / dlPFC領域は、有意水準にある誤差を用いて、もともと有意な活性化に関連した領域とかなり重なっていた( 図 S2B )。行動レベルの行動予測誤差を値レベルの誤差ではなく回帰変数として用いた場合でも、顕著な活性化を伴うdmPFC / dlPFC領域は、有意水準にある誤差を用いて、もともと有意な活性化に関連した領域とかなり重なっていた( 図 S2B )。行動レベルの行動予測誤差を値レベルの誤差ではなく回帰変数として用いた場合でも、顕著な活性化を伴うdmPFC / dlPFC領域は、有意水準にある誤差を用いて、もともと有意な活性化に関連した領域とかなり重なっていた( 図 S2B )。
これらの知見を考慮して、我々はさらに、これらの脳領域におけるニューロン活動がsRPEおよびsAPEをコードするならば、被験者にわたるこれらのシグナルの変動性はそれらのシミュレーション学習に影響を及ぼすはずであるため、シミュレートされた他の値これらのエラーを使用します。換言すれば、ROI内のより大きいまたはより小さい神経信号を有する対象は、誤差(すなわち、各誤差に関連するより大きいまたはより小さい学習率を表示する)に起因して、より大きなまたはより小さな行動学習効果を呈するべきである。
この仮説を検証するために、被験者のグループレベルの相関を調べた(図3)。sRPEのvmPFC BOLD信号の個人差(誤差の回帰係数の推定大きさによって測定;「効果サイズ」と呼ばれる)は、sRPEの学習率の個人差と相関していた(S- RL SRPE + SAPE行動データに対するモデル)を、SAPEのdmPFC / DLPFC BOLD信号でそれらながらSAPEの学習速度のものと相関していました。第1に、vmPFC活性は、説明された分散が比較的小さい(Pearson 'sの平方根で測定された)場合でも、sRPEの学習速度と有意に相関した(図3A、左;スピアマンのρ= 0.360、s相関係数、 r 2 = 0.124)。元の相関分析を複合した可能性のある被験者の異常値を防ぐために、2つの追加分析を行った。Jackknife外れ値検出法(ρ= 0.447、p <0.005)または強い相関係数(r '= 0.346、p <0.05)(補足実験手順)を用いてすべての外れ値を除去した場合でも相関は有意なままであった。したがって、vmPFC活性の観察された調節は、vmPFCシグナル(sRPEの推定シグナル)が被験者間のsRPEを用いた学習によって引き起こされる行動変動と関連するという我々の仮説に対する相関的支持を提供する。二番、dmPFC / dlPFC活性はsAPEの学習速度と有意に相関していた( 図 3B、ρ= 0.330、p <0.05; r 2 = 0.140; 図 3C、ρ= 0.294、p <0.05; r 2 = 0.230 )。(dmPFC、ρ= 0.553、p <0.0005; dlPFC、ρ= 0.382、p <0.05)またはロバスト相関係数(dmPFC、r '= 0.377、p <0.005; dlPFC、r '= 0.478、p <0.01)。これらの結果は、dmPFCおよびdlPFCシグナル(sAPEの推定シグナル)の変動が、被験者間のsAPEを用いた学習によって引き起こされる行動変動性と関連するという我々の仮説を支持する。ρ= 0.330、p <0.05; r 2 = 0.140; そして、図3 C、ρ= 0.294、p <0.05。r 2 = 0.230)。(dmPFC、ρ= 0.553、p <0.0005; dlPFC、ρ= 0.382、p <0.05)またはロバスト相関係数(dmPFC、r '= 0.377、p <0.005; dlPFC、r '= 0.478、p <0.01)。これらの結果は、dmPFCおよびdlPFCシグナル(sAPEの推定シグナル)の変動が、被験者間のsAPEを用いた学習によって引き起こされる行動変動性と関連するという我々の仮説を支持する。ρ= 0.330、p <0.05; r 2 = 0.140; そして、図3 C、ρ= 0.294、p <0.05。r 2 = 0.230)。(dmPFC、ρ= 0.553、p <0.0005; dlPFC、ρ= 0.382、p <0.05)またはロバスト相関係数(dmPFC、r '= 0.377、p <0.005; dlPFC、r '= 0.478、p <0.01)。これらの結果は、dmPFCおよびdlPFCシグナル(sAPEの推定シグナル)の変動が、被験者間のsAPEを用いた学習によって引き起こされる行動変動性と関連するという我々の仮説を支持する。r 2 = 0.230)。(dmPFC、ρ= 0.553、p <0.0005; dlPFC、ρ= 0.382、p <0.05)またはロバスト相関係数(dmPFC、r '= 0.377、p <0.005; dlPFC、r '= 0.478、p <0.01)。これらの結果は、dmPFCおよびdlPFCシグナル(sAPEの推定シグナル)の変化が、被験者間のsAPEを用いた学習によって引き起こされる行動変動性と関連するという我々の仮説を支持する。r 2 = 0.230)。(dmPFC、ρ= 0.553、p <0.0005; dlPFC、ρ= 0.382、p <0.05)またはロバスト相関係数(dmPFC、r '= 0.377、p <0.005; dlPFC、r '= 0.478、p <0.01)。これらの結果は、dmPFCおよびdlPFCシグナル(sAPEの推定シグナル)の変動が、被験者間のsAPEを用いた学習によって引き起こされる行動変動性と関連するという我々の仮説を支持する。01)。これらの結果は、dmPFCおよびdlPFCシグナル(sAPEの推定シグナル)の変動が、被験者間のsAPEを用いた学習によって引き起こされる行動変動性と関連するという我々の仮説を支持する。01)。これらの結果は、dmPFCおよびdlPFCシグナル(sAPEの推定シグナル)の変動が、被験者間のsAPEを用いた学習によって引き起こされる行動変動性と関連するという我々の仮説を支持する。
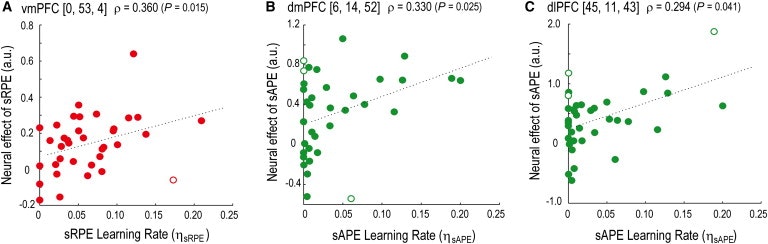
図3
vmPFCとdmPFC / dlPFCにおける学習信号による神経変動と行動変動の関係
SRPE(エラーの学習速度の行動効果を有するSRPEためvmPFC活性の(a)被験体群レベルの相関η SRPE)。vmPFCアクティビティは、vmPFC領域で平均化されたエラーのエフェクトサイズによって示されます。白丸はジャックナイフ外れ値検出を使用して潜在的な異常値データポイント(被験者)を示す。
(B)sAPEのdmPFC活性とsAPE (ηsAPE)の行動効果との相関性は、。
(C)sAPEのd1PFC活性とsAPE (ηsAPE)の行動効果との相関。
価値観に基づく意思決定の自己表現とシミュレーションの共有表現
次に、vmPFCアクティビティのパターンが2つの側面で自己と他者の決定プロセスとで共有されているかどうかを調べました。第1に、vmPFC領域は、その他のタスクでsRPEによって変調された唯一の領域でした。sRPEは、他人の隠れ変数を代用すると推定されるシミュレートされた他の報酬確率を参照して生成された、社会的環境における他のプロセスをシミュレートすることに基づいていました。我々は、同じvmPFC領域が、シミュレーションを伴わない非社会的環境における制御タスク中の被験者の報酬予測誤差の信号を含んでいたかどうかを知ることに興味を持った。第2に、他のタスクの決定時に、被験者はシミュレーションに基づいて他の選択肢の予測を示すように選択したのに対し、制御タスクでは、彼らはシミュレーションなしで彼ら自身のために最良の結果を得るために彼らの選択をしました。したがって、同じvmPFC領域に、両方のタイプの決定における被験者の決定変数の信号が含まれているかどうかにも興味があった。これらの問題に対処するために、我々は両方のタスクの間に脳全体の分析におけるこれらの変数の神経相関を調べ、交差検定ROI分析を行った。
我々は、vmPFCが、他のタスクにおける被験者自身の報酬確率に関連する信号によって変調されることを見出した。他のタスク中の全脳解析は、vmPFC(p <0.05、補正; 図4A)を含むいくつかの脳領域におけるBOLDシグナルを同定し、被験者の報酬確率(被験者によって選択された刺激について)決定の時(表1)。被験者の報酬確率は、選択肢を生成するための仮定された計算プロセスにおける最下流のものであるため、選択肢に最も近い決定変数であるが、他者の意思決定プロセス、特に模擬他者のシミュレーションプロセスにも基づいている報奨確率(図 S1A )。被験者の報酬確率によって有意に調節されたvmPFCの活性化が、シミュレートされた他者の報酬確率によって、またはおそらくむしろむしろそれによって増強されるかどうかを決定するために、我々は2つのさらなる全脳解析を行った:潜在的な交絡者として回帰分析に加えられ、被験者の確率の回帰変数が最初に擬似他者の報酬確率に直交化され、その後、シミュレートされた他の報酬確率と共に回帰分析に含まれたとき、他の報酬確率。両方の場合において、vmPFCの活性化は、被験者の報酬確率によって有意に調節されたままであった(p <0.05、補正された)。
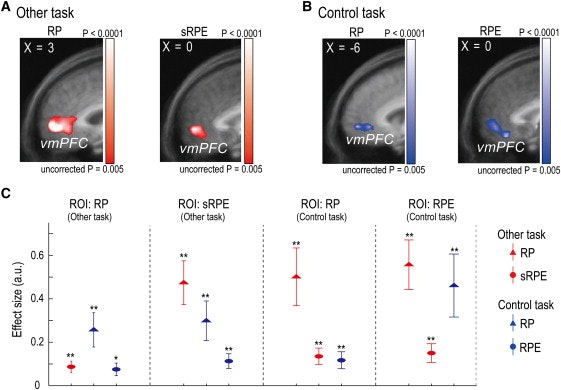
図4
vmPFCにおける自己と他者のための共有表現
(x = 3、y = 56、z = 4; p <0.05、補正された)被験者の報酬確率(RP)によって有意に調節されたその他のタスクにおける(A)(左)vmPFC信号。(右)SRPE;に示される信号に対して(X = 0、Yが= 53、Z = 4、P <0.05、補正後)。図2(A)及び(B)にマップはP <0.005で閾値処理さA.、表示のために補正されていない。
(x = -6、y = 56、z = 1; p <0.05、補正後)の被験者の報酬確率(RP)によって有意に変調された制御タスクにおける(B)(左)vmPFC信号。(右)OUTCOME時(x = 6、y = 53、z = -2、p <0.05、補正後)の被験者の報酬予測誤差。
(C)vmPFC信号がOther(赤色)およびControl(青色)タスクのタスク関連情報、つまりOtherタスクのRPおよびsRPE、ControlタスクのRPおよびRPEを表す範囲を示す4つのROI分析。各プロットは、vmPFCで検査されたROIを定義した変数でラベル付けされています。ROI上の他の3つの信号のエフェクトサイズがプロットされます(右の記号の凡例を参照)。点は平均(±SEM)を表す。* p <0.05、** p <0.005。
比較のために、SRPEに関連する重要なvmPFC信号もに示されている。図4ここでA.、我々はSRPEは、被験者自身の報酬予測誤差(対象者自身の成果と彼/彼女の自身の報酬確率の差)はなかったことを強調しますその他のタスク中に 実際に、他のタスク中の被験者自身の報酬予測エラーによって、領域は有意に活性化されなかった。この観察は、被験者自身の報酬予測誤差の回帰変数を追加し、sRPEおよびsAPEの退縮者を除いたことを除いて、元の分析と同じ方法で行われた追加の全脳解析によって確認された。
コントロールタスク中の全脳解析では、決定時点の報酬確率(被験者が選択した刺激の場合)と報酬予測誤差が有意に変化していた(p <0.05、修正)結果(図 4B、表2)。選択された刺激の報酬の大きさと、報酬の確率の値と報酬の確率と、報酬予測の誤差との間で有意な差はなかった(p <0.05、修正)。

次に、4つの交差検定ROI分析を使用して、同一のvmPFC領域が、対象となる4つの変数、すなわち、他の課題(図4A)におけるsRPEおよびrRPEの4つの全ての変数によって有意に変調された信号を含むかどうかを調べた。被験者自身のRPおよび報酬予測誤差(RPE)を制御タスク(図 4B)に示す。全脳解析では、これらの変数ごとにvmPFCのROIを定義しました。次に、与えられたROIの神経活動が、他の3つの変数のいずれかまたはすべてによって有意に調節されているかどうかを調べた。実際、vmPFC中の所与のROIの各々は、他の3つのROIを規定する変数のそれぞれによって有意に調節されたシグナルを含んでいた(p <0.05またはp <0.005; 図4C)。また、元のフィルタ(FWHM = 8 mm)よりも狭い画像データ前処理中の空間平滑化のためのガウスフィルタ(半値全幅(FWHM)= 6 mm)を使用して同じ分析を行った。この場合、コントロールタスクのRPではなく、3つの変数がvmPFCで有意なアクティブ化を示しました(p <0.05、補正されました;コントロールタスクのRPではクラスタサイズ= 21)。より狭いガウスフィルタを用いて補正されたp <0.05)。しかしながら、制御タスクにおけるRPのROIがリベラル閾値の下で定義されたとき、1つの変数の所与のROIにおける活性が、他の3つの変数のそれぞれによって有意に調節されたことが再度観察された(p <0.05)。元の分析における観察は真のままであった(p <0)。05)を使用してもROI分析( 補足情報を参照)で直交化された変数を使用しています。これらの結果は、vmPFCの同じ領域には、制御タスクおよびその他のタスクの両方における被験者の決定のための神経信号、ならびにシミュレーションの有無にかかわらず報酬予測エラーから学習するための信号が含まれることが示される。
討論
私たちは、知識が新しいものであり、被験者は他者の価値に基づく決定を学び、予測しなければならない選択パラダイムにおける行動を調べた。このパラダイムは、直接的に相互作用することなく他のものを観察することを伴うため、最も基本的なシミュレーション学習に焦点を当てることができました(Amodio and Frith 、2006、Frith and Frith 、1999 and Mitchell、2009)。集合的に、我々の結果は、自分自身のプロセスを直接募集することによって他方のプロセスのシミュレーションの考え方を支持するが、この直接募集仮説の重要な改訂を示唆している。被験者は、シミュレーション学習における2つの異なる予測誤差信号、すなわちシミュレートされた他の報酬および行動予測誤差、sRPEおよびsAPEをそれぞれ同時に追跡した。sRPEは、vmPFCのみで信号を大きく変調し、直接募集によるシミュレーション学習におけるこの領域の顕著な役割を示しています。しかし、我々はまた、シミュレーション学習がアクセサリ学習信号:dmPFC / dlPFCにおける神経表現を伴うsAPEを利用することも見出した。
自己とシミュレートされた共有表現 - その他
私たちの発見は、vmPFCが、価値ベースの意思決定において、自己とシミュレートされたものとの間の共有表現のための標準的なリソースであることを示しています。本研究では、制御課題や他の課題に被験者内設計を採用することで、vmPFCが報酬予測誤差の表現が自己と他者の間で共有される領域であるという最初の直接的な証拠を我々が知る限り、被験者は、sRPEを用いて他の隠れ変数を学習し、vmPFCはBOLD信号を有する唯一の脳領域であり、制御タスクの被験者の報酬予測エラーとその他のタスクの被験者のsRPEの両方によって著しく調節された。さらに、我々の発見は、同じvmPFC領域が被験者の決定に重要であるという直接的な証拠を提供し、他のプロセスがシミュレートされているかどうかは関係ありません。両方のタスクにおいて、vmPFCシグナルは、決定が下された時点で、被験者の決定変数(被験者の報酬確率)によって有意に調節された。直接募集による擬人化は、自己と擬似他者との間の共有表現のために同じ神経回路を必要とする。直接募集とは別に、自己と他者との共有表現は、共感のような社会的認知の他の形態において重要な役割を果たすと考えられている。vmPFCは、さまざまな認知領域における共有表現の領域に属していることが示されています( Decety and Sommerville、2003、Keysers and Gazzola、2007、
学習信号をコード化するために、vmPFCは腹側線条より適応性が高いと思われる。vmPFCシグナルとは対照的に、腹側線条体のシグナルは、コントロールタスクにおける被験者自身の報酬予測誤差によってのみ有意に調節された(図S3 ; 表2)。vmPFCは、内部モデルが関与しているときにvmPFCが報酬予測エラーに関連する信号をエンコードする可能性があるという一般的な考え方と一致して、この研究における他のプロセスをシミュレートするため優先的に採用された(O'Doherty et al。、2007)。vmPFCはタスクの要求に対してより敏感かもしれません。その他のタスクでは、被験者自身の報酬予測エラーによって領域が大きく変調されなかった。これは単にタスク設計の限界に起因するものかもしれませんが、対象の固定報酬サイズが報酬予測誤差の検出を制限する可能性があるためです。しかし、もう一つの側面は、この課題の他の選択を予測することを学ぶために、被験者自身の報酬予測誤差がsRPEほど有用ではなかったことである。また、vmPFCは、被験者が他の結果を代理したときではなく、他のタスクのように、学習のために他の結果を使用したときに具体的に採用されるかもしれない。他の結果は、被験者(より「個人」の場合のみ、腹側線条体の活動が誘発される可能性がありますMollのら。、2006)、彼らは相手の成果(に自分の成果を比較する際に、例えば、Fliessbachら、2007 および Rillingら、
sRPEは、他のものに関連した報酬予測エラーの特定の形式であり、シミュレートされたotherを参照して作成され、隠れ変数を学習するために使用されました。他の報酬予測誤差の異なる形態も、vmPFCにおける活動を調節した。vmPFCの活動は、「観察的」報酬予測誤差(他者の刺激選択結果と被験者の刺激値との間の差)と相関した(Burkeら、2010 および Cooperら、2011)。このエラーは、どの刺激が被験者に報酬を与える可能性が高いかを示したが、ここに示した研究では、sRPEは、どの刺激が他の刺激に報われる可能性が高いかを示した。vmPFC信号はまた、他の ' ( Cooper et al。、2010)。今後の研究のための興味深い道はとの関係についての理解を深め、および使用、仮想または反事実学習(の形で関与代行報酬予測誤差の異なるタイプのことですベーレンスら。、2008、Boormanら。、2011、Haydenら、2009 および Lohrenzら、2007)。
シミュレーション学習の洗練:行動予測誤差
私たちの発見は、シミュレーション中に、人間は他の内部変数をモデル化するためにsAPEという別の学習信号を使用することを実証しています。このエラーは直接的な募集仮説に基づいて全く予期しなかったものであり、他方の選択の観察を使用して学習中にシミュレーションが動的に洗練され、より強い仮説も拒否されることを示している。
sAPEは、dmPFC / dlPFCおよびいくつかの他の領域(表1)においてBOLDシグナルを有意に調節したが、sRPEはそうではなかった。この活性化パターンは、これらの領域が、他の結果(Amodio and Frith 、2006)ではなく、他者の選択を利用する際に特定の役割を果たす可能性があることを示唆している。この見解は、対象が他人の行動、選択、または意図を考慮した社会的状況における以前の研究に集中しているが、必ずしもその結果ではない(Barraclough et al。、2004、Hampton et al。、2008、Izuma et al。 2008、Mitchellら、2006、Yoshidaら、2010 および Yoshidaら、2011)、また、非社会的環境における研究( Gläscheret al。、2010、Li et al。、2011 and Rushworth、2008)もある。他の領域のうち、側頭頂接合部および後側頭側頭溝(TPJ / pSTS)は注目に値する。我々の結果は、社会的背景(Behrens et al。、2008、Hampton et al。、2008 and Haruno and Kawato、2009)におけるRLパラダイムを用いた以前の研究と一致して、TPJ / pSTSが他者の選択を利用する役割を支持する。
dmPFC / dlPFCおよびTPJ / pSTSが価値および行動レベルの両方でsAPEによって有意に活性化されたという我々の知見は、行動と結果の符号化の間、または行動と結果のモニタリングの間の区別に重要な歪みを与える(Amodio and Frith 、2006)。これらの領域の信号は、行動モニタリングの結果を表していましたが、アウトカム期待値(シミュレートされた他の報酬確率)をすぐに利用できる形式でした。このエラーに関連するすべてのプロセス(アクション・レベルでの生成)から、(アクションからバリュー・レベルへの)評価値の学習シグナルとしてのエラーの表現への変換(値レベルにおける)のすべてが、これらの領域で同時に発生することがあります。
sAPEは、シミュレートされた他のものの選択確率を参照して生成され、シミュレートされた他の変数を学習するために使用された、他のものに関連する行動予測エラーの特定の形態であった。dmPFC / dlPFCの活性は、他の行動予測誤差とは異なる形態の行動予測誤差、および被験者自身の評価の改善(Behrens et al。、2008 and Burke et al。、2010)によっても調整することができる。Burke et al。(2010)は、dlPFCの活性が、観察行動予測誤差(他者の実際の刺激選択と被験者自身の選択確率との間の差)によって調節されることを見出した。Behrensら (2008) は、dmPFCにおける活性が、「同盟者予測誤差」(同盟国の実際の忠実度と予想される忠実度との間の差異)によって有意に調節されることを見出した。彼らの誤差は、同盟国が被験者の刺激 - 報酬確率の学習と平行しているが、それとは別の確率であることを知るために用いられた。決定の時点で、被験者は自分の意思決定を改善するために同盟国に横たわる確率を利用することができる。対照的に、他の課題では、被験者は他者の選択を予測する必要があった。考えられる解釈の1つは、dmPFCとdlPFCは、タスクの要求に応じて、他の行動予測や参照フレームのさまざまな形を学習し、学習のために他の行動予測誤差を差別的に利用することである(Baumgartner et al。
我々の知見は、dmPFC信号の後軸から前軸への解釈をサポートしており、他の内部変数を表すために抽象度の高い順になっている(Amodio and Frith 、2006 and Mitchell et al。、2006)。sAPEは他者の実際の選択を参照していたのに対して、連邦機関の予測誤差は、彼らの選択ではなく他のコミュニケーションの意図の真実を参照していました。相応して、この研究において活性化されたdmPFC領域とBehrensらのものとの比較は、(2008)は、この研究で同定されたdmPFC領域が、それらが同定した領域のわずかに後方であることを示唆している。さらに、我々の発見は、vmPFCとdmPFCの間の軸解釈もサポートしています。sRPEは、"より抽象的な、sAPEよりもシミュレーションのための変数です。sRPEとsAPEはそれぞれシミュレートされた報酬と選択確率で生成されたが、この選択確率は報酬確率を用いて試行ごとに生成された。
全体として、我々はsAPEがシミュレーション学習のための一般的で重要なコンポーネントであることを提案する。sAPEは、被験者が他の選択肢を観察した場合のシミュレートされた他の選択確率から容易に生成されるため、直接募集によってシミュレーションから生じる可能性がある追加の、しかし「自然な」学習信号を提供する。この誤差は、他者の隠れ変数の学習を改善するために有用であるはずである。特に、他者が自分自身が期待する方法とは異なる挙動、すなわち直接動員シミュレーション(Mitchell et al。、2006)による予測とは異なる。このように、我々は、このエラーと関連する神経活動のパターンを、vmPFCで発生する評価のコアシミュレーションプロセスへのアクセサリ信号とみなし、それはさらに、sAPE以外のシミュレーションにおける学習信号のより一般的な階層を示唆している。この研究のもう1つの選択行動は、特定の性格または心理的アイソタイプにのみ関連し、リスク中性であるため、sAPEが異なる性格や心理的アイソタイプに応じて他のものについて学習を促進するように改変されているかどうか、もう一方。また、この研究では、sAPEを一般的なシグナルとして調査したので、モデルにおける他のリスク行動またはリスクパラメータの性質について学習することは、すべての試行で固定された副次的なものとして扱われました。しかし、被験者は、もう一方のリスクパラメータを学んだり、トライアル中に自分のリスクパラメータを調整したりしているかもしれません。
一緒に、私たちは、直接募集による他の評価プロセスを習得し、他者の行動変化を追跡することによって全体的な学習軌道を精緻化するために、シミュレーションが明確な前頭前部回路を必要とすることを実証する。私たちのアプローチは基本的なシミュレーション学習を使用していたため、私たちの発見は、社会的なやりとり、再帰的な推論を含むより複雑なタスクにおける高レベルの擬制化を含む、認知の多くの領域における他者の行動をモデル化し予測することに広く関係する/または別のタスクの目標。我々は、複雑な社会的相互作用におけるより高いレベルの擬人化の基礎となる信号および計算が、本研究で特定されたものに基づいて構築されることを提案する。シミュレートされた他の ' タスクの複雑さが増すと、報酬および行動予測誤差信号が利用され、修正される。この点に関して、我々は、この研究で同定されたシミュレーションプロセスおよび関連する神経回路は、複数の状況に依存する躁化シグナルを利用可能な学習シグナルとして募集することができる認知骨格として概念化することができ、社会環境における主題の目標。
実験手順
私たちは、中の材料および方法のより包括的な説明を提供補足実験手順を。
39人の健康な正常被験者がfMRI実験に参加した。被験者は、4回のテストセッション(2つのfMRIスキャンセッション、そこから行動およびイメージングデータが本文に報告され、fMRIを含まない2つのテストセッション(データが表示されない))で得られたポイントに比例した金銭的報酬を受け取った基本的な参加料に。外れ値選択行動に基づいて3人の被験者を除外した後、残りの36人の被験者を、その後の行動およびfMRIデータ分析に使用した。別個の行動実験では、24人の正常な被験者が関与し、2人の外れ者被験者を除いて、残りの22人の被験者を最終分析に使用した(図 1C)。すべての被験者は書面による同意を得て、理研の第3回研究倫理委員会の承認を得ました。
実験的な仕事
コントロールタスクとその他のタスクの2つのタスクが実行されました(図1A)。制御タスクは、1武装の攻撃タスクであった(Behrens et al。、2007)。その中心に数字で示されたランダムに割り当てられた報酬の大きさを持つ2つの刺激は、固定点の左または右にランダムに配置された。すべての試行において、報酬の大きさは、刺激とは無関係に無作為にサンプリングされたが、同じ刺激が3回の連続した試行でより大きい大きさに割り当てられないという追加の制約がある。被験者が同じ刺激を繰り返し選択しないことをさらに確実にするために、報酬の大きさのランダム化に加えて、この制約が導入された(対照分析については図 S1Dを参照)。被験者が選択した後、選択された刺激はすぐに灰色の枠で強調表示された。その後、報酬を与えられた刺激が画面中央に現れました。被験者はその確率について通知されなかったが、報酬の確率は報酬の大きさとは無関係であると指示された。
その他のタスクでは、被験者は別の人の選択を予測した。CUEからISIフェーズまで、画面上のイメージは、表示の点でコントロールタスクのイメージと同じでした。しかし、CUEに提示された2つの刺激は、制御タスクを実行する他の人物のために生成されたものである。被験者の選択肢の予測は、すぐに灰色の枠で強調表示されました。アウトカムでは、もう一方の実際の選択肢は赤枠で強調表示され、もう一方の報酬刺激は中央に表示されました。被験者の予測された選択肢が他者の実際の選択と一致したとき、彼らは一定の報酬を得た。RLモデルは、リスク中立的な基準(fMRI実験の場合)で他の選択肢を生成し、
MRIスキャナーの実験では、コントロールとその他の2つのタスクが採用されました。別の行動実験(図 1C)では、1人の対照と2人の他の3つの条件を使用した。コントロールと「その他I」タスクの設定はfMRI実験と同じでしたが、「その他II」タスクでは、リスク回避型RLモデルを使用して他の選択肢を生成しました。
fMRIの取得と分析
fMRI画像は、4T MRIシステム(Agilient Inc.、Santa Clara、CA)を用いて収集した。2ショットEPIシーケンスを用いて、BOLD信号を測定した。T1強調3D FLASHパルスシーケンスを使用して、高分解能および低分解能の全脳解剖学的画像を取得した。すべての画像をBrain Voyager QX 2.1(Brain Innovation BV、マーストリヒト、オランダ)を用いて分析した。機能イメージは、ガウスフィルタ(FWHM = 8mm)による空間平滑化を含む、前処理された。解剖学的画像を標準的なTalairach空間(TAL)に変換し、機能的画像を高解像度解剖学的画像に登録した。全ての活性化は、図S3に報告された腹側線条体における活性化を除いて、TALに基づいて報告された(凡例参照)。
BOLD信号を解析するためにモデルベースの分析を採用しました。回帰分析の退行者としての主要な変数は、制御タスクでは、決定期(CUEの発症から被験者が応答期間中に応答を出すまでの期間として定義される)で選択された刺激の報酬確率であり、およびOUTCOME期間における報酬予測エラーが含まれます。その他のタスクでは、決定的な期間に選択された刺激に対する被験者の報酬確率、およびOUTCOME期間中のsRPEおよびsAPEが主な関心対象変数であった。片側t検定を用いてランダム効果分析を行った。有意なBOLDシグナルは、複数の比較補正(クラスターレベルの推論)のためのファミリーワイズエラーを用いて補正されたp値(p <0.05)に基づいて報告された。BOLDシグナルのクロスバリデートされたパーセント変化( 図 2Bおよび2D)については、以前に記載されたleave-one-out手順(Gläscheret al。、2010)に従った。相関分析(のために図3)、私たちは、スピアマンの相関係数を計算し、(参照正の相関の我々の仮説与えられた片側t検定を使用して、その統計的有意性をテストした補足情報を二つの追加の分析のために)。